Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Pesawat Kontrol EKS
Amazon Elastic Kubernetes Service (EKS) adalah layanan Kubernetes terkelola yang memudahkan Anda menjalankan Kubernetes di AWS tanpa perlu menginstal, mengoperasikan, dan memelihara pesawat kontrol Kubernetes atau node pekerja Anda sendiri. Ini berjalan di hulu Kubernetes dan bersertifikat kesesuaian Kubernetes. Kesesuaian ini memastikan bahwa EKS mendukung KubernetesAPIs, seperti versi komunitas sumber terbuka yang dapat Anda instal di atau di tempat. EC2 Aplikasi yang ada yang berjalan di Kubernetes upstream kompatibel dengan Amazon EKS.
EKS secara otomatis mengelola ketersediaan dan skalabilitas node bidang kontrol Kubernetes, dan secara otomatis menggantikan node bidang kontrol yang tidak sehat.
Arsitektur EKS
Arsitektur EKS dirancang untuk menghilangkan titik kegagalan tunggal yang dapat membahayakan ketersediaan dan daya tahan bidang kontrol Kubernetes.
Pesawat kontrol Kubernetes yang dikelola oleh EKS berjalan di dalam VPC yang dikelola EKS. Bidang kontrol EKS terdiri dari node server API Kubernetes, klaster etcd. Node server API Kubernetes yang menjalankan komponen seperti server API, scheduler, dan berjalan kube-controller-manager dalam grup auto-scaling. EKS menjalankan minimal dua node server API di Availability Zones (AZs) yang berbeda di dalam wilayah AWS. Demikian juga, untuk daya tahan, node server etcd juga berjalan dalam grup auto-scaling yang mencakup tiga. AZs EKS menjalankan NAT Gateway di setiap AZ, dan server API dan server etcd berjalan di subnet pribadi. Arsitektur ini memastikan bahwa peristiwa dalam satu AZ tidak memengaruhi ketersediaan kluster EKS.
Saat Anda membuat klaster baru, Amazon EKS membuat titik akhir yang sangat tersedia untuk server API Kubernetes terkelola yang Anda gunakan untuk berkomunikasi dengan klaster Anda (menggunakan alat seperti). kubectl Endpoint terkelola menggunakan NLB untuk load balance Kubernetes API server. EKS juga menyediakan dua ENI berbeda AZs untuk memfasilitasi komunikasi ke node pekerja Anda.
EKS Konektivitas jaringan pesawat data
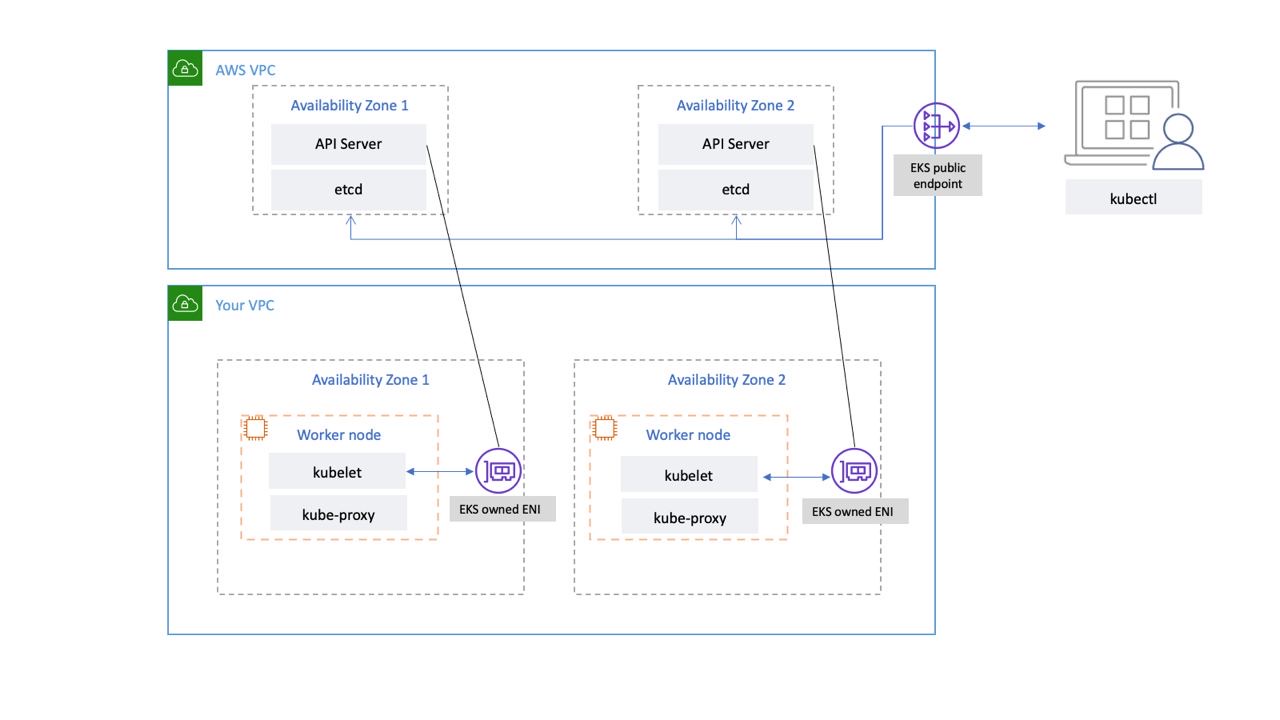
Anda dapat mengonfigurasi apakah server API klaster Kubernetes Anda dapat dijangkau dari internet publik (menggunakan titik akhir publik) atau melalui VPC Anda (menggunakan yang dikelola EKS) atau keduanya. ENIs
Baik pengguna dan node pekerja terhubung ke server API menggunakan titik akhir publik atau ENI yang dikelola EKS, ada jalur redundan untuk koneksi.
