Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Kembangkan dan uji AWS Glue pekerjaan secara lokal menggunakan image Docker
Untuk platform data siap produksi, proses pengembangan dan CI/CD saluran untuk AWS Glue pekerjaan adalah topik utama. Anda dapat mengembangkan dan menguji AWS Glue pekerjaan secara fleksibel dalam wadah Docker. AWS Glue meng-host gambar Docker di Docker Hub untuk mengatur lingkungan pengembangan Anda dengan utilitas tambahan. Anda dapat menggunakan IDE, notebook, atau REPL pilihan Anda menggunakan pustaka AWS Glue ETL. Topik ini menjelaskan cara mengembangkan dan menguji pekerjaan AWS Glue versi 5.0 dalam wadah Docker menggunakan gambar Docker.
Gambar Docker yang tersedia
Gambar Docker berikut tersedia untuk AWS Glue Amazon ECR
-
Untuk AWS Glue versi 5.0:
public.ecr.aws/glue/aws-glue-libs:5 -
Untuk AWS Glue versi 4.0:
public.ecr.aws/glue/aws-glue-libs:glue_libs_4.0.0_image_01 -
Untuk AWS Glue versi 3.0:
public.ecr.aws/glue/aws-glue-libs:glue_libs_3.0.0_image_01 -
Untuk AWS Glue versi 2.0:
public.ecr.aws/glue/aws-glue-libs:glue_libs_2.0.0_image_01
catatan
AWS Glue Gambar Docker kompatibel dengan x86_64 dan arm64.
Dalam contoh ini, kita menggunakan public.ecr.aws/glue/aws-glue-libs:5 dan menjalankan container pada mesin lokal (Mac, Windows, atau Linux). Gambar kontainer ini telah diuji untuk pekerjaan Spark AWS Glue versi 5.0. Gambar berisi yang berikut:
-
Amazon Linux 2023
-
AWS Glue Perpustakaan ETL
-
Apache Spark 3.5.4
-
Buka perpustakaan format tabel; Apache Iceberg 1.7.1, Apache Hudi 0.15.0, dan Delta Lake 3.3.0
-
AWS Glue Data Katalog Klien
-
Amazon Redshift konektor untuk Apache Spark
-
Amazon DynamoDB konektor untuk Apache Hadoop
Untuk menyiapkan wadah Anda, tarik gambar dari Galeri Publik ECR dan kemudian jalankan wadah. Topik ini menunjukkan cara menjalankan container Anda dengan metode berikut, tergantung pada kebutuhan Anda:
-
spark-submit -
Cangkang REPL
(pyspark) -
pytest -
Kode Studio Visual
Prasyarat
Sebelum Anda mulai, pastikan Docker diinstal dan daemon Docker sedang berjalan. Untuk petunjuk penginstalan, lihat dokumentasi Docker untuk Mac
Untuk informasi selengkapnya tentang pembatasan saat mengembangkan AWS Glue kode secara lokal, lihat Pembatasan pengembangan lokal.
Mengkonfigurasi AWS
Untuk mengaktifkan panggilan AWS API dari penampung, siapkan AWS kredensil dengan mengikuti langkah-langkah berikut. Di bagian berikut, kami akan menggunakan profil AWS bernama ini.
-
Buka
cmddi Windows atau terminal Mac/Linux dan jalankan perintah berikut di terminal:PROFILE_NAME="<your_profile_name>"
Di bagian berikut, kami menggunakan profil AWS bernama ini.
Jika Anda menjalankan Docker di Windows, pilih ikon Docker (klik kanan) dan pilih Beralih ke wadah Linux sebelum menarik gambar.
Jalankan perintah berikut untuk menarik gambar dari ECR Public:
docker pull public.ecr.aws/glue/aws-glue-libs:5
Jalankan wadah
Anda sekarang dapat menjalankan wadah menggunakan gambar ini. Anda dapat memilih salah satu dari berikut berdasarkan kebutuhan Anda.
spark-submit
Anda dapat menjalankan skrip AWS Glue pekerjaan dengan menjalankan spark-submit perintah pada wadah.
