Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Tutorial: Menulis skrip ETL AWS Glue untuk Ray
Ray memberi Anda kemampuan untuk menulis dan menskalakan tugas terdistribusi secara native dengan Python. AWS Glue untuk Ray menawarkan lingkungan Ray tanpa server yang dapat Anda akses dari pekerjaan dan sesi interaktif (sesi interaktif Ray dalam pratinjau). Sistem AWS Glue pekerjaan menyediakan cara yang konsisten untuk mengelola dan menjalankan tugas Anda—sesuai jadwal, dari pemicu, atau dari konsol. AWS Glue
Menggabungkan AWS Glue alat-alat ini menciptakan rantai alat yang kuat yang dapat Anda gunakan untuk mengekstrak, mengubah, dan memuat beban kerja (ETL), kasus penggunaan populer untuk. AWS Glue Dalam tutorial ini, Anda akan mempelajari dasar-dasar menyusun solusi ini.
Kami juga mendukung penggunaan Spark AWS Glue untuk beban kerja ETL Anda. Untuk tutorial tentang menulis skrip AWS Glue untuk Spark, lihatTutorial: Menulis AWS Glue untuk skrip Spark. Untuk informasi lebih lanjut tentang mesin yang tersedia, lihatAWS Glue untuk Spark dan AWS Glue untuk Ray. Ray mampu menangani berbagai jenis tugas dalam analitik, pembelajaran mesin (ML), dan pengembangan aplikasi.
Dalam tutorial ini, Anda akan mengekstrak, mengubah, dan memuat kumpulan data CSV yang di-host di Amazon Simple Storage Service (Amazon S3). Anda akan mulai dengan New York City Taxi and Limousine Commission (TLC) Trip Record Data Dataset, yang disimpan dalam ember Amazon S3 publik. Untuk informasi selengkapnya tentang kumpulan data ini, lihat Registry of Open Data pada AWS
Anda akan mengubah data Anda dengan transformasi yang telah ditentukan yang tersedia di perpustakaan Ray Data. Ray Data adalah pustaka persiapan kumpulan data yang dirancang oleh Ray dan disertakan secara default AWS Glue untuk lingkungan Ray. Untuk informasi selengkapnya tentang pustaka yang disertakan secara default, lihatModul disediakan dengan pekerjaan Ray. Anda kemudian akan menulis data yang diubah ke ember Amazon S3 yang Anda kontrol.
Prasyarat - Untuk tutorial ini, Anda memerlukan AWS akun dengan akses ke dan Amazon AWS Glue S3.
Langkah 1: Buat bucket di Amazon S3 untuk menyimpan data keluaran Anda
Anda akan memerlukan bucket Amazon S3 yang Anda kontrol untuk berfungsi sebagai wastafel untuk data yang dibuat dalam tutorial ini. Anda dapat membuat ember ini dengan prosedur berikut.
catatan
Jika Anda ingin menulis data ke bucket yang sudah ada yang Anda kontrol, Anda dapat melewati langkah ini. PerhatikanyourBucketName, nama bucket yang ada, untuk digunakan di langkah selanjutnya.
Untuk membuat bucket untuk output pekerjaan Ray Anda
-
Buat bucket dengan mengikuti langkah-langkah dalam Membuat bucket di Panduan Pengguna Amazon S3.
-
Saat memilih nama ember, perhatikan
yourBucketName, yang akan Anda rujuk di langkah selanjutnya. -
Untuk konfigurasi lain, pengaturan yang disarankan yang disediakan di konsol Amazon S3 akan berfungsi dengan baik dalam tutorial ini.
Sebagai contoh, kotak dialog pembuatan bucket mungkin terlihat seperti ini di konsol Amazon S3.
