Amazon Forecast tidak lagi tersedia untuk pelanggan baru. Pelanggan Amazon Forecast yang ada dapat terus menggunakan layanan seperti biasa. Pelajari lebih lanjut”
Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Algoritma DeepAR+
Amazon Forecast DeepAR+ adalah algoritma pembelajaran yang diawasi untuk meramalkan deret waktu skalar (satu dimensi) menggunakan jaringan saraf berulang (). RNNs Metode peramalan klasik, seperti autoregressive integrated moving average (ARIMA) atau exponential smoothing (ETS), menyesuaikan model tunggal untuk setiap deret waktu individu, dan kemudian menggunakan model itu untuk mengekstrapolasi deret waktu ke masa depan. Namun, dalam banyak aplikasi, Anda memiliki banyak deret waktu serupa di satu set unit penampang. Pengelompokan deret waktu ini menuntut berbagai produk, beban server, dan permintaan untuk halaman web. Dalam hal ini, akan bermanfaat untuk melatih satu model bersama-sama di semua deret waktu. DeepAR+ mengambil pendekatan ini. Ketika kumpulan data Anda berisi ratusan deret waktu fitur, algoritme DeepAR+ mengungguli metode ARIMA dan ETS standar. Anda juga dapat menggunakan model terlatih untuk menghasilkan perkiraan untuk deret waktu baru yang mirip dengan yang telah dilatih.
Notebook Python
Untuk step-by-step panduan tentang penggunaan algoritma DeepAR+, lihat Memulai dengan
Bagaimana DeepAR+ Bekerja
Selama pelatihan, DeepAR+ menggunakan kumpulan data pelatihan dan kumpulan data pengujian opsional. Ini menggunakan dataset pengujian untuk mengevaluasi model terlatih. Secara umum, kumpulan data pelatihan dan pengujian tidak harus berisi rangkaian deret waktu yang sama. Anda dapat menggunakan model yang dilatih pada set pelatihan tertentu untuk menghasilkan perkiraan untuk masa depan deret waktu dalam set pelatihan, dan untuk deret waktu lainnya. Baik pelatihan dan kumpulan data pengujian terdiri dari (lebih disukai lebih dari satu) deret waktu target. Secara opsional, mereka dapat dikaitkan dengan vektor deret waktu fitur dan vektor fitur kategoris (untuk detailnya, lihat Antarmuka Input/Output DeepAR di Panduan Pengembang AI). SageMaker Contoh berikut menunjukkan cara kerjanya untuk elemen kumpulan data pelatihan yang diindeks oleh. i Dataset pelatihan terdiri dari deret waktu target,zi,t, dan dua rangkaian waktu fitur terkait, xi,1,t danxi,2,t.
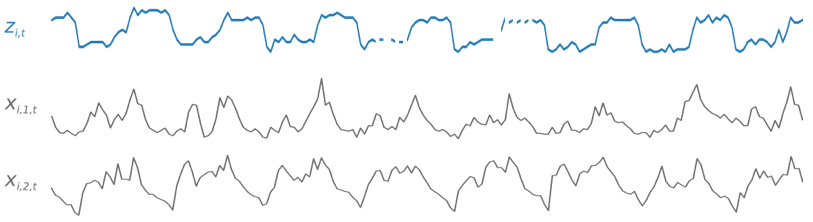
Deret waktu target mungkin berisi nilai yang hilang (dilambangkan dalam grafik dengan jeda dalam deret waktu). DeepAR+hanya mendukung fitur time series yang dikenal di masa depan. Ini memungkinkan Anda untuk menjalankan skenario “bagaimana-jika” kontrafaktual. Misalnya, “Apa yang terjadi jika saya mengubah harga suatu produk dengan cara tertentu?”
Setiap deret waktu target juga dapat dikaitkan dengan sejumlah fitur kategoris. Anda dapat menggunakan ini untuk menyandikan bahwa deret waktu milik pengelompokan tertentu. Menggunakan fitur kategoris memungkinkan model untuk mempelajari perilaku khas untuk pengelompokan tersebut, yang dapat meningkatkan akurasi. Sebuah model mengimplementasikan ini dengan mempelajari vektor embedding untuk setiap grup yang menangkap properti umum dari semua deret waktu dalam grup.
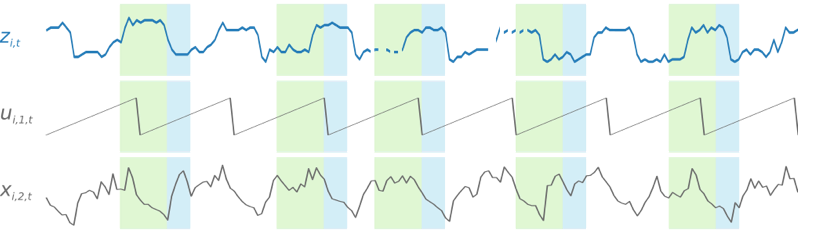
Untuk memfasilitasi pembelajaran pola yang bergantung pada waktu, seperti lonjakan selama akhir pekan, DeepAR+ secara otomatis membuat deret waktu fitur berdasarkan perincian deret waktu. Misalnya, DeepAR+ membuat dua rangkaian waktu fitur (hari dalam sebulan dan hari dalam setahun) pada frekuensi deret waktu mingguan. Ini menggunakan deret waktu fitur turunan ini bersama dengan deret waktu fitur khusus yang Anda berikan selama pelatihan dan inferensi. Contoh berikut menunjukkan dua fitur deret waktu turunan: ui,1,t mewakili jam dalam sehari, dan ui,2,t hari dalam seminggu.

DeepAR+ secara otomatis menyertakan rangkaian waktu fitur ini berdasarkan frekuensi data dan ukuran data pelatihan. Tabel berikut mencantumkan fitur yang dapat diturunkan untuk setiap frekuensi waktu dasar yang didukung.
| Frekuensi Deret Waktu | Fitur Berasal |
|---|---|
| Menit | minute-of-hour, hour-of-day, day-of-week, day-of-month, day-of-year |
| Jam | hour-of-day, day-of-week, day-of-month, day-of-year |
| Hari | day-of-week, day-of-month, day-of-year |
| Minggu | week-of-month, week-of-year |
| Bulan | month-of-year |
Model DeepAR+ dilatih dengan mengambil sampel secara acak beberapa contoh pelatihan dari masing-masing deret waktu dalam kumpulan data pelatihan. Setiap contoh pelatihan terdiri dari sepasang konteks dan jendela prediksi yang berdekatan dengan panjang yang telah ditentukan sebelumnya. context_lengthHyperparameter mengontrol seberapa jauh di masa lalu jaringan dapat melihat, dan ForecastHorizon parameter mengontrol seberapa jauh prediksi masa depan dapat dibuat. Selama pelatihan, Amazon Forecast mengabaikan elemen dalam kumpulan data pelatihan dengan deret waktu lebih pendek dari panjang prediksi yang ditentukan. Contoh berikut menunjukkan lima sampel, dengan panjang konteks (disorot dengan warna hijau) 12 jam dan panjang prediksi (disorot dengan warna biru) 6 jam, diambil dari elemeni. Demi singkatnya, kami telah mengecualikan deret waktu fitur xi,1,t danui,2,t.
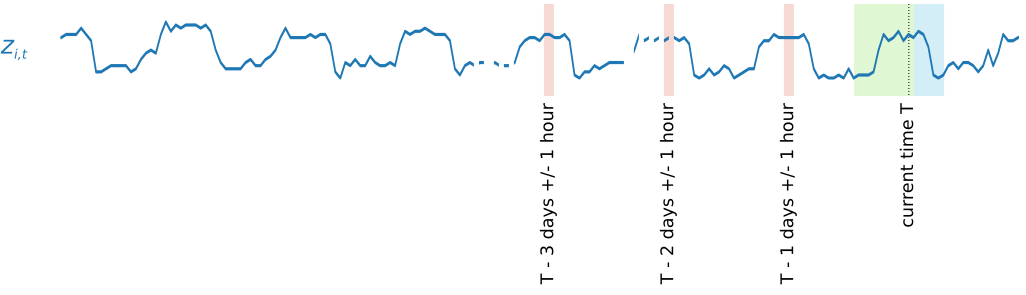
Untuk menangkap pola musiman, DeepAR+ juga secara otomatis memberi umpan nilai tertinggal (periode sebelumnya) dari deret waktu target. Dalam contoh kami dengan sampel yang diambil pada frekuensi per jam, untuk setiap indeks waktut = T, model memperlihatkan zi,t nilai yang terjadi kira-kira satu, dua, dan tiga hari di masa lalu (disorot dalam warna merah muda).
Untuk inferensi, model terlatih mengambil input deret waktu target, yang mungkin atau mungkin tidak digunakan selama pelatihan, dan memperkirakan distribusi probabilitas untuk ForecastHorizon nilai berikutnya. Karena DeepAR+ dilatih pada seluruh kumpulan data, perkiraan memperhitungkan pola yang dipelajari dari deret waktu yang serupa.