-
Tulis skrip Anda dan simpan seperti
sample.pypada contoh di bawah ini dan simpan di bawah/local_path_to_workspace/src/direktori menggunakan perintah berikut:$ WORKSPACE_LOCATION=/local_path_to_workspace $ SCRIPT_FILE_NAME=sample.py $ mkdir -p ${WORKSPACE_LOCATION}/src $ vim ${WORKSPACE_LOCATION}/src/${SCRIPT_FILE_NAME} -
Variabel ini digunakan dalam perintah docker run di bawah ini. Kode sampel (sample.py) yang digunakan dalam perintah spark-submit di bawah ini disertakan dalam lampiran di akhir topik ini.
Jalankan perintah berikut untuk menjalankan
spark-submitperintah pada wadah untuk mengirimkan aplikasi Spark baru:$ docker run -it --rm \ -v ~/.aws:/home /hadoop/.aws \ -v $WORKSPACE_LOCATION:/home/hadoop/workspace/ \ -e AWS_PROFILE=$PROFILE_NAME \ --name glue5_spark_submit \ public.ecr.aws/glue/aws-glue-libs:5 \ spark-submit /home/hadoop/workspace/src/$SCRIPT_FILE_NAME -
(Opsional) Konfigurasikan
spark-submitagar sesuai dengan lingkungan Anda. Misalnya, Anda dapat meneruskan dependensi Anda dengan konfigurasi.--jarsUntuk informasi lebih lanjut, lihat Dynamically Loading Spark Propertiesdi dokumentasi Spark.
Cangkang REPL (Pyspark)
Anda dapat menjalankan REPL (read-eval-print loops) shell untuk pengembangan interaktif. Jalankan perintah berikut untuk menjalankan PySpark perintah pada wadah untuk memulai shell REPL:
$ docker run -it --rm \ -v ~/.aws:/home/hadoop/.aws \ -e AWS_PROFILE=$PROFILE_NAME \ --name glue5_pyspark \ public.ecr.aws/glue/aws-glue-libs:5 \ pyspark
Anda akan melihat output berikut:
Python 3.11.6 (main, Jan 9 2025, 00:00:00) [GCC 11.4.1 20230605 (Red Hat 11.4.1-2)] on linux Type "help", "copyright", "credits" or "license" for more information. Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 3.5.4-amzn-0 /_/ Using Python version 3.11.6 (main, Jan 9 2025 00:00:00) Spark context Web UI available at None Spark context available as 'sc' (master = local[*], app id = local-1740643079929). SparkSession available as 'spark'. >>>
Dengan shell REPL ini, Anda dapat membuat kode dan menguji secara interaktif.
Pytest
Untuk pengujian unit, Anda dapat menggunakan pytest skrip pekerjaan AWS Glue Spark. Jalankan perintah berikut untuk persiapan.
$ WORKSPACE_LOCATION=/local_path_to_workspace $ SCRIPT_FILE_NAME=sample.py $ UNIT_TEST_FILE_NAME=test_sample.py $ mkdir -p ${WORKSPACE_LOCATION}/tests $ vim ${WORKSPACE_LOCATION}/tests/${UNIT_TEST_FILE_NAME}
Jalankan perintah berikut untuk menjalankan pytest menggunakandocker run:
$ docker run -i --rm \ -v ~/.aws:/home/hadoop/.aws \ -v $WORKSPACE_LOCATION:/home/hadoop/workspace/ \ --workdir /home/hadoop/workspace \ -e AWS_PROFILE=$PROFILE_NAME \ --name glue5_pytest \ public.ecr.aws/glue/aws-glue-libs:5 \ -c "python3 -m pytest --disable-warnings"
Setelah pytest selesai menjalankan pengujian unit, output Anda akan terlihat seperti ini:
============================= test session starts ============================== platform linux -- Python 3.11.6, pytest-8.3.4, pluggy-1.5.0 rootdir: /home/hadoop/workspace plugins: integration-mark-0.2.0 collected 1 item tests/test_sample.py . [100%] ======================== 1 passed, 1 warning in 34.28s =========================
Menyiapkan wadah untuk menggunakan Visual Studio Code
Untuk mengatur wadah dengan Visual Studio Code, selesaikan langkah-langkah berikut:
Instal Kode Visual Studio.
