Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Mengintegrasikan dengan Registri Skema AWS Glue
Bagian ini menjelaskan integrasi dengan registri AWS Glue skema. Contoh-contoh dalam bagian ini menunjukkan skema dengan format data AVRO. Untuk contoh lainnya, termasuk skema dengan format data JSON, lihat tes integrasi dan ReadMe informasi dalam repositori open source AWS Glue Schema Registry
Topik
Kasus penggunaan: Menghubungkan Registri Skema ke Amazon MSK atau Apache Kafka
Mari kita anggap Anda sedang menulis data ke topik Apache Kafka, dan Anda dapat mengikuti langkah-langkah untuk memulai.
Buat cluster Amazon Managed Streaming for Apache Kafka (Amazon MSK) atau Apache Kafka dengan setidaknya satu topik. Jika membuat sebuah klaster Amazon MSK, maka Anda dapat menggunakan AWS Management Console. Ikuti instruksi berikut: Mulai Menggunakan Amazon MSK di Panduan Developer Amazon Managed Streaming for Apache Kafka.
Ikuti langkah-langkah di atas Instalasi SerDe Perpustakaan.
Untuk membuat skema registri, skema, atau skema versi, ikuti petunjuk pada bagian Memulai dengan registri skema dalam dokumen ini.
Mulai produsen dan konsumen Anda untuk menggunakan Schema Registry untuk menulis dan membaca catatan to/from topik Amazon MSK atau Apache Kafka. Contoh kode produsen dan konsumen dapat ditemukan dalam ReadMe file dari
pustaka Serde. Perpustakaan Registri Skema pada produsen akan secara otomatis melakukan serialisasi pada catatan dan menghias catatan dengan ID versi skema. Jika skema dari catatan ini telah diinput, atau jika pendaftaran otomatis telah diaktifkan, maka skema akan telah terdaftar dalam Registri Skema.
Pembacaan konsumen dari topik Amazon MSK atau Apache Kafka, menggunakan perpustakaan Registri Skema AWS Glue, secara otomatis akan mencari skema dari Registri Skema.
Kasus penggunaan: Mengintegrasikan Amazon Kinesis Data Streams dengan Registri Skema AWS Glue
Integrasi ini mengharuskan Anda memiliki pengaliran data Amazon Kinesis Data Streams yang sudah ada. Untuk informasi selengkapnya, lihat Memulai Amazon Kinesis Data Streams? dalam Panduan Developer Amazon Kinesis Data Streams.
Ada dua cara untuk berinteraksi dengan data dalam pengaliran data Kinesis Data Streams.
Melalui perpustakaan Kinesis Producer Library (KPL) dan Kinesis Client Library (KCL) di Java. Support multi-bahasa tidak tersedia.
Melalui
PutRecords,PutRecord, danGetRecordsKinesis APIs Data Streams yang tersedia di. AWS SDK untuk Java
Jika saat ini Anda menggunakan KPL/KCL pustaka, kami sarankan untuk terus menggunakan metode itu. Ada versi KCL dan KPL yang diperbarui dengan Registri Skema terintegrasi, seperti yang ditunjukkan dalam contoh. Jika tidak, Anda dapat menggunakan kode sampel untuk memanfaatkan AWS Glue Schema Registry jika menggunakan KDS secara langsung. APIs
Integrasi Registri Skema ini hanya tersedia dengan KPL v0.14.2 atau yang lebih baru dan dengan KCL v2.3 atau yang lebih baru. Integrasi Registri Skema dengan format data JSON tersedia dengan KPL v0.14.8 atau yang lebih baru dan dengan KCL v2.3.6 atau yang lebih baru.