Rekomendasi
Tinjau rekomendasi berikut.
Monitor Metrik Bidang Kontrol
Memantau metrik API Kubernetes dapat memberi Anda wawasan tentang kinerja bidang kontrol dan mengidentifikasi masalah. Bidang kontrol yang tidak sehat dapat membahayakan ketersediaan beban kerja yang berjalan di dalam cluster. Misalnya, pengontrol yang ditulis dengan buruk dapat membebani server API, memengaruhi ketersediaan aplikasi Anda.
Kubernetes mengekspos metrik bidang kontrol di titik akhir. /metrics
Anda dapat melihat metrik yang diekspos menggunakankubectl:
kubectl get --raw /metrics
Metrik ini direpresentasikan dalam format teks Prometheus
Anda dapat menggunakan Prometheus untuk mengumpulkan dan menyimpan metrik ini. Pada Mei 2020, CloudWatch menambahkan dukungan untuk memantau metrik Prometheus di Wawasan Kontainer. CloudWatch Jadi Anda juga dapat menggunakan Amazon CloudWatch untuk memantau bidang kontrol EKS. Anda dapat menggunakan Tutorial untuk Menambahkan Target Scrape Prometheus Baru: Metrik Server Prometheus KPI untuk mengumpulkan metrik dan membuat dasbor untuk memantau bidang kontrol cluster Anda. CloudWatch
Anda dapat menemukan metrik server API Kubernetes di sini.apiserver_request_duration_seconds dapat menunjukkan berapa lama permintaan API dijalankan.
Pertimbangkan untuk memantau metrik bidang kontrol ini:
Server API
| Metrik | Deskripsi |
|---|---|
|
|
Penghitung permintaan apiserver dipecah untuk setiap kata kerja, nilai dry run, grup, versi, sumber daya, ruang lingkup, komponen, dan kode respons HTTP. |
|
|
Histogram latensi respons dalam hitungan detik untuk setiap kata kerja, nilai dry run, grup, versi, sumber daya, subsumber daya, ruang lingkup, dan komponen. |
|
|
Histogram latensi pengontrol penerimaan dalam hitungan detik, diidentifikasi berdasarkan nama dan dipecah untuk setiap operasi dan sumber daya API dan jenis (memvalidasi atau mengakui). |
|
|
Hitungan penerimaan penolakan webhook. Diidentifikasi berdasarkan nama, operasi, rejection_code, jenis (memvalidasi atau mengakui), error_type (calling_webhook_error, apiserver_internal_error, no_error) |
|
|
Minta histogram latensi dalam hitungan detik. Diuraikan berdasarkan kata kerja dan URL. |
|
|
Jumlah permintaan HTTP, dipartisi berdasarkan kode status, metode, dan host. |
-
Metrik histogram mencakup sufiks _bucket, _sum, dan _count.
etcd
| Metrik | Deskripsi |
|---|---|
|
|
Etcd meminta histogram latensi dalam hitungan detik untuk setiap operasi dan jenis objek. |
|
|
Ukuran database Etcd. |
-
Metrik histogram mencakup sufiks _bucket, _sum, dan _count.