Untuk informasi tentang matematika di balik DeepAR +, lihat DeepAR: Peramalan Probabilistik dengan Jaringan Berulang Autoregresif
DeepAR+Hyperparameter
Tabel berikut mencantumkan hyperparameters yang dapat Anda gunakan dalam algoritma DeepAR+. Parameter dalam huruf tebal berpartisipasi dalam optimasi hyperparameter (HPO).
| Nama Parameter | Deskripsi |
|---|---|
context_length |
Jumlah titik waktu yang dibaca model sebelum membuat prediksi. Nilai untuk parameter ini harus hampir sama dengan
|
epochs |
Jumlah lintasan maksimum untuk memeriksa data pelatihan. Nilai optimal tergantung pada ukuran data dan tingkat pembelajaran Anda. Kumpulan data yang lebih kecil dan tingkat pembelajaran yang lebih rendah keduanya membutuhkan lebih banyak zaman, untuk mencapai hasil yang baik.
|
learning_rate |
Tingkat pembelajaran yang digunakan dalam pelatihan.
|
learning_rate_decay |
Tingkat di mana tingkat pembelajaran menurun. Paling-paling, tingkat pembelajaran dikurangi
|
likelihood |
Model menghasilkan perkiraan probabilistik, dan dapat memberikan kuantil distribusi dan sampel pengembalian. Bergantung pada data Anda, pilih kemungkinan yang sesuai (model kebisingan) yang digunakan untuk perkiraan ketidakpastian. Nilai valid
|
max_learning_rate_decays |
Jumlah maksimum pengurangan tingkat pembelajaran yang harus terjadi.
|
num_averaged_models |
Di DeepAR+, lintasan pelatihan dapat menemukan beberapa model. Setiap model mungkin memiliki kekuatan dan kelemahan peramalan yang berbeda. DeepAR+dapat rata-rata perilaku model untuk mengambil keuntungan dari kekuatan semua model.
|
num_cells |
Jumlah sel yang digunakan di setiap lapisan tersembunyi RNN.
|
num_layers |
Jumlah lapisan tersembunyi di RNN.
|
Model Tune DeepAR+
Untuk menyetel model Amazon Forecast DeepAR+, ikuti rekomendasi berikut untuk mengoptimalkan proses pelatihan dan konfigurasi perangkat keras.
Praktik Terbaik untuk Optimasi Proses
Untuk mencapai hasil terbaik, ikuti rekomendasi ini:
-
Kecuali saat membagi kumpulan data pelatihan dan pengujian, selalu sediakan seluruh deret waktu untuk pelatihan dan pengujian, dan saat memanggil model untuk inferensi. Terlepas dari bagaimana Anda mengatur
context_length, jangan membagi deret waktu atau hanya menyediakan sebagian saja. Model akan menggunakan titik data lebih jauh ke belakang daripadacontext_lengthfitur nilai tertinggal. -
Untuk penyetelan model, Anda dapat membagi kumpulan data menjadi kumpulan data pelatihan dan pengujian. Dalam skenario evaluasi yang khas, Anda harus menguji model pada deret waktu yang sama yang digunakan dalam pelatihan, tetapi pada titik
ForecastHorizonwaktu future segera setelah titik waktu terakhir terlihat selama pelatihan. Untuk membuat kumpulan data pelatihan dan pengujian yang memenuhi kriteria ini, gunakan seluruh kumpulan data (semua deret waktu) sebagai kumpulan data pengujian dan hapusForecastHorizonpoin terakhir dari setiap deret waktu untuk pelatihan. Dengan cara ini, selama pelatihan, model tidak melihat nilai target untuk titik waktu yang dievaluasi selama pengujian. Pada fase pengujian,ForecastHorizonpoin terakhir dari setiap deret waktu dalam kumpulan data pengujian ditahan dan prediksi dihasilkan. Perkiraan kemudian dibandingkan dengan nilai aktual untukForecastHorizonpoin terakhir. Anda dapat membuat evaluasi yang lebih kompleks dengan mengulangi deret waktu beberapa kali dalam kumpulan data pengujian, tetapi memotongnya pada titik akhir yang berbeda. Ini menghasilkan metrik akurasi yang dirata-ratakan pada beberapa perkiraan dari titik waktu yang berbeda. -
Hindari menggunakan nilai yang sangat besar (> 400)
ForecastHorizonkarena ini memperlambat model dan membuatnya kurang akurat. Jika Anda ingin meramalkan lebih jauh ke masa depan, pertimbangkan untuk menggabungkan ke frekuensi yang lebih tinggi. Misalnya, gunakan5minsebagai ganti dari1min. -
Karena kelambatan, model dapat melihat lebih jauh ke belakang daripada
context_length. Oleh karena itu, Anda tidak perlu mengatur parameter ini ke nilai yang besar. Titik awal yang baik untuk parameter ini adalah nilai yang sama denganForecastHorizon. -
Latih model DeepAR+ dengan deret waktu sebanyak yang tersedia. Meskipun model DeepAR+ yang dilatih pada satu deret waktu mungkin sudah bekerja dengan baik, metode peramalan standar seperti ARIMA atau ETS mungkin lebih akurat dan lebih disesuaikan dengan kasus penggunaan ini. DeepAR+ mulai mengungguli metode standar ketika kumpulan data Anda berisi ratusan deret waktu fitur. Saat ini, DeepAR+ mensyaratkan bahwa jumlah total pengamatan yang tersedia, di semua deret waktu pelatihan, setidaknya 300.