Berinteraksi dengan Data Menggunakan Kinesis SDK V2
Bagian ini menjelaskan cara berinteraksi dengan Kinesis menggunakan Kinesis SDK V2
// Example JSON Record, you can construct a AVRO record also private static final JsonDataWithSchema record = JsonDataWithSchema.builder(schemaString, payloadString); private static final DataFormat dataFormat = DataFormat.JSON; //Configurations for Schema Registry GlueSchemaRegistryConfiguration gsrConfig = new GlueSchemaRegistryConfiguration("us-east-1"); GlueSchemaRegistrySerializer glueSchemaRegistrySerializer = new GlueSchemaRegistrySerializerImpl(awsCredentialsProvider, gsrConfig); GlueSchemaRegistryDataFormatSerializer dataFormatSerializer = new GlueSchemaRegistrySerializerFactory().getInstance(dataFormat, gsrConfig); Schema gsrSchema = new Schema(dataFormatSerializer.getSchemaDefinition(record), dataFormat.name(), "MySchema"); byte[] serializedBytes = dataFormatSerializer.serialize(record); byte[] gsrEncodedBytes = glueSchemaRegistrySerializer.encode(streamName, gsrSchema, serializedBytes); PutRecordRequest putRecordRequest = PutRecordRequest.builder() .streamName(streamName) .partitionKey("partitionKey") .data(SdkBytes.fromByteArray(gsrEncodedBytes)) .build(); shardId = kinesisClient.putRecord(putRecordRequest) .get() .shardId(); GlueSchemaRegistryDeserializer glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(awsCredentialsProvider, gsrConfig); GlueSchemaRegistryDataFormatDeserializer gsrDataFormatDeserializer = glueSchemaRegistryDeserializerFactory.getInstance(dataFormat, gsrConfig); GetShardIteratorRequest getShardIteratorRequest = GetShardIteratorRequest.builder() .streamName(streamName) .shardId(shardId) .shardIteratorType(ShardIteratorType.TRIM_HORIZON) .build(); String shardIterator = kinesisClient.getShardIterator(getShardIteratorRequest) .get() .shardIterator(); GetRecordsRequest getRecordRequest = GetRecordsRequest.builder() .shardIterator(shardIterator) .build(); GetRecordsResponse recordsResponse = kinesisClient.getRecords(getRecordRequest) .get(); List<Object> consumerRecords = new ArrayList<>(); List<Record> recordsFromKinesis = recordsResponse.records(); for (int i = 0; i < recordsFromKinesis.size(); i++) { byte[] consumedBytes = recordsFromKinesis.get(i) .data() .asByteArray(); Schema gsrSchema = glueSchemaRegistryDeserializer.getSchema(consumedBytes); Object decodedRecord = gsrDataFormatDeserializer.deserialize(ByteBuffer.wrap(consumedBytes), gsrSchema.getSchemaDefinition()); consumerRecords.add(decodedRecord); }
Berinteraksi dengan data menggunakan pustaka KPL/KCL
Bagian ini menjelaskan integrasi Kinesis Data Streams dengan Schema Registry menggunakan pustaka. KPL/KCL Untuk informasi selengkapnya tentang KPL/KCL, lihat Mengembangkan Produsen Menggunakan Amazon Kinesis Producer Library dalam Panduan Developer Amazon Kinesis Data Streams.
Menyiapkan Registri Skema di KPL
Menentukan definisi skema untuk data, format data dan nama skema yang ditulis dalam Registri Skema AWS Glue.
Mengkonfigurasi objek
GlueSchemaRegistryConfiguration, opsional.Berikan objek skema ke
addUserRecord API.private static final String SCHEMA_DEFINITION = "{"namespace": "example.avro",\n" + " "type": "record",\n" + " "name": "User",\n" + " "fields": [\n" + " {"name": "name", "type": "string"},\n" + " {"name": "favorite_number", "type": ["int", "null"]},\n" + " {"name": "favorite_color", "type": ["string", "null"]}\n" + " ]\n" + "}"; KinesisProducerConfiguration config = new KinesisProducerConfiguration(); config.setRegion("us-west-1") //[Optional] configuration for Schema Registry. GlueSchemaRegistryConfiguration schemaRegistryConfig = new GlueSchemaRegistryConfiguration("us-west-1"); schemaRegistryConfig.setCompression(true); config.setGlueSchemaRegistryConfiguration(schemaRegistryConfig); ///Optional configuration ends. final KinesisProducer producer = new KinesisProducer(config); final ByteBuffer data = getDataToSend(); com.amazonaws.services.schemaregistry.common.Schema gsrSchema = new Schema(SCHEMA_DEFINITION, DataFormat.AVRO.toString(), "demoSchema"); ListenableFuture<UserRecordResult> f = producer.addUserRecord( config.getStreamName(), TIMESTAMP, Utils.randomExplicitHashKey(), data, gsrSchema); private static ByteBuffer getDataToSend() { org.apache.avro.Schema avroSchema = new org.apache.avro.Schema.Parser().parse(SCHEMA_DEFINITION); GenericRecord user = new GenericData.Record(avroSchema); user.put("name", "Emily"); user.put("favorite_number", 32); user.put("favorite_color", "green"); ByteArrayOutputStream outBytes = new ByteArrayOutputStream(); Encoder encoder = EncoderFactory.get().directBinaryEncoder(outBytes, null); new GenericDatumWriter<>(avroSchema).write(user, encoder); encoder.flush(); return ByteBuffer.wrap(outBytes.toByteArray()); }
Menyiapkan pustaka klien Kinesis
Anda akan mengembangkan konsumen Perpustakaan Klien Kinesis di Java. Untuk informasi selengkapnya tentang KCL, lihat Mengembangkan Konsumen Kinesis Client Librarydi Java dalam Panduan Developer Amazon Kinesis Data Streams.
