Integrating with AWS Glue Schema Registry
These sections describe integrations with AWS Glue schema registry.
The examples in these section show a schema with AVRO data format.
For more examples, including schemas with JSON data format, see the integration tests and ReadMe information in the AWS Glue Schema Registry open source repository
Topics
Use case: Connecting Schema Registry to Amazon MSK or Apache Kafka
Let's assume you are writing data to an Apache Kafka topic, and you can follow these steps to get started.
Create an Amazon Managed Streaming for Apache Kafka (Amazon MSK) or Apache Kafka cluster with at least one topic. If creating an Amazon MSK cluster, you can use the AWS Management Console. Follow these instructions: Getting Started Using Amazon MSK in the Amazon Managed Streaming for Apache Kafka Developer Guide.
Follow the Installing SerDe Libraries step above.
To create schema registries, schemas, or schema versions, follow the instructions under the Getting started with schema registry section of this document.
Start your producers and consumers to use the Schema Registry to write and read records to/from the Amazon MSK or Apache Kafka topic. Example producer and consumer code can be found in the ReadMe file
from the Serde libraries. The Schema Registry library on the producer will automatically serialize the record and decorate the record with a schema version ID. If the schema of this record has been inputted, or if auto-registration is turned on, then the schema will have been registered in the Schema Registry.
The consumer reading from the Amazon MSK or Apache Kafka topic, using the AWS Glue Schema Registry library, will automatically lookup the schema from the Schema Registry.
Use case: Integrating Amazon Kinesis Data Streams with the AWS Glue Schema Registry
This integration requires that you have an existing Amazon Kinesis data stream. For more information, see Getting Started with Amazon Kinesis Data Streams in the Amazon Kinesis Data Streams Developer Guide.
There are two ways that you can interact with data in a Kinesis data stream.
Through the Kinesis Producer Library (KPL) and Kinesis Client Library (KCL) libraries in Java. Multi-language support is not provided.
Through the
PutRecords,PutRecord, andGetRecordsKinesis Data Streams APIs available in the AWS SDK for Java.
If you currently use the KPL/KCL libraries, we recommend continuing to use that method. There are updated KCL and KPL versions with Schema Registry integrated, as shown in the examples. Otherwise, you can use the sample code to leverage the AWS Glue Schema Registry if using the KDS APIs directly.
Schema Registry integration is only available with KPL v0.14.2 or later and with KCL v2.3 or later. Schema Registry integration with JSON data format is available with KPL v0.14.8 or later and with KCL v2.3.6 or later.
Interacting with Data Using Kinesis SDK V2
This section describes interacting with Kinesis using Kinesis SDK V2
// Example JSON Record, you can construct a AVRO record also private static final JsonDataWithSchema record = JsonDataWithSchema.builder(schemaString, payloadString); private static final DataFormat dataFormat = DataFormat.JSON; //Configurations for Schema Registry GlueSchemaRegistryConfiguration gsrConfig = new GlueSchemaRegistryConfiguration("us-east-1"); GlueSchemaRegistrySerializer glueSchemaRegistrySerializer = new GlueSchemaRegistrySerializerImpl(awsCredentialsProvider, gsrConfig); GlueSchemaRegistryDataFormatSerializer dataFormatSerializer = new GlueSchemaRegistrySerializerFactory().getInstance(dataFormat, gsrConfig); Schema gsrSchema = new Schema(dataFormatSerializer.getSchemaDefinition(record), dataFormat.name(), "MySchema"); byte[] serializedBytes = dataFormatSerializer.serialize(record); byte[] gsrEncodedBytes = glueSchemaRegistrySerializer.encode(streamName, gsrSchema, serializedBytes); PutRecordRequest putRecordRequest = PutRecordRequest.builder() .streamName(streamName) .partitionKey("partitionKey") .data(SdkBytes.fromByteArray(gsrEncodedBytes)) .build(); shardId = kinesisClient.putRecord(putRecordRequest) .get() .shardId(); GlueSchemaRegistryDeserializer glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(awsCredentialsProvider, gsrConfig); GlueSchemaRegistryDataFormatDeserializer gsrDataFormatDeserializer = glueSchemaRegistryDeserializerFactory.getInstance(dataFormat, gsrConfig); GetShardIteratorRequest getShardIteratorRequest = GetShardIteratorRequest.builder() .streamName(streamName) .shardId(shardId) .shardIteratorType(ShardIteratorType.TRIM_HORIZON) .build(); String shardIterator = kinesisClient.getShardIterator(getShardIteratorRequest) .get() .shardIterator(); GetRecordsRequest getRecordRequest = GetRecordsRequest.builder() .shardIterator(shardIterator) .build(); GetRecordsResponse recordsResponse = kinesisClient.getRecords(getRecordRequest) .get(); List<Object> consumerRecords = new ArrayList<>(); List<Record> recordsFromKinesis = recordsResponse.records(); for (int i = 0; i < recordsFromKinesis.size(); i++) { byte[] consumedBytes = recordsFromKinesis.get(i) .data() .asByteArray(); Schema gsrSchema = glueSchemaRegistryDeserializer.getSchema(consumedBytes); Object decodedRecord = gsrDataFormatDeserializer.deserialize(ByteBuffer.wrap(consumedBytes), gsrSchema.getSchemaDefinition()); consumerRecords.add(decodedRecord); }
Interacting with data using the KPL/KCL libraries
This section describes integrating Kinesis Data Streams with Schema Registry using the KPL/KCL libraries. For more information on using KPL/KCL, see Developing Producers Using the Amazon Kinesis Producer Library in the Amazon Kinesis Data Streams Developer Guide.
Setting up the Schema Registry in KPL
Define the schema definition for the data, data format and schema name authored in the AWS Glue Schema Registry.