Pertimbangkan untuk menggunakan Dasbor Ikhtisar Pemantauan Kubernetes
penting
Ketika batas ukuran database terlampaui, etcd memancarkan alarm tanpa ruang dan berhenti mengambil permintaan tulis lebih lanjut. Dengan kata lain, klaster menjadi hanya-baca, dan semua permintaan untuk mengubah objek seperti membuat pod baru, penyebaran skala, dll., akan ditolak oleh server API klaster.
Otentikasi Cluster
EKS saat ini mendukung dua jenis otentikasi: token akun bearer/service dan autentikasi IAM yang menggunakan otentikasi token
Pengguna IAM atau peran yang membuat EKS Cluster secara otomatis mendapatkan akses penuh ke cluster. Anda dapat mengelola akses ke cluster EKS dengan mengedit configmap aws-auth.
Jika Anda salah mengonfigurasi aws-auth configmap dan kehilangan akses ke cluster, Anda masih dapat menggunakan pengguna atau peran pembuat klaster untuk mengakses kluster EKS Anda.
Jika Anda tidak dapat menggunakan layanan IAM di wilayah AWS, Anda juga dapat menggunakan token pembawa akun layanan Kubernetes untuk mengelola klaster.
Buat super-admin akun yang diizinkan untuk melakukan semua tindakan di cluster:
kubectl -n kube-system create serviceaccount super-admin
Buat pengikatan peran yang memberikan peran cluster-admin super-admin:
kubectl create clusterrolebinding super-admin-rb --clusterrole=cluster-admin --serviceaccount=kube-system:super-admin
Dapatkan rahasia akun layanan:
SECRET_NAME=`kubectl -n kube-system get serviceaccount/super-admin -o jsonpath='{.secrets[0].name}'`
Dapatkan token yang terkait dengan rahasia:
TOKEN=`kubectl -n kube-system get secret $SECRET_NAME -o jsonpath='{.data.token}'| base64 --decode`
Tambahkan akun layanan dan token kekubeconfig:
kubectl config set-credentials super-admin --token=$TOKEN
Atur konteks saat ini kubeconfig untuk menggunakan akun super-admin:
kubectl config set-context --current --user=super-admin
Final kubeconfig akan terlihat seperti ini:
apiVersion: v1 clusters: - cluster: certificate-authority-data:<REDACTED> server: https://<CLUSTER>.gr7.us-west-2.eks.amazonaws.com name: arn:aws:eks:us-west-2:<account number>:cluster/<cluster name> contexts: - context: cluster: arn:aws:eks:us-west-2:<account number>:cluster/<cluster name> user: super-admin name: arn:aws:eks:us-west-2:<account number>:cluster/<cluster name> current-context: arn:aws:eks:us-west-2:<account number>:cluster/<cluster name> kind: Config preferences: {} users: #- name: arn:aws:eks:us-west-2:<account number>:cluster/<cluster name> # user: # exec: # apiVersion: client.authentication.k8s.io/v1beta1 # args: # - --region # - us-west-2 # - eks # - get-token # - --cluster-name # - <<cluster name>> # command: aws # env: null - name: super-admin user: token: <<super-admin sa's secret>>
Penerimaan Webhooks
Kubernetes memiliki dua jenis webhook penerimaan: memvalidasi webhook masuk dan memutasi webhook masuk
Untuk menghindari dampak operasi kritis klaster, hindari pengaturan webhook “catch-all” seperti berikut:
- name: "pod-policy.example.com" rules: - apiGroups: ["*"] apiVersions: ["*"] operations: ["*"] resources: ["*"] scope: "*"
Atau pastikan webhook memiliki kebijakan buka yang gagal dengan batas waktu lebih pendek dari 30 detik untuk memastikan bahwa jika webhook Anda tidak tersedia, itu tidak akan mengganggu beban kerja kritis klaster.
Blokir Pod dengan tidak aman sysctls
Sysctladalah utilitas Linux yang memungkinkan pengguna untuk memodifikasi parameter kernel selama runtime. Parameter kernel ini mengontrol berbagai aspek perilaku sistem operasi, seperti jaringan, sistem file, memori virtual, dan manajemen proses.
Kubernetes memungkinkan sysctl penetapan profil untuk Pod. Kubernetes dikategorikan sebagai aman systcls dan tidak aman. Safe sysctls adalah namespaced di container atau Pod, dan menyetelnya tidak berdampak pada Pod lain pada node atau node itu sendiri. Sebaliknya, sysctl yang tidak aman dinonaktifkan secara default karena berpotensi mengganggu Pod lain atau membuat node tidak stabil.