Buat sebuah instans
GlueSchemaRegistryDeserializerdengan memberikan sebuah objekGlueSchemaRegistryConfiguration.Berikan
GlueSchemaRegistryDeserializerkeretrievalConfig.glueSchemaRegistryDeserializer.Mengakses skema pesan masuk dengan memanggil
kinesisClientRecord.getSchema().GlueSchemaRegistryConfiguration schemaRegistryConfig = new GlueSchemaRegistryConfiguration(this.region.toString()); GlueSchemaRegistryDeserializer glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(DefaultCredentialsProvider.builder().build(), schemaRegistryConfig); RetrievalConfig retrievalConfig = configsBuilder.retrievalConfig().retrievalSpecificConfig(new PollingConfig(streamName, kinesisClient)); retrievalConfig.glueSchemaRegistryDeserializer(glueSchemaRegistryDeserializer); Scheduler scheduler = new Scheduler( configsBuilder.checkpointConfig(), configsBuilder.coordinatorConfig(), configsBuilder.leaseManagementConfig(), configsBuilder.lifecycleConfig(), configsBuilder.metricsConfig(), configsBuilder.processorConfig(), retrievalConfig ); public void processRecords(ProcessRecordsInput processRecordsInput) { MDC.put(SHARD_ID_MDC_KEY, shardId); try { log.info("Processing {} record(s)", processRecordsInput.records().size()); processRecordsInput.records() .forEach( r -> log.info("Processed record pk: {} -- Seq: {} : data {} with schema: {}", r.partitionKey(), r.sequenceNumber(), recordToAvroObj(r).toString(), r.getSchema())); } catch (Throwable t) { log.error("Caught throwable while processing records. Aborting."); Runtime.getRuntime().halt(1); } finally { MDC.remove(SHARD_ID_MDC_KEY); } } private GenericRecord recordToAvroObj(KinesisClientRecord r) { byte[] data = new byte[r.data().remaining()]; r.data().get(data, 0, data.length); org.apache.avro.Schema schema = new org.apache.avro.Schema.Parser().parse(r.schema().getSchemaDefinition()); DatumReader datumReader = new GenericDatumReader<>(schema); BinaryDecoder binaryDecoder = DecoderFactory.get().binaryDecoder(data, 0, data.length, null); return (GenericRecord) datumReader.read(null, binaryDecoder); }
Berinteraksi dengan data menggunakan Kinesis Data Streams APIs
Bagian ini menjelaskan integrasi Kinesis Data Streams dengan Schema Registry menggunakan Kinesis Data Streams. APIs
Memperbarui dependensi Maven ini:
<dependencyManagement> <dependencies> <dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-java-sdk-bom</artifactId> <version>1.11.884</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <dependencies> <dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-java-sdk-kinesis</artifactId> </dependency> <dependency> <groupId>software.amazon.glue</groupId> <artifactId>schema-registry-serde</artifactId> <version>1.1.5</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.dataformat</groupId> <artifactId>jackson-dataformat-cbor</artifactId> <version>2.11.3</version> </dependency> </dependencies>Dalam produsen, tambahkan informasi header skema menggunakan
PutRecordsatau APIPutRecorddi Kinesis Data Streams.//The following lines add a Schema Header to the record com.amazonaws.services.schemaregistry.common.Schema awsSchema = new com.amazonaws.services.schemaregistry.common.Schema(schemaDefinition, DataFormat.AVRO.name(), schemaName); GlueSchemaRegistrySerializerImpl glueSchemaRegistrySerializer = new GlueSchemaRegistrySerializerImpl(DefaultCredentialsProvider.builder().build(), new GlueSchemaRegistryConfiguration(getConfigs())); byte[] recordWithSchemaHeader = glueSchemaRegistrySerializer.encode(streamName, awsSchema, recordAsBytes);Di produsen, gunakan
PutRecordsatau APIPutRecorduntuk menempatkan catatan ke dalam aliran data.Dalam konsumen, hapus catatan skema dari header, dan lakukan serialisasi pada catatan skema Avro.