Instal Python
. Buka folder ruang kerja di Visual Studio Code.
Tekan
Ctrl+Shift+P(Windows/Linux) atauCmd+Shift+P(Mac).Ketik
Preferences: Open Workspace Settings (JSON).Tekan Enter.
Tempel JSON berikut dan simpan.
{ "python.defaultInterpreterPath": "/usr/bin/python3.11", "python.analysis.extraPaths": [ "/usr/lib/spark/python/lib/py4j-0.10.9.7-src.zip:/usr/lib/spark/python/:/usr/lib/spark/python/lib/", ] }
Untuk mengatur wadah:
-
Jalankan wadah Docker.
$ docker run -it --rm \ -v ~/.aws:/home/hadoop/.aws \ -v $WORKSPACE_LOCATION:/home/hadoop/workspace/ \ -e AWS_PROFILE=$PROFILE_NAME \ --name glue5_pyspark \ public.ecr.aws/glue/aws-glue-libs:5 \ pyspark -
Mulai Kode Visual Studio.
-
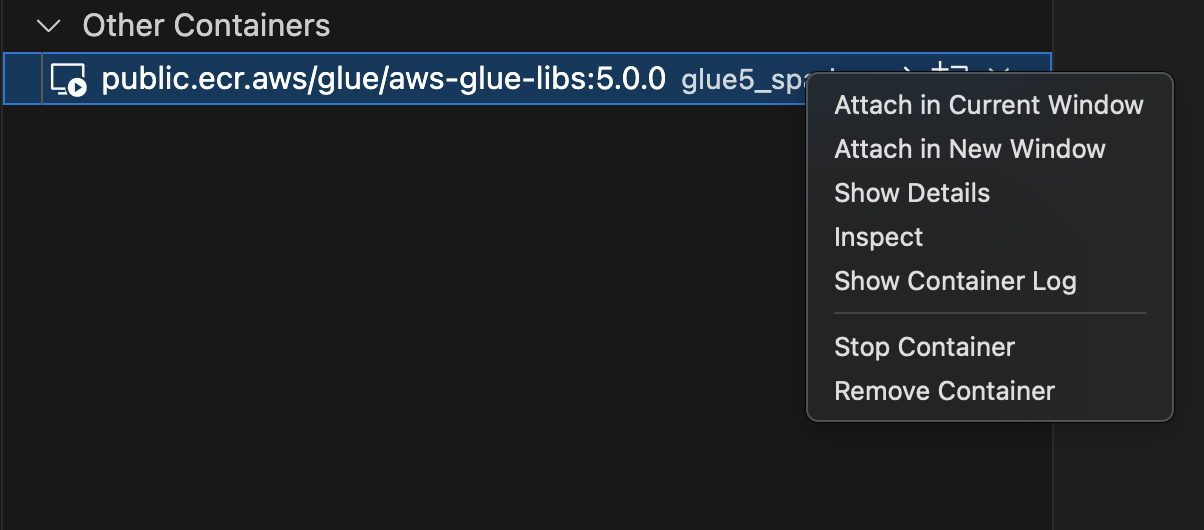
Pilih Remote Explorer di menu sebelah kiri, dan pilih
amazon/aws-glue-libs:glue_libs_4.0.0_image_01. -
Klik kanan dan pilih Lampirkan di Jendela Saat Ini.
-
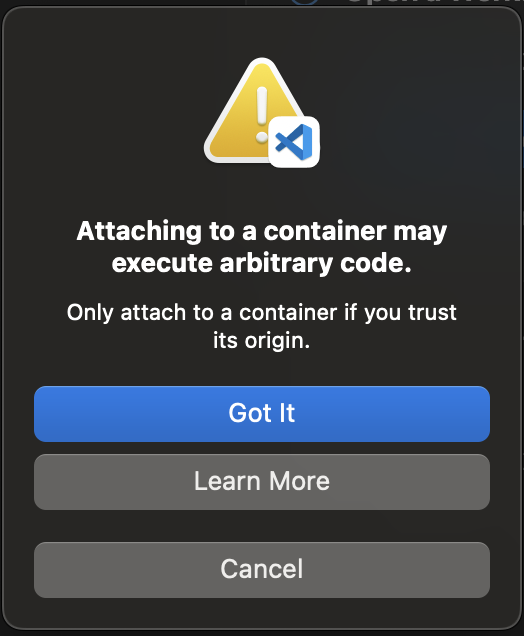
Jika dialog berikut muncul, pilih Mengerti.
-
Buka
/home/handoop/workspace/.
-
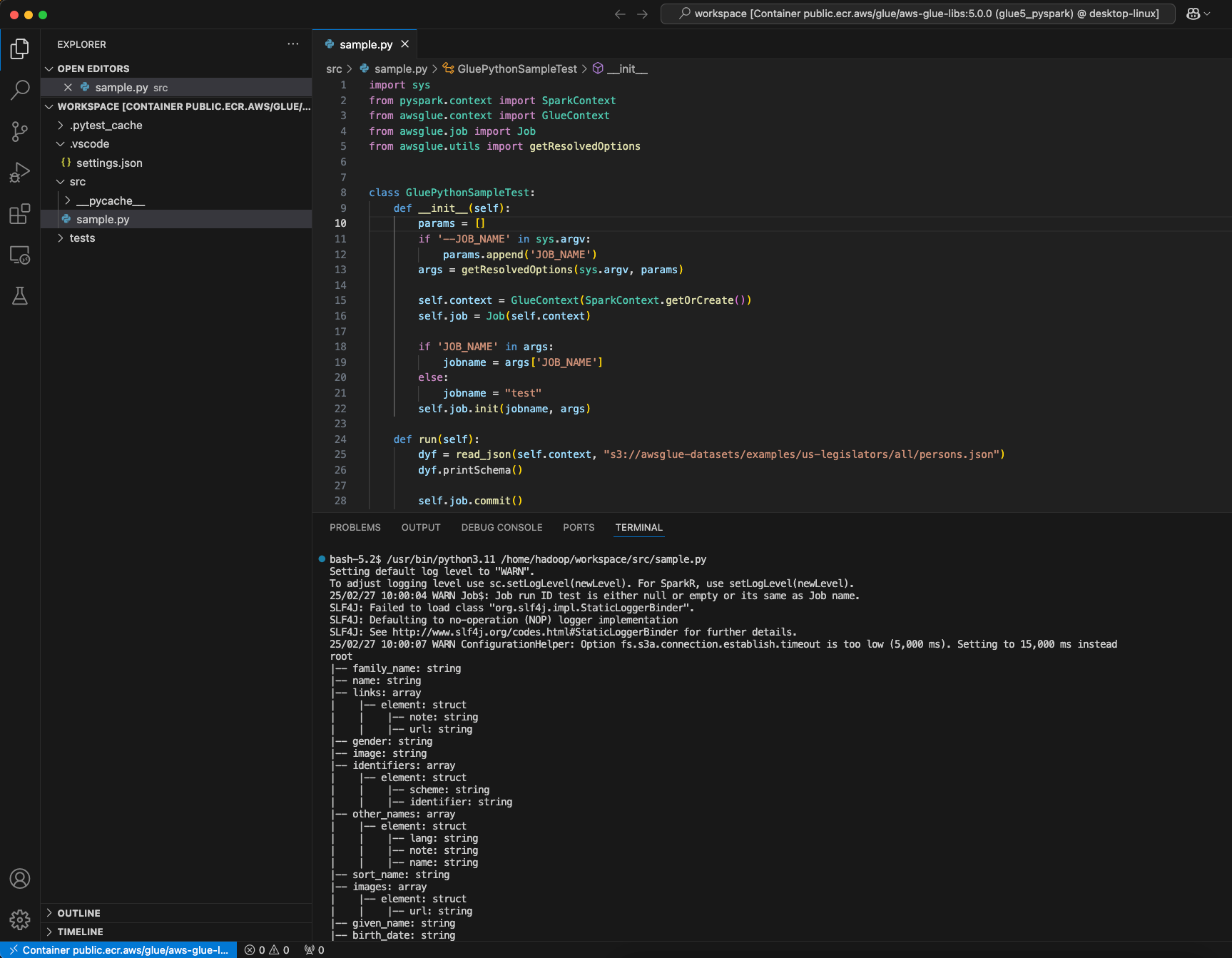
Buat AWS Glue PySpark skrip dan pilih Jalankan.
Anda akan melihat keberhasilan menjalankan skrip.
Perubahan antara gambar AWS Glue 4.0 dan AWS Glue 5.0 Docker
Perubahan besar antara gambar Docker AWS Glue 4.0 dan AWS Glue 5.0:
-
Di AWS Glue 5.0, ada gambar kontainer tunggal untuk pekerjaan batch dan streaming. Ini berbeda dari Glue 4.0, di mana ada satu gambar untuk batch dan satu lagi untuk streaming.
-
Di AWS Glue 5.0, nama pengguna default wadah adalah
hadoop. Di AWS Glue 4.0, nama pengguna default adalahglue_user. -
Di AWS Glue 5.0, beberapa perpustakaan tambahan termasuk JupyterLab dan Livy telah dihapus dari gambar. Anda dapat menginstalnya secara manual.
-
Di AWS Glue 5.0, semua pustaka Iceberg, Hudi dan Delta dimuat sebelumnya secara default, dan variabel lingkungan tidak lagi diperlukan.
DATALAKE_FORMATSSebelum AWS Glue 4.0, variabel lingkungan variabelDATALAKE_FORMATSlingkungan digunakan untuk menentukan format tabel tertentu yang harus dimuat.
Daftar di atas khusus untuk gambar Docker. Untuk mempelajari lebih lanjut tentang pembaruan AWS Glue 5.0, lihat Memperkenalkan AWS Glue 5.0 untuk Apache Spark
Pertimbangan
Perlu diingat bahwa fitur berikut tidak didukung saat menggunakan gambar AWS Glue kontainer untuk mengembangkan skrip pekerjaan secara lokal.
-
AWS Glue Penulis parket (Menggunakan format Parket di) AWS Glue
-
Properti customJdbcDriverS3Path untuk memuat driver JDBC dari jalur Amazon S3
-
AWS Lake Formation penjual kredenal berbasis izin
Lampiran: Menambahkan driver JDBC dan pustaka Java
Untuk menambahkan driver JDBC yang saat ini tidak tersedia di wadah, Anda dapat membuat direktori baru di bawah ruang kerja Anda dengan file JAR yang Anda butuhkan dan memasang direktori ke dalam perintah /opt/spark/jars/ docker run. File JAR yang ditemukan /opt/spark/jars/ di bawah wadah secara otomatis ditambahkan ke Spark Classpath dan akan tersedia untuk digunakan selama pekerjaan dijalankan.
Misalnya, gunakan perintah docker run berikut untuk menambahkan stoples driver JDBC ke shell REPL. PySpark
docker run -it --rm \ -v ~/.aws:/home/hadoop/.aws \ -v $WORKSPACE_LOCATION:/home/hadoop/workspace/ \ -v $WORKSPACE_LOCATION/jars/:/opt/spark/jars/ \ --workdir /home/hadoop/workspace \ -e AWS_PROFILE=$PROFILE_NAME \ --name glue5_jdbc \ public.ecr.aws/glue/aws-glue-libs:5 \ pyspark
Seperti yang disorot dalam Pertimbangan, opsi customJdbcDriverS3Path koneksi tidak dapat digunakan untuk mengimpor driver JDBC khusus dari Amazon S3 dalam gambar kontainer. AWS Glue