-
Langkah 2: Buat peran dan kebijakan IAM untuk pekerjaan Ray Anda
Pekerjaan Anda akan membutuhkan peran AWS Identity and Access Management (IAM) dengan yang berikut:
-
Izin yang diberikan oleh kebijakan
AWSGlueServiceRoleterkelola. Ini adalah izin dasar yang diperlukan untuk menjalankan AWS Glue pekerjaan. -
Readizin tingkat akses untuk sumber dayanyc-tlc/*Amazon S3. -
Writeizin tingkat akses untuk sumber dayayourBucketName/* -
Hubungan kepercayaan yang memungkinkan kepala
glue.amazonaws.comsekolah untuk mengambil peran.
Anda dapat membuat peran ini dengan prosedur berikut.
Untuk membuat peran IAM untuk pekerjaan Ray Anda AWS Glue
catatan
Anda dapat membuat peran IAM dengan mengikuti banyak prosedur yang berbeda. Untuk informasi selengkapnya atau opsi tentang cara menyediakan sumber daya IAM, lihat AWS Identity and Access Management dokumentasi.
-
Buat kebijakan yang menentukan izin Amazon S3 yang telah diuraikan sebelumnya dengan mengikuti langkah-langkah dalam Membuat kebijakan IAM (konsol) dengan editor visual di Panduan Pengguna IAM.
-
Saat memilih layanan, pilih Amazon S3.
-
Saat memilih izin untuk kebijakan Anda, lampirkan kumpulan tindakan berikut untuk sumber daya berikut (disebutkan sebelumnya):
-
Baca izin tingkat akses untuk sumber daya
nyc-tlc/*Amazon S3. -
Tulis izin tingkat akses untuk sumber daya
yourBucketName/*
-
-
Saat memilih nama kebijakan, perhatikan
YourPolicyName, yang akan Anda rujuk di langkah selanjutnya.
-
-
Buat peran untuk pekerjaan Ray Anda AWS Glue dengan mengikuti langkah-langkah dalam Membuat peran untuk AWS layanan (konsol) di Panduan Pengguna IAM.
-
Saat memilih entitas AWS layanan tepercaya, pilih
Glue. Ini secara otomatis akan mengisi hubungan kepercayaan yang diperlukan untuk pekerjaan Anda. -
Saat memilih kebijakan untuk kebijakan izin, lampirkan kebijakan berikut:
-
AWSGlueServiceRole -
YourPolicyName
-
-
Saat memilih nama peran, perhatikan
YourRoleName, yang akan Anda rujuk di langkah selanjutnya.
-
Langkah 3: Buat dan jalankan pekerjaan AWS Glue untuk Ray
Pada langkah ini, Anda membuat AWS Glue pekerjaan menggunakan AWS Management Console, menyediakannya dengan skrip contoh, dan menjalankan pekerjaan. Ketika Anda membuat pekerjaan, itu menciptakan tempat di konsol bagi Anda untuk menyimpan, mengkonfigurasi, dan mengedit skrip Ray Anda. Untuk informasi selengkapnya tentang cara membuat pekerjaan, lihat Mengelola AWS Glue Pekerjaan di AWS Konsol.
Dalam tutorial ini, kami membahas skenario ETL berikut: Anda ingin membaca catatan Januari 2022 dari kumpulan data Rekaman Perjalanan TLC Kota New York, menambahkan kolom baru (tip_rate) ke kumpulan data dengan menggabungkan data di kolom yang ada, lalu hapus sejumlah kolom yang tidak relevan dengan analisis Anda saat ini, dan kemudian Anda ingin menulis hasilnya. yourBucketName Skrip Ray berikut melakukan langkah-langkah ini:
import ray import pandas from ray import data ray.init('auto') ds = ray.data.read_csv("s3://nyc-tlc/opendata_repo/opendata_webconvert/yellow/yellow_tripdata_2022-01.csv") # Add the given new column to the dataset and show the sample record after adding a new column ds = ds.add_column( "tip_rate", lambda df: df["tip_amount"] / df["total_amount"]) # Dropping few columns from the underlying Dataset ds = ds.drop_columns(["payment_type", "fare_amount", "extra", "tolls_amount", "improvement_surcharge"]) ds.write_parquet("s3://yourBucketName/ray/tutorial/output/")
Untuk membuat dan menjalankan pekerjaan AWS Glue untuk Ray
-
Di AWS Management Console, navigasikan ke halaman AWS Glue arahan.