//The following lines remove Schema Header from record GlueSchemaRegistryDeserializerImpl glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(DefaultCredentialsProvider.builder().build(), getConfigs()); byte[] recordWithSchemaHeaderBytes = new byte[recordWithSchemaHeader.remaining()]; recordWithSchemaHeader.get(recordWithSchemaHeaderBytes, 0, recordWithSchemaHeaderBytes.length); com.amazonaws.services.schemaregistry.common.Schema awsSchema = glueSchemaRegistryDeserializer.getSchema(recordWithSchemaHeaderBytes); byte[] record = glueSchemaRegistryDeserializer.getData(recordWithSchemaHeaderBytes); //The following lines serialize an AVRO schema record if (DataFormat.AVRO.name().equals(awsSchema.getDataFormat())) { Schema avroSchema = new org.apache.avro.Schema.Parser().parse(awsSchema.getSchemaDefinition()); Object genericRecord = convertBytesToRecord(avroSchema, record); System.out.println(genericRecord); }
Berinteraksi dengan data menggunakan Kinesis Data Streams APIs
Berikut ini adalah contoh kode untuk menggunakan PutRecords dan GetRecords APIs.
//Full sample code import com.amazonaws.services.schemaregistry.deserializers.GlueSchemaRegistryDeserializerImpl; import com.amazonaws.services.schemaregistry.serializers.GlueSchemaRegistrySerializerImpl; import com.amazonaws.services.schemaregistry.utils.AVROUtils; import com.amazonaws.services.schemaregistry.utils.AWSSchemaRegistryConstants; import org.apache.avro.Schema; import org.apache.avro.generic.GenericData; import org.apache.avro.generic.GenericDatumReader; import org.apache.avro.generic.GenericDatumWriter; import org.apache.avro.generic.GenericRecord; import org.apache.avro.io.Decoder; import org.apache.avro.io.DecoderFactory; import org.apache.avro.io.Encoder; import org.apache.avro.io.EncoderFactory; import software.amazon.awssdk.auth.credentials.DefaultCredentialsProvider; import software.amazon.awssdk.services.glue.model.DataFormat; import java.io.ByteArrayOutputStream; import java.io.File; import java.io.IOException; import java.nio.ByteBuffer; import java.util.Collections; import java.util.HashMap; import java.util.Map; public class PutAndGetExampleWithEncodedData { static final String regionName = "us-east-2"; static final String streamName = "testStream1"; static final String schemaName = "User-Topic"; static final String AVRO_USER_SCHEMA_FILE = "src/main/resources/user.avsc"; KinesisApi kinesisApi = new KinesisApi(); void runSampleForPutRecord() throws IOException { Object testRecord = getTestRecord(); byte[] recordAsBytes = convertRecordToBytes(testRecord); String schemaDefinition = AVROUtils.getInstance().getSchemaDefinition(testRecord); //The following lines add a Schema Header to a record com.amazonaws.services.schemaregistry.common.Schema awsSchema = new com.amazonaws.services.schemaregistry.common.Schema(schemaDefinition, DataFormat.AVRO.name(), schemaName); GlueSchemaRegistrySerializerImpl glueSchemaRegistrySerializer = new GlueSchemaRegistrySerializerImpl(DefaultCredentialsProvider.builder().build(), new GlueSchemaRegistryConfiguration(regionName)); byte[] recordWithSchemaHeader = glueSchemaRegistrySerializer.encode(streamName, awsSchema, recordAsBytes); //Use PutRecords api to pass a list of records kinesisApi.putRecords(Collections.singletonList(recordWithSchemaHeader), streamName, regionName); //OR //Use PutRecord api to pass single record //kinesisApi.putRecord(recordWithSchemaHeader, streamName, regionName); } byte[] runSampleForGetRecord() throws IOException { ByteBuffer recordWithSchemaHeader = kinesisApi.getRecords(streamName, regionName); //The following lines