Scénario 5 : surveillance des données de télémétrie en temps réel avec Apache Kafka
ABC1cabs est une société de services de réservation de taxi en ligne. Tous les taxis sont équipés d'appareils IoT qui recueillent les données de télémétrie des véhicules. Actuellement, ABC1Cabs exécute des clusters Apache Kafka conçus pour la consommation d'événements en temps réel, la collecte de métriques sur l'état du système, le suivi de l'activité et l'alimentation en données de la plateforme Apache Spark Streaming basée sur un cluster Hadoop sur site.
ABC1Cabs utilise OpenSearch Dashboards pour les métriques métier, le débogage, les alertes et la création d'autres tableaux de bord. Cette société est intéressée par Amazon MSK, par Amazon EMR avec Spark Streaming et par OpenSearch Service avec OpenSearch Dashboards. Leur exigence consiste à réduire les frais administratifs liés à la maintenance des clusters Apache Kafka et Hadoop, tout en utilisant des API et des logiciels open source familiers pour orchestrer leur pipeline de données. Le diagramme d'architecture suivant présente leur solution sur AWS.
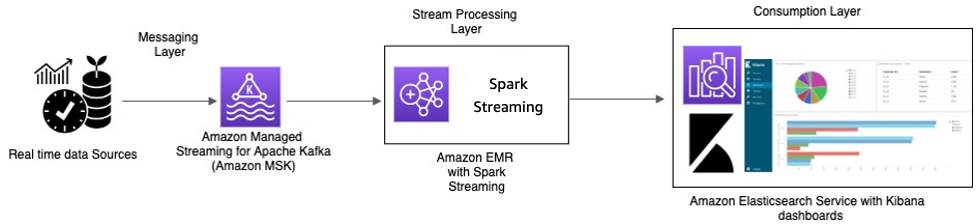
Traitement en temps réel avec Amazon MSK et traitement Stream à l'aide d'Apache Spark Streaming sur Amazon EMR et Amazon OpenSearch Service avec OpenSearch Dashboards
Les appareils IoT des taxis collectent des données de télémétrie et les envoient à un hub source. Le hub source est configuré pour envoyer des données en temps réel à Amazon MSK. À l'aide des API de la bibliothèque du producteur Apache Kafka, Amazon MSK est configuré pour diffuser les données dans un cluster Amazon EMR. Le cluster Amazon EMR possède un client Kafka et Spark Streaming installé pour pouvoir consommer et traiter les flux de données.
Spark Streaming possède des connecteurs de récepteur qui peuvent écrire des données directement dans des index définis d'Elasticsearch. Les clusters Elasticsearch OpenSearch Dashboards peuvent être utilisés pour les métriques et les tableaux de bord. Amazon MSK, Amazon EMR avec Spark Streaming et OpenSearch Service avec OpenSearch Dashboards sont tous des services gérés dans lesquels AWS s'occupe de la lourde charge de travail indifférenciée de la gestion de l'infrastructure des différents clusters, ce qui vous permet de créer votre application à l'aide de logiciels open source familiers en quelques clics. La section suivante présente ces services plus en détail.
Amazon Managed Streaming pour Apache Kafka (Amazon MSK)
Apache Kafka est une plateforme open source qui permet aux clients de capturer des données de streaming telles que des événements de flux de clics, des transactions, des événements IoT et des journaux d'application et de machine. Avec ces informations, vous pouvez développer des applications qui effectuent des analyses en temps réel, exécutent des transformations en continu et distribuent ces données aux lacs de données et aux bases de données en temps réel.
Vous pouvez utiliser Kafka en tant que magasin de données de streaming pour découpler les applications du producteur et des consommateurs et permettre un transfert de données fiable entre les deux composants. Bien que Kafka soit une plateforme de flux de données et de messagerie d'entreprise populaire, elle peut être difficile à configurer, à mettre à l'échelle et à gérer en production.
Amazon MSK se charge de ces tâches de gestion et facilite la configuration et l'exécution de Kafka, avec Apache Zookeeper, dans un environnement respectant les bonnes pratiques en matière de haute disponibilité et de sécurité. Vous pouvez toujours utiliser les opérations de plan de contrôle et les opérations de plan de données de Kafka pour gérer la production et la consommation de données.
Étant donné qu'Amazon MSK exécute et gère Apache Kafka open source, les clients peuvent facilement migrer et exécuter des applications Apache Kafka existantes sur AWS sans avoir à modifier leur code d'application.
Mise à l'échelle
Amazon MSK propose des opérations de mise à l'échelle afin que l'utilisateur puisse dimensionner activement le cluster pendant son exécution. Lors de la création d'un cluster Amazon MSK, vous pouvez spécifier le type d'instance des agents lors du lancement du cluster. Vous pouvez commencer avec quelques agents au sein d'un cluster Amazon MSK. Ensuite, à l'aide d'AWS Management Console ou de l'AWS CLI, vous pouvez augmenter le nombre d'agents (jusqu'à plusieurs centaines) par cluster.
