Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Optimalisasi Biaya - Jaringan
Sistem arsitektur untuk ketersediaan tinggi (HA) adalah praktik terbaik untuk mencapai ketahanan dan toleransi kesalahan. Dalam praktiknya, ini berarti menyebarkan beban kerja Anda dan infrastruktur yang mendasarinya di beberapa Availability Zone (AZs) di Wilayah AWS tertentu. Memastikan karakteristik ini tersedia untuk lingkungan Amazon EKS Anda akan meningkatkan keandalan keseluruhan sistem Anda. Sehubungan dengan ini, lingkungan EKS Anda kemungkinan juga akan terdiri dari berbagai konstruksi (yaitu VPCs), komponen (yaitu ELBs), dan integrasi (yaitu ECR dan pendaftar kontainer lainnya).
Kombinasi sistem yang sangat tersedia dan komponen spesifik kasus penggunaan lainnya dapat memainkan peran penting dalam bagaimana data ditransfer dan diproses. Ini pada gilirannya akan berdampak pada biaya yang dikeluarkan karena transfer dan pemrosesan data.
Praktik yang dirinci di bawah ini akan membantu Anda merancang dan mengoptimalkan lingkungan EKS Anda untuk mencapai efektivitas biaya untuk berbagai domain dan kasus penggunaan.
Komunikasi Pod ke Pod
Bergantung pada penyiapan Anda, komunikasi jaringan dan transfer data antar Pod dapat berdampak signifikan terhadap keseluruhan biaya menjalankan beban kerja Amazon EKS. Bagian ini akan mencakup berbagai konsep dan pendekatan untuk mengurangi biaya yang terkait dengan komunikasi antar-pod, sambil mempertimbangkan arsitektur, kinerja aplikasi, dan ketahanan yang sangat tersedia (HA).
Membatasi Lalu Lintas ke Availability Zone
Proyek Kubernetes sejak awal mulai mengembangkan konstruksi sadar topologi termasuk label seperti kubernetes. io/hostname, topology.kubernetes.io/region, and topology.kubernetes.io/zoneditugaskan ke node untuk mengaktifkan fitur seperti distribusi beban kerja di seluruh domain kegagalan dan penyedia volume sadar topologi. Setelah lulus di Kubernetes 1.17, label juga dimanfaatkan untuk mengaktifkan kemampuan routing yang sadar topologi untuk komunikasi Pod ke Pod.
Di bawah ini adalah beberapa strategi tentang cara mengontrol jumlah lalu lintas lintas AZ antar Pod di klaster EKS Anda untuk mengurangi biaya dan meminimalkan latensi.
Jika Anda ingin visibilitas granular ke dalam jumlah lalu lintas lintas AZ antar Pod di klaster Anda (seperti jumlah data yang ditransfer dalam byte), lihat
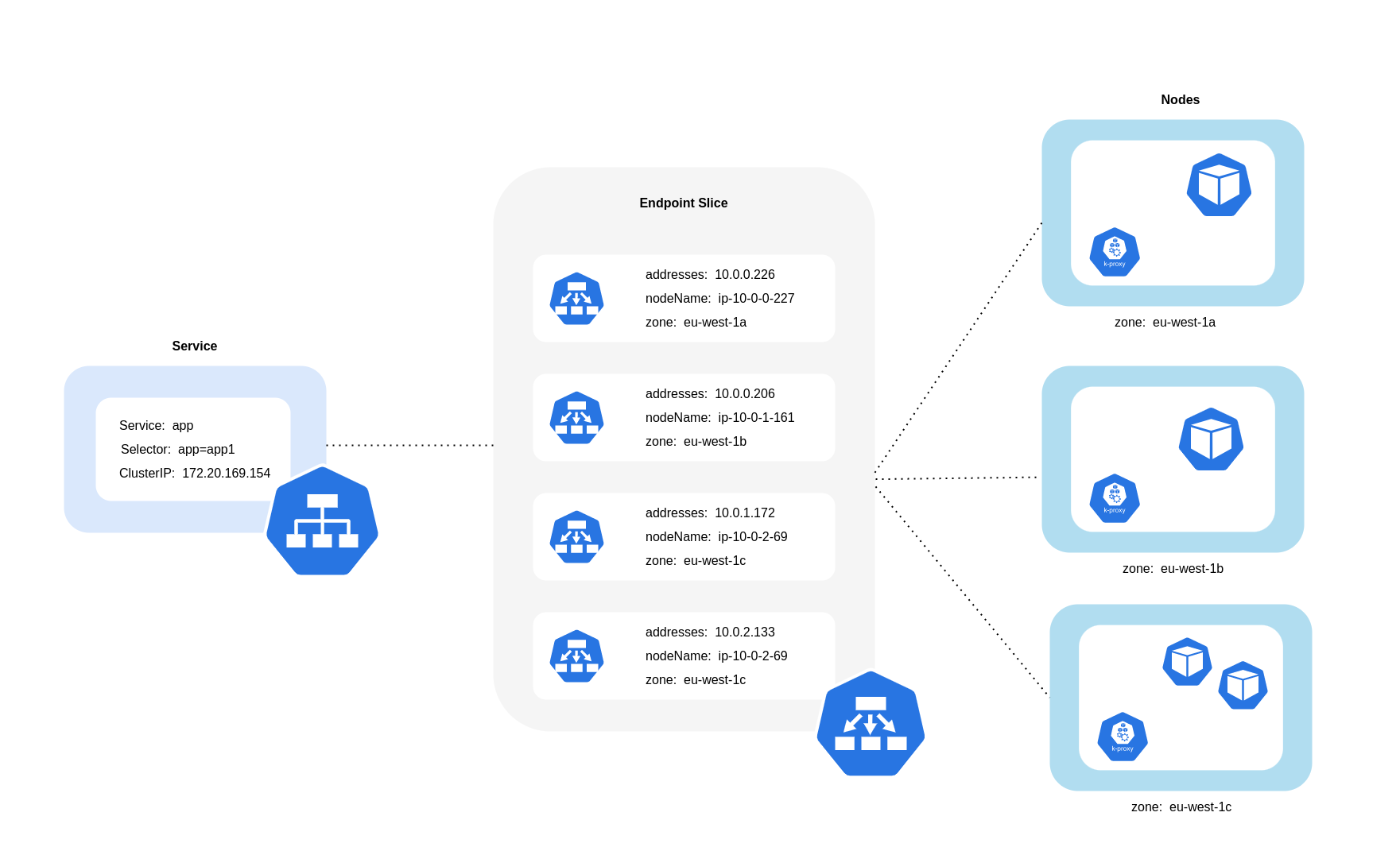
Seperti yang digambarkan diagram di atas, Layanan adalah lapisan abstraksi jaringan stabil yang menerima lalu lintas yang ditujukan untuk Pod Anda. Ketika Layanan dibuat, beberapa EndpointSlices dibuat. Masing-masing EndpointSlice memiliki daftar titik akhir yang berisi subset alamat Pod bersama dengan node yang mereka jalankan dan informasi topologi tambahan. Saat menggunakan Amazon VPC CNI, kube-proxy, daemonset yang berjalan di setiap node, mempertahankan aturan jaringan untuk mengaktifkan komunikasi Pod dan penemuan Layanan (berbasis EBPF CNIs alternatif mungkin tidak menggunakan kube-proxy tetapi memberikan perilaku yang setara). Ini memenuhi peran perutean internal, tetapi melakukannya berdasarkan apa yang dikonsumsi dari yang dibuat. EndpointSlices
Di EKS, kube-proxy terutama menggunakan aturan NAT iptables (atau IPVS, NFTables
Menggunakan Topology Aware Routing (sebelumnya dikenal sebagai Topology Aware Hints)
Ketika routing sadar topologikube-proxykemudian akan merutekan lalu lintas dari zona ke titik akhir berdasarkan petunjuk yang diterapkan.
Diagram di bawah ini menunjukkan bagaimana EndpointSlices dengan petunjuk diatur sedemikian rupa sehingga kube-proxy dapat mengetahui tujuan apa yang harus mereka tuju berdasarkan titik asal zona mereka. Tanpa petunjuk, tidak ada alokasi atau organisasi seperti itu dan lalu lintas akan diproksi ke tujuan zona yang berbeda terlepas dari mana asalnya.
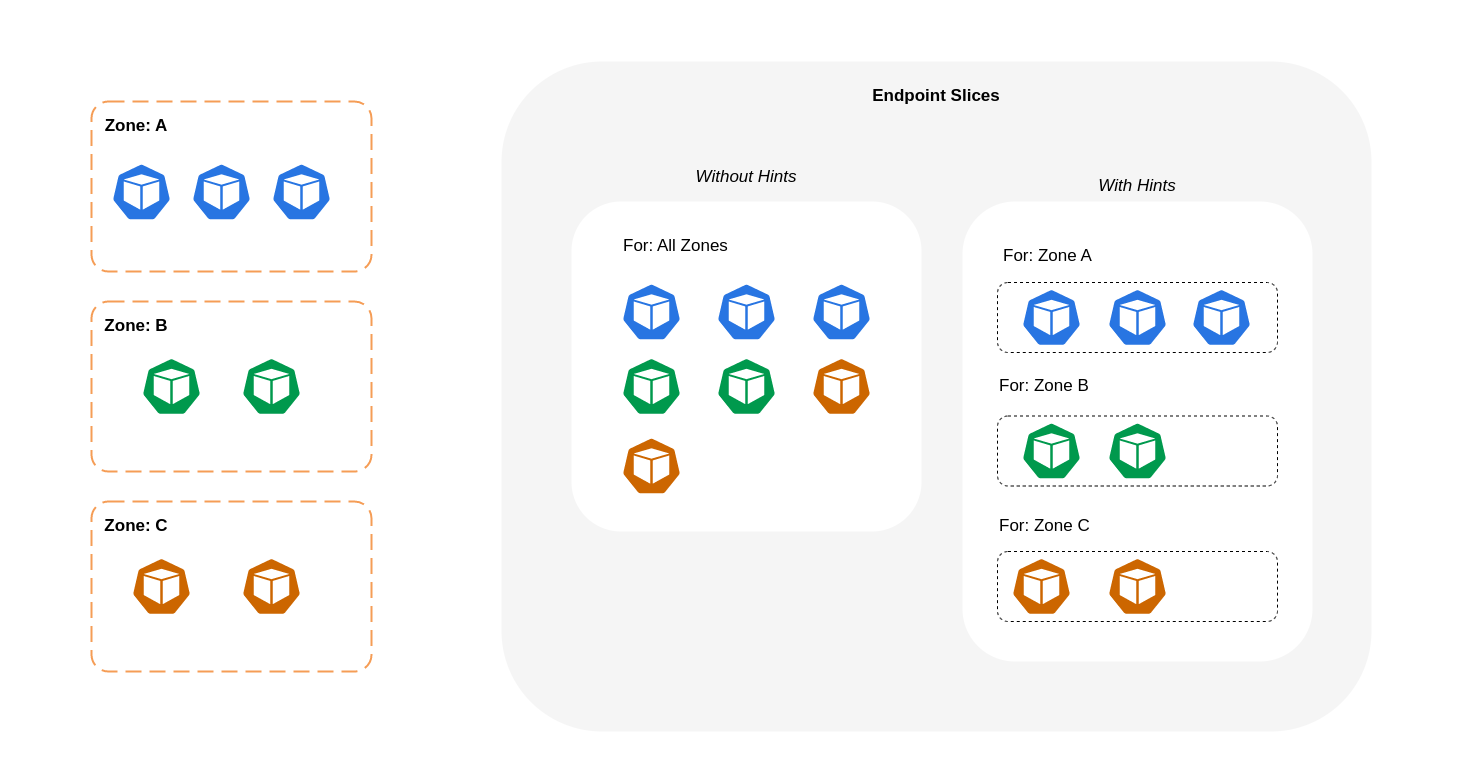
Dalam beberapa kasus, EndpointSlice pengontrol dapat menerapkan petunjuk untuk zona yang berbeda, yang berarti titik akhir dapat berakhir melayani lalu lintas yang berasal dari zona yang berbeda. Alasan untuk ini adalah untuk mencoba dan mempertahankan distribusi lalu lintas yang merata antara titik akhir di zona yang berbeda.
Di bawah ini adalah cuplikan kode tentang cara mengaktifkan perutean sadar topologi untuk Layanan.
apiVersion: v1 kind: Service metadata: name: orders-service namespace: ecommerce annotations: service.kubernetes.io/topology-mode: Auto spec: selector: app: orders type: ClusterIP ports: * protocol: TCP port: 3003 targetPort: 3003
Tangkapan layar di bawah ini menunjukkan hasil dari EndpointSlice controller yang telah berhasil menerapkan petunjuk ke titik akhir untuk replika Pod yang berjalan di AZ. eu-west-1a
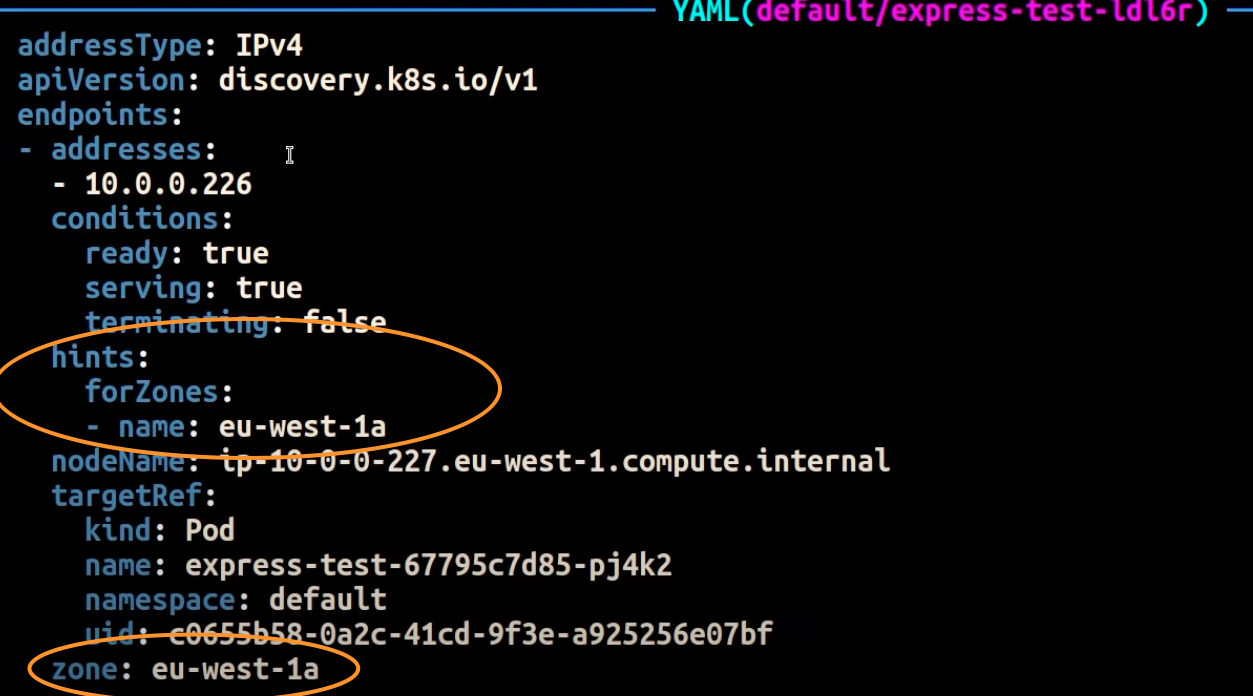
catatan
Penting untuk dicatat bahwa perutean sadar topologi masih dalam versi beta. Fitur ini bekerja lebih dapat diprediksi dengan beban kerja yang didistribusikan secara merata di seluruh topologi cluster, karena pengontrol mengalokasikan titik akhir secara proporsional di seluruh zona tetapi dapat melewati penetapan petunjuk ketika sumber daya node di zona terlalu tidak seimbang untuk menghindari kelebihan beban yang berlebihan. Oleh karena itu, sangat disarankan untuk menggunakannya bersamaan dengan kendala penjadwalan yang meningkatkan ketersediaan aplikasi seperti kendala penyebaran topologi pod.
Menggunakan Distribusi Lalu Lintas
Diperkenalkan di Kubernetes 1.30 dan tersedia secara umum di 1.33, Traffic Distribution menawarkan alternatif yang lebih sederhana untuk Topology Aware Routing untuk preferensi lalu lintas
Di bawah ini adalah cuplikan kode tentang cara mengaktifkan distribusi lalu lintas untuk Layanan.
apiVersion: v1 kind: Service metadata: name: orders-service namespace: ecommerce spec: trafficDistribution: PreferClose selector: app: orders type: ClusterIP ports: * protocol: TCP port: 3003 targetPort: 3003
Saat mengaktifkan Distribusi Lalu Lintas, tantangan umum muncul: titik akhir dalam satu AZ dapat menjadi kelebihan beban jika sebagian besar lalu lintas berasal dari zona yang sama. Kelebihan beban ini dapat menimbulkan masalah signifikan:
-
Satu Horizontal Pod Autoscaler (HPA) yang mengelola penerapan Multi-AZ dapat merespons dengan menskalakan pod di berbagai jenis. AZs Namun, tindakan ini gagal untuk secara efektif mengatasi peningkatan beban di zona yang terkena dampak.
-
Situasi ini pada gilirannya dapat menyebabkan inefisiensi sumber daya. Ketika autoscaler cluster seperti Karpenter mendeteksi penskalaan pod secara berbeda AZs, mereka dapat menyediakan node tambahan di tempat yang tidak terpengaruh, menghasilkan alokasi sumber daya yang tidak AZs perlu.
Untuk mengatasi tantangan ini:
-
Buat penerapan terpisah per zona yang akan memiliki skala sendiri HPAs untuk diskalakan secara independen satu sama lain.
-
Manfaatkan Batasan Penyebaran Topologi untuk memastikan distribusi beban kerja di seluruh klaster, yang membantu mencegah kelebihan titik akhir di zona lalu lintas tinggi.
Menggunakan Autoscaler: Menyediakan Node ke AZ Tertentu
Kami sangat menyarankan untuk menjalankan beban kerja Anda di lingkungan yang sangat tersedia di beberapa AZs tempat. Ini meningkatkan keandalan aplikasi Anda, terutama ketika ada insiden masalah dengan AZ. Jika Anda bersedia mengorbankan keandalan demi mengurangi biaya terkait jaringan mereka, Anda dapat membatasi node Anda ke satu AZ.
Untuk menjalankan semua Pod Anda di AZ yang sama, berikan node worker di AZ yang sama atau jadwalkan Pod pada node pekerja yang berjalan pada AZ yang sama. Untuk menyediakan node dalam satu AZ, tentukan grup node dengan subnet milik AZ yang sama dengan Cluster Autoscalertopology.kubernetes.io/zone dan tentukan AZ tempat Anda ingin membuat node pekerja. Misalnya, cuplikan penyedia Karpenter di bawah ini menyediakan node di us-west-2a AZ.
Karpenter
apiVersion: karpenter.sh/v1 kind: Provisioner metadata: name: single-az spec: requirements: * key: "topology.kubernetes.io/zone"` operator: In values: ["us-west-2a"]
Cluster Autoscaler (CA)
apiVersion: eksctl.io/v1alpha5 kind: ClusterConfig metadata: name: my-ca-cluster region: us-east-1 version: "1.21" availabilityZones: * us-east-1a managedNodeGroups: * name: managed-nodes labels: role: managed-nodes instanceType: t3.medium minSize: 1 maxSize: 10 desiredCapacity: 1 ...
Menggunakan Pod Assignment dan Node Affinity
Atau, jika Anda memiliki node pekerja yang berjalan dalam beberapa AZs, setiap node akan memiliki label topology.kubernetes.io/zone dengan nilai AZ-nya (seperti us-west-2a atau us-west-2bnodeSelector atau nodeAffinity menjadwalkan Pod ke node dalam satu AZ. Misalnya, file manifes berikut akan menjadwalkan Pod di dalam sebuah node yang berjalan di AZ us-west-2a.
apiVersion: v1 kind: Pod metadata: name: nginx labels: env: test spec: nodeSelector: topology.kubernetes.io/zone: us-west-2a containers: * name: nginx image: nginx imagePullPolicy: IfNotPresent
Membatasi Lalu Lintas ke Node
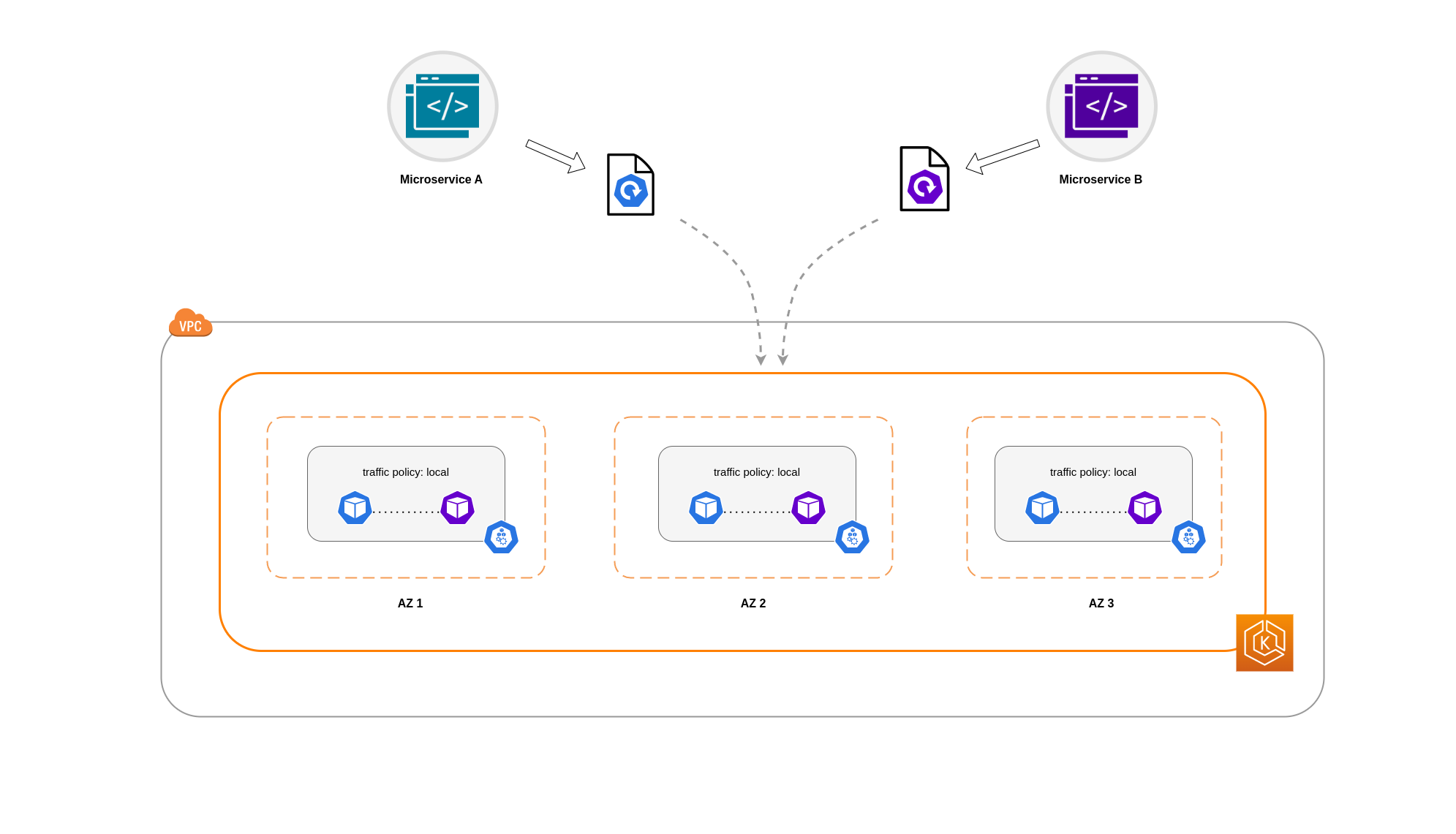
Ada kasus di mana membatasi lalu lintas di tingkat zona tidak cukup. Selain mengurangi biaya, Anda mungkin memiliki persyaratan tambahan untuk mengurangi latensi jaringan antara aplikasi tertentu yang sering melakukan komunikasi antar. Untuk mencapai kinerja jaringan yang optimal dan mengurangi biaya, Anda memerlukan cara untuk membatasi lalu lintas ke node tertentu. Misalnya, Microservice A harus selalu berbicara dengan Microservice B di Node 1, bahkan dalam pengaturan (HA) yang sangat tersedia. Memiliki Microservice A pada Node 1 berbicara dengan Microservice B pada Node 2 mungkin berdampak negatif pada kinerja yang diinginkan untuk aplikasi seperti ini, terutama jika Node 2 berada di AZ terpisah sama sekali.
Menggunakan Kebijakan Lalu Lintas Internal Layanan
Untuk membatasi lalu lintas jaringan Pod ke sebuah node, Anda dapat menggunakan kebijakan lalu lintas internal LayananLocal, lalu lintas akan dibatasi ke titik akhir pada node tempat lalu lintas berasal. Kebijakan ini menentukan penggunaan eksklusif titik akhir node-lokal. Implikasinya, biaya terkait lalu lintas jaringan Anda untuk beban kerja itu akan lebih rendah daripada jika distribusinya luas. Selain itu, latensi akan lebih rendah, membuat aplikasi Anda lebih berkinerja.
catatan
Penting untuk dicatat bahwa fitur ini tidak dapat digabungkan dengan perutean sadar topologi di Kubernetes.
Di bawah ini adalah cuplikan kode tentang cara mengatur kebijakan lalu lintas internal untuk Layanan.
apiVersion: v1 kind: Service metadata: name: orders-service namespace: ecommerce spec: selector: app: orders type: ClusterIP ports: * protocol: TCP port: 3003 targetPort: 3003 internalTrafficPolicy: Local
Untuk menghindari perilaku tak terduga dari aplikasi Anda karena penurunan lalu lintas, Anda harus mempertimbangkan pendekatan berikut:
-
Jalankan replika yang cukup untuk setiap Pod yang berkomunikasi
-
Memiliki penyebaran Pod yang relatif merata menggunakan kendala penyebaran topologi
-
Memanfaatkan aturan pod-affinity
untuk co-lokasi Pod yang berkomunikasi
Dalam contoh ini, Anda memiliki 2 replika Microservice A dan 3 replika Microservice B. Jika Microservice A memiliki replika yang tersebar antara Nodes 1 dan 2, dan Microservice B memiliki semua 3 replika pada Node 3, maka mereka tidak akan dapat berkomunikasi karena kebijakan lalu lintas internal. Local Ketika tidak ada titik akhir node-lokal yang tersedia, lalu lintas dijatuhkan.
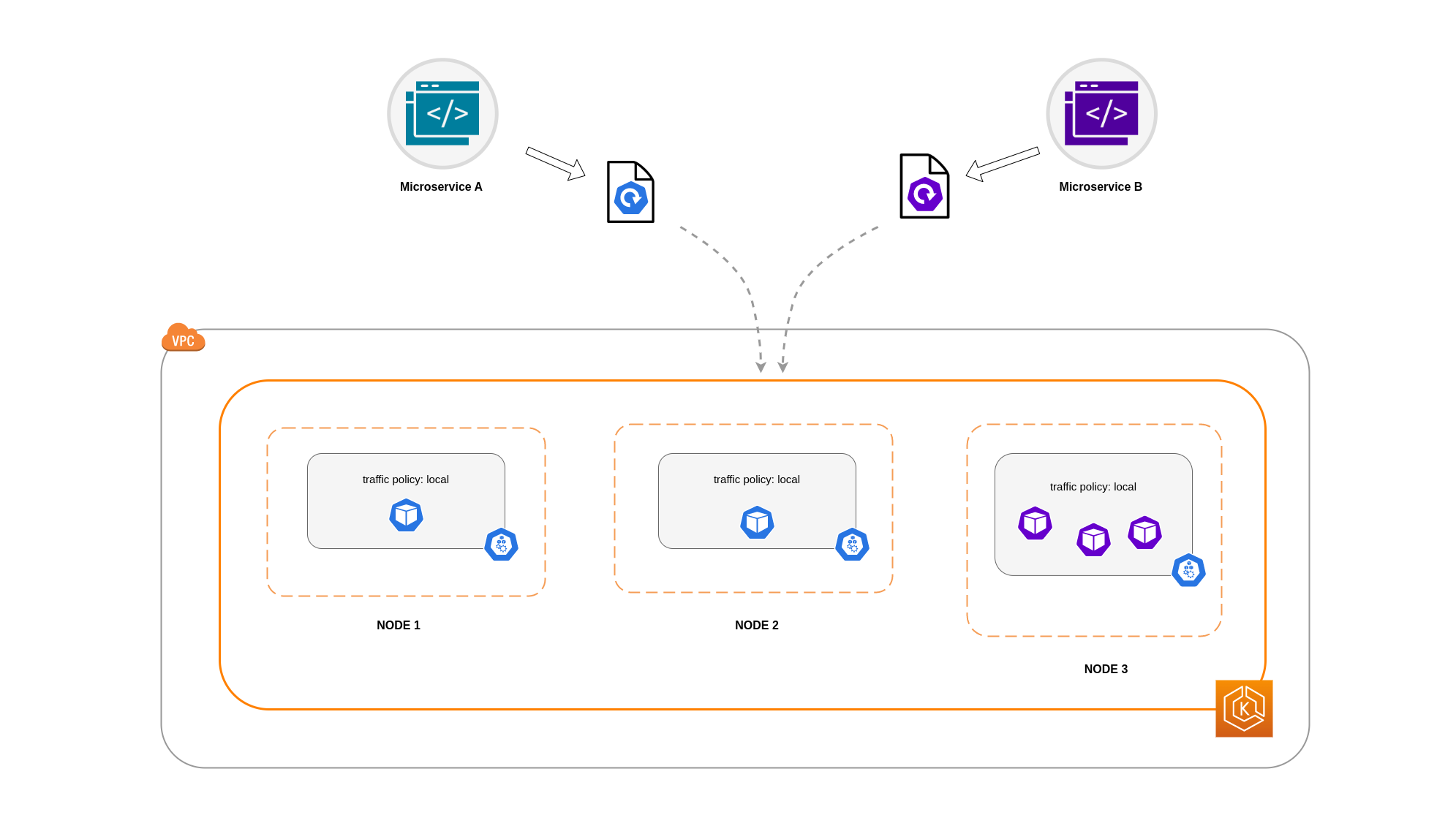
Jika Microservice B memang memiliki 2 dari 3 replika pada Nodes 1 dan 2, maka akan ada komunikasi antara aplikasi peer. Tetapi Anda masih akan memiliki replika Microservice B yang terisolasi tanpa replika rekan untuk berkomunikasi.
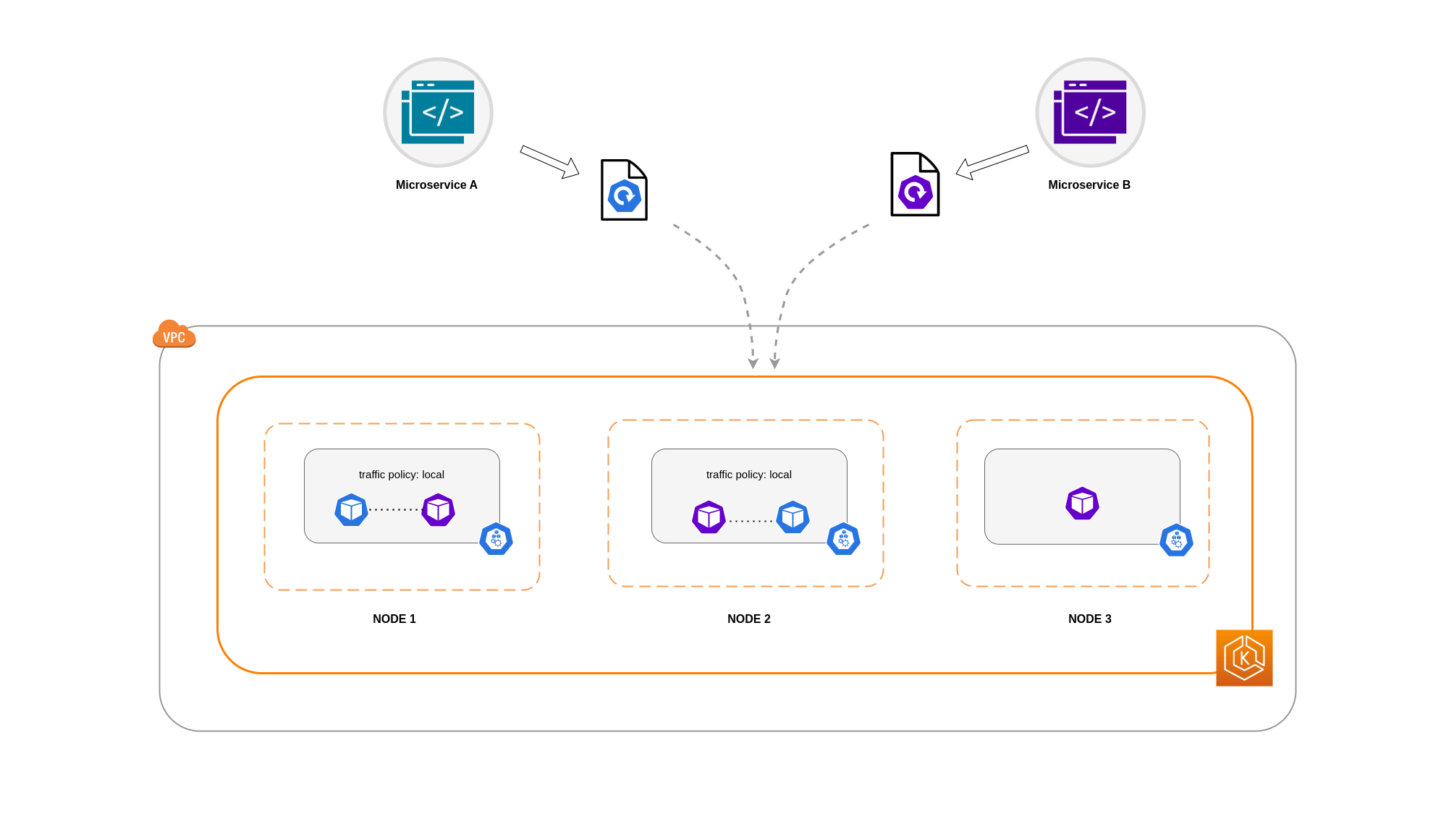
catatan
Dalam beberapa skenario, replika terisolasi seperti yang digambarkan dalam diagram di atas mungkin tidak menjadi perhatian jika masih melayani tujuan (seperti melayani permintaan dari lalu lintas masuk eksternal).
Menggunakan Kebijakan Lalu Lintas Internal Layanan dengan Kendala Penyebaran Topologi
Menggunakan kebijakan lalu lintas internal bersama dengan kendala penyebaran topologi dapat berguna untuk memastikan bahwa Anda memiliki jumlah replika yang tepat untuk mengkomunikasikan layanan mikro pada node yang berbeda.
apiVersion: apps/v1 kind: Deployment metadata: name: express-test spec: replicas: 6 selector: matchLabels: app: express-test template: metadata: labels: app: express-test tier: backend spec: topologySpreadConstraints: - maxSkew: 1 topologyKey: "topology.kubernetes.io/zone" whenUnsatisfiable: ScheduleAnyway labelSelector: matchLabels: app: express-test
Menggunakan Kebijakan Lalu Lintas Internal Layanan dengan Aturan Afinitas Pod
Pendekatan lain adalah dengan menggunakan aturan afinitas Pod saat menggunakan kebijakan lalu lintas internal Layanan. Dengan afinitas Pod, Anda dapat memengaruhi scheduler untuk menemukan Pod tertentu karena sering berkomunikasi. Dengan menerapkan batasan penjadwalan yang ketat (requiredDuringSchedulingIgnoredDuringExecution) pada Pod tertentu, ini akan memberi Anda hasil yang lebih baik untuk co-location Pod ketika Scheduler menempatkan Pod pada node.
apiVersion: apps/v1 kind: Deployment metadata: name: graphql namespace: ecommerce labels: app.kubernetes.io/version: "0.1.6" ... spec: serviceAccountName: graphql-service-account affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - orders topologyKey: "kubernetes.io/hostname"
Load Balancer ke Komunikasi Pod
Beban kerja EKS biasanya digawangi oleh penyeimbang beban yang mendistribusikan lalu lintas ke Pod yang relevan di klaster EKS Anda. Arsitektur Anda dapat terdiri dari penyeimbang beban menghadap and/or eksternal internal. Bergantung pada arsitektur dan konfigurasi lalu lintas jaringan Anda, komunikasi antara load balancer dan Pod dapat memberikan kontribusi yang signifikan terhadap biaya transfer data.
Anda dapat menggunakan AWS Load Balancer Controller
Saat menggunakan mode instance, a NodePort akan dibuka pada setiap node di cluster EKS Anda. Penyeimbang beban kemudian akan mem-proxy lalu lintas secara merata di seluruh node. Jika sebuah node memiliki Pod tujuan yang berjalan di atasnya, maka tidak akan ada biaya transfer data yang dikeluarkan. Namun, jika Pod tujuan berada pada node terpisah dan di AZ yang berbeda dari yang NodePort menerima lalu lintas, maka akan ada tambahan network hop dari kube-proxy ke Pod tujuan. Dalam skenario seperti itu, akan ada biaya transfer data lintas-AZ. Karena distribusi lalu lintas yang merata di seluruh node, sangat mungkin bahwa akan ada biaya transfer data tambahan yang terkait dengan hop lalu lintas jaringan lintas zona dari kube-proxy ke Pod tujuan yang relevan.
Diagram di bawah ini menggambarkan jalur jaringan untuk lalu lintas yang mengalir dari load balancer ke NodePort, dan selanjutnya dari Pod kube-proxy ke tujuan pada node terpisah di AZ yang berbeda. Ini adalah contoh pengaturan mode instance.
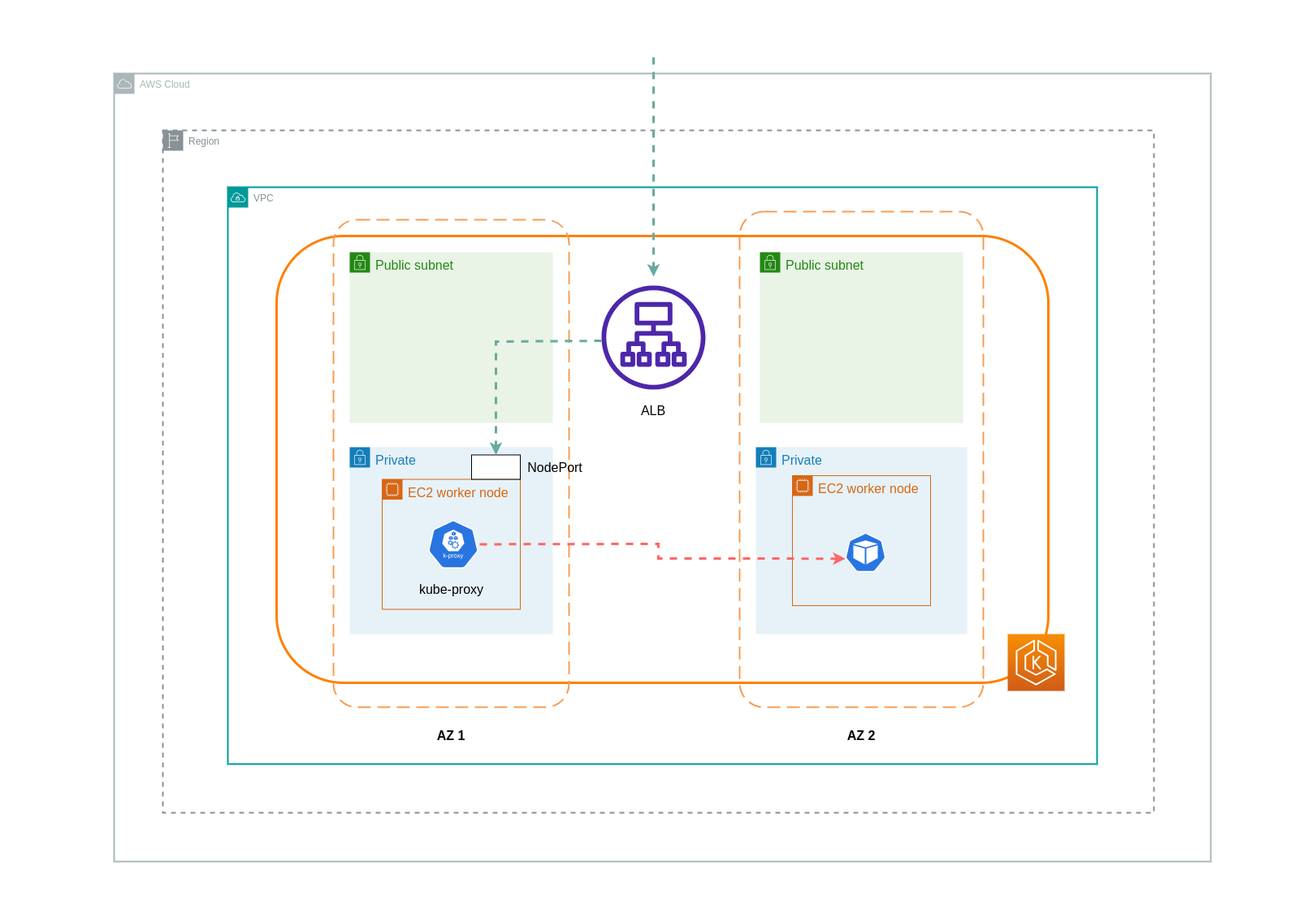
Saat menggunakan mode ip, lalu lintas jaringan diproksi dari load balancer langsung ke Pod tujuan. Akibatnya, tidak ada biaya transfer data yang terlibat dalam pendekatan ini.
catatan
Disarankan agar Anda mengatur penyeimbang beban Anda ke mode lalu lintas ip untuk mengurangi biaya transfer data. Untuk pengaturan ini, penting juga untuk memastikan bahwa penyeimbang beban Anda diterapkan di semua subnet di VPC Anda.
Diagram di bawah ini menggambarkan jalur jaringan untuk lalu lintas yang mengalir dari load balancer ke Pod dalam mode ip jaringan.
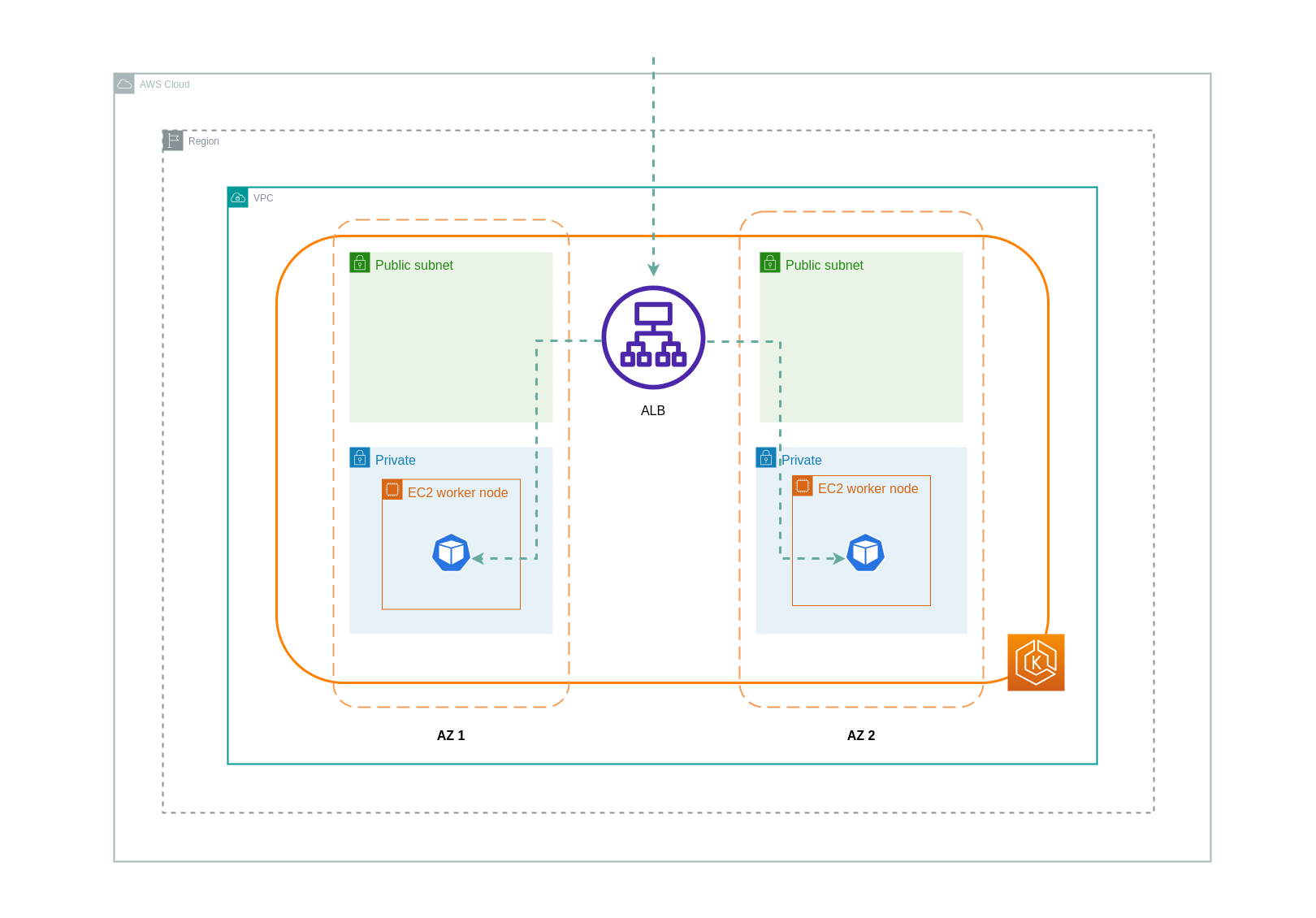
Transfer Data dari Registri Kontainer
Amazon ECR
Transfer data ke registri pribadi Amazon ECR gratis. Transfer data dalam wilayah tidak dikenakan biaya, tetapi transfer data ke internet dan lintas wilayah akan dikenakan tarif Transfer Data Internet di kedua sisi transfer.
Anda harus menggunakan fitur replikasi gambar ECRs bawaan untuk mereplikasi gambar kontainer yang relevan ke wilayah yang sama dengan beban kerja Anda. Dengan cara ini replikasi akan diisi sekali, dan semua tarikan gambar wilayah (intra-wilayah) yang sama akan gratis.
Anda dapat mengurangi biaya transfer data yang terkait dengan pengambilan gambar dari ECR (transfer data keluar) dengan menggunakan Titik Akhir VPC Antarmuka untuk terhubung ke repositori ECR di wilayah. Pendekatan alternatif untuk menghubungkan ke titik akhir AWS publik ECR (melalui Gateway NAT dan Internet Gateway) akan menimbulkan biaya pemrosesan dan transfer data yang lebih tinggi. Bagian selanjutnya akan mencakup pengurangan biaya transfer data antara beban kerja Anda dan AWS Services secara lebih rinci.
Jika Anda menjalankan beban kerja dengan gambar yang sangat besar, Anda dapat membuat Amazon Machine Images (AMIs) kustom Anda sendiri dengan gambar kontainer pra-cache. Ini dapat mengurangi waktu penarikan gambar awal dan potensi biaya transfer data dari registri kontainer ke node pekerja EKS.
Transfer Data ke Layanan Internet & AWS
Merupakan praktik umum untuk mengintegrasikan beban kerja Kubernetes dengan layanan AWS lainnya atau alat dan platform pihak ketiga melalui Internet. Infrastruktur jaringan yang mendasari yang digunakan untuk mengarahkan lalu lintas ke dan dari tujuan yang relevan dapat memengaruhi biaya yang dikeluarkan dalam proses transfer data.
Menggunakan NAT Gateways
NAT Gateways adalah komponen jaringan yang melakukan terjemahan alamat jaringan (NAT). Diagram di bawah ini menggambarkan Pod dalam klaster EKS yang berkomunikasi dengan layanan AWS lainnya (Amazon ECR, DynamoDB, dan S3), dan platform pihak ketiga. Dalam contoh ini, Pod berjalan di subnet pribadi secara terpisah AZs. Untuk mengirim dan menerima lalu lintas dari Internet, NAT Gateway dikerahkan ke subnet publik dari satu AZ, memungkinkan sumber daya apa pun dengan alamat IP pribadi untuk berbagi satu alamat IP publik untuk mengakses Internet. NAT Gateway ini pada gilirannya berkomunikasi dengan komponen Internet Gateway, memungkinkan paket dikirim ke tujuan akhir mereka.
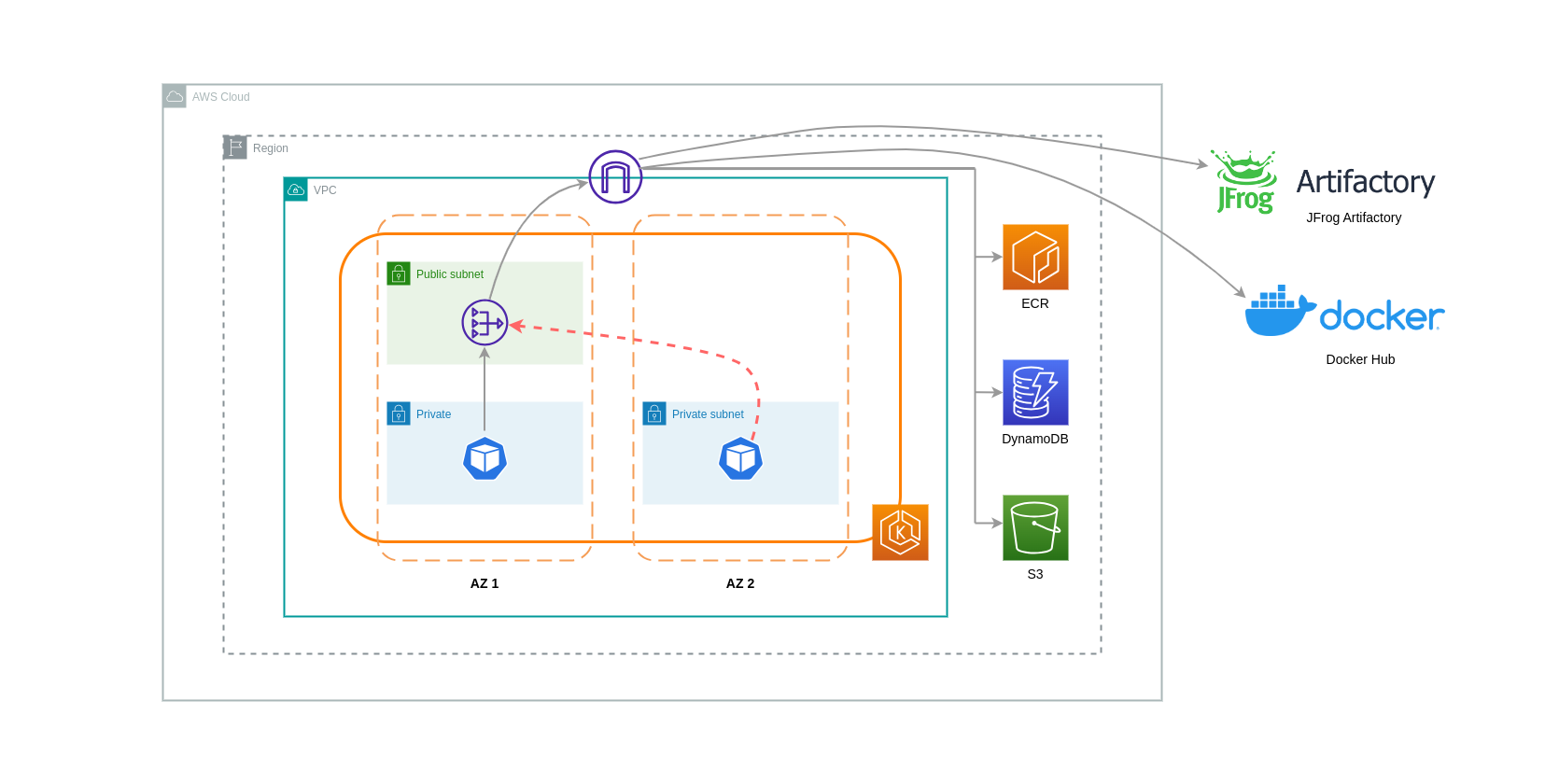
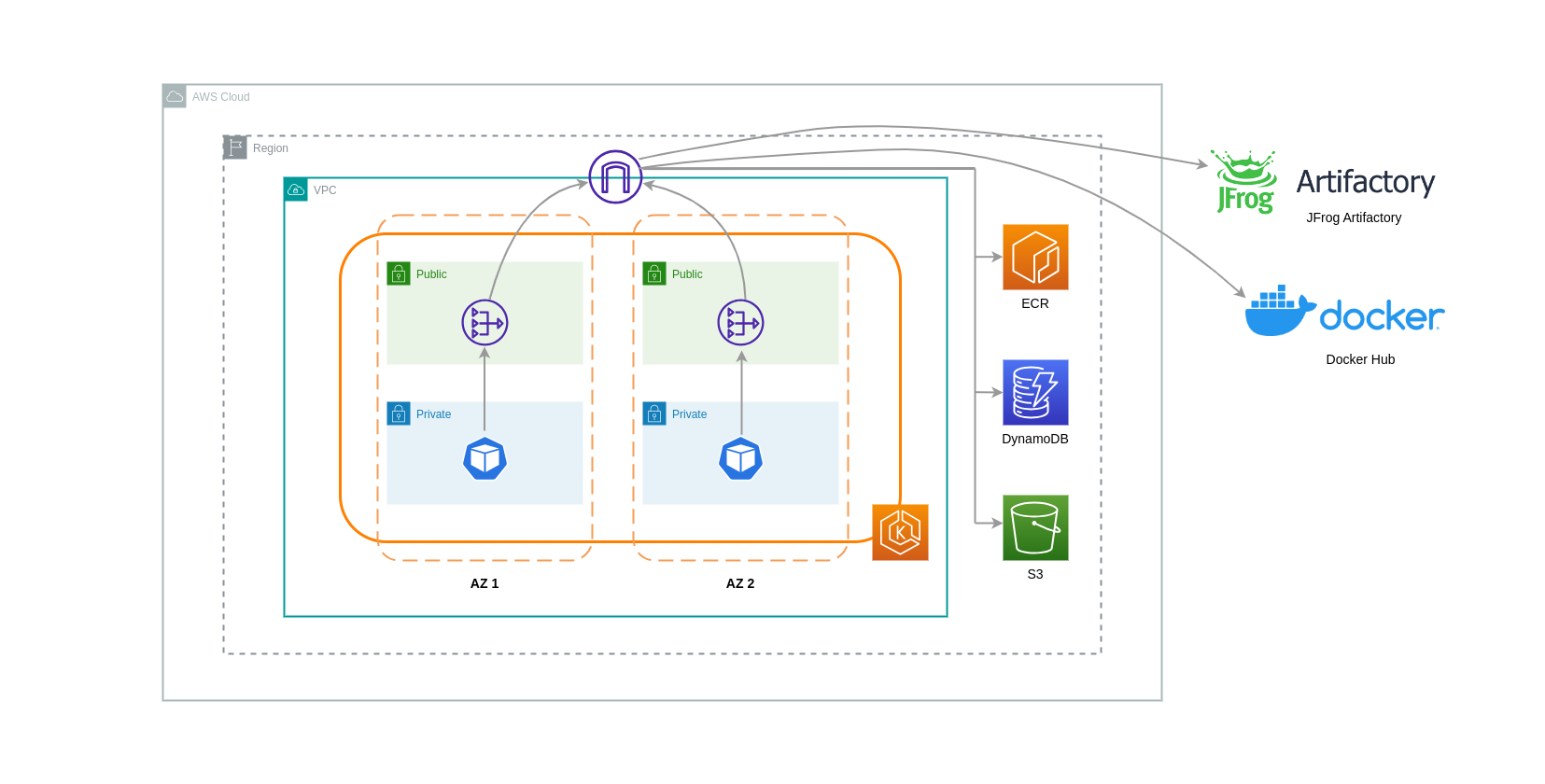
Saat menggunakan NAT Gateways untuk kasus penggunaan seperti itu, Anda dapat meminimalkan biaya transfer data dengan menerapkan NAT Gateway di setiap AZ. Dengan cara ini, lalu lintas yang diarahkan ke Internet akan melalui NAT Gateway di AZ yang sama, menghindari transfer data antar-AZ. Namun, meskipun Anda akan menghemat biaya transfer data antar-AZ, implikasi dari pengaturan ini adalah Anda akan dikenakan biaya tambahan NAT Gateway dalam arsitektur Anda.
Pendekatan yang direkomendasikan ini digambarkan dalam diagram di bawah ini.
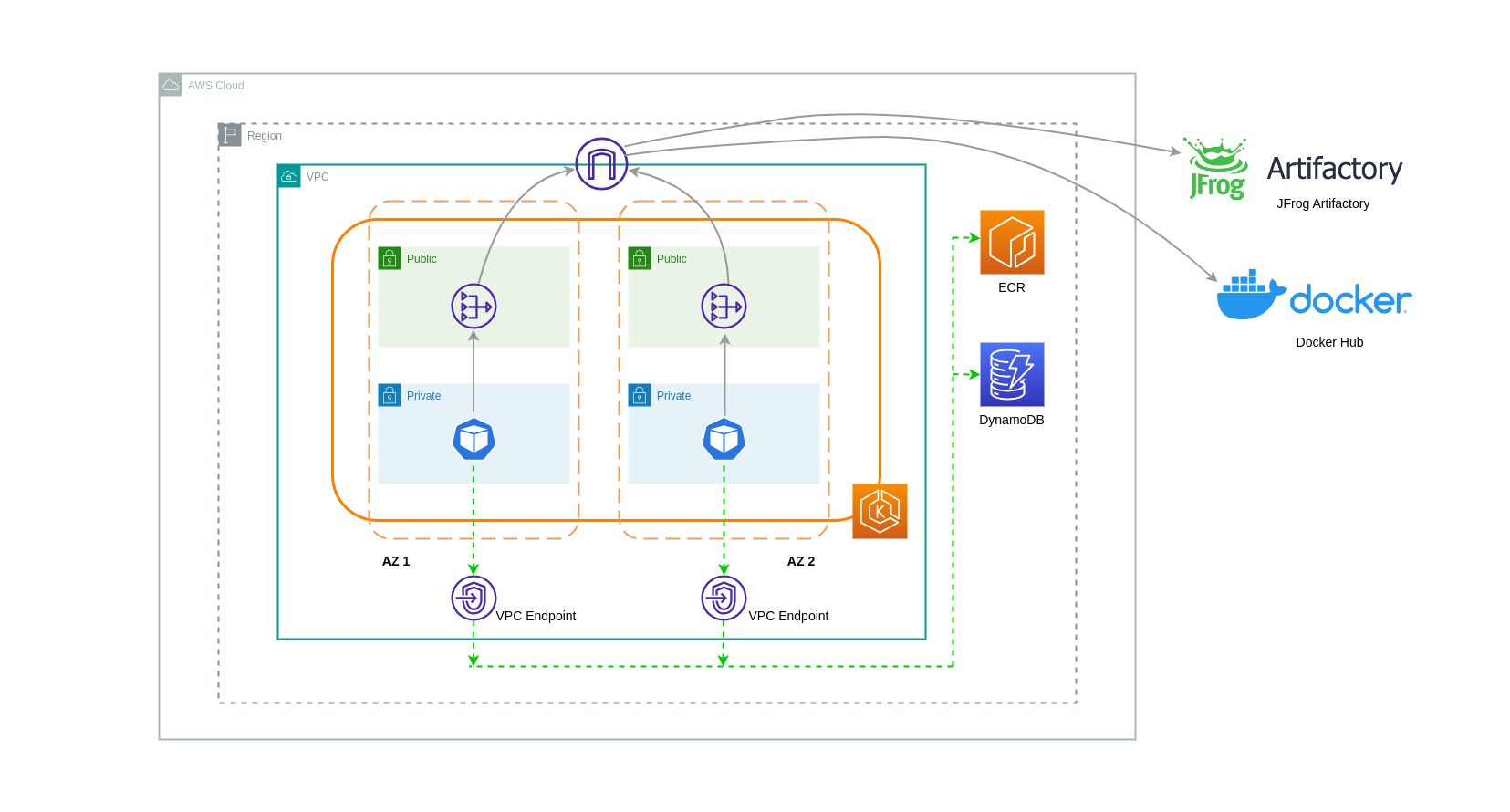
Menggunakan VPC Endpoint
Untuk lebih mengurangi biaya dalam arsitektur tersebut, Anda harus menggunakan VPC Endpoint untuk membangun konektivitas antara beban kerja Anda dan layanan AWS. Titik Akhir VPC memungkinkan Anda mengakses layanan AWS dari dalam VPC tanpa data/network paket yang melintasi Internet. Semua lalu lintas bersifat internal dan tetap berada dalam jaringan AWS. Ada dua jenis VPC Endpoint: Interface VPC Endpoints (didukung oleh banyak layanan AWS) dan Gateway VPC Endpoints (hanya didukung oleh S3 dan DynamoDB).
Titik Akhir VPC Gerbang
Tidak ada biaya per jam atau transfer data yang terkait dengan Titik Akhir VPC Gateway. Saat menggunakan Gateway VPC Endpoints, penting untuk dicatat bahwa titik tersebut tidak dapat diperpanjang melintasi batas VPC. Mereka tidak dapat digunakan dalam peering VPC, jaringan VPN, atau melalui Direct Connect.
Antarmuka VPC Endpoint
Titik Akhir VPC memiliki biaya per jam dan memiliki biaya
Diagram di bawah ini menunjukkan Pod yang berkomunikasi dengan layanan AWS melalui Titik Akhir VPC.