remove the schema registry header GlueSchemaRegistryDeserializerImpl glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(DefaultCredentialsProvider.builder().build(), new GlueSchemaRegistryConfiguration(regionName)); byte[] recordWithSchemaHeaderBytes = new byte[recordWithSchemaHeader.remaining()]; recordWithSchemaHeader.get(recordWithSchemaHeaderBytes, 0, recordWithSchemaHeaderBytes.length); com.amazonaws.services.schemaregistry.common.Schema awsSchema = glueSchemaRegistryDeserializer.getSchema(recordWithSchemaHeaderBytes); byte[] record = glueSchemaRegistryDeserializer.getData(recordWithSchemaHeaderBytes); //The following lines serialize an AVRO schema record if (DataFormat.AVRO.name().equals(awsSchema.getDataFormat())) { Schema avroSchema = new org.apache.avro.Schema.Parser().parse(awsSchema.getSchemaDefinition()); Object genericRecord = convertBytesToRecord(avroSchema, record); System.out.println(genericRecord); } return record; } private byte[] convertRecordToBytes(final Object record) throws IOException { ByteArrayOutputStream recordAsBytes = new ByteArrayOutputStream(); Encoder encoder = EncoderFactory.get().directBinaryEncoder(recordAsBytes, null); GenericDatumWriter datumWriter = new GenericDatumWriter<>(AVROUtils.getInstance().getSchema(record)); datumWriter.write(record, encoder); encoder.flush(); return recordAsBytes.toByteArray(); } private GenericRecord convertBytesToRecord(Schema avroSchema, byte[] record) throws IOException { final GenericDatumReader<GenericRecord> datumReader = new GenericDatumReader<>(avroSchema); Decoder decoder = DecoderFactory.get().binaryDecoder(record, null); GenericRecord genericRecord = datumReader.read(null, decoder); return genericRecord; } private Map<String, String> getMetadata() { Map<String, String> metadata = new HashMap<>(); metadata.put("event-source-1", "topic1"); metadata.put("event-source-2", "topic2"); metadata.put("event-source-3", "topic3"); metadata.put("event-source-4", "topic4"); metadata.put("event-source-5", "topic5"); return metadata; } private GlueSchemaRegistryConfiguration getConfigs() { GlueSchemaRegistryConfiguration configs = new GlueSchemaRegistryConfiguration(regionName); configs.setSchemaName(schemaName); configs.setAutoRegistration(true); configs.setMetadata(getMetadata()); return configs; } private Object getTestRecord() throws IOException { GenericRecord genericRecord; Schema.Parser parser = new Schema.Parser(); Schema avroSchema = parser.parse(new File(AVRO_USER_SCHEMA_FILE)); genericRecord = new GenericData.Record(avroSchema); genericRecord.put("name", "testName"); genericRecord.put("favorite_number", 99); genericRecord.put("favorite_color", "red"); return genericRecord; } }
Kasus penggunaan: Amazon Managed Service untuk Apache Flink
Apache Flink adalah sebuah kerangka kerja sumber terbuka populer dan mesin pengolahan terdistribusi untuk komputasi stateful atas aliran data yang tak terbatas dan dibatasi. Amazon Managed Service untuk Apache Flink adalah AWS layanan terkelola penuh yang memungkinkan Anda membangun dan mengelola aplikasi Apache Flink untuk memproses data streaming.
Apache Flink sumber terbuka menyediakan sejumlah sumber dan sink. Sebagai contoh, sumber data yang telah ditetapkan termasuk membaca dari file, direktori, dan soket, dan menyerap data dari koleksi dan iterator. DataStream Konektor Apache Flink menyediakan kode untuk Apache Flink untuk berinteraksi dengan berbagai sistem pihak ketiga, seperti Apache Kafka atau Kinesis sebagai sumber tenggelam. and/or
Untuk informasi lebih lanjut, lihat Panduan Developer Amazon Kinesis Data Analytics.
