Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Fiabilité
Définition
La fiabilité fait référence à la capacité d'un service ou d'un système à exécuter la fonction attendue lorsque cela est nécessaire. La fiabilité d'un système peut être mesurée par le niveau de sa qualité opérationnelle dans un laps de temps donné. Comparez cela à la résilience, qui fait référence à la capacité d'un système à se remettre d'une infrastructure ou d'une interruption de service de manière dynamique et fiable.
Pour plus de détails sur la manière dont la disponibilité et la résilience sont utilisées pour mesurer la fiabilité, reportez-vous au pilier de fiabilité du AWS Well-Architected Framework.
Questions clés
Disponibilité
La disponibilité correspond au pourcentage de temps pendant lequel une charge de travail est disponible à’ l’utilisation. Les objectifs les plus courants sont les suivants : 99 % (3,65 jours d'indisponibilité autorisés par an), 99,9 % (8,77 heures) et 99,99 % (52,6 minutes), avec une réduction du nombre de neuf dans le pourcentage (« deux neuf » pour 99 %, « trois neuf » pour 99,9 %, etc.). La disponibilité de la solution réseau entre AWS et le centre de données sur site peut être différente de la disponibilité globale de la solution ou de l'application.
Les principales questions relatives à la disponibilité d'une solution réseau sont les suivantes :
-
Mes AWS ressources peuvent-elles continuer à fonctionner si elles ne peuvent pas communiquer avec mes ressources locales ? Et vice versa ?
-
Dois-je considérer les interruptions programmées pour la maintenance planifiée comme incluses ou exclues de la métrique de disponibilité ?
-
Comment vais-je mesurer la disponibilité de la couche réseau, indépendamment de l'état général de l'application ?
La section Disponibilité du pilier de fiabilité du Well-Architected Framework contient des suggestions et des formules pour la disponibilité des calculs.
Résilience
La résilience est la capacité d’une charge de travail à récupérer après des perturbations de l’infrastructure ou du service, d’acquérir de manière dynamique les ressources de calcul pour satisfaire la demande et d’atténuer les perturbations telles que les erreurs de configuration ou les problèmes réseau temporaires. Si un composant réseau redondant (lien, périphériques réseau, etc.) n'est pas suffisamment disponible pour fournir à lui seul la fonction attendue, il présente une faible résilience face aux pannes. Il en résulte une expérience utilisateur médiocre et dégradée.
Les principales questions relatives à la résilience d'une solution réseau sont les suivantes :
-
Combien de défaillances discrètes et simultanées dois-je prévoir ?
-
Comment puis-je réduire les points de défaillance uniques à la fois grâce aux solutions de connectivité et à mon réseau interne ?
-
Quelle est ma vulnérabilité face aux événements de déni de service distribué (DDoS) ?
Solution technique
Tout d'abord, il est important de noter que toutes les solutions de connectivité réseau hybride ne nécessitent pas un haut niveau de fiabilité, et que l'augmentation des niveaux de fiabilité entraîne une augmentation correspondante des coûts. Dans certains scénarios, un site principal peut nécessiter des connexions fiables (redondantes et résilientes) car les interruptions de service ont un impact plus important sur l'activité, tandis que les sites régionaux peuvent ne pas exiger le même niveau de fiabilité en raison de l'impact moindre sur l'entreprise en cas de panne. Il est recommandé de se référer aux recommandations de AWS Direct Connect résilience car elles
Pour obtenir une solution de connectivité réseau hybride fiable dans un contexte de résilience, la conception doit prendre en compte les aspects suivants :
-
Redondance : visez à éliminer tout point de défaillance unique sur le chemin de connectivité réseau hybride, y compris, mais sans s'y limiter, les connexions réseau, les périphériques réseau, la redondance entre les zones de disponibilité et les emplacements DX Régions AWS, ainsi que les sources d'alimentation des appareils, les chemins de fibre optique et les systèmes d'exploitation. Aux fins et dans le cadre de ce livre blanc, la redondance se concentre sur les connexions réseau, les appareils périphériques (par exemple, les dispositifs de passerelle client), la localisation AWS DX et Régions AWS (pour les architectures multirégionales).