Karena unsafe dinonaktifkan sysctls secara default, kubelet tidak akan membuat Pod dengan profil yang tidak aman. sysctl Jika Anda membuat Pod seperti itu, scheduler akan berulang kali menetapkan Pod tersebut ke node, sementara node gagal meluncurkannya. Loop tak terbatas ini akhirnya membebani bidang kontrol cluster, membuat cluster tidak stabil.
Pertimbangkan untuk menggunakan OPA Gatekeepersysctls
Menangani Upgrade Cluster
Sejak April 2021, siklus rilis Kubernetes telah diubah dari empat rilis setahun (sekali seperempat) menjadi tiga rilis setahun. Versi minor baru (seperti 1. 21 atau 1. 22) dirilis kira-kira setiap lima belas minggu
Konektivitas Titik Akhir Cluster
Saat bekerja dengan Amazon EKS (Elastic Kubernetes Service), Anda mungkin mengalami batas waktu koneksi atau kesalahan selama peristiwa seperti penskalaan atau patching bidang kontrol Kubernetes. Peristiwa ini dapat menyebabkan instance kube-apiserver diganti, berpotensi mengakibatkan alamat IP yang berbeda dikembalikan saat menyelesaikan FQDN. Dokumen ini menguraikan praktik terbaik bagi konsumen API Kubernetes untuk menjaga konektivitas yang andal.
catatan
Menerapkan praktik terbaik ini mungkin memerlukan pembaruan pada konfigurasi atau skrip klien untuk menangani resolusi ulang DNS baru dan mencoba lagi strategi secara efektif.
Masalah utama berasal dari cache sisi klien DNS dan potensi alamat IP basi dari titik akhir EKS - NLB publik untuk titik akhir publik atau X-ENI untuk titik akhir pribadi. Ketika instans kube-apiserver diganti, Fully Qualified Domain Name (FQDN) dapat diselesaikan ke alamat IP baru. Namun, karena pengaturan DNS Time to Live (TTL), yang diatur ke 60 detik di zona Route 53 AWS yang dikelola AWS, klien dapat terus menggunakan alamat IP yang sudah ketinggalan zaman untuk waktu yang singkat.
Untuk mengatasi masalah ini, konsumen Kubernetes API (seperti kubectl, CI/CD pipelines, dan aplikasi kustom) harus menerapkan praktik terbaik berikut:
-
Menerapkan resolusi ulang DNS
-
Implementasikan Retries dengan Backoff dan Jitter. Misalnya, lihat artikel ini berjudul Kegagalan
Terjadi -
Menerapkan Timeout Klien. Tetapkan batas waktu yang sesuai untuk mencegah permintaan yang berjalan lama memblokir aplikasi Anda. Ketahuilah bahwa beberapa pustaka klien Kubernetes, terutama yang dihasilkan oleh generator OpenAPI, mungkin tidak mengizinkan pengaturan batas waktu kustom dengan mudah.
-
Contoh 1 dengan kubectl:
kubectl get pods --request-timeout 10s # default: no timeout
-
Contoh 2 dengan Python: Klien Kubernetes
menyediakan parameter _request_timeout
-
Dengan menerapkan praktik terbaik ini, Anda dapat secara signifikan meningkatkan keandalan dan ketahanan aplikasi Anda saat berinteraksi dengan Kubernetes API. Ingatlah untuk menguji implementasi ini secara menyeluruh, terutama di bawah kondisi kegagalan simulasi, untuk memastikan implementasi tersebut berperilaku seperti yang diharapkan selama peristiwa penskalaan atau penambalan aktual.
Menjalankan cluster besar
EKS secara aktif memonitor beban pada instans bidang kontrol dan secara otomatis menskalakannya untuk memastikan kinerja tinggi. Namun, Anda harus memperhitungkan potensi masalah dan batasan kinerja dalam Kubernetes dan kuota di layanan AWS saat menjalankan klaster besar.
-
Cluster dengan lebih dari 1000 layanan dapat mengalami latensi jaringan dengan menggunakan
kube-proxydalamiptablesmode sesuai dengan tes yang dilakukan oleh tim. ProjectCalico Solusinya adalah beralih ke kube-proxyipvsmode berjalan. -
Anda juga dapat mengalami pembatasan permintaan EC2 API jika CNI perlu meminta alamat IP untuk Pod atau jika Anda perlu sering membuat instance baru EC2 . Anda dapat mengurangi panggilan EC2 API dengan mengonfigurasi CNI untuk menyimpan alamat IP cache. Anda dapat menggunakan jenis EC2 instans yang lebih besar untuk mengurangi peristiwa EC2 penskalaan.
Sumber Daya Tambahan:
