Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Memahami metrik penskalaan terkelola di Amazon EMR
Amazon EMR menerbitkan metrik resolusi tinggi dengan data pada rincian satu menit ketika penskalaan terkelola diaktifkan untuk suatu klaster. Anda dapat melihat peristiwa pada setiap inisiasi dan penyelesaian pengubahan ukuran yang dikendalikan oleh penskalaan terkelola dengan konsol EMR Amazon atau konsol Amazon. CloudWatch CloudWatch metrik sangat penting agar penskalaan terkelola Amazon EMR dapat beroperasi. Kami menyarankan Anda memantau CloudWatch metrik dengan cermat untuk memastikan data tidak hilang. Untuk informasi selengkapnya tentang cara mengonfigurasi CloudWatch alarm untuk mendeteksi metrik yang hilang, lihat Menggunakan alarm Amazon CloudWatch . Untuk informasi selengkapnya tentang penggunaan CloudWatch peristiwa dengan Amazon EMR, lihat Memantau CloudWatch peristiwa.
Metrik berikut menunjukkan kapasitas saat ini atau kapasitas target suatu klaster. Metrik ini hanya tersedia apabila penskalaan terkelola diaktifkan. Untuk klaster yang terdiri dari armada instans, metrik kapasitas klaster diukur dalam Units. Untuk klaster yang terdiri dari grup instans, metrik kapasitas klaster diukur dalam Nodes atau vCPU berdasarkan jenis unit yang digunakan dalam kebijakan penskalaan terkelola.
| Metrik | Deskripsi |
|---|---|
|
Jumlah total target units/nodes/vCPUs dalam sebuah cluster ditentukan oleh scaling terkelola. Unit: Count (Jumlah) |
|
Jumlah total saat ini yang units/nodes/vCPUs tersedia di cluster yang sedang berjalan. Ketika ada permintaan perubahan ukuran klaster, metrik ini akan diperbarui setelah instans baru ditambahkan atau dihapus dari klaster. Unit: Jumlah |
|
Jumlah target CORE units/nodes/vCPUs dalam cluster ditentukan oleh scaling terkelola. Unit: Count (Jumlah) |
|
Jumlah CORE saat ini units/nodes/vCPUs berjalan dalam sebuah cluster. Unit: Count (Jumlah) |
|
Jumlah target TASK units/nodes/vCPUs dalam klaster yang ditentukan oleh penskalaan terkelola. Unit: Count (Jumlah) |
|
Jumlah TASK saat ini units/nodes/vCPUs berjalan dalam sebuah cluster. Unit: Jumlah |
Metrik berikut menunjukkan status penggunaan klaster dan aplikasi. Metrik ini tersedia untuk semua fitur Amazon EMR, tetapi diterbitkan pada resolusi yang lebih tinggi dengan data pada rincian satu menit ketika penskalaan terkelola diaktifkan untuk sebuah klaster. Anda dapat mengkorelasikan metrik berikut dengan metrik kapasitas klaster di tabel sebelumnya untuk memahami keputusan penskalaan terkelola.
| Metrik | Deskripsi |
|---|---|
|
|
Jumlah aplikasi yang dikirimkan ke YARN yang telah selesai. Kasus penggunaan: Memantau kemajuan klaster Unit: Jumlah |
|
|
Jumlah aplikasi yang dikirimkan ke YARN yang berada dalam status tertunda. Kasus penggunaan: Memantau kemajuan klaster Unit: Jumlah |
|
|
Jumlah aplikasi yang dikirimkan ke YARN yang sedang berjalan. Kasus penggunaan: Memantau kemajuan klaster Unit: Jumlah |
ContainerAllocated |
Jumlah wadah sumber daya yang dialokasikan oleh. ResourceManager Kasus penggunaan: Memantau kemajuan klaster Unit: Jumlah |
|
|
Jumlah kontainer dalam antrean yang belum dialokasikan. Kasus penggunaan: Memantau kemajuan klaster Unit: Jumlah |
ContainerPendingRatio |
Rasio kontainer yang tertunda dengan kontainer yang dialokasikan (ContainerPendingRatio = ContainerPending / ContainerAllocated). Jika ContainerAllocated = 0, maka ContainerPendingRatio =ContainerPending. Nilai ContainerPendingRatio mewakili angka, bukan persentase. Nilai ini berguna untuk menskalakan sumber daya klaster berdasarkan perilaku alokasi kontainer. Unit: Jumlah |