Vous pouvez également mettre à l'échelle vos clusters en modifiant la taille ou la famille de vos agents Apache Kafka. La modification de la taille ou de la famille de vos agents vous donne la possibilité d'ajuster la capacité de calcul de votre cluster Amazon MSK en fonction de l'évolution de vos charges de travail. Utilisez la feuille de calcul Amazon MSK Sizing and Pricing
Après avoir créé le cluster Amazon MSK, vous pouvez augmenter la quantité de stockage EBS par agent, à l'exception de la diminution du stockage. Les volumes de stockage restent disponibles pendant cette opération de mise à l'échelle. Deux types d'opération de dimensionnement sont proposés : mise à l'échelle automatique et mise à l'échelle manuelle.
Amazon MSK prend en charge l'extension automatique du stockage de votre cluster en réponse à une augmentation de l'utilisation à l'aide des stratégies de mise à l'échelle automatique de l'application. Votre stratégie de mise à l'échelle automatique définit l'utilisation du disque cible et la capacité de mise à l'échelle maximale.
Le seuil d'utilisation du stockage permet à Amazon MSK de déclencher une opération de mise à l'échelle automatique. Pour augmenter le stockage à l'aide de la mise à l'échelle manuelle, attendez que le cluster soit à l'état ACTIVE. La mise à l'échelle du stockage requiert un temps de stabilisation d'au moins six heures entre les événements. Même si l'opération met immédiatement à disposition du stockage supplémentaire, le service effectue des optimisations sur votre cluster qui peuvent prendre jusqu'à 24 heures ou plus.
La durée de ces optimisations est proportionnelle à la taille de votre stockage. En outre, la réplication de plusieurs zones de disponibilité au sein d'une région AWS vous est proposée de manière à fournir une haute disponibilité.
Configuration
Amazon MSK fournit une configuration par défaut pour les agents, les rubriques et les nœuds Apache ZooKeeper. Vous pouvez également créer des configurations personnalisées et utiliser celles-ci pour créer de nouveaux clusters Amazon MSK ou pour mettre à jour des clusters existants. Lorsque vous créez un cluster MSK sans spécifier de configuration Amazon MSK personnalisée, Amazon MSK crée et utilise une configuration par défaut. Pour obtenir la liste des valeurs par défaut, consultez cette configuration Apache Kafka.
À des fins de surveillance, Amazon MSK collecte les métriques Apache Kafka et les envoie à Amazon CloudWatch, où vous pouvez les consulter. Les métriques que vous configurez pour votre cluster MSK sont automatiquement collectées et envoyées à CloudWatch. La surveillance du décalage des consommateurs vous permet d'identifier les consommateurs lents ou bloqués qui ne suivent pas les dernières données disponibles dans une rubrique. Si nécessaire, vous pouvez ensuite prendre des mesures correctives, telles que la mise à l'échelle ou le redémarrage de ces consommateurs.
Migration vers Amazon MSK
La migration depuis un site vers Amazon MSK peut être réalisée par l'intermédiaire d'une des méthodes suivantes.
-
MirrorMaker2.0 : MirrorMaker2.0 (MM2) MM2 est un moteur de réplication de données multi-cluster basé sur le cadre Apache Kafka Connect. MM2 est la combinaison d'un connecteur source Apache Kafka et d'un connecteur récepteur. Vous pouvez utiliser un cluster MM2 unique pour migrer des données entre plusieurs clusters. MM2 détecte automatiquement les nouvelles rubriques et partitions, tout en veillant à ce que les configurations de rubrique soient synchronisées entre les clusters. MM2 prend en charge les listes de contrôle d'accès de migration, les configurations de rubrique et la traduction de décalage. Pour de plus amples détails sur la migration, veuillez consulter Migration de clusters à l'aide de MirrorMaker d'Apache Kafka. MM2 est utilisé pour les cas d'utilisation liés à la réplication des configurations de rubrique et à la traduction de décalage.
-
Apache Flink : MM2 prend en charge la sémantique « au moins une fois ». Les enregistrements peuvent être dupliqués vers la destination et les consommateurs sont censés être idempotents pour traiter les enregistrements dupliqués. Dans les scénarios de type « exactement une fois », la sémantique est requise, les clients peuvent utiliser Apache Flink. Il fournit une alternative pour obtenir une sémantique de type « exactement une fois ».
Apache Flink peut également être utilisé pour les scénarios où les données nécessitent des actions de mappage ou de transformation avant d'être soumises au cluster de destination. Apache Flink fournit des connecteurs pour Apache Kafka avec des sources et des récepteurs capables de lire les données d'un cluster Apache Kafka et d'écrire sur un autre. Apache Flink peut être exécuté sur AWS en lançant un cluster Amazon EMR ou en exécutant Apache Flink en tant qu'application à l'aide d'Amazon Kinesis Data Analytics.