-
Composants de basculement fiables : dans certains scénarios, un système peut être fonctionnel, mais ne pas exécuter ses fonctions au niveau requis. Une telle situation est courante lors d'une panne unique lorsqu'il est découvert que les composants redondants prévus fonctionnaient de manière non redondante. Leur charge réseau n'a aucune autre destination en raison de leur utilisation, ce qui se traduit par une capacité insuffisante pour l'ensemble de la solution.
-
Temps de basculement : le temps de basculement est le temps nécessaire à un composant secondaire pour assumer pleinement le rôle du composant principal. Le temps de basculement dépend de plusieurs facteurs : le temps nécessaire pour détecter la panne, le temps nécessaire pour activer la connectivité secondaire et le temps nécessaire pour informer le reste du réseau de la modification. La détection des défaillances peut être améliorée à l'aide de Dead Peer Detection (DPD) pour les VPN liens et de la détection de transfert bidirectionnel (BFD) pour les AWS Direct Connect liens. Le délai d'activation de la connectivité secondaire peut être très court (si ces connexions sont toujours actives), court (si une VPN connexion préconfigurée doit être activée) ou plus long (si des ressources physiques doivent être déplacées ou de nouvelles ressources configurées). La notification du reste du réseau se fait généralement par le biais de protocoles de routage internes au réseau du client, chacun d'entre eux ayant des temps de convergence et des options de configuration différents. La configuration de ces protocoles n'entre pas dans le cadre de ce livre blanc.
-
Ingénierie du trafic : L'ingénierie du trafic dans le contexte d'une conception de connectivité réseau hybride résiliente vise à déterminer comment le trafic doit circuler sur plusieurs connexions disponibles dans des scénarios normaux et de panne. Il est recommandé de suivre le concept de conception en cas de défaillance, selon lequel vous devez déterminer comment la solution fonctionnera dans différents scénarios de défaillance et si elle sera acceptable ou non par l'entreprise. Cette section décrit certains des cas d'utilisation courants de l'ingénierie du trafic qui visent à améliorer le niveau de résilience global de la solution de connectivité réseau hybride. La AWS Direct Connect section sur le routage traite BGP de plusieurs options d'ingénierie du trafic pour influencer le flux de trafic (communautés, préférences BGP locales, longueur du chemin AS). Pour concevoir une solution d'ingénierie du trafic efficace, vous devez bien comprendre comment chacun des composants du AWS réseau gère le routage IP en termes d'évaluation et de sélection des itinéraires, ainsi que les mécanismes possibles pour influencer le choix des itinéraires. Les détails à ce sujet n'entrent pas dans le cadre de ce document. Pour plus d'informations, consultez Transit Gateway Route Evaluation Order, Site-to-Site VPNRoute Priority et Direct Connect Routing ainsi que BGP la documentation nécessaire.
Note
Dans la table de VPC routage, vous pouvez faire référence à une liste de préfixes contenant des règles de sélection d'itinéraires supplémentaires. Pour plus d'informations sur ce cas d'utilisation, reportez-vous à la section Priorité des itinéraires pour les listes de préfixes. AWS Transit Gateway les tables de routage prennent également en charge les listes de préfixes, mais une fois appliquées, elles sont étendues à des entrées de route spécifiques.
Exemple de Site-to-Site VPN connexions doubles avec des itinéraires plus spécifiques
Ce scénario est basé sur un petit site sur site se connectant à un seul Région AWS via des VPN connexions redondantes via Internet à. AWS Transit Gateway La conception de l'ingénierie du trafic illustrée à la Figure 10 montre qu'avec l'ingénierie du trafic, vous pouvez influencer le choix du chemin afin d'accroître la fiabilité de la solution de connectivité hybride en :
-
Connectivité hybride résiliente : VPN les connexions redondantes fournissent chacune la même capacité de performance, prennent en charge le basculement automatique en utilisant le protocole de routage dynamique (BGP) et accélèrent la détection des défaillances de connexion grâce à la détection des pairs VPN morts.
-
Efficacité des performances : configuration ECMP sur les deux VPN connexions AWS Transit Gateway pour optimiser la bande passante globale de la VPN connexion. Alternativement, en annonçant des itinéraires différents, plus spécifiques, en plus de l'itinéraire récapitulatif du site, la charge peut être gérée indépendamment sur les deux connexions VPN
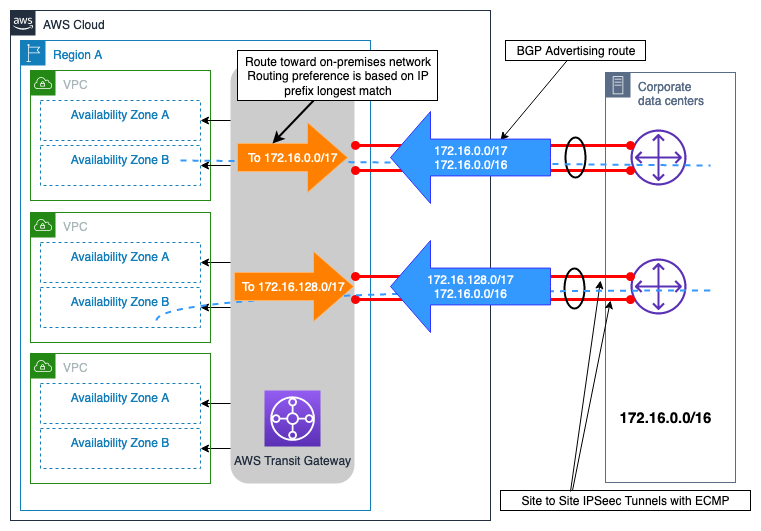
Figure 10 — Exemple de Site-to-Site VPN connexions doubles avec des itinéraires plus spécifiques
Exemple de deux sites sur site avec plusieurs connexions DX
Le scénario illustré à la Figure 11 montre deux sites de centres de données sur site situés dans différentes régions géographiques et connectés à AWS l'aide du modèle de connectivité Maximum Resiliency (décrit dans les recommandations de AWS Direct Connect résilience
En associant les attributs de la BGP communauté aux itinéraires annoncés AWS DXGW, vous pouvez influencer le choix du chemin de sortie depuis AWS DXGW le côté. Ces attributs communautaires contrôlent AWS l'attribut de préférence BGP locale attribué à l'itinéraire annoncé. Pour plus d'informations, reportez-vous à la section Politiques et BGP communautés de routage AWS DX.
Pour optimiser la fiabilité de la connectivité au Région AWS niveau, chaque paire de connexions AWS DX est configurée de ECMP telle sorte que les deux puissent être utilisées simultanément pour le transfert de données entre chaque site sur site et. AWS
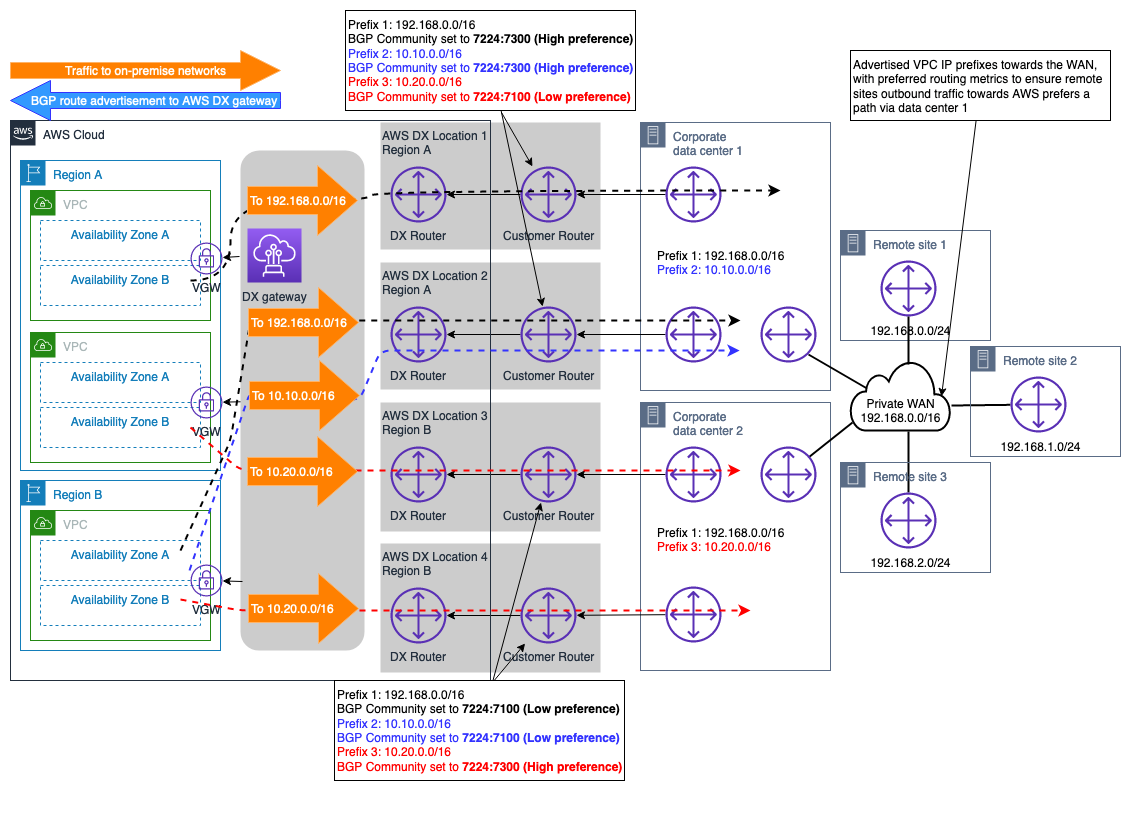
Figure 11 — Exemple de deux sites sur site avec plusieurs connexions DX
Grâce à cette conception, les flux de trafic destinés aux réseaux locaux (avec la même longueur de préfixe et la même BGP communauté annoncés) seront répartis sur les deux connexions DX par site utilisé. ECMP Toutefois, s'il n'ECMPest pas requis via la connexion DX, le même concept discuté précédemment et décrit dans la documentation des politiques de routage et BGP des communautés peut être utilisé pour affiner la sélection du chemin au niveau de la connexion DX.
Remarque : Si des dispositifs de sécurité se trouvent sur le chemin des centres de données locaux, ils doivent être configurés pour autoriser les flux de trafic sortant par une liaison DX et provenant d'une autre liaison DX (les deux liaisons étant utilisées avecECMP) au sein du même site de centre de données.