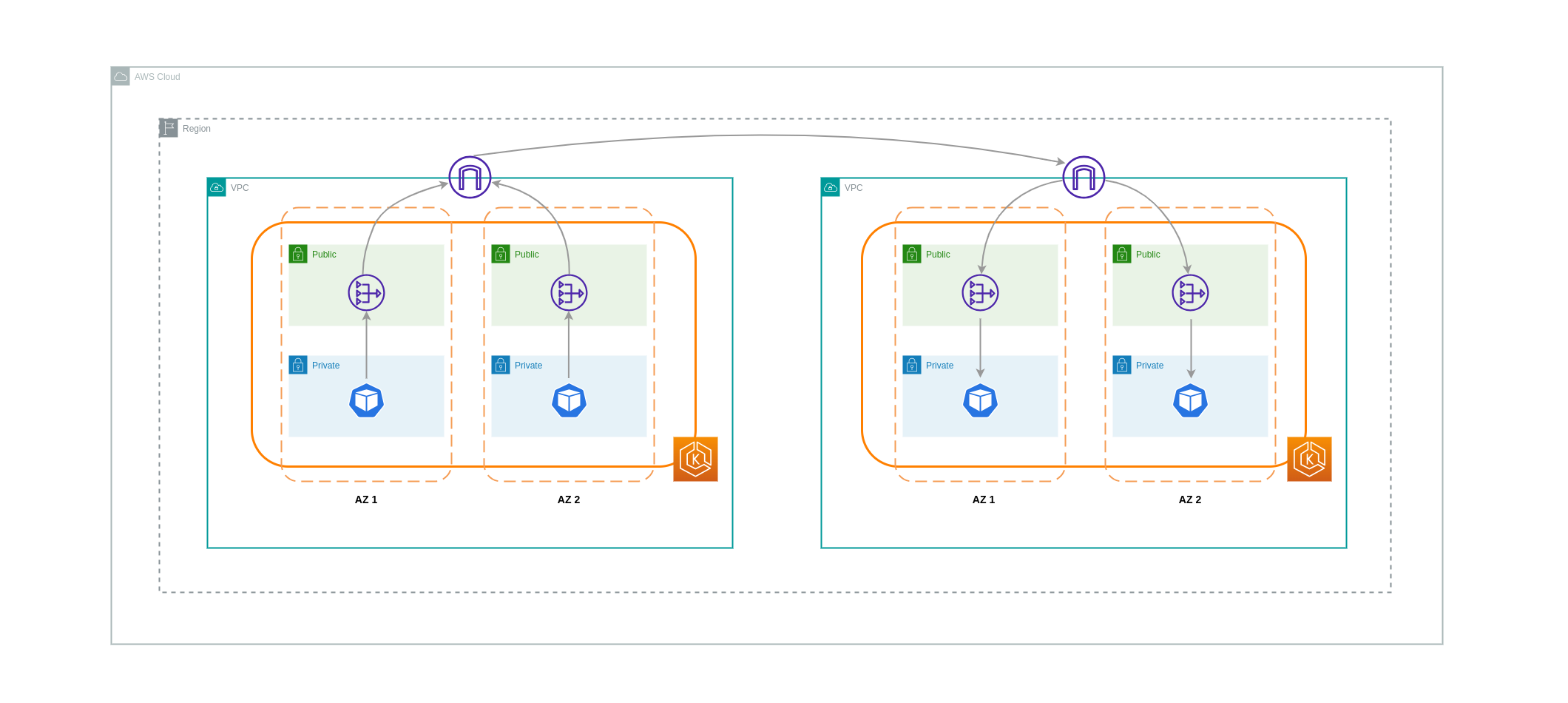
Transfer Data antara VPCs
Dalam beberapa kasus, Anda mungkin memiliki beban kerja yang berbeda VPCs (dalam wilayah AWS yang sama) yang perlu berkomunikasi satu sama lain. Hal ini dapat dicapai dengan memungkinkan lalu lintas untuk melintasi internet publik melalui Internet Gateways yang melekat pada masing-masing. VPCs Komunikasi semacam itu dapat diaktifkan dengan menyebarkan komponen infrastruktur seperti EC2 instance, NAT Gateways atau instance NAT di subnet publik. Namun, pengaturan termasuk komponen-komponen ini akan dikenakan biaya untuk processing/transferring data masuk dan keluar dari. VPCs Jika lalu lintas ke dan dari VPCs yang terpisah bergerak AZs, maka akan ada biaya tambahan dalam transfer data. Diagram di bawah ini menggambarkan pengaturan yang menggunakan NAT Gateways dan Internet Gateways untuk membangun komunikasi antara beban kerja yang berbeda. VPCs
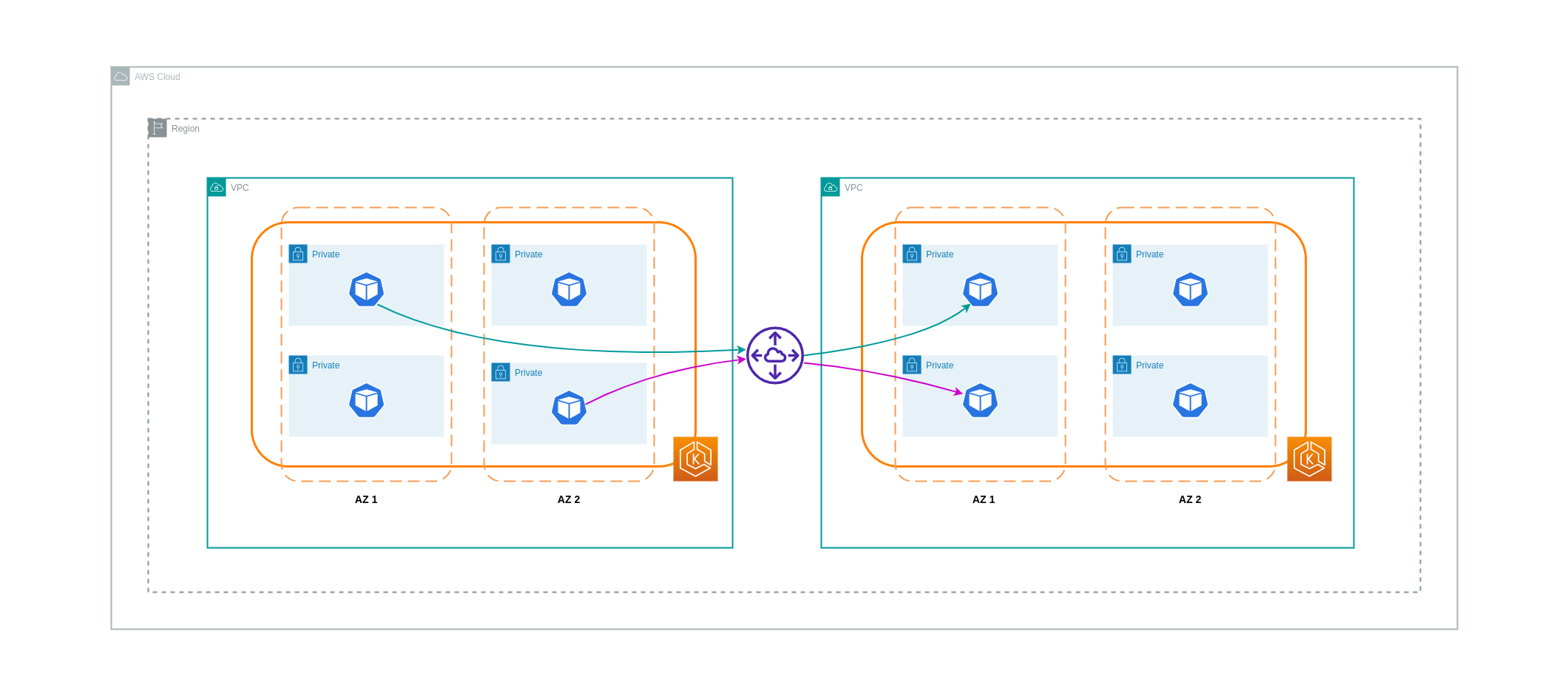
Koneksi Peering VPC
Untuk mengurangi biaya untuk kasus penggunaan seperti itu, Anda dapat menggunakan VPC Peering. Dengan koneksi VPC Peering, tidak ada biaya transfer data untuk lalu lintas jaringan yang tetap berada dalam AZ yang sama. Jika lalu lintas melintas AZs, akan ada biaya yang dikeluarkan. Meskipun demikian, pendekatan VPC Peering direkomendasikan untuk komunikasi yang hemat biaya antara beban kerja secara terpisah dalam wilayah AWS yang sama. VPCs Namun, penting untuk dicatat bahwa peering VPC terutama efektif untuk konektivitas VPC 1:1 karena tidak memungkinkan jaringan transitif.
Diagram di bawah ini adalah representasi tingkat tinggi dari komunikasi beban kerja melalui koneksi peering VPC.
Koneksi Jaringan Transitif
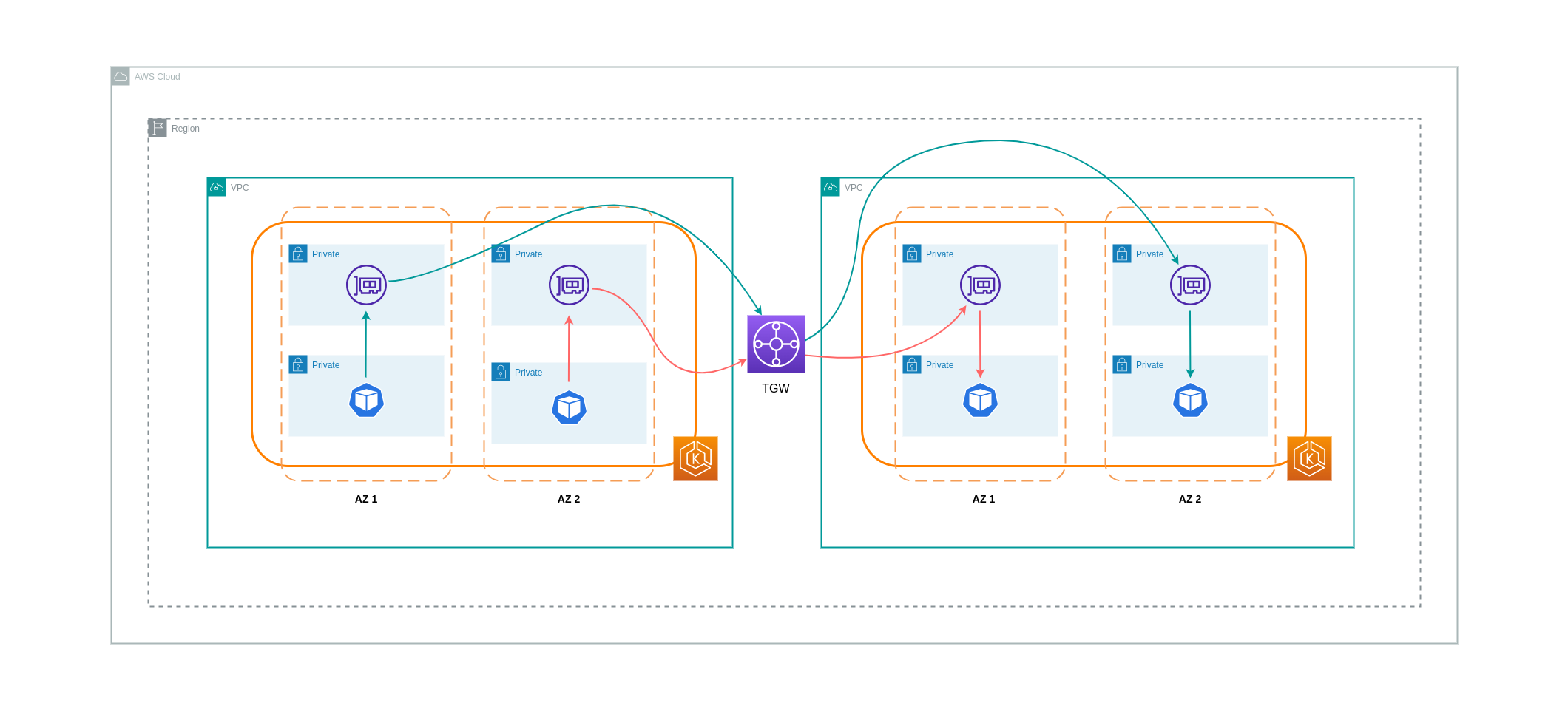
Seperti yang ditunjukkan di bagian sebelumnya, koneksi VPC Peering tidak memungkinkan konektivitas jaringan transitif. Jika Anda ingin menghubungkan 3 atau lebih VPCs dengan persyaratan jaringan transitif, maka Anda harus menggunakan Transit Gateway (TGW). Ini akan memungkinkan Anda untuk mengatasi batasan VPC Peering atau overhead operasional apa pun yang terkait dengan memiliki beberapa koneksi VPC Peering antara beberapa. VPCs Anda ditagih setiap jam
Diagram di bawah ini menunjukkan lalu lintas antar-AZ yang mengalir melalui TGW antara beban kerja yang berbeda VPCs tetapi dalam wilayah AWS yang sama.
Menggunakan Service Mesh
Service mesh menawarkan kemampuan jaringan yang kuat yang dapat digunakan untuk mengurangi biaya terkait jaringan di lingkungan kluster EKS Anda. Namun, Anda harus mempertimbangkan dengan cermat tugas operasional dan kompleksitas yang akan diperkenalkan oleh mesh layanan ke lingkungan Anda jika Anda mengadopsinya.
Membatasi Lalu Lintas ke Availability Zone
Menggunakan Distribusi Tertimbang Lokalitas Istio
Istio memungkinkan Anda menerapkan kebijakan jaringan ke lalu lintas setelah perutean terjadi. Ini dilakukan dengan menggunakan Aturan Tujuan
catatan
Sebelum menerapkan distribusi tertimbang lokalitas, Anda harus mulai dengan memahami pola lalu lintas jaringan Anda dan implikasi yang mungkin dimiliki kebijakan Aturan Tujuan terhadap perilaku aplikasi Anda. Karena itu, penting untuk memiliki mekanisme penelusuran terdistribusi dengan alat seperti AWS X-Ray
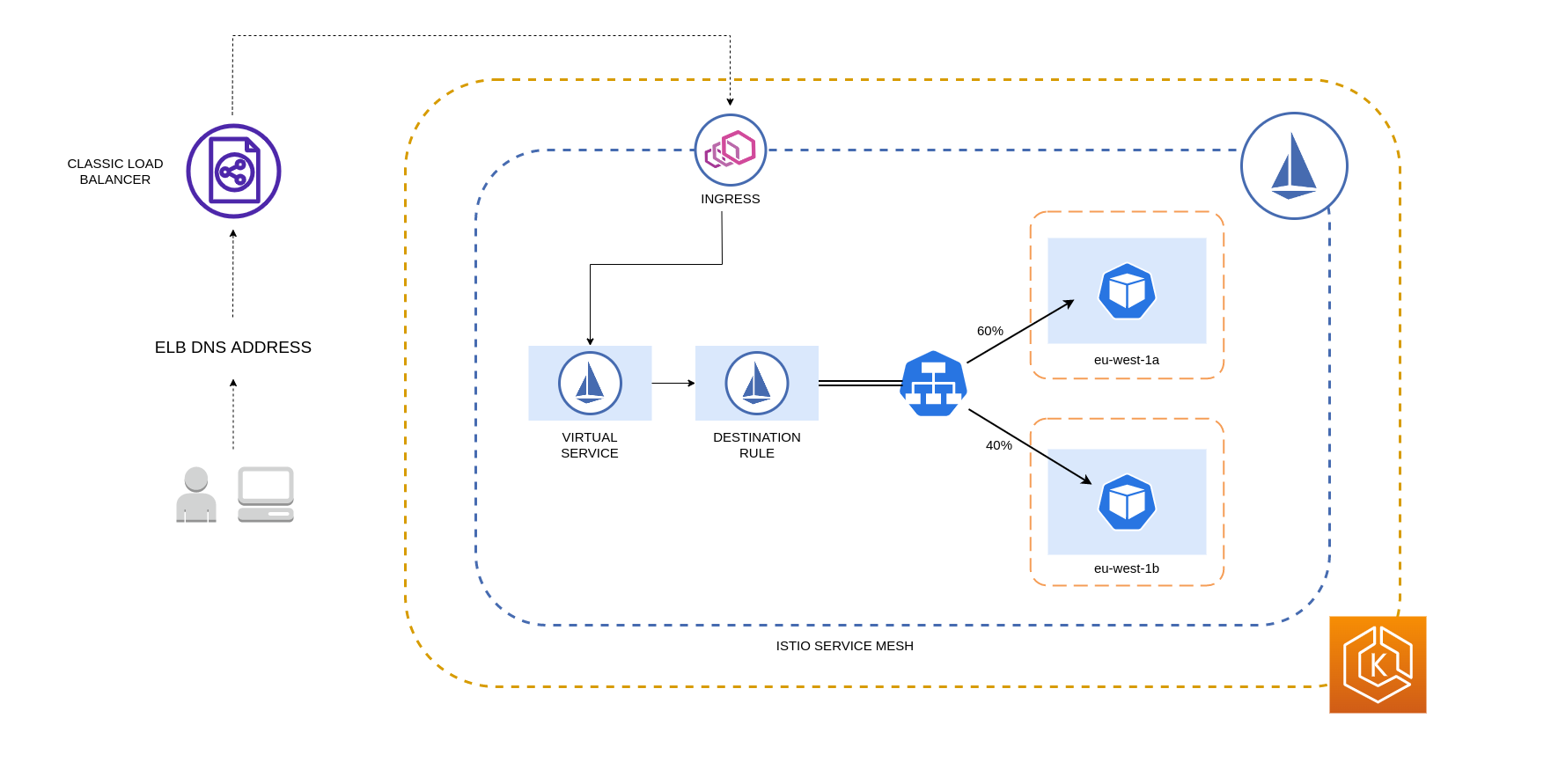
Aturan Destinasi Istio yang dijelaskan di atas juga dapat diterapkan untuk mengelola lalu lintas dari penyeimbang beban ke Pod di klaster EKS Anda. Aturan distribusi tertimbang lokalitas dapat diterapkan pada Layanan yang menerima lalu lintas dari penyeimbang beban yang sangat tersedia (khususnya Ingress Gateway). Aturan-aturan ini memungkinkan Anda untuk mengontrol berapa banyak lalu lintas yang berjalan berdasarkan asal zonalnya - penyeimbang beban dalam kasus ini. Jika dikonfigurasi dengan benar, lalu lintas lintas zona keluar yang lebih sedikit akan terjadi dibandingkan dengan penyeimbang beban yang mendistribusikan lalu lintas secara merata atau acak ke replika Pod yang berbeda. AZs
Di bawah ini adalah contoh blok kode sumber daya Aturan Tujuan di Istio. Seperti dapat dilihat di bawah, sumber daya ini menentukan konfigurasi tertimbang untuk lalu lintas masuk dari 3 berbeda AZs di wilayah tersebut. eu-west-1 Konfigurasi ini menyatakan bahwa sebagian besar lalu lintas masuk (70% dalam hal ini) dari AZ tertentu harus diproksi ke tujuan di AZ yang sama dari mana asalnya.