-
AWS Lambda : grâce au support d'Apache Kafka en tant que source d'événements pour AWS Lambda
, les clients peuvent désormais consommer les messages d'une rubrique via une fonction Lambda. Le service AWS Lambda interroge en interne les nouveaux enregistrements ou messages provenant de la source de l'événement, puis appelle de manière synchrone la fonction Lambda cible pour consommer ces messages. Lambda lit les messages par lots et fournit les lots de messages à votre fonction dans la charge utile de l'événement pour traitement. Les messages consommés peuvent ensuite être transformés et/ou écrits directement dans votre cluster Amazon MSK de destination.
Amazon EMR avec Spark Streaming
Amazon EMR
Amazon EMR fournit les capacités de Spark et peut être utilisé pour démarrer Spark Streaming afin de consommer les données de Kafka. Spark Streaming est une extension de l'API Spark principale qui permet le traitement évolutif, à haut débit et tolérant aux pannes de flux de données en direct.
Vous pouvez créer un cluster Amazon EMR à l'aide d'AWS Command Line Interface
Les données traitées peuvent être transférées vers des systèmes de fichiers, des bases de données et des tableaux de bord en direct.
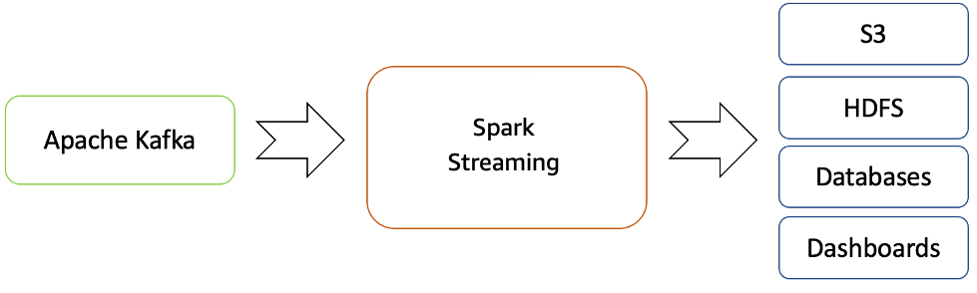
Flux de streaming en temps réel d'Apache Kafka vers l'écosystème Hadoop
Par défaut, Apache Spark Streaming possède un modèle d'exécution par micro-lots. Cependant, depuis la sortie de Spark 2.3, Apache a introduit un nouveau mode de traitement à faible latence appelé traitement continu, qui peut atteindre des latences de bout en bout d'une milliseconde avec des garanties de type « au moins une fois ».
Sans modifier les opérations Dataset/DataFrames dans vos requêtes, vous pouvez choisir le mode en fonction des exigences de votre application. Voici quelques avantages de Spark Streaming :
-
Il apporte l'API intégrée au langage
d'Apache Spark pour le traitement des flux, ce qui vous permet d'écrire des tâches de streaming de la même manière que vous écrivez des tâches par lots. -
Il prend en charge Java, Scala et Python.
-
Il peut récupérer à la fois le travail perdu et l'état de l'opérateur (comme les fenêtres coulissantes) dès le départ, sans aucun code supplémentaire de votre part.
-
En s'exécutant sur Spark, Spark Streaming vous permet de réutiliser le même code pour le traitement par lots, de joindre des flux par rapport à des données historiques ou d'exécuter des requêtes ad hoc sur l'état du flux et de créer de puissantes applications interactives, pas seulement des analyses.
-
Une fois le flux de données traité avec Spark Streaming, OpenSearch Sink Connector peut être utilisé pour écrire des données dans le cluster OpenSearch Service et, à son tour, OpenSearch Service avec OpenSearch Dashboards peut être utilisé en tant que couche de consommation.
Amazon OpenSearch Service avec OpenSearch Dashboards
OpenSearch Service est un service géré qui facilite le déploiement, l'utilisation et la mise à l'échelle des clusters OpenSearch dans le cloud AWS. OpenSearch est un moteur de recherche et d'analyse à code source libre très populaire, utilisé notamment pour l'analyse des fichiers journaux, la surveillance d'applications en temps réel et l'analyse des parcours de navigation.
OpenSearch Dashboards
OpenSearch Dashboards propose une intégration étroite avec OpenSearch
Récapitulatif
Avec Apache Kafka proposé en tant que service géré sur AWS, vous pouvez vous concentrer sur la consommation plutôt que sur la gestion de la coordination entre les agents, ce qui nécessite généralement une compréhension détaillée d'Apache Kafka. Des fonctions telles que la haute disponibilité, la capacité de mise à l'échelle des agents et le contrôle d'accès détaillé sont gérées par la plateforme Amazon MSK.
ABC1Cabs a utilisé ces services pour créer des applications de production sans avoir besoin d'une expertise en gestion d'infrastructure. Ils ont pu se concentrer sur la couche de traitement pour consommer les données d'Amazon MSK et les propager davantage vers la couche de visualisation.
Spark Streaming sur Amazon EMR peut faciliter l'analyse en temps réel des données de streaming et la publication sur OpenSearch Dashboards