|
|
Persentase penyimpanan HDFS yang saat ini digunakan. Kasus penggunaan: Menganalisis performa klaster Unit: Persen |
|
|
Menunjukkan bahwa klaster tidak lagi melakukan pekerjaan, tetapi masih hidup dan menimbulkan biaya. Diatur ke 1 jika tidak ada tugas yang berjalan dan tidak ada pekerjaan yang berjalan, dan diatur ke 0 jika sebaliknya. Nilai ini diperiksa pada interval lima menit dan nilai 1 hanya menunjukkan bahwa klaster tersebut menganggur ketika diperiksa, bukan bahwa klaster tersebut menganggur selama lima menit tersebut. Untuk menghindari positif yang salah, Anda harus menyalakan alarm ketika nilai ini 1 selama lebih dari satu pemeriksaan lima menit berturut-turut. Misalnya, Anda mungkin menyalakan alarm pada nilai ini jika telah 1 selama tiga puluh menit atau lebih. Kasus penggunaan: Memantau performa klaster Unit: Boolean |
|
|
Jumlah memori yang tersedia untuk dialokasikan. Kasus penggunaan: Memantau kemajuan klaster Unit: Jumlah |
|
|
Jumlah node yang saat ini menjalankan MapReduce tugas atau pekerjaan. Setara dengan metrik YARN Kasus penggunaan: Memantau kemajuan klaster Unit: Jumlah |
|
|
Persentase sisa memori yang tersedia untuk YARN (YARNMemoryAvailablePercentage = MemoryAvailable MB/MemoryTotalMB). Nilai ini berguna untuk menskalakan sumber daya klaster berdasarkan penggunaan memori YARN. Unit: Persen |
Metrik berikut memberikan informasi tentang sumber daya yang digunakan oleh wadah dan node YARN. Metrik dari manajer sumber daya YARN ini menawarkan wawasan tentang sumber daya yang digunakan oleh kontainer dan node yang berjalan di cluster. Membandingkan metrik ini dengan metrik kapasitas klaster tabel sebelumnya memberikan gambaran yang lebih jelas tentang dampak penskalaan terkelola:
| Metrik | Rilis terkait | Deskripsi |
|---|---|---|
|
|
Tersedia untuk merilis label 7.3.0 dan yang lebih tinggi |
Memori kontainer yang dikonsumsi* detik untuk periode penerbitan. Unit: GB* detik |
|
|
Tersedia untuk merilis label 7.3.0 dan yang lebih tinggi |
Total wadah benang * detik untuk periode penerbitan. Unit: GB* detik |
|
|
Tersedia untuk merilis label 7.5.0 dan lebih tinggi |
Kontainer yang dikonsumsi VCPU * detik untuk periode penerbitan. Unit: VCPU * detik |
|
Tersedia untuk merilis label 7.5.0 dan lebih tinggi |
Total kontainer VCPU * detik untuk periode penerbitan. Unit: VCPU * detik |
|
|
Tersedia untuk merilis label 7.5.0 dan lebih tinggi |
Memori node yang dikonsumsi * detik untuk periode penerbitan. Unit: GB* detik |
|
Tersedia untuk merilis label 7.5.0 dan lebih tinggi |
Total memori node * detik untuk periode penerbitan. Unit: GB* detik |
|
|
Tersedia untuk merilis label 7.3.0 dan yang lebih tinggi |
Node VCPU yang dikonsumsi * detik untuk periode penerbitan. Unit: VCPU * detik |
|
|
Tersedia untuk merilis label 7.3.0 dan yang lebih tinggi |
Total node VCPU * detik untuk periode penerbitan. Unit: VCPU * detik |
Membuat grafik metrik penskalaan terkelola
Anda dapat membuat grafik metrik untuk memvisualisasikan pola beban kerja klaster Anda dan keputusan penskalaan terkait yang dibuat oleh penskalaan terkelola Amazon EMR seperti yang ditunjukkan oleh langkah-langkah berikut.
Untuk membuat grafik metrik penskalaan terkelola di konsol CloudWatch
-
Buka konsol CloudWatch
. -
Di panel navigasi, pilih Amazon EMR. Anda dapat mencari di pengidentifikasi klaster pada klaster tersebut untuk memantau.
-
Gulir ke bawah ke metrik untuk membuat grafik. Buka metrik untuk menampilkan grafik.
-
Untuk membuat grafik pada satu metrik atau lebih, pilih kotak centang di samping setiap metrik.