Optionally configure the
GlueSchemaRegistryConfigurationobject.Pass the schema object to the
addUserRecord API.private static final String SCHEMA_DEFINITION = "{"namespace": "example.avro",\n" + " "type": "record",\n" + " "name": "User",\n" + " "fields": [\n" + " {"name": "name", "type": "string"},\n" + " {"name": "favorite_number", "type": ["int", "null"]},\n" + " {"name": "favorite_color", "type": ["string", "null"]}\n" + " ]\n" + "}"; KinesisProducerConfiguration config = new KinesisProducerConfiguration(); config.setRegion("us-west-1") //[Optional] configuration for Schema Registry. GlueSchemaRegistryConfiguration schemaRegistryConfig = new GlueSchemaRegistryConfiguration("us-west-1"); schemaRegistryConfig.setCompression(true); config.setGlueSchemaRegistryConfiguration(schemaRegistryConfig); ///Optional configuration ends. final KinesisProducer producer = new KinesisProducer(config); final ByteBuffer data = getDataToSend(); com.amazonaws.services.schemaregistry.common.Schema gsrSchema = new Schema(SCHEMA_DEFINITION, DataFormat.AVRO.toString(), "demoSchema"); ListenableFuture<UserRecordResult> f = producer.addUserRecord( config.getStreamName(), TIMESTAMP, Utils.randomExplicitHashKey(), data, gsrSchema); private static ByteBuffer getDataToSend() { org.apache.avro.Schema avroSchema = new org.apache.avro.Schema.Parser().parse(SCHEMA_DEFINITION); GenericRecord user = new GenericData.Record(avroSchema); user.put("name", "Emily"); user.put("favorite_number", 32); user.put("favorite_color", "green"); ByteArrayOutputStream outBytes = new ByteArrayOutputStream(); Encoder encoder = EncoderFactory.get().directBinaryEncoder(outBytes, null); new GenericDatumWriter<>(avroSchema).write(user, encoder); encoder.flush(); return ByteBuffer.wrap(outBytes.toByteArray()); }
Setting up the Kinesis client library
You will develop your Kinesis Client Library consumer in Java. For more information, see Developing a Kinesis Client Library Consumer in Java in the Amazon Kinesis Data Streams Developer Guide.
Create an instance of
GlueSchemaRegistryDeserializerby passing aGlueSchemaRegistryConfigurationobject.Pass the
GlueSchemaRegistryDeserializertoretrievalConfig.glueSchemaRegistryDeserializer.Access the schema of incoming messages by calling
kinesisClientRecord.getSchema().GlueSchemaRegistryConfiguration schemaRegistryConfig = new GlueSchemaRegistryConfiguration(this.region.toString()); GlueSchemaRegistryDeserializer glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(DefaultCredentialsProvider.builder().build(), schemaRegistryConfig); RetrievalConfig retrievalConfig = configsBuilder.retrievalConfig().retrievalSpecificConfig(new PollingConfig(streamName, kinesisClient)); retrievalConfig.glueSchemaRegistryDeserializer(glueSchemaRegistryDeserializer); Scheduler scheduler = new Scheduler( configsBuilder.checkpointConfig(), configsBuilder.coordinatorConfig(), configsBuilder.leaseManagementConfig(), configsBuilder.lifecycleConfig(), configsBuilder.metricsConfig(), configsBuilder.processorConfig(), retrievalConfig ); public void processRecords(ProcessRecordsInput processRecordsInput) { MDC.put(SHARD_ID_MDC_KEY, shardId); try { log.info("Processing {} record(s)", processRecordsInput.records().size()); processRecordsInput.records() .forEach( r -> log.info("Processed record pk: {} -- Seq: {} : data {} with schema: {}", r.partitionKey(), r.sequenceNumber(), recordToAvroObj(r).toString(), r.getSchema())); } catch (Throwable t) { log.error("Caught throwable while processing records. Aborting."); Runtime.getRuntime().halt(1); } finally { MDC.remove(SHARD_ID_MDC_KEY); } } private GenericRecord recordToAvroObj(KinesisClientRecord r) { byte[] data = new byte[r.data().remaining()]; r.data().get(data, 0, data.length); org.apache.avro.Schema schema = new org.apache.avro.Schema.Parser().parse(r.schema().getSchemaDefinition()); DatumReader datumReader = new GenericDatumReader<>(schema); BinaryDecoder binaryDecoder = DecoderFactory.get().binaryDecoder(data, 0, data.length, null); return (GenericRecord) datumReader.read(null, binaryDecoder); }
Interacting with data using the Kinesis Data Streams APIs
This section describes integrating Kinesis Data Streams with Schema Registry using the Kinesis Data Streams APIs.
Update these Maven dependencies:
<dependencyManagement> <dependencies> <dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-java-sdk-bom</artifactId> <version>1.11.884</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <dependencies> <dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-java-sdk-kinesis</artifactId> </dependency> <dependency> <groupId>software.amazon.glue</groupId> <artifactId>schema-registry-serde</artifactId> <version>1.1.5</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.dataformat</groupId> <artifactId>jackson-dataformat-cbor</artifactId> <version>2.11.3</version> </dependency> </dependencies>In the producer, add schema header information using the
PutRecordsorPutRecordAPI in Kinesis Data Streams.//The following lines add a Schema Header to the record com.amazonaws.services.schemaregistry.common.Schema awsSchema = new com.amazonaws.services.schemaregistry.common.Schema(schemaDefinition, DataFormat.AVRO.name(), schemaName); GlueSchemaRegistrySerializerImpl glueSchemaRegistrySerializer = new GlueSchemaRegistrySerializerImpl(DefaultCredentialsProvider.builder().build(), new GlueSchemaRegistryConfiguration(getConfigs())); byte[] recordWithSchemaHeader = glueSchemaRegistrySerializer.encode(streamName, awsSchema, recordAsBytes);In the producer, use the
PutRecordsorPutRecordAPI to put the record into the data stream.In the consumer, remove the schema record from the header, and serialize an Avro schema record.