apiVersion: networking.istio.io/v1beta1 kind: DestinationRule metadata: name: express-test-dr spec: host: express-test.default.svc.cluster.local trafficPolicy: loadBalancer: + localityLbSetting: distribute: - from: eu-west-1/eu-west-1a/ + to: "eu-west-1/eu-west-1a/_": 70 "eu-west-1/eu-west-1b/_": 20 "eu-west-1/eu-west-1c/_": 10 - from: eu-west-1/eu-west-1b/_ + to: "eu-west-1/eu-west-1a/_": 20 "eu-west-1/eu-west-1b/_": 70 "eu-west-1/eu-west-1c/_": 10 - from: eu-west-1/eu-west-1c/_ + to: "eu-west-1/eu-west-1a/_": 20 "eu-west-1/eu-west-1b/_": 10 "eu-west-1/eu-west-1c/*": 70** connectionPool: http: http2MaxRequests: 10 maxRequestsPerConnection: 10 outlierDetection: consecutiveGatewayErrors: 1 interval: 1m baseEjectionTime: 30s
catatan
Berat minimum yang dapat didistribusikan tujuan adalah 1%. Alasan untuk ini adalah untuk mempertahankan wilayah dan zona failover jika titik akhir di tujuan utama menjadi tidak sehat atau tidak tersedia.
Diagram di bawah ini menggambarkan skenario di mana ada penyeimbang beban yang sangat tersedia di wilayah eu-west-1 dan distribusi tertimbang lokalitas diterapkan. Kebijakan Aturan Tujuan untuk diagram ini dikonfigurasi untuk mengirim 60% lalu lintas yang berasal dari eu-west-1a ke Pod di AZ yang sama, sedangkan 40% lalu lintas dari eu-west-1a harus masuk ke Pod di eu-west-1b.
Membatasi Lalu Lintas ke Availability Zone dan Node
Menggunakan Kebijakan Lalu Lintas Internal Layanan dengan Istio
Untuk mengurangi biaya jaringan yang terkait dengan lalu lintas masuk eksternal dan lalu lintas internal antar Pod, Anda dapat menggabungkan Aturan Tujuan Istio dan kebijakan lalu lintas internal Layanan Kubernetes. Cara menggabungkan aturan tujuan Istio dengan kebijakan lalu lintas internal layanan akan sangat bergantung pada 3 hal:
-
Peran layanan mikro
-
Pola lalu lintas jaringan di seluruh layanan mikro
-
Bagaimana layanan mikro harus diterapkan di seluruh topologi klaster Kubernetes
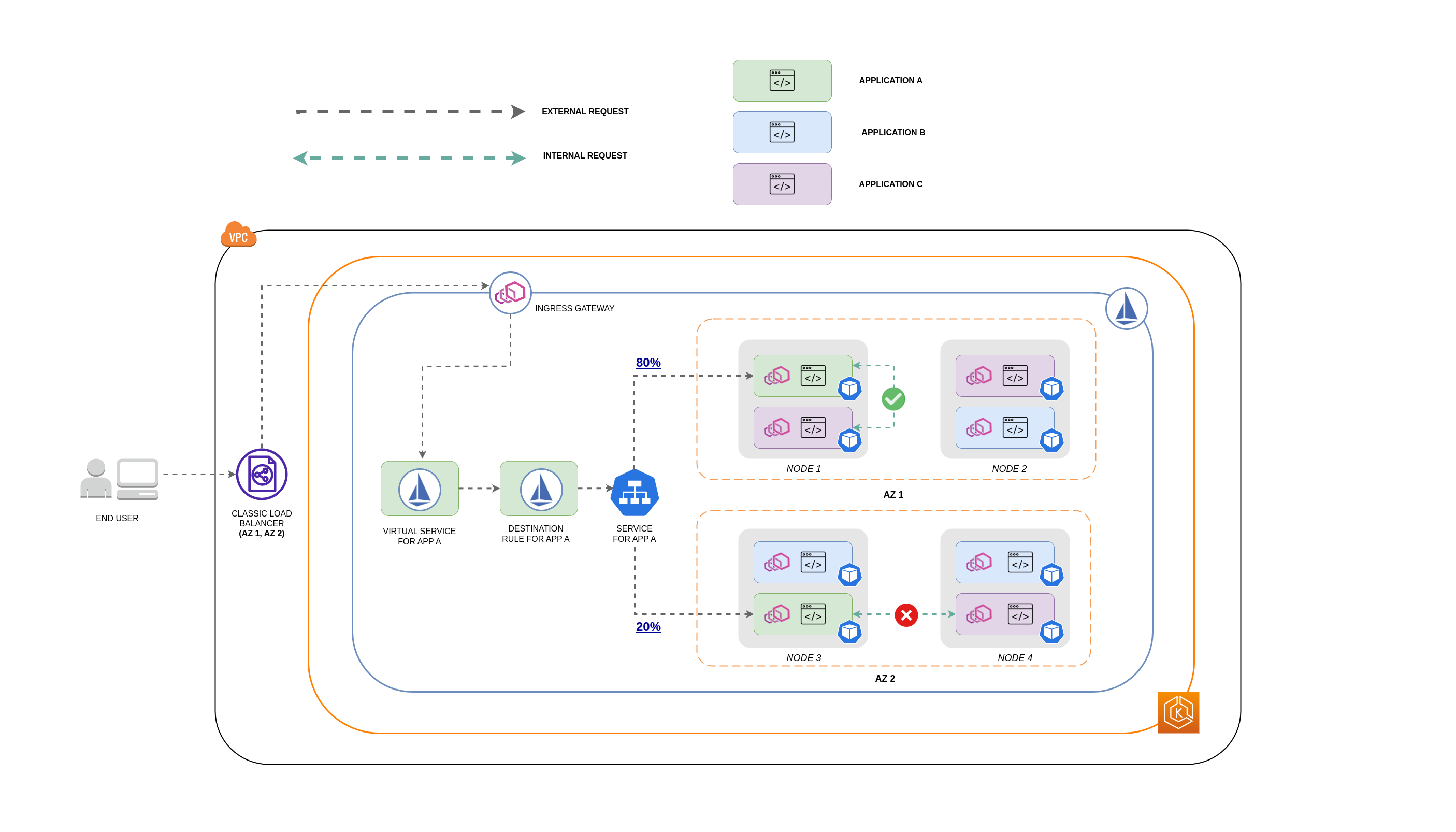
Diagram di bawah ini menunjukkan seperti apa aliran jaringan dalam kasus permintaan bersarang dan bagaimana kebijakan yang disebutkan di atas akan mengontrol lalu lintas.
-
Pengguna akhir membuat permintaan ke APP A, yang pada gilirannya membuat permintaan bersarang ke APP C. Permintaan ini pertama kali dikirim ke penyeimbang beban yang sangat tersedia, yang memiliki instance di AZ 1 dan AZ 2 seperti yang ditunjukkan diagram di atas.
-
Permintaan masuk eksternal kemudian diarahkan ke tujuan yang benar oleh Layanan Virtual Istio.
-
Setelah permintaan dialihkan, Aturan Destinasi Istio mengontrol berapa banyak lalu lintas yang masuk ke masing-masing AZs berdasarkan dari mana asalnya (AZ 1 atau AZ 2).
-
Lalu lintas kemudian masuk ke Layanan untuk APP A, dan kemudian diproksi ke titik akhir Pod masing-masing. Seperti yang ditunjukkan pada diagram, 80% dari lalu lintas masuk dikirim ke titik akhir Pod di AZ 1, dan 20% dari lalu lintas masuk dikirim ke AZ 2.
-
APP A kemudian membuat permintaan internal ke APP C. Layanan APP C memiliki kebijakan lalu lintas internal yang diaktifkan (
internalTrafficPolicy`: Local`). -
Permintaan internal dari APP A (pada NODE 1) ke APP C berhasil karena titik akhir node-lokal yang tersedia untuk APP C.