-
Di panel navigasi samping, pilih ETL Jobs.
-
Di Buat pekerjaan, pilih Editor skrip Ray, lalu pilih Buat, seperti pada ilustrasi berikut.
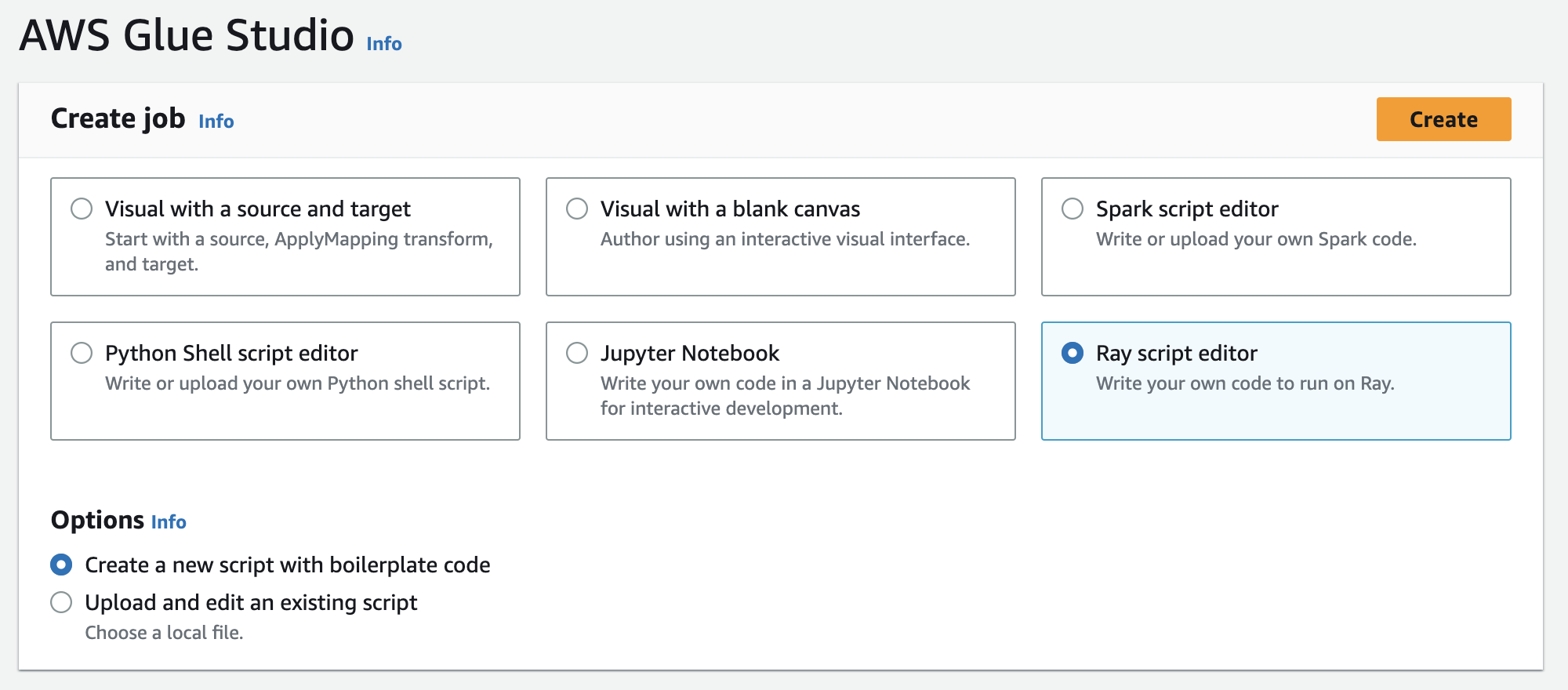
-
Tempelkan teks lengkap skrip ke panel Script, dan ganti teks yang ada.
