Étape 1 : Collecter et agréger des données
La figure suivante montre un modèle mental du problème de prévision. L'objectif est de prévoir la série temporelle z_t dans le futur, en utilisant autant d'informations pertinentes que possible pour rendre la prévision aussi précise que possible. Par conséquent, la première étape, et la plus importante, consiste à collecter autant de données correctes que possible.
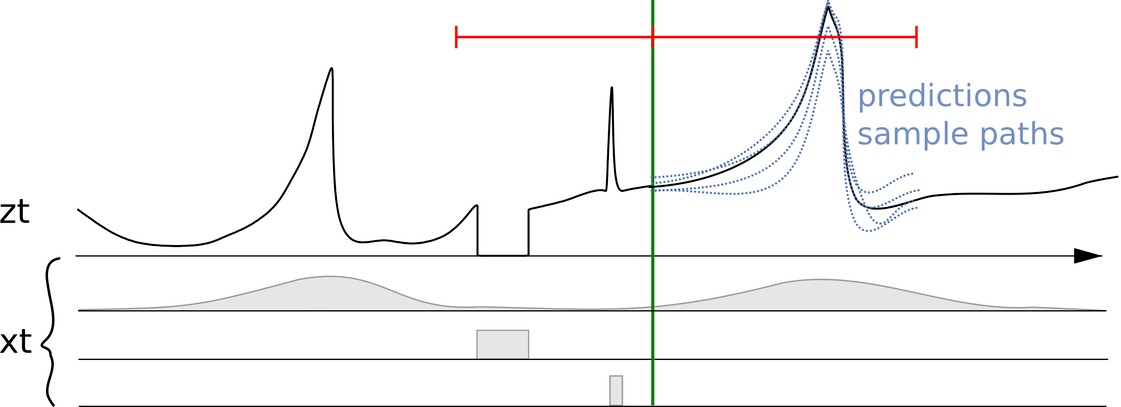
Une série temporelle z_t avec des caractéristiques ou covariables associées (x_t) et plusieurs prévisions
Dans la figure précédente, plusieurs prévisions sont affichées à droite de la ligne verticale. Ces prévisions sont des échantillons de la distribution de la prévision probabiliste (ou, inversement, peuvent être utilisées pour représenter la prévision probabiliste).
Les informations principales à enregistrer pour un commerce de détail sont les suivantes :
-
Les données de vente de la transaction : par exemple, l'unité de gestion des stocks (référence), le lieu, l'horodatage et les unités vendues.
-
Données détaillées de la référence : métadonnées d'un article. Par exemple, la couleur, le service, la taille, etc.
-
Données sur les prix : séries temporelles de prix de chaque article avec horodatage.
-
Données d'information sur les promotions : différents types de promotions, soit sur une collection d'articles (catégorie), soit sur des articles individuels avec horodatage.
-
Données d'information sur les stocks : pour chaque unité de temps, l'information indiquant si une référence était en stock ou achetable ou si elle était en rupture de stock.
-
Données de localisation : l'emplacement d'un article ou d'une vente à un moment donné peut être représenté par un
location_idou unstore_idde chaîne de caractères, ou par une géolocalisation réelle. Les géolocalisations peuvent être le code du pays plus un code postal à cinq chiffres, ou des coordonnéeslatitude_longitude. L'emplacement est considéré comme une « dimension » des ventes transactionnelles.
Dans Amazon Forecast
Notez que les informations sur les stocks sont importantes car ce problème est centré sur la demande prévue et non sur les ventes, mais l'entreprise enregistre uniquement les ventes. Lorsqu'une référence est en rupture de stock, le nombre de ventes est inférieur à la demande potentielle. Il est donc important de savoir et d'enregistrer quand de telles ruptures de stock surviennent.
Parmi les autres jeux de données à prendre en compte figurent le nombre de visites de pages Web, les détails sur les termes de recherche, les réseaux sociaux et les informations météorologiques. Il est souvent important de disposer de données pour le passé et pour l'avenir afin de pouvoir les utiliser dans des modèles. C'est une exigence de nombreux modèles de prévision et lors du processus de backtesting (décrit dans la section Étape 4 : Évaluation des prédicteurs).
Pour certains problèmes de prévision, la fréquence des données brutes correspond naturellement à celle du problème de prévision. Les exemples incluent la demande du volume du serveur, qui est échantillonné par minute, lorsque vous souhaitez effectuer des prévisions à une fréquence minute par minute.
Les données sont souvent enregistrées à une fréquence plus précise, ou simplement à des horodatages arbitraires à l'intérieur d'une plage de temps, mais le problème de la prévision concerne un niveau de granularité plus grossier. Cela se produit fréquemment dans les études de cas sur le commerce de détail, où les données de vente sont normalement enregistrées sous forme de données transactionnelles ; par exemple, le format consiste en un horodatage avec une précision fine indiquant le moment où les ventes ont eu lieu. Dans le cas d'utilisation des prévisions, ce faible niveau de granularité n'est peut-être pas nécessaire ; il peut être plus approprié d'agréger ces données en ventes horaires ou quotidiennes. Ici, le niveau d'agrégation correspond au problème en aval ; par exemple, la gestion des stocks ou la planification des ressources.
Exemple
Dans la figure suivante, le graphique de gauche présente un exemple de données brutes sur les ventes clients qui peuvent être saisies dans Amazon Forecast sous la forme d'un fichier de valeurs séparées par des virgules (CSV). Dans cet exemple, les données de vente sont définies sur une grille temporelle quotidienne plus précise, et le problème consiste à prévoir la demande hebdomadaire sur la grille temporelle plus large dans le futur. Amazon Forecast procède à l'agrégation des valeurs quotidiennes d'une semaine donnée dans le cadre de l'appel d'API create_predictor.
Le résultat transforme les données brutes en un ensemble de séries temporelles bien formées avec une fréquence hebdomadaire fixe. Le graphique de droite illustre cette agrégation sur la série temporelle cible à l'aide de la méthode d'agrégation par somme par défaut. Les autres méthodes d'agrégation incluent la moyenne, le maximum, le minimum ou le choix d'un seul point (par exemple, le premier). Le niveau de granularité et la méthode d'agrégation doivent être choisis de manière à correspondre au mieux à l'utilisation commerciale des données. Dans cet exemple, la valeur agrégée est alignée sur l'agrégation hebdomadaire. L'utilisateur peut définir d'autres méthodes d'agrégation en utilisant la clé FeaturizationMethodParameters du paramètre FeaturizationConfig de l'API create_predictor.
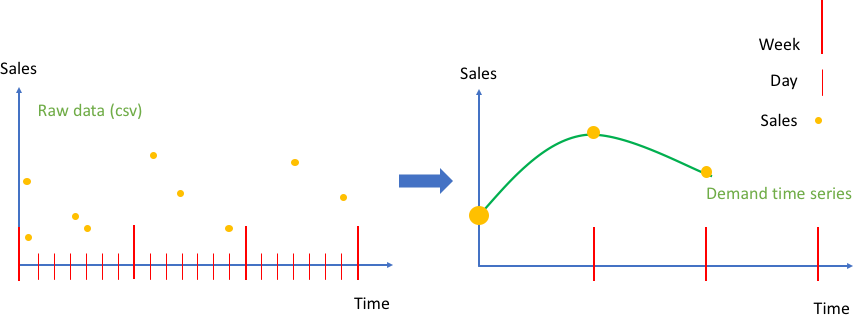
Agrégation des données de ventes brutes sous forme d'événements (à gauche), dans une série temporelle à intervalles réguliers (à droite)