VPNexemple de connexion en tant que sauvegarde vers une connexion AWS DX
VPNpeut être sélectionné pour fournir une connexion réseau de secours à une AWS Direct Connect connexion. Ce type de modèle de connectivité est généralement dicté par le coût, car il fournit un niveau de fiabilité inférieur à l'ensemble de la solution de connectivité hybride en raison de performances indéterministes sur Internet, et il n'est pas SLA possible d'obtenir une connexion via l'Internet public. Il s'agit d'un modèle de connectivité valide et rentable, qui doit être utilisé lorsque le coût est la priorité absolue et que le budget est limité, ou éventuellement comme solution provisoire jusqu'à ce qu'un DX secondaire puisse être fourni. La figure 12 illustre la conception de ce modèle de connectivité. L'un des principaux aspects de cette conception, où les connexions DX VPN et DX se terminent au AWS Transit Gateway, est que la VPN connexion peut annoncer un plus grand nombre de routes que celles qui peuvent être annoncées via une connexion DX connectée à. AWS Transit Gateway Cela peut entraîner une situation de routage sous-optimale. Une option pour résoudre ce problème consiste à configurer le filtrage des itinéraires sur le dispositif de passerelle client (CGW) pour les itinéraires reçus de la VPN connexion, en autorisant uniquement les itinéraires récapitulatifs à accepter.
Remarque : Pour créer l'itinéraire récapitulatif sur le AWS Transit Gateway, vous devez spécifier un itinéraire statique vers une pièce jointe arbitraire dans la table de AWS Transit Gateway routage afin que le résumé soit envoyé le long de l'itinéraire le plus spécifique.
Du point de vue de la table de AWS Transit Gateway routage, les itinéraires pour le préfixe local sont reçus à la fois depuis la connexion AWS DX (viaDXGW) et depuisVPN, avec la même longueur de préfixe. Selon la logique de priorité des itinéraires de AWS Transit Gateway, les itinéraires reçus via Direct Connect ont une préférence plus élevée que ceux reçus Site-to-SiteVPN, et le chemin qui les traverse AWS Direct Connect sera donc le chemin préféré pour atteindre le ou les réseaux locaux.