-
Arahkan ke rincian Job dan atur properti IAM Role ke
YourRoleName. -
Pilih Simpan, lalu pilih Jalankan.
Langkah 4: Periksa output Anda
Setelah menjalankan AWS Glue pekerjaan Anda, Anda harus memvalidasi bahwa output sesuai dengan harapan skenario ini. Anda dapat melakukannya dengan prosedur berikut.
Untuk memvalidasi apakah pekerjaan Ray Anda berhasil
-
Di halaman detail pekerjaan, navigasikan ke Runs.
-
Setelah beberapa menit, Anda akan melihat run dengan status Run Succeeded.
-
Arahkan ke konsol Amazon S3 di https://console.aws.amazon.com/s3/
dan periksa. yourBucketNameAnda akan melihat file yang ditulis ke bucket keluaran Anda. -
Baca file Parket dan verifikasi isinya. Anda dapat melakukan ini dengan alat yang ada. Jika Anda tidak memiliki proses untuk memvalidasi file Parket, Anda dapat melakukannya di AWS Glue konsol dengan sesi AWS Glue interaktif, menggunakan Spark atau Ray (dalam pratinjau).
Dalam sesi interaktif, Anda memiliki akses ke perpustakaan Ray Data, Spark, atau panda, yang disediakan secara default (berdasarkan pilihan mesin Anda). Untuk memverifikasi konten file, Anda dapat menggunakan metode pemeriksaan umum yang tersedia di pustaka tersebut—metode seperti
count,, dan.schemashowUntuk informasi selengkapnya tentang sesi interaktif di konsol, lihat Menggunakan buku catatan dengan AWS Glue Studio dan AWS Glue.Karena Anda telah mengkonfirmasi bahwa file telah ditulis ke bucket, Anda dapat mengatakan dengan pasti relatif bahwa jika output Anda memiliki masalah, mereka tidak terkait dengan konfigurasi IAM. Konfigurasikan sesi Anda
yourRoleNameuntuk memiliki akses ke file yang relevan.
Jika Anda tidak melihat hasil yang diharapkan, periksa konten pemecahan masalah dalam panduan ini untuk mengidentifikasi dan memulihkan sumber kesalahan. Anda dapat menemukan konten pemecahan masalah di bagian ini. Pemecahan Masalah AWS Glue Untuk kesalahan spesifik yang terkait dengan pekerjaan Ray, lihat Pemecahan masalah AWS Glue untuk kesalahan Ray dari log di bagian pemecahan masalah.
Langkah selanjutnya
Anda sekarang telah melihat dan melakukan proses ETL menggunakan AWS Glue untuk Ray dari ujung ke ujung. Anda dapat menggunakan sumber daya berikut untuk memahami alat apa yang disediakan Ray AWS Glue untuk mengubah dan menafsirkan data Anda dalam skala besar.
-
Untuk informasi selengkapnya tentang model tugas Ray, lihatMenggunakan Ray Core dan Ray Data AWS Glue untuk Ray. Untuk lebih banyak pengalaman dalam menggunakan tugas Ray, ikuti contoh dalam dokumentasi Ray Core. Lihat Ray Core: Ray Tutorials and Examples (2.4.0)
dalam dokumentasi Ray. -
Untuk panduan tentang pustaka manajemen data yang tersedia AWS Glue untuk Ray, lihatMenghubungkan ke data dalam pekerjaan Ray. Untuk pengalaman lebih lanjut menggunakan Ray Data untuk mengubah dan menulis dataset, ikuti contoh dalam dokumentasi Ray Data. Lihat Data Sinar: Contoh (2.4.0)
. -
Untuk informasi selengkapnya tentang mengonfigurasi AWS Glue pekerjaan Ray, lihatBekerja dengan pekerjaan Ray di AWS Glue.
-
Untuk informasi lebih lanjut tentang menulis AWS Glue skrip Ray, lanjutkan membaca dokumentasi di bagian ini.
