Export configurations for supported AWS Cloud destinations
User-defined Greengrass components use StreamManagerClient in the Stream Manager SDK to
interact with stream manager. When a component creates a stream or updates a stream, it passes a
MessageStreamDefinition object that represents stream properties, including the
export definition. The ExportDefinition object contains the export configurations
defined for the stream. Stream manager uses these export configurations to determine where and
how to export the stream.
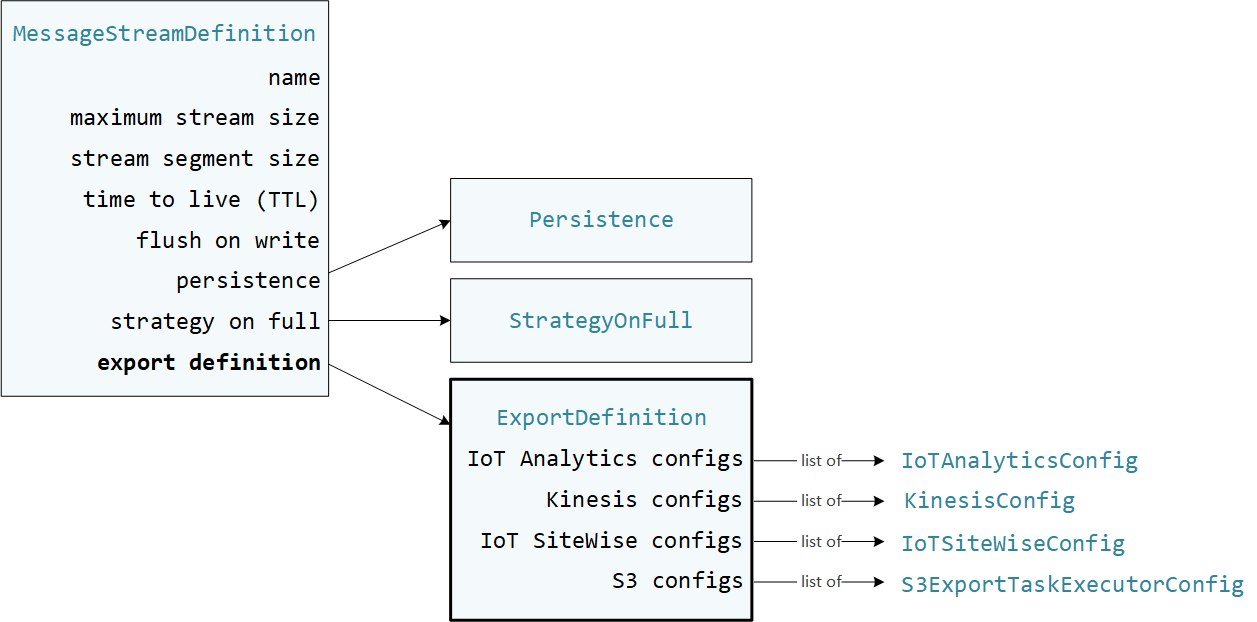
You can define zero or more export configurations on a stream, including multiple export configurations for a single destination type. For example, you can export a stream to two AWS IoT Analytics channels and one Kinesis data stream.
For failed export attempts, stream manager continually retries exporting data to the AWS Cloud at intervals of up to five minutes. The number of retry attempts doesn't have a maximum limit.
Note
StreamManagerClient also provides a target
destination you can use to export streams to an HTTP server. This target is intended for testing
purposes only. It is not stable or supported for use in production environments.
Supported AWS Cloud destinations
You are responsible for maintaining these AWS Cloud resources.
AWS IoT Analytics channels
Stream manager supports automatic exports to AWS IoT Analytics. AWS IoT Analytics lets you perform advanced analysis on your data to help make business decisions and improve machine learning models. For more information, see What is AWS IoT Analytics? in the AWS IoT Analytics User Guide.
In the Stream Manager SDK, your Greengrass components use the IoTAnalyticsConfig to define
the export configuration for this destination type. For more information, see the SDK
reference for your target language:
-
IoTAnalyticsConfig
in the Python SDK -
IoTAnalyticsConfig
in the Java SDK -
IoTAnalyticsConfig
in the Node.js SDK
Requirements
This export destination has the following requirements:
-
Target channels in AWS IoT Analytics must be in the same AWS account and AWS Region as the Greengrass core device.
-
The Authorize core devices to interact with AWS services must allow the
iotanalytics:BatchPutMessagepermission to target channels. For example:You can grant granular or conditional access to resources, for example, by using a wildcard
*naming scheme. For more information, see Adding and removing IAM policies in the IAM User Guide.
Exporting to AWS IoT Analytics
To create a stream that exports to AWS IoT Analytics, your Greengrass components create a stream with an export
definition that includes one or more IoTAnalyticsConfig objects. This object
defines export settings, such as the target channel, batch size, batch interval, and
priority.
When your Greengrass components receive data from devices, they append messages that contain a blob of data to the target stream.
Then, stream manager exports the data based on the batch settings and priority defined in the stream's export configurations.
Amazon Kinesis data streams
Stream manager supports automatic exports to Amazon Kinesis Data Streams. Kinesis Data Streams is commonly used to aggregate high-volume data and load it into a data warehouse or MapReduce cluster. For more information, see What is Amazon Kinesis Data Streams? in the Amazon Kinesis Developer Guide.
In the Stream Manager SDK, your Greengrass components use the KinesisConfig to define the
export configuration for this destination type. For more information, see the SDK reference
for your target language:
-
KinesisConfig
in the Python SDK -
KinesisConfig
in the Java SDK -
KinesisConfig
in the Node.js SDK
Requirements
This export destination has the following requirements:
-
Target streams in Kinesis Data Streams must be in the same AWS account and AWS Region as the Greengrass core device.
-
(Recommended) Starting in version 2.2.1, stream manager improves the performance of exporting streams to Kinesis Data Streams destinations. Version 2.3.1 adds adaptive, shard-aware pacing that further increases export throughput. To use these improvements, upgrade your stream manager component to the latest version. Then, grant the
kinesis:ListShardspermission in the Greengrass token exchange role. With this permission, stream manager distributes records across the shards of the target data stream and paces requests to stay within the per-shard limits of Kinesis Data Streams. -
The Authorize core devices to interact with AWS services must allow the
kinesis:PutRecordspermission to target data streams. For example:You can grant granular or conditional access to resources, for example, by using a wildcard
*naming scheme. For more information, see Adding and removing IAM policies in the IAM User Guide.
Exporting to Kinesis Data Streams
To create a stream that exports to Kinesis Data Streams, your Greengrass components create a stream with an export
definition that includes one or more KinesisConfig objects. This object defines
export settings, such as the target data stream, batch size, batch interval, and
priority.
When your Greengrass components receive data from devices, they append messages that contain a blob of data to the target stream. Then, stream manager exports the data based on the batch settings and priority defined in the stream's export configurations.
When stream manager can determine the shard layout of the target data stream, it distributes records across the available shards. Stream manager also paces requests to stay within the per-shard limits of Kinesis Data Streams. If stream manager cannot determine the shard layout, it assigns a unique, random UUID as the partition key for each record that it uploads to Amazon Kinesis.
AWS IoT SiteWise asset properties
Stream manager supports automatic exports to AWS IoT SiteWise. AWS IoT SiteWise lets you collect, organize, and analyze data from industrial equipment at scale. For more information, see What is AWS IoT SiteWise? in the AWS IoT SiteWise User Guide.
In the Stream Manager SDK, your Greengrass components use the IoTSiteWiseConfig to define
the export configuration for this destination type. For more information, see the SDK
reference for your target language:
-
IoTSiteWiseConfig
in the Python SDK -
IoTSiteWiseConfig
in the Java SDK -
IoTSiteWiseConfig
in the Node.js SDK
Note
AWS also provides AWS IoT SiteWise components, which offer a pre-built solution that you can use to stream data from OPC-UA sources. For more information, see IoT SiteWise OPC UA collector.
Requirements
This export destination has the following requirements:
-
Target asset properties in AWS IoT SiteWise must be in the same AWS account and AWS Region as the Greengrass core device.
Note
For the list of AWS Regions that AWS IoT SiteWise supports, see AWS IoT SiteWise endpoints and quotas in the AWS General Reference.
-
The Authorize core devices to interact with AWS services must allow the
iotsitewise:BatchPutAssetPropertyValuepermission to target asset properties. The following example policy uses theiotsitewise:assetHierarchyPathcondition key to grant access to a target root asset and its children. You can remove theConditionfrom the policy to allow access to all of your AWS IoT SiteWise assets or specify ARNs of individual assets.You can grant granular or conditional access to resources, for example, by using a wildcard
*naming scheme. For more information, see Adding and removing IAM policies in the IAM User Guide.For important security information, see BatchPutAssetPropertyValue authorization in the AWS IoT SiteWise User Guide.
Exporting to AWS IoT SiteWise
To create a stream that exports to AWS IoT SiteWise, your Greengrass components create a stream with an export
definition that includes one or more IoTSiteWiseConfig objects. This object
defines export settings, such as the batch size, batch interval, and priority.
When your Greengrass components receive asset property data from devices, they append messages
that contain the data to the target stream. Messages are JSON-serialized
PutAssetPropertyValueEntry objects that contain property values for one or
more asset properties. For more information, see Append message for AWS IoT SiteWise
export destinations.
Note
When you send data to AWS IoT SiteWise, your data must meet
the requirements of the BatchPutAssetPropertyValue action. For more information,
see BatchPutAssetPropertyValue in the AWS IoT SiteWise API Reference.
Then, stream manager exports the data based on the batch settings and priority defined in the stream's export configurations.
You can adjust your stream manager settings and Greengrass component logic to design your export strategy. For example:
-
For near real time exports, set low batch size and interval settings and append the data to the stream when it's received.
-
To optimize batching, mitigate bandwidth constraints, or minimize cost, your Greengrass components can pool the timestamp-quality-value (TQV) data points received for a single asset property before appending the data to the stream. One strategy is to batch entries for up to 10 different property-asset combinations, or property aliases, in one message instead of sending more than one entry for the same property. This helps stream manager to remain within AWS IoT SiteWise quotas.
Amazon S3 objects
Stream manager supports automatic exports to Amazon S3. You can use Amazon S3 to store and retrieve large amounts of data. For more information, see What is Amazon S3? in the Amazon Simple Storage Service Developer Guide.
In the Stream Manager SDK, your Greengrass components use the S3ExportTaskExecutorConfig to
define the export configuration for this destination type. For more information, see the SDK
reference for your target language:
-
S3ExportTaskExecutorConfig
in the Python SDK -
S3ExportTaskExecutorConfig
in the Java SDK -
S3ExportTaskExecutorConfig
in the Node.js SDK
Requirements
This export destination has the following requirements:
-
Target Amazon S3 buckets must be in the same AWS account as the Greengrass core device.
-
If a Lambda function that runs in Greengrass container mode writes input files to an input file directory, you must mount the directory as a volume in the container with write permissions. This ensures that the files are written to the root file system and visible to the stream manager component, which runs outside the container.
-
If a Docker container component writes input files to an input file directory, you must mount the directory as a volume in the container with write permissions. This ensures that the files are written to the root file system and visible to the stream manager component, which runs outside the container.
-
The Authorize core devices to interact with AWS services must allow the following permissions to the target buckets. For example:
You can grant granular or conditional access to resources, for example, by using a wildcard
*naming scheme. For more information, see Adding and removing IAM policies in the IAM User Guide.
Exporting to Amazon S3
To create a stream that exports to Amazon S3, your Greengrass components use the
S3ExportTaskExecutorConfig object to configure the export policy. The policy
defines export settings, such as the multipart upload threshold and priority. For Amazon S3
exports, stream manager uploads data that it reads from local files on the core device. To
initiate an upload, your Greengrass components append an export task to the target stream. The
export task contains information about the input file and target Amazon S3 object. Stream manager
runs tasks in the sequence that they are appended to the stream.