//The following lines remove Schema Header from record GlueSchemaRegistryDeserializerImpl glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(DefaultCredentialsProvider.builder().build(), getConfigs()); byte[] recordWithSchemaHeaderBytes = new byte[recordWithSchemaHeader.remaining()]; recordWithSchemaHeader.get(recordWithSchemaHeaderBytes, 0, recordWithSchemaHeaderBytes.length); com.amazonaws.services.schemaregistry.common.Schema awsSchema = glueSchemaRegistryDeserializer.getSchema(recordWithSchemaHeaderBytes); byte[] record = glueSchemaRegistryDeserializer.getData(recordWithSchemaHeaderBytes); //The following lines serialize an AVRO schema record if (DataFormat.AVRO.name().equals(awsSchema.getDataFormat())) { Schema avroSchema = new org.apache.avro.Schema.Parser().parse(awsSchema.getSchemaDefinition()); Object genericRecord = convertBytesToRecord(avroSchema, record); System.out.println(genericRecord); }
Interacting with data using the Kinesis Data Streams APIs
The following is example code for using the PutRecords and GetRecords APIs.
//Full sample code import com.amazonaws.services.schemaregistry.deserializers.GlueSchemaRegistryDeserializerImpl; import com.amazonaws.services.schemaregistry.serializers.GlueSchemaRegistrySerializerImpl; import com.amazonaws.services.schemaregistry.utils.AVROUtils; import com.amazonaws.services.schemaregistry.utils.AWSSchemaRegistryConstants; import org.apache.avro.Schema; import org.apache.avro.generic.GenericData; import org.apache.avro.generic.GenericDatumReader; import org.apache.avro.generic.GenericDatumWriter; import org.apache.avro.generic.GenericRecord; import org.apache.avro.io.Decoder; import org.apache.avro.io.DecoderFactory; import org.apache.avro.io.Encoder; import org.apache.avro.io.EncoderFactory; import software.amazon.awssdk.auth.credentials.DefaultCredentialsProvider; import software.amazon.awssdk.services.glue.model.DataFormat; import java.io.ByteArrayOutputStream; import java.io.File; import java.io.IOException; import java.nio.ByteBuffer; import java.util.Collections; import java.util.HashMap; import java.util.Map; public class PutAndGetExampleWithEncodedData { static final String regionName = "us-east-2"; static final String streamName = "testStream1"; static final String schemaName = "User-Topic"; static final String AVRO_USER_SCHEMA_FILE = "src/main/resources/user.avsc"; KinesisApi kinesisApi = new KinesisApi(); void runSampleForPutRecord() throws IOException { Object testRecord = getTestRecord(); byte[] recordAsBytes = convertRecordToBytes(testRecord); String schemaDefinition = AVROUtils.getInstance().getSchemaDefinition(testRecord); //The following lines add a Schema Header to a record com.amazonaws.services.schemaregistry.common.Schema awsSchema = new com.amazonaws.services.schemaregistry.common.Schema(schemaDefinition, DataFormat.AVRO.name(), schemaName); GlueSchemaRegistrySerializerImpl glueSchemaRegistrySerializer = new GlueSchemaRegistrySerializerImpl(DefaultCredentialsProvider.builder().build(), new GlueSchemaRegistryConfiguration(regionName)); byte[] recordWithSchemaHeader = glueSchemaRegistrySerializer.encode(streamName, awsSchema, recordAsBytes); //Use PutRecords api to pass a list of records kinesisApi.putRecords(Collections.singletonList(recordWithSchemaHeader), streamName, regionName); //OR //Use PutRecord api to pass single record //kinesisApi.putRecord(recordWithSchemaHeader, streamName, regionName); } byte[] runSampleForGetRecord() throws IOException { ByteBuffer recordWithSchemaHeader = kinesisApi.getRecords(streamName, regionName); //The following lines remove the schema registry header GlueSchemaRegistryDeserializerImpl glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(DefaultCredentialsProvider.builder().build(), new GlueSchemaRegistryConfiguration(regionName)); byte[] recordWithSchemaHeaderBytes = new byte[recordWithSchemaHeader.remaining()]; recordWithSchemaHeader.get(recordWithSchemaHeaderBytes, 0, recordWithSchemaHeaderBytes.length); com.amazonaws.services.schemaregistry.common.Schema awsSchema = glueSchemaRegistryDeserializer.getSchema(recordWithSchemaHeaderBytes); byte[] record = glueSchemaRegistryDeserializer.getData(recordWithSchemaHeaderBytes); //The following lines serialize an AVRO schema record if (DataFormat.AVRO.name().equals(awsSchema.getDataFormat())) { Schema avroSchema = new org.apache.avro.Schema.Parser().parse(awsSchema.getSchemaDefinition()); Object genericRecord = convertBytesToRecord(avroSchema, record); System.out.println(genericRecord); } return record; } private byte[] convertRecordToBytes(final Object record) throws IOException { ByteArrayOutputStream recordAsBytes = new ByteArrayOutputStream(); Encoder encoder = EncoderFactory.get().directBinaryEncoder(recordAsBytes, null); GenericDatumWriter datumWriter = new GenericDatumWriter<>(AVROUtils.getInstance().getSchema(record)); datumWriter.write(record, encoder); encoder.flush(); return recordAsBytes.toByteArray(); } private GenericRecord convertBytesToRecord(Schema avroSchema, byte[] record) throws IOException { final GenericDatumReader<GenericRecord> datumReader = new GenericDatumReader<>(avroSchema); Decoder decoder = DecoderFactory.get().binaryDecoder(record, null); GenericRecord genericRecord = datumReader.read(null, decoder); return genericRecord; } private Map<String, String> getMetadata() { Map<String, String> metadata = new HashMap<>(); metadata.put("event-source-1", "topic1"); metadata.put("event-source-2", "topic2"); metadata.put("event-source-3", "topic3"); metadata.put("event-source-4", "topic4"); metadata.put("event-source-5", "topic5"); return metadata; } private GlueSchemaRegistryConfiguration getConfigs() { GlueSchemaRegistryConfiguration configs = new GlueSchemaRegistryConfiguration(regionName); configs.setSchemaName(schemaName); configs.setAutoRegistration(true); configs.setMetadata(getMetadata()); return configs; } private Object getTestRecord() throws IOException { GenericRecord genericRecord; Schema.Parser parser = new Schema.Parser(); Schema avroSchema = parser.parse(new File(AVRO_USER_SCHEMA_FILE)); genericRecord = new GenericData.Record(avroSchema); genericRecord.put("name", "testName"); genericRecord.put("favorite_number", 99); genericRecord.put("favorite_color", "red"); return genericRecord; } }
Use case: Amazon Managed Service for Apache Flink
Apache Flink is a popular open source framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Amazon Managed Service for Apache Flink is a fully managed AWS service that enables you to build and manage Apache Flink applications to process streaming data.
