Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Kebijakan penskalaan berdasarkan Amazon SQS
penting
Informasi dan langkah-langkah berikut menunjukkan cara menghitung backlog antrean Amazon SQS per instance menggunakan atribut antrian sebelum mempublikasikannya sebagai metrik kustom. ApproximateNumberOfMessages CloudWatch Namun, Anda sekarang dapat menghemat biaya dan upaya untuk menerbitkan metrik Anda sendiri dengan menggunakan matematika metrik. Untuk informasi selengkapnya, lihat Membuat kebijakan penskalaan pelacakan target menggunakan matematika metrik.
Anda dapat menskalakan grup Auto Scaling sebagai respons terhadap perubahan pemuatan sistem dalam antrian Amazon Simple Queue Service (Amazon SQS). Untuk mempelajari lebih lanjut tentang cara menggunakan Amazon SQS, lihat Panduan Pengembang Amazon Simple Queue Service.
Ada beberapa skenario di mana Anda mungkin berpikir tentang penskalaan sebagai respons terhadap aktivitas dalam antrean Amazon SQS. Misalnya, kita asumsikan Anda memiliki aplikasi web yang memungkinkan pengguna mengunggah gambar dan menggunakannya secara online. Dalam skenario ini, setiap gambar perlu mengubah ukuran dan mengenkodekannya sebelum dapat diterbitkan. Aplikasi ini berjalan pada EC2 instance dalam grup Auto Scaling, dan dikonfigurasi untuk menangani kecepatan upload tipikal Anda. Instance yang tidak sehat dihentikan dan diganti untuk memelihara tingkat instance saat ini setiap saat. Aplikasi ini menempatkan data gambar bitmap mentah dalam antrean SQS untuk pemrosesan. Aplikasi ini memproses gambar dan menerbitkan gambar yang diproses di mana gambar tersebut dapat dilihat oleh pengguna. Arsitektur untuk skenario ini berfungsi dengan baik jika jumlah pengunggahan gambar tidak bervariasi dari waktu ke waktu. Tetapi jika jumlah unggahan berubah dari waktu ke waktu, Anda dapat mempertimbangkan menggunakan penskalaan dinamis untuk menskalakan kapasitas grup Auto Scaling Anda.
Daftar Isi
Gunakan pelacakan target dengan metrik yang tepat
Jika Anda menggunakan kebijakan penskalaan pelacakan target berdasarkan metrik antrean Amazon SQS kustom, penskalaan dinamis dapat menyesuaikan kurva permintaan aplikasi Anda secara lebih efektif. Untuk informasi selengkapnya tentang memilih metrik untuk pelacakan target, lihat Pilih metrik.
Masalah dengan menggunakan metrik CloudWatch Amazon SQS seperti ApproximateNumberOfMessagesVisible untuk pelacakan target adalah bahwa jumlah pesan dalam antrian mungkin tidak berubah secara proporsional dengan ukuran grup Auto Scaling yang memproses pesan dari antrian. Hal itu karena jumlah pesan dalam antrean SQS Anda tidak hanya menentukan jumlah instance yang diperlukan. Jumlah instance dalam grup Auto Scaling Anda dapat didorong oleh beberapa faktor, termasuk berapa lama waktu yang diperlukan untuk memproses pesan dan jumlah latensi yang dapat diterima (penundaan antrean).
Solusinya adalah menggunakan metrik backlog per instance dengan nilai target menjadi backlog yang dapat diterima per instance untuk dipertahankan. Anda dapat menghitung angka-angka ini sebagai berikut:
-
Backlog per instance: Untuk menghitung backlog per instance, mulailah dengan atribut
ApproximateNumberOfMessagesantrian untuk menentukan panjang antrian SQS (jumlah pesan yang tersedia untuk diambil dari antrian). Bagi jumlahnya berdasarkan kapasitas berjalan fleet, yang untuk grup Auto Scaling adalah jumlah instance dalam statusInService, untuk mendapatkan backlog per instance. -
Backlog yang dapat diterima per instance: Untuk menghitung nilai target Anda, tentukan terlebih dahulu apa yang dapat diterima aplikasi Anda dalam hal latensi. Kemudian, ambil nilai latensi yang dapat diterima dan bagi dengan waktu rata-rata yang dibutuhkan sebuah EC2 instance untuk memproses pesan.