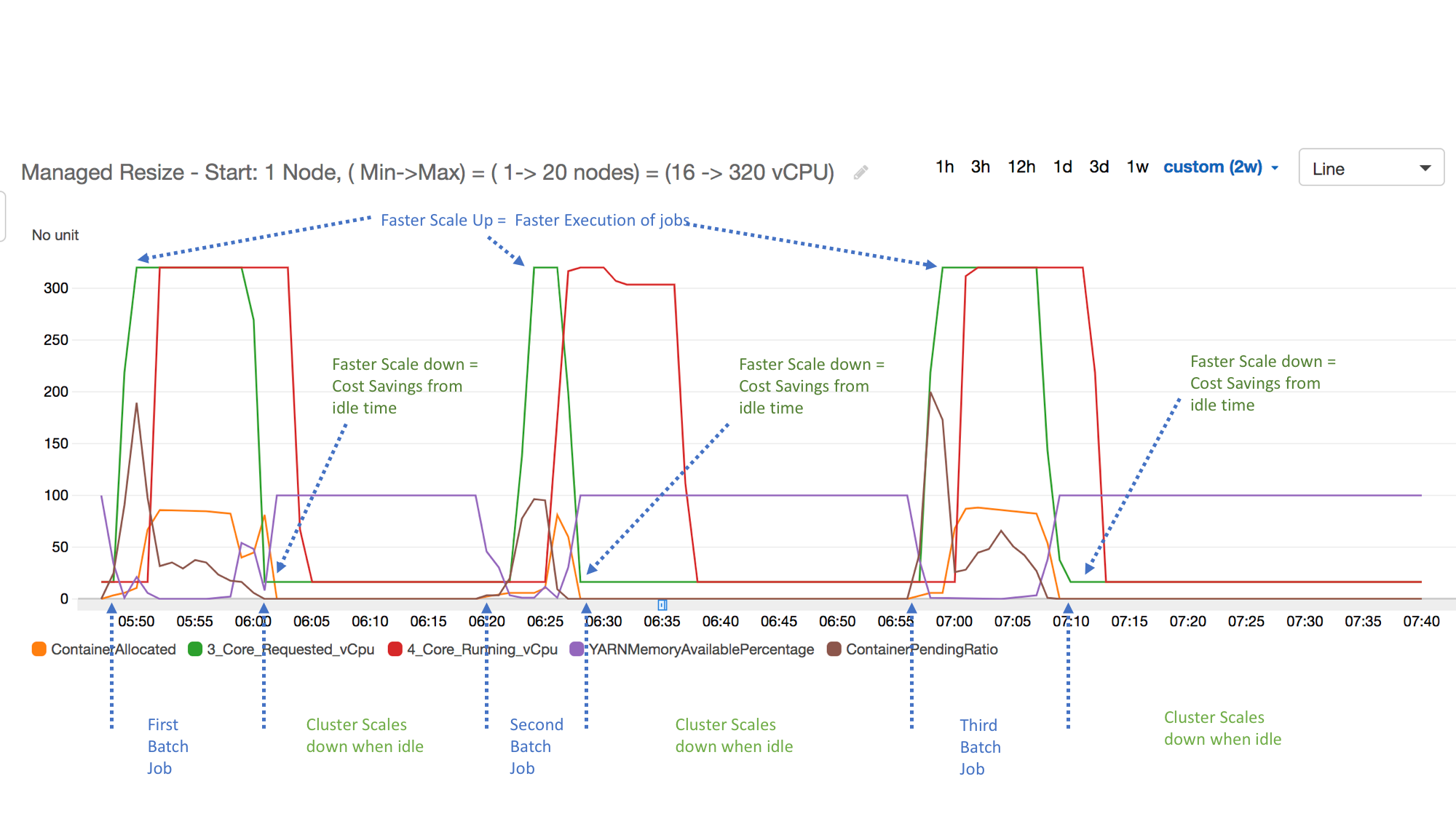
Contoh berikut menggambarkan aktivitas penskalaan terkelola Amazon EMR dari sebuah cluster. Grafik menunjukkan tiga periode penskalaan otomatis, yang menghemat biaya ketika ada beban kerja yang kurang aktif.
Semua metrik penggunaan dan kapasitas klaster dipublikasikan pada interval satu menit. Informasi statistik tambahan juga dikaitkan dengan setiap data satu menit, yang memungkinkan Anda merencanakan berbagai fungsi seperti Percentiles, Min, Max, Sum, Average, SampleCount.
Misalnya, grafik berikut menggambarkan metrik YARNMemoryAvailablePercentage yang sama pada persentil yang berbeda, P10, P50, P90, P99, bersama dengan Sum, Average, Min, SampleCount.