Open source Apache Flink provides a number of sources and sinks. For example, predefined data sources include reading from files, directories, and sockets, and ingesting data from collections and iterators. Apache Flink DataStream Connectors provide code for Apache Flink to interface with various third-party systems, such as Apache Kafka or Kinesis as sources and/or sinks.
For more information, see Amazon Kinesis Data Analytics Developer Guide.
Apache Flink Kafka connector
Apache Flink provides an Apache Kafka data stream connector for reading data from and writing data to Kafka topics with exactly-once guarantees. Flink's Kafka consumer, FlinkKafkaConsumer, provides access to read from one or more Kafka topics. Apache Flink’s Kafka Producer, FlinkKafkaProducer, allows writing a stream of records to one or more Kafka topics. For more information, see Apache Kafka Connector
Apache Flink Kinesis streams Connector
The Kinesis data stream connector provides access to Amazon Kinesis Data Streams. The FlinkKinesisConsumer is an exactly-once parallel streaming data source that subscribes to multiple Kinesis streams within the same AWS service region, and can transparently handle re-sharding of streams while the job is running. Each subtask of the consumer is responsible for fetching data records from multiple Kinesis shards. The number of shards fetched by each subtask will change as shards are closed and created by Kinesis. The FlinkKinesisProducer uses Kinesis Producer Library (KPL) to put data from an Apache Flink stream into a Kinesis stream. For more information, see Amazon Kinesis Streams Connector
For more information, see the AWS Glue Schema Github
repository
Integrating with Apache Flink
The SerDes library provided with Schema Registry integrates with Apache Flink. To work with Apache Flink, you are required to implement SerializationSchemaDeserializationSchemaGlueSchemaRegistryAvroSerializationSchema and GlueSchemaRegistryAvroDeserializationSchema, which you can plug into Apache Flink connectors.
Adding an AWS Glue Schema Registry dependency into the Apache Flink application
To set up the integration dependencies to AWS Glue Schema Registry in the Apache Flink application:
Add the dependency to the
pom.xmlfile.<dependency> <groupId>software.amazon.glue</groupId> <artifactId>schema-registry-flink-serde</artifactId> <version>1.0.0</version> </dependency>
Integrating Kafka or Amazon MSK with Apache Flink
You can use Managed Service for Apache Flink for Apache Flink, with Kafka as a source or Kafka as a sink.
Kafka as a source
The following diagram shows integrating Kinesis Data Streams with Managed Service for Apache Flink for Apache Flink, with Kafka as a source.
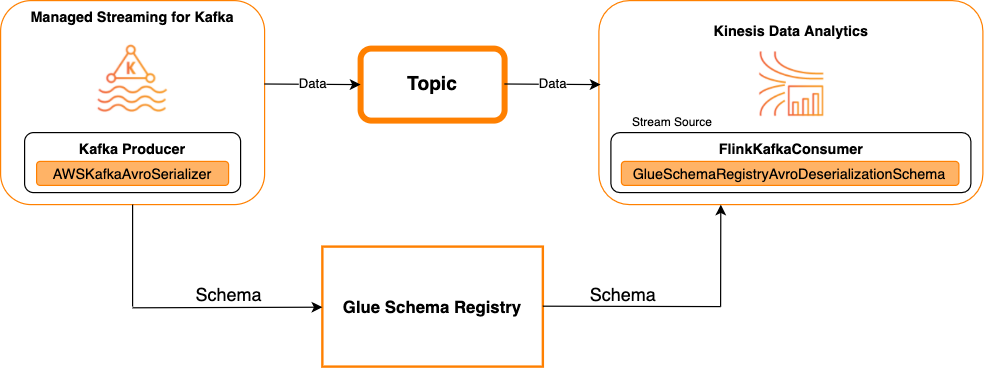
Kafka as a sink
The following diagram shows integrating Kinesis Data Streams with Managed Service for Apache Flink for Apache Flink, with Kafka as a sink.
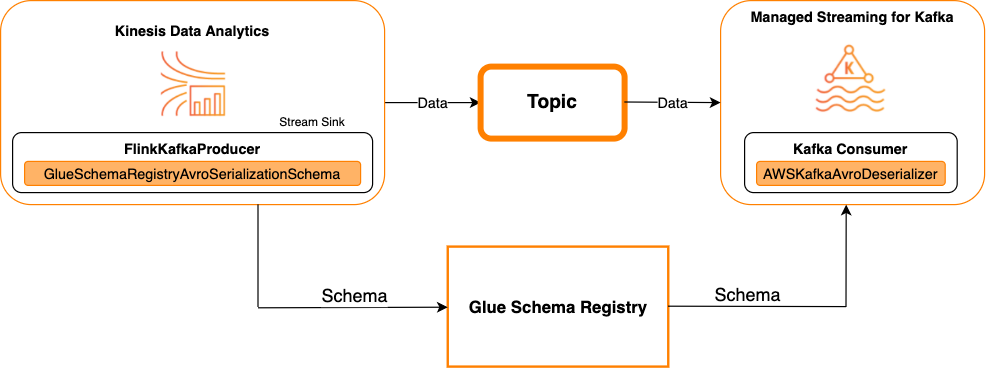
To integrate Kafka (or Amazon MSK) with Managed Service for Apache Flink for Apache Flink, with Kafka as a source or Kafka as a sink, make the code changes below. Add the bolded code blocks to your respective code in the analogous sections.
If Kafka is the source, then use the deserializer code (block 2). If Kafka is the sink, use the serializer code (block 3).
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); String topic = "topic"; Properties properties = new Properties(); properties.setProperty("bootstrap.servers", "localhost:9092"); properties.setProperty("group.id", "test"); // block 1 Map<String, Object> configs = new HashMap<>(); configs.put(AWSSchemaRegistryConstants.AWS_REGION, "aws-region"); configs.put(AWSSchemaRegistryConstants.SCHEMA_AUTO_REGISTRATION_SETTING, true); configs.put(AWSSchemaRegistryConstants.AVRO_RECORD_TYPE, AvroRecordType.GENERIC_RECORD.getName()); FlinkKafkaConsumer<GenericRecord> consumer = new FlinkKafkaConsumer<>( topic, // block 2 GlueSchemaRegistryAvroDeserializationSchema.forGeneric(schema, configs), properties); FlinkKafkaProducer<GenericRecord> producer = new FlinkKafkaProducer<>( topic, // block 3 GlueSchemaRegistryAvroSerializationSchema.forGeneric(schema, topic, configs), properties); DataStream<GenericRecord> stream = env.addSource(consumer); stream.addSink(producer); env.execute();
Integrating Kinesis Data Streams with Apache Flink
You can use Managed Service for Apache Flink for Apache Flink with Kinesis Data Streams as a source or a sink.
Kinesis Data Streams as a source
The following diagram shows integrating Kinesis Data Streams with Managed Service for Apache Flink for Apache Flink, with Kinesis Data Streams as a source.
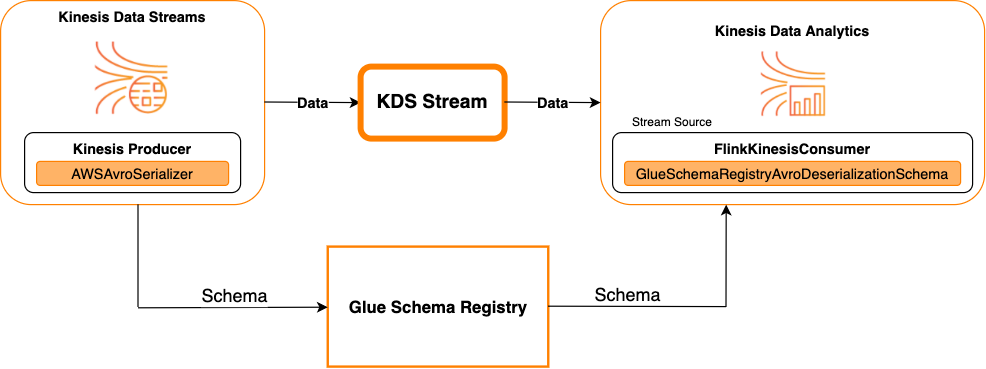
Kinesis Data Streams as a sink
The following diagram shows integrating Kinesis Data Streams with Managed Service for Apache Flink for Apache Flink, with Kinesis Data Streams as a sink.
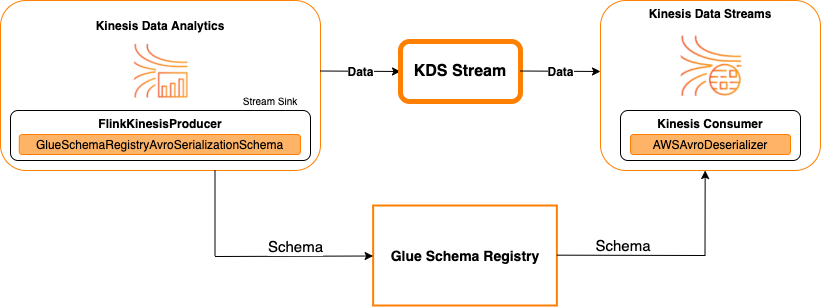
To integrate Kinesis Data Streams with Managed Service for Apache Flink for Apache Flink, with Kinesis Data Streams as a source or Kinesis Data Streams as a sink, make the code changes below. Add the bolded code blocks to your respective code in the analogous sections.
If Kinesis Data Streams is the source, use the deserializer code (block 2). If Kinesis Data Streams is the sink, use the serializer code (block 3).
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); String streamName = "stream"; Properties consumerConfig = new Properties(); consumerConfig.put(AWSConfigConstants.AWS_REGION, "aws-region"); consumerConfig.put(AWSConfigConstants.AWS_ACCESS_KEY_ID, "aws_access_key_id"); consumerConfig.put(AWSConfigConstants.AWS_SECRET_ACCESS_KEY, "aws_secret_access_key"); consumerConfig.put(ConsumerConfigConstants.STREAM_INITIAL_POSITION, "LATEST"); // block 1 Map<String, Object> configs = new HashMap<>(); configs.put(AWSSchemaRegistryConstants.AWS_REGION, "aws-region"); configs.put(AWSSchemaRegistryConstants.SCHEMA_AUTO_REGISTRATION_SETTING, true); configs.put(AWSSchemaRegistryConstants.AVRO_RECORD_TYPE, AvroRecordType.GENERIC_RECORD.getName()); FlinkKinesisConsumer<GenericRecord> consumer = new FlinkKinesisConsumer<>( streamName, // block 2 GlueSchemaRegistryAvroDeserializationSchema.forGeneric(schema, configs), properties); FlinkKinesisProducer<GenericRecord> producer = new FlinkKinesisProducer<>( // block 3 GlueSchemaRegistryAvroSerializationSchema.forGeneric(schema, topic, configs), properties); producer.setDefaultStream(streamName); producer.setDefaultPartition("0"); DataStream<GenericRecord> stream = env.addSource(consumer); stream.addSink(producer); env.execute();
Use Case: Integration with AWS Lambda
To use an AWS Lambdafunction as an Apache Kafka/Amazon MSK consumer and deserialize Avro-encoded messages using AWS Glue Schema Registry, visit the MSK Labs page
Use case: AWS Glue Data Catalog
AWS Glue tables support schemas that you can specify manually or by reference to the AWS Glue Schema Registry. The Schema Registry integrates with the Data Catalog to allow you to optionally use schemas stored in the Schema Registry when creating or updating AWS Glue tables or partitions in the Data Catalog. To identify a schema definition in the Schema Registry, at a minimum, you need to know the ARN of the schema it is part of. A schema version of a schema, which contains a schema definition, can be referenced by its UUID or version number. There is always one schema version, the "latest" version, that can be looked up without knowing its version number or UUID.
When calling the CreateTable or UpdateTable operations, you will pass a TableInput structure that contains a StorageDescriptor, which may have a SchemaReference to an existing schema in the Schema Registry. Similarly, when you call the GetTable or GetPartition APIs, the response may contain the schema and the SchemaReference. When a table or partition was created using a schema references, the Data Catalog will try to fetch the schema for this schema reference. In case it is unable to find the schema in the Schema Registry, it returns an empty schema in the GetTable response; otherwise the response will have both the schema and schema reference.
You can also perform the actions from the AWS Glue console.
To perform these operations and create, update, or view the schema information, you must give an IAM role to the calling user that provides permissions for the GetSchemaVersion API.
Adding a table or updating the schema for a table
Adding a new table from an existing schema binds the table to a specific schema version. Once new schema versions get registered, you can update this table definition from the View table page in the AWS Glue console or using the UpdateTable action (Python: update_table) API.
Adding a table from an existing schema
You can create an AWS Glue table from a schema version in the registry using the AWS Glue console or CreateTable API.
AWS Glue API
When calling the CreateTable API, you will pass a TableInput that contains a StorageDescriptor which has a SchemaReference to an existing schema in the Schema Registry.
AWS Glue console
To create a table from the AWS Glue console:
-
Sign in to the AWS Management Console and open the AWS Glue console at https://console.aws.amazon.com/glue/
. In the navigation pane, under Data catalog, choose Tables.
In the Add Tables menu, choose Add table from existing schema.
Configure the table properties and data store per the AWS Glue Developer Guide.
In the Choose a Glue schema page, select the Registry where the schema resides.
Choose the Schema name and select the Version of the schema to apply.
Review the schema preview, and choose Next.
Review and create the table.
The schema and version applied to the table appears in the Glue schema column in the list of tables. You can view the table to see more details.
Updating the schema for a table
When a new schema version becomes available, you may want to update a table's schema using the UpdateTable action (Python: update_table) API or the AWS Glue console.
Important
When updating the schema for an existing table that has an AWS Glue schema specified manually, the new schema referenced in the Schema Registry may be incompatible. This can result in your jobs failing.
AWS Glue API
When calling the UpdateTable API, you will pass a TableInput that contains a StorageDescriptor which has a SchemaReference to an existing schema in the Schema Registry.
AWS Glue console
To update the schema for a table from the AWS Glue console:
-
Sign in to the AWS Management Console and open the AWS Glue console at https://console.aws.amazon.com/glue/
. In the navigation pane, under Data catalog, choose Tables.
View the table from the list of tables.
Click Update schema in the box that informs you about a new version.
Review the differences between the current and new schema.
Choose Show all schema differences to see more details.
Choose Save table to accept the new version.
Use case: AWS Glue streaming
AWS Glue streaming consumes data from streaming sources and perform ETL operations before writing to an output sink. Input streaming source can be specified using a Data Table or directly by specifying the source configuration.
AWS Glue streaming supports a Data Catalog table for the streaming source created with the schema present in the AWS Glue Schema Registry. You can create a schema in the AWS Glue Schema Registry and create an AWS Glue table with a streaming source using this schema. This AWS Glue table can be used as an input to an AWS Glue streaming job for deserializing data in the input stream.
One point to note here is when the schema in the AWS Glue Schema Registry changes, you need to restart the AWS Glue streaming job needs to reflect the changes in the schema.
Use case: Apache Kafka Streams
The Apache Kafka Streams API is a client library for processing and analyzing data stored in Apache Kafka. This section describes the integration of Apache Kafka Streams with AWS Glue Schema Registry, which allows you to manage and enforce schemas on your data streaming applications. For more information on Apache Kafka Streams, see Apache Kafka Streams
Integrating with the SerDes Libraries
There is a GlueSchemaRegistryKafkaStreamsSerde class that you can configure a Streams application with.
Kafka Streams application example code
To use the AWS Glue Schema Registry within an Apache Kafka Streams application:
Configure the Kafka Streams application.
final Properties props = new Properties(); props.put(StreamsConfig.APPLICATION_ID_CONFIG, "avro-streams"); props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); props.put(StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG, 0); props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName()); props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, AWSKafkaAvroSerDe.class.getName()); props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); props.put(AWSSchemaRegistryConstants.AWS_REGION, "aws-region"); props.put(AWSSchemaRegistryConstants.SCHEMA_AUTO_REGISTRATION_SETTING, true); props.put(AWSSchemaRegistryConstants.AVRO_RECORD_TYPE, AvroRecordType.GENERIC_RECORD.getName()); props.put(AWSSchemaRegistryConstants.DATA_FORMAT, DataFormat.AVRO.name());Create a stream from the topic avro-input.
StreamsBuilder builder = new StreamsBuilder(); final KStream<String, GenericRecord> source = builder.stream("avro-input");Process the data records (the example filters out those records whose value of favorite_color is pink or where the value of amount is 15).
final KStream<String, GenericRecord> result = source .filter((key, value) -> !"pink".equals(String.valueOf(value.get("favorite_color")))); .filter((key, value) -> !"15.0".equals(String.valueOf(value.get("amount"))));Write the results back to the topic avro-output.
result.to("avro-output");Start the Apache Kafka Streams application.
KafkaStreams streams = new KafkaStreams(builder.build(), props); streams.start();
Implementation results
These results show the filtering process of records that were filtered out in step 3 as a favorite_color of "pink" or value of "15.0".
Records before filtering:
{"name": "Sansa", "favorite_number": 99, "favorite_color": "white"} {"name": "Harry", "favorite_number": 10, "favorite_color": "black"} {"name": "Hermione", "favorite_number": 1, "favorite_color": "red"} {"name": "Ron", "favorite_number": 0, "favorite_color": "pink"} {"name": "Jay", "favorite_number": 0, "favorite_color": "pink"} {"id": "commute_1","amount": 3.5} {"id": "grocery_1","amount": 25.5} {"id": "entertainment_1","amount": 19.2} {"id": "entertainment_2","amount": 105} {"id": "commute_1","amount": 15}
Records after filtering:
{"name": "Sansa", "favorite_number": 99, "favorite_color": "white"} {"name": "Harry", "favorite_number": 10, "favorite_color": "black"} {"name": "Hermione", "favorite_number": 1, "favorite_color": "red"} {"name": "Ron", "favorite_number": 0, "favorite_color": "pink"} {"id": "commute_1","amount": 3.5} {"id": "grocery_1","amount": 25.5} {"id": "entertainment_1","amount": 19.2} {"id": "entertainment_2","amount": 105}
Use case: Apache Kafka Connect
The integration of Apache Kafka Connect with the AWS Glue Schema Registry enables you to get schema information from connectors. The Apache Kafka converters specify the format of data within Apache Kafka and how to translate it into Apache Kafka Connect data. Every Apache Kafka Connect user will need to configure these converters based on the format they want their data in when loaded from or stored into Apache Kafka. In this way, you can define your own converters to translate Apache Kafka Connect data into the type used in the AWS Glue Schema Registry (for example: Avro) and utilize our serializer to register its schema and do serialization. Then converters are also able to use our deserializer to deserialize data received from Apache Kafka and convert it back into Apache Kafka Connect data. An example workflow diagram is given below.
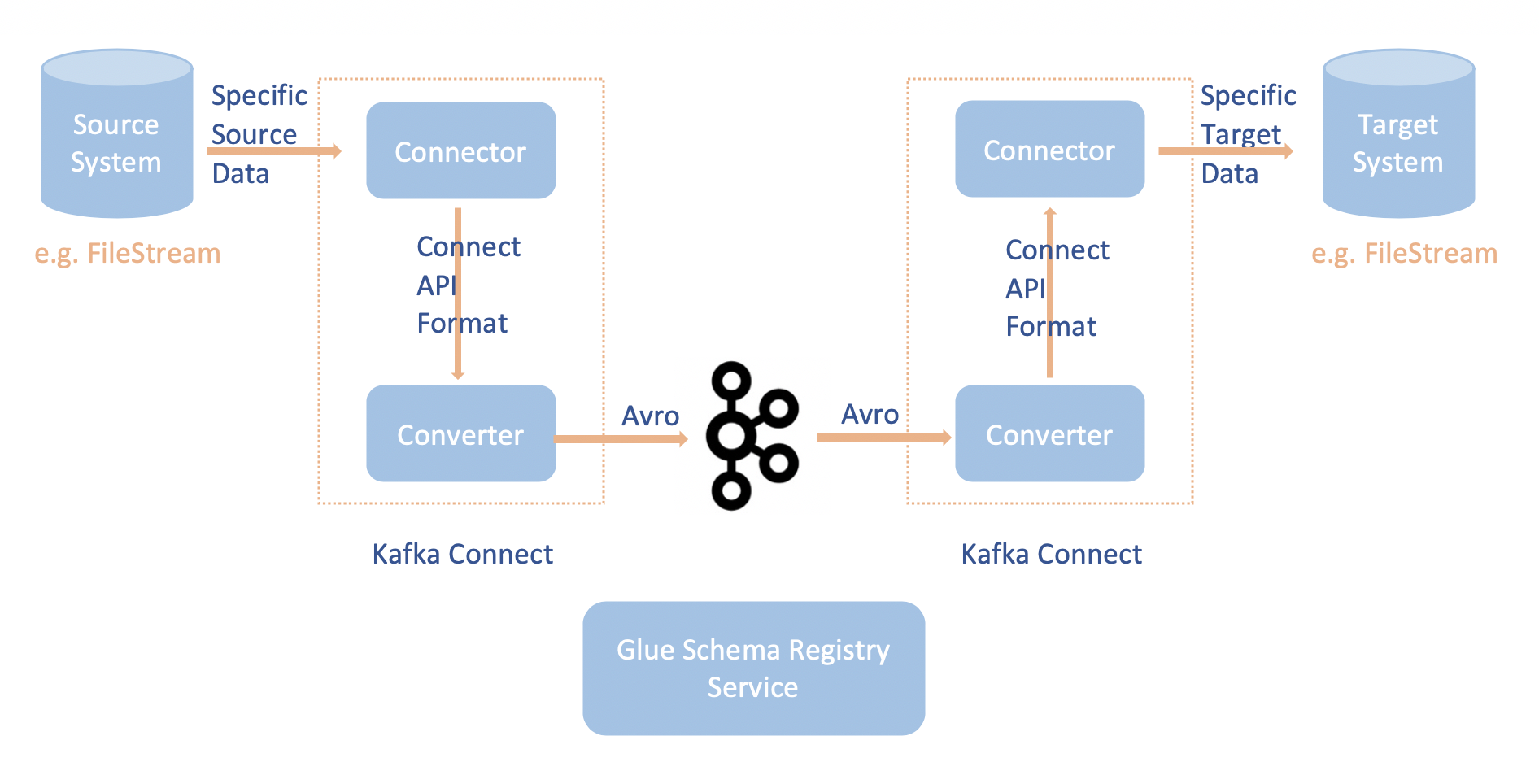
Install the
aws-glue-schema-registryproject by cloning the Github repository for the AWS Glue Schema Registry. git clone git@github.com:awslabs/aws-glue-schema-registry.git cd aws-glue-schema-registry mvn clean install mvn dependency:copy-dependenciesIf you plan on using Apache Kafka Connect in Standalone mode, update connect-standalone.properties using the instructions below for this step. If you plan on using Apache Kafka Connect in Distributed mode, update connect-avro-distributed.properties using the same instructions.