-
Permintaan internal dari APP A (pada NODE 3) ke APP C gagal karena tidak ada titik akhir node-lokal yang tersedia untuk APP C. Seperti yang ditunjukkan diagram, APP C tidak memiliki replika pada NODE 3. * *
Tangkapan layar di bawah ini diambil dari contoh langsung dari pendekatan ini. Kumpulan tangkapan layar pertama menunjukkan permintaan eksternal yang berhasil ke graphql dan permintaan bersarang yang berhasil dari graphql ke orders replika yang ditempatkan bersama pada node. ip-10-0-0-151.af-south-1.compute.internal
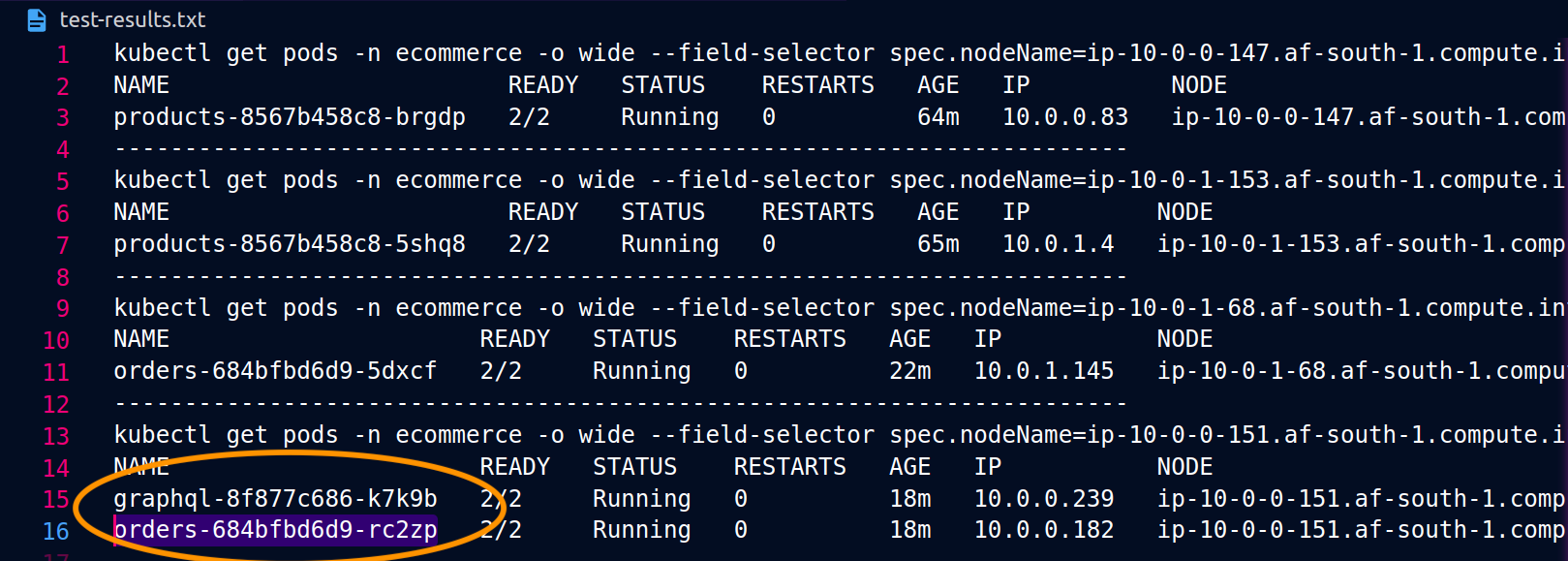
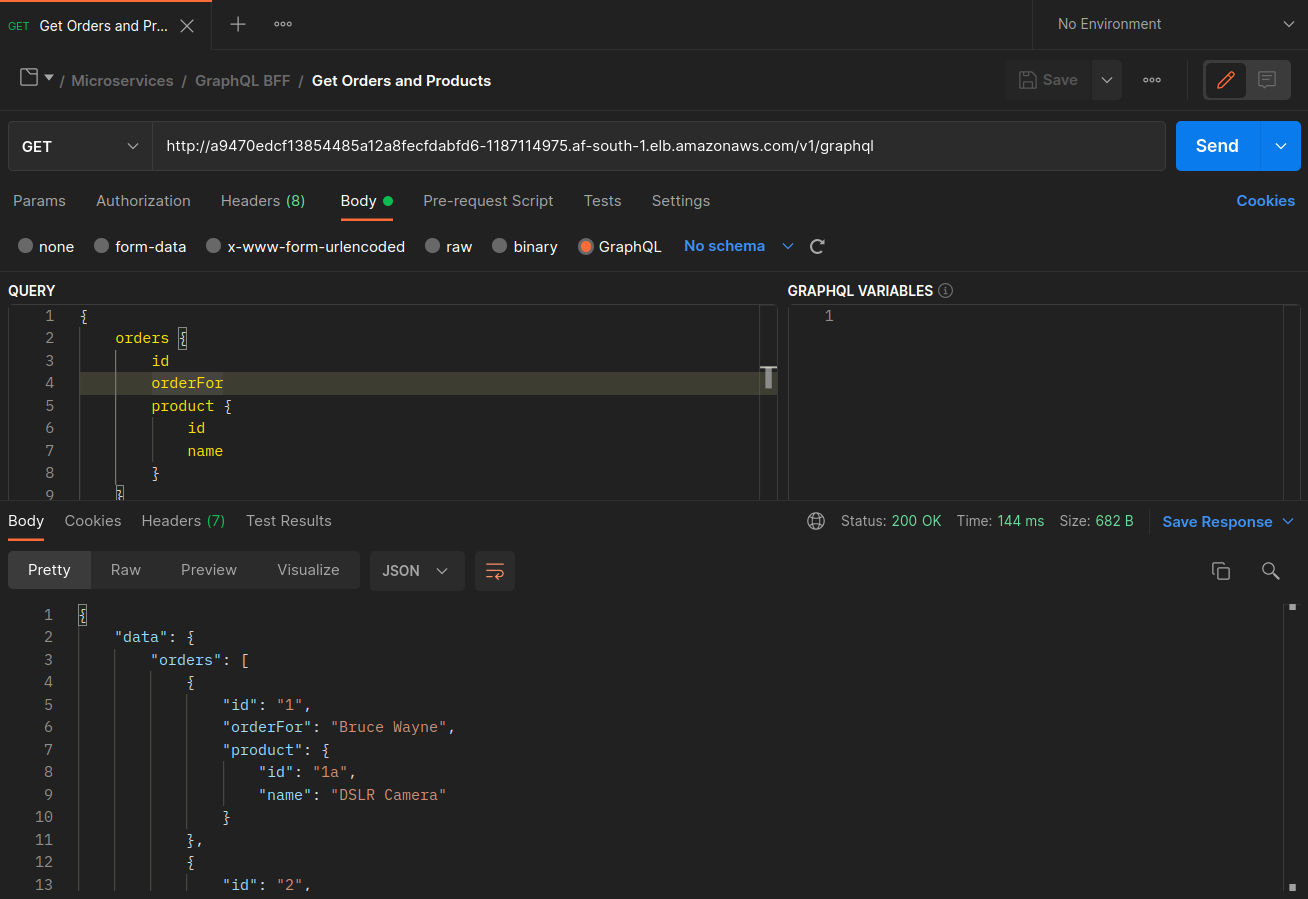
Dengan Istio, Anda dapat memverifikasi dan mengekspor statistik [klaster hulu] apa pun (https://www.envoyproxy. io/docs/envoy/latest/intro/arch_overview/intro/terminologyorders titik akhir yang diketahui graphql proxy dapat diperoleh dengan menggunakan perintah berikut:
kubectl exec -it deploy/graphql -n ecommerce -c istio-proxy -- curl localhost:15000/clusters | grep orders
... orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**rq_error::0** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**rq_success::119** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**rq_timeout::0** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**rq_total::119** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**health_flags::healthy** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**region::af-south-1** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**zone::af-south-1b** ...
Dalam hal ini, graphql proxy hanya mengetahui orders titik akhir untuk replika yang berbagi node dengannya. Jika Anda menghapus internalTrafficPolicy: Local pengaturan dari Layanan pesanan, dan menjalankan kembali perintah seperti di atas, maka hasilnya akan mengembalikan semua titik akhir replika yang tersebar di node yang berbeda. Selanjutnya, dengan memeriksa titik akhir masing-masing, Anda akan melihat pangsa yang relatif merata dalam distribusi jaringan. rq_total Akibatnya, jika titik akhir dikaitkan dengan layanan hulu yang berjalan berbeda AZs, maka distribusi jaringan ini di seluruh zona akan menghasilkan biaya yang lebih tinggi.
Seperti yang disebutkan di bagian sebelumnya di atas, Anda dapat menempatkan Pod yang sering berkomunikasi dengan memanfaatkan pod-affinity.
... spec: ... template: metadata: labels: app: graphql role: api workload: ecommerce spec: affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - orders topologyKey: "kubernetes.io/hostname" nodeSelector: managedBy: karpenter billing-team: ecommerce ...
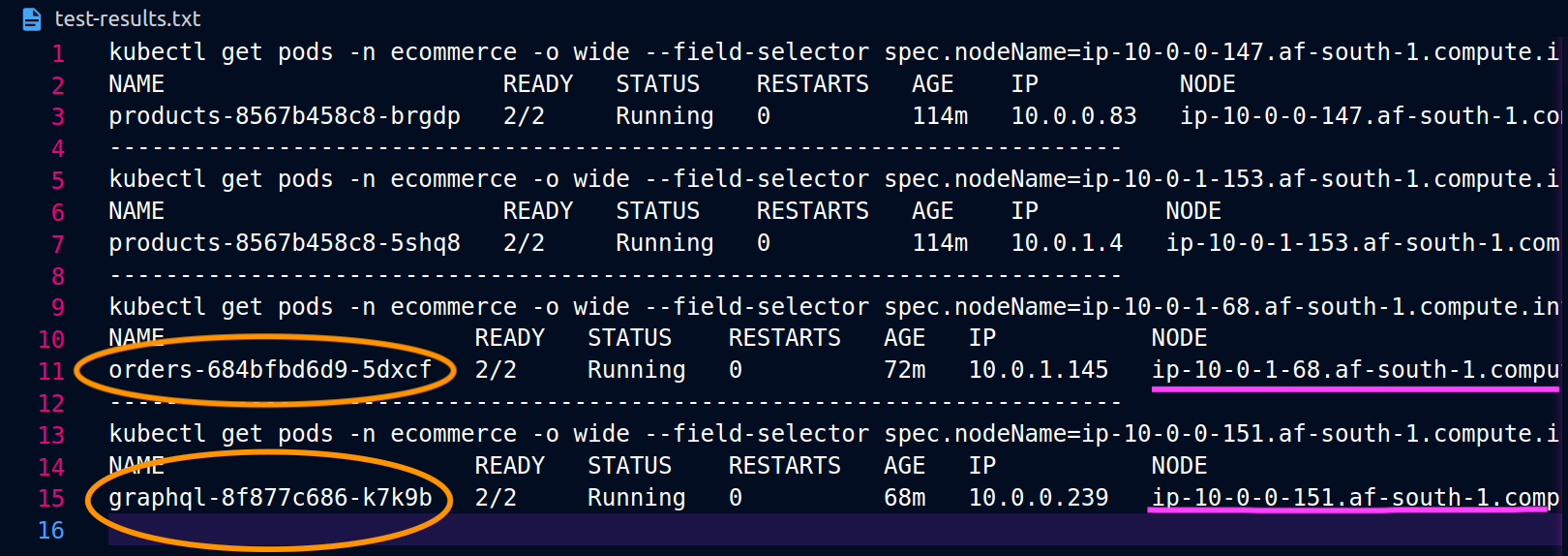
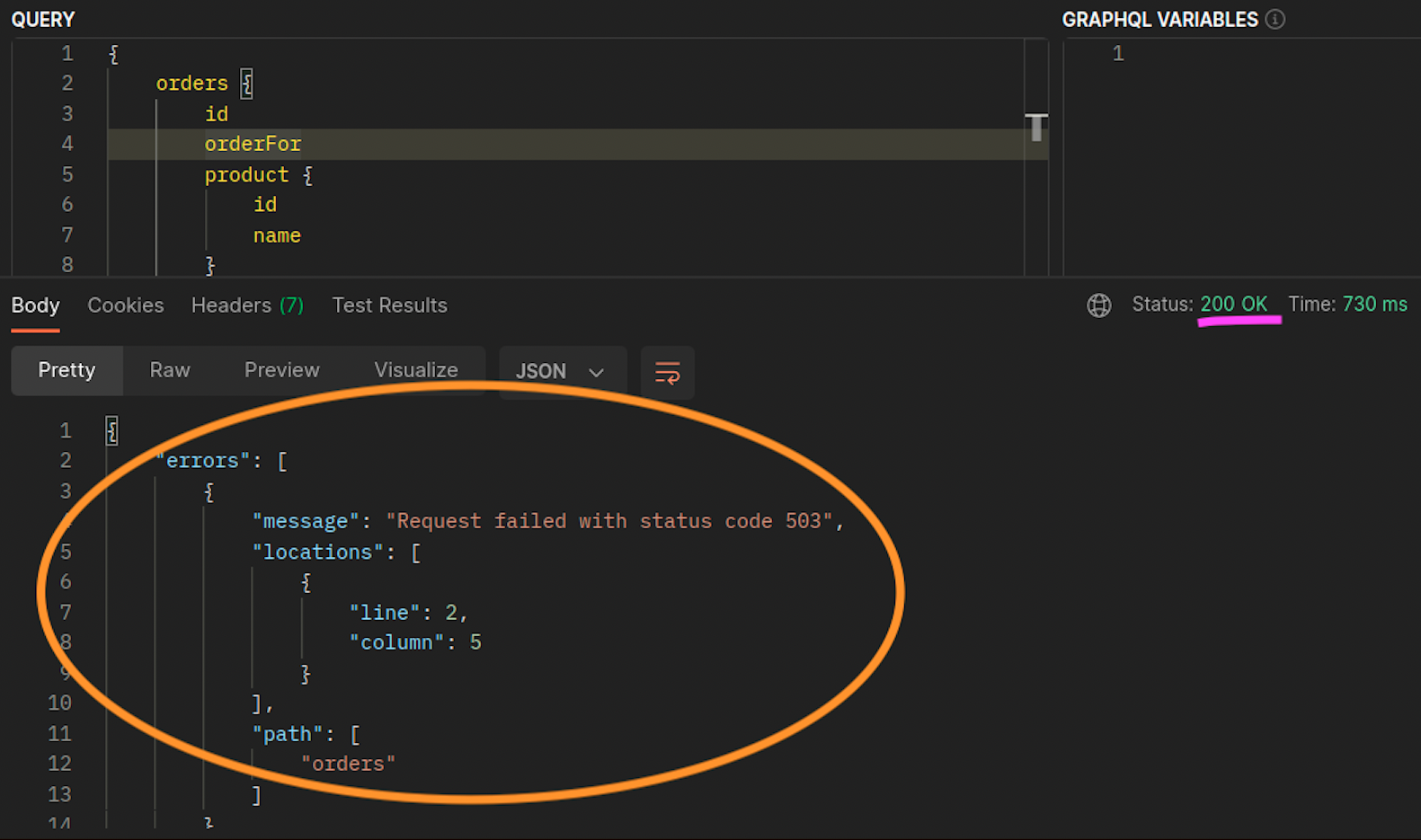
Ketika graphql dan orders replika tidak hidup berdampingan pada node (ip-10-0-0-151.af-south-1.compute.internal) yang sama, permintaan pertama berhasil seperti yang dicatat oleh screenshot di Postman 200 response code di bawah ini, sedangkan permintaan bersarang kedua dari graphql gagal orders dengan a. graphql 503 response code
Sumber Daya Tambahan
-
Mengatasi latensi dan biaya transfer data di EKS menggunakan Istio
-
Mendapatkan visibilitas ke pod Amazon EKS Cross-AZ Anda ke byte jaringan pod
-
Optimalkan Biaya & Kinerja Kubernetes dengan Kebijakan Lalu Lintas Internal Layanan
-
Optimalkan Biaya & Kinerja Kubernetes dengan Istio dan Kebijakan Lalu Lintas Internal Layanan