Note
The target bucket must already exist in your AWS account. If an object for the specified key doesn't exist, stream manager creates the object for you.
Stream manager uses the multipart upload threshold property, minimum part size setting, and size of the input file to determine how to upload data. The multipart upload threshold must be greater or equal to the minimum part size. If you want to upload data in parallel, you can create multiple streams.
The keys that specify your target Amazon S3 objects can include valid Java DateTimeFormatter!{timestamp: placeholders. You can use
these timestamp placeholders to partition data in Amazon S3 based on the time that the input file
data was uploaded. For example, the following key name resolves to a value such as
value}my-key/2020/12/31/data.txt.
my-key/!{timestamp:YYYY}/!{timestamp:MM}/!{timestamp:dd}/data.txt
Note
If you want to monitor the export status for a stream, first create a status stream and then configure the export stream to use it. For more information, see Monitor export tasks.
Manage input data
You can author code that IoT applications use to manage the lifecycle of the input data. The following example workflow shows how you might use Greengrass components to manage this data.
-
A local process receives data from devices or peripherals, and then writes the data to files in a directory on the core device. These are the input files for stream manager.
-
A Greengrass component scans the directory and appends an export task to the target stream when a new file is created. The task is a JSON-serialized
S3ExportTaskDefinitionobject that specifies the URL of the input file, the target Amazon S3 bucket and key, and optional user metadata. -
Stream manager reads the input file and exports the data to Amazon S3 in the order of appended tasks. The target bucket must already exist in your AWS account. If an object for the specified key doesn't exist, stream manager creates the object for you.
-
The Greengrass component reads messages from a status stream to monitor the export status. After export tasks are completed, the Greengrass component can delete the corresponding input files. For more information, see Monitor export tasks.
Monitor export tasks
You can author code that IoT applications use to monitor the status of your Amazon S3 exports. Your Greengrass components must create a status stream and then configure the export stream to write status updates to the status stream. A single status stream can receive status updates from multiple streams that export to Amazon S3.
First, create a stream to use as the status stream. You can configure the size and retention policies for the stream to control the lifespan of the status messages. For example:
-
Set
PersistencetoMemoryif you don't want to store the status messages. -
Set
StrategyOnFulltoOverwriteOldestDataso that new status messages are not lost.
Then, create or update the export stream to use the status stream. Specifically, set the
status configuration property of the stream’s S3ExportTaskExecutorConfig export
configuration. This setting tells stream manager to write status messages about the export
tasks to the status stream. In the StatusConfig object, specify the name of the
status stream and the level of verbosity. The following supported values range from least
verbose (ERROR) to most verbose (TRACE). The default is
INFO.
-
ERROR -
WARN -
INFO -
DEBUG -
TRACE
The following example workflow shows how Greengrass components might use a status stream to monitor export status.
-
As described in the previous workflow, a Greengrass component appends an export task to a stream that's configured to write status messages about export tasks to a status stream. The append operation return a sequence number that represents the task ID.
-
A Greengrass component reads messages sequentially from the status stream, and then filters the messages based on the stream name and task ID or based on an export task property from the message context. For example, the Greengrass component can filter by the input file URL of the export task, which is represented by the
S3ExportTaskDefinitionobject in the message context.The following status codes indicate that an export task has reached a completed state:
-
Success. The upload was completed successfully. -
Failure. Stream manager encountered an error, for example, the specified bucket does not exist. After resolving the issue, you can append the export task to the stream again. -
Canceled. The task was stopped because the stream or export definition was deleted, or the time-to-live (TTL) period of the task expired.
Note
The task might also have a status of
InProgressorWarning. Stream manager issues warnings when an event returns an error that doesn't affect the execution of the task. For example, a failure to clean up a partial upload returns a warning. -
-
After export tasks are completed, the Greengrass component can delete the corresponding input files.
The following example shows how a Greengrass component might read and process status messages.