Sebagai contoh, katakanlah Anda saat ini memiliki grup Auto Scaling dengan 10 instance dan jumlah pesan yang terlihat dalam antrian () ApproximateNumberOfMessages adalah 1500. Jika waktu pemrosesan rata-rata adalah 0,1 detik untuk setiap pesan dan latensi terpanjang yang dapat diterima adalah 10 detik, maka backlog yang dapat diterima per instance adalah 10/0,1, yang sama dengan 100 pesan. Ini berarti bahwa 100 adalah nilai target untuk kebijakan pelacakan target Anda. Ketika backlog per instance mencapai nilai target, peristiwa scale-out akan terjadi. Karena backlog per instance sudah 150 pesan (1500 pesan/10 instance), grup Anda akan ditingkatkan, dan diskalakan oleh lima instance untuk mempertahankan proporsi dengan nilai target.
Prosedur berikut mendemonstrasikan cara mempublikasikan metrik khusus dan membuat kebijakan penskalaan pelacakan target yang mengonfigurasi grup Auto Scaling Anda ke skala berdasarkan perhitungan ini.
penting
Ingat, untuk mengurangi biaya, gunakan matematika metrik sebagai gantinya. Untuk informasi selengkapnya, lihat Membuat kebijakan penskalaan pelacakan target menggunakan matematika metrik.
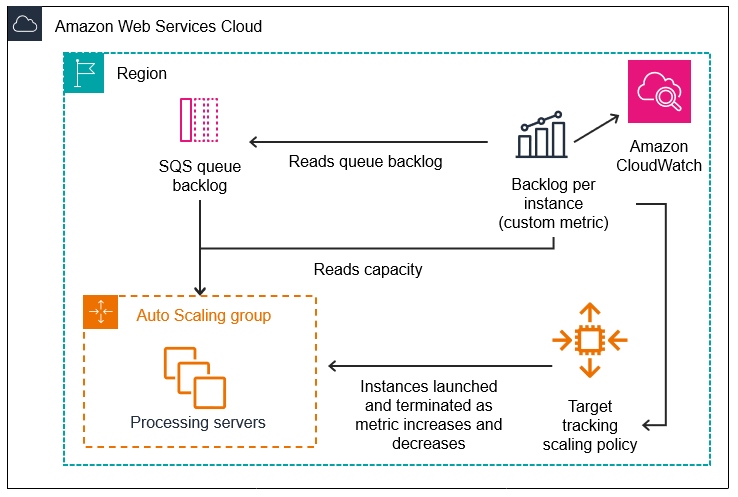
Ada tiga bagian utama untuk konfigurasi ini:
-
Grup Auto Scaling untuk mengelola EC2 instance untuk tujuan memproses pesan dari antrian SQS.
-
Metrik khusus untuk dikirim ke Amazon CloudWatch yang mengukur jumlah pesan dalam antrian per EC2 instance di grup Auto Scaling.
-
Kebijakan pelacakan target yang mengonfigurasi grup Auto Scaling Anda untuk menskalakan berdasarkan metrik kustom dan nilai target yang ditetapkan. CloudWatch alarm memanggil kebijakan penskalaan.
Diagram berikut menggambarkan arsitektur konfigurasi ini.
Batasan
Anda harus menggunakan AWS CLI atau SDK untuk mempublikasikan metrik kustom Anda. CloudWatch Anda kemudian dapat memantau metrik Anda dengan AWS Management Console.
Di bagian berikut Anda menggunakan AWS CLI untuk tugas yang perlu Anda lakukan. Misalnya, untuk mendapatkan data metrik yang mencerminkan penggunaan antrean saat ini, Anda menggunakan perintah SQS get-queue-attributes
Amazon SQS dan perlindungan penskalaan instans
Pesan yang belum diproses pada saat instance dihentikan dikembalikan ke antrian SQS di mana mereka dapat diproses oleh instance lain yang masih berjalan. Untuk aplikasi yang menjalankan tugas yang berjalan lama, Anda dapat menggunakan perlindungan skala masuk instans secara opsional untuk mengontrol pekerja antrian mana yang dihentikan saat grup Auto Scaling Anda masuk.
Pseudocode berikut menunjukkan satu cara untuk melindungi proses pekerja berbasis antrian yang berjalan lama dari penghentian skala.
while (true) { SetInstanceProtection(False); Work = GetNextWorkUnit(); SetInstanceProtection(True); ProcessWorkUnit(Work); SetInstanceProtection(False); }
Untuk informasi selengkapnya, lihat Rancang aplikasi Anda untuk menangani penghentian instans dengan anggun.