Add these properties also to the Apache Kafka connect properties file:
key.converter.region=aws-regionvalue.converter.region=aws-regionkey.converter.schemaAutoRegistrationEnabled=true value.converter.schemaAutoRegistrationEnabled=true key.converter.avroRecordType=GENERIC_RECORD value.converter.avroRecordType=GENERIC_RECORDAdd the command below to the Launch mode section under kafka-run-class.sh:
-cp $CLASSPATH:"<your AWS GlueSchema Registry base directory>/target/dependency/*"
Add the command below to the Launch mode section under kafka-run-class.sh
-cp $CLASSPATH:"<your AWS GlueSchema Registry base directory>/target/dependency/*"It should look like this:
# Launch mode if [ "x$DAEMON_MODE" = "xtrue" ]; then nohup "$JAVA" $KAFKA_HEAP_OPTS $KAFKA_JVM_PERFORMANCE_OPTS $KAFKA_GC_LOG_OPTS $KAFKA_JMX_OPTS $KAFKA_LOG4J_OPTS -cp $CLASSPATH:"/Users/johndoe/aws-glue-schema-registry/target/dependency/*" $KAFKA_OPTS "$@" > "$CONSOLE_OUTPUT_FILE" 2>&1 < /dev/null & else exec "$JAVA" $KAFKA_HEAP_OPTS $KAFKA_JVM_PERFORMANCE_OPTS $KAFKA_GC_LOG_OPTS $KAFKA_JMX_OPTS $KAFKA_LOG4J_OPTS -cp $CLASSPATH:"/Users/johndoe/aws-glue-schema-registry/target/dependency/*" $KAFKA_OPTS "$@" fiIf using bash, run the below commands to set-up your CLASSPATH in your bash_profile. For any other shell, update the environment accordingly.
echo 'export GSR_LIB_BASE_DIR=<>' >>~/.bash_profile echo 'export GSR_LIB_VERSION=1.0.0' >>~/.bash_profile echo 'export KAFKA_HOME=<your Apache Kafka installation directory>' >>~/.bash_profile echo 'export CLASSPATH=$CLASSPATH:$GSR_LIB_BASE_DIR/avro-kafkaconnect-converter/target/schema-registry-kafkaconnect-converter-$GSR_LIB_VERSION.jar:$GSR_LIB_BASE_DIR/common/target/schema-registry-common-$GSR_LIB_VERSION.jar:$GSR_LIB_BASE_DIR/avro-serializer-deserializer/target/schema-registry-serde-$GSR_LIB_VERSION.jar' >>~/.bash_profile source ~/.bash_profile(Optional) If you want to test with a simple file source, then clone the file source connector.
git clone https://github.com/mmolimar/kafka-connect-fs.git cd kafka-connect-fs/Under the source connector configuration, edit the data format to Avro, file reader to
AvroFileReaderand update an example Avro object from the file path you are reading from. For example:vim config/kafka-connect-fs.propertiesfs.uris=<path to a sample avro object> policy.regexp=^.*\.avro$ file_reader.class=com.github.mmolimar.kafka.connect.fs.file.reader.AvroFileReaderInstall the source connector.
mvn clean package echo "export CLASSPATH=\$CLASSPATH:\"\$(find target/ -type f -name '*.jar'| grep '\-package' | tr '\n' ':')\"" >>~/.bash_profile source ~/.bash_profileUpdate the sink properties under
<your Apache Kafka installation directory>/config/connect-file-sink.propertiesfile=<output file full path> topics=<my topic>
Start the Source Connector (in this example it is a file source connector).
$KAFKA_HOME/bin/connect-standalone.sh $KAFKA_HOME/config/connect-standalone.properties config/kafka-connect-fs.propertiesRun the Sink Connector (in this example it is a file sink connector).
$KAFKA_HOME/bin/connect-standalone.sh $KAFKA_HOME/config/connect-standalone.properties $KAFKA_HOME/config/connect-file-sink.propertiesFor an example Kafka Connect usage, look at the run-local-tests.sh script under integration-tests folder in the Github repository for the AWS Glue Schema Registry
.