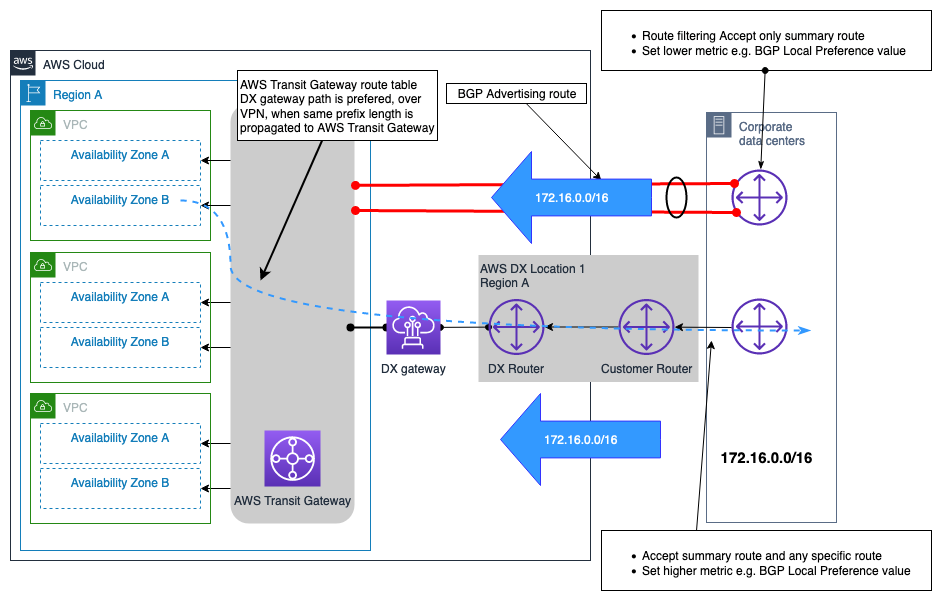
Figure 12 — Exemple de VPN connexion en tant que sauvegarde vers AWS DX
L'arbre de décision suivant vous guide dans la prise de décision souhaitée pour parvenir à une connectivité réseau hybride résiliente (qui se traduira par une connectivité réseau hybride fiable). Pour plus d'informations, reportez-vous à AWS Direct Connect Resiliency Toolkit.
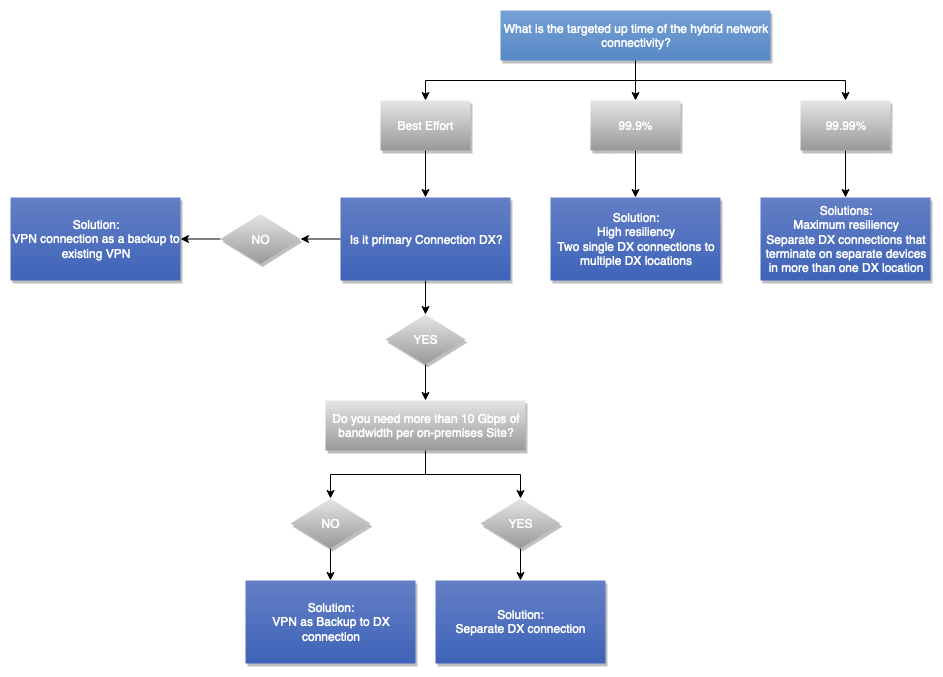
Figure 13 — Arbre décisionnel en matière de fiabilité