Konektor Apache Flink Kafka
Apache Flink menyediakan sebuah konektor aliran data Apache Kafka untuk membaca data dari dan menulis data untuk topik Kafka dengan jaminan persis-satu-kali. Konsumen Kafka Flink,FlinkKafkaConsumer, menyediakan akses untuk membaca dari satu atau lebih topik Kafka. Produsen Kafka dari Apache Flink, FlinkKafkaProducer, memungkinkan menulis aliran catatan untuk satu atau beberapa topik Kafka. Untuk informasi lebih lanjut, lihat Konektor Apache Kafka
Konektor aliran Kinesis Apache Flink
Konektor pengaliran data Kinesis menyediakan akses ke Amazon Kinesis Data Streams. FlinkKinesisConsumerIni adalah sumber data streaming paralel persis sekali yang berlangganan beberapa aliran Kinesis dalam wilayah layanan yang AWS sama, dan dapat secara transparan menangani re-sharding aliran saat pekerjaan sedang berjalan. Setiap subtugas konsumen bertanggung jawab untuk mengambil catatan data dari beberapa serpihan Kinesis. Jumlah serpihan yang diambil oleh setiap subtugas akan berubah karena serpihan ditutup dan dibuat oleh Kinesis. FlinkKinesisProducer menggunakan Kinesis Producer Library (KPL) untuk memasukkan data dari pengaliran Apache Flink ke pengaliran Kinesis. Untuk informasi selengkapnya, lihat Konektor Amazon Kinesis Streams
Untuk informasi lebih lanjut, lihat Repositori GitHub Skema AWS Glue
Mengintegrasikan dengan Apache Flink
SerDes Perpustakaan yang disediakan dengan Schema Registry terintegrasi dengan Apache Flink. Untuk bekerja dengan Apache Flink, Anda diharuskan untuk menerapkan antarmuka SerializationSchemaDeserializationSchemaGlueSchemaRegistryAvroSerializationSchema dan GlueSchemaRegistryAvroDeserializationSchema, yang dapat Anda hubungkan ke konektor Apache Flink.
Menambahkan ketergantungan AWS Glue Schema Registry ke dalam aplikasi Apache Flink
Untuk menyiapkan dependensi integrasi ke Registri Skema AWS Glue dalam aplikasi Apache Flink:
Tambahkan dependensi ke file
pom.xmlAnda.<dependency> <groupId>software.amazon.glue</groupId> <artifactId>schema-registry-flink-serde</artifactId> <version>1.0.0</version> </dependency>
Mengintegrasikan Kafka atau Amazon MSK dengan Apache Flink
Anda dapat menggunakan Managed Service untuk Apache Flink untuk Apache Flink, dengan Kafka sebagai sumber atau Kafka sebagai wastafel.
Kafka sebagai sumber
Diagram berikut menunjukkan integrasi Kinesis Data Streams dengan Managed Service untuk Apache Flink untuk Apache Flink, dengan Kafka sebagai sumber.
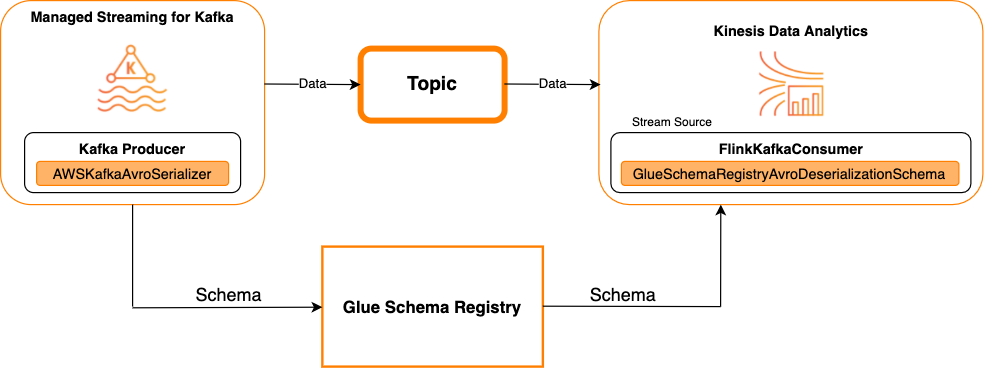
Kafka sebagai sebuah sink
Diagram berikut menunjukkan integrasi Kinesis Data Streams dengan Managed Service untuk Apache Flink untuk Apache Flink, dengan Kafka sebagai wastafel.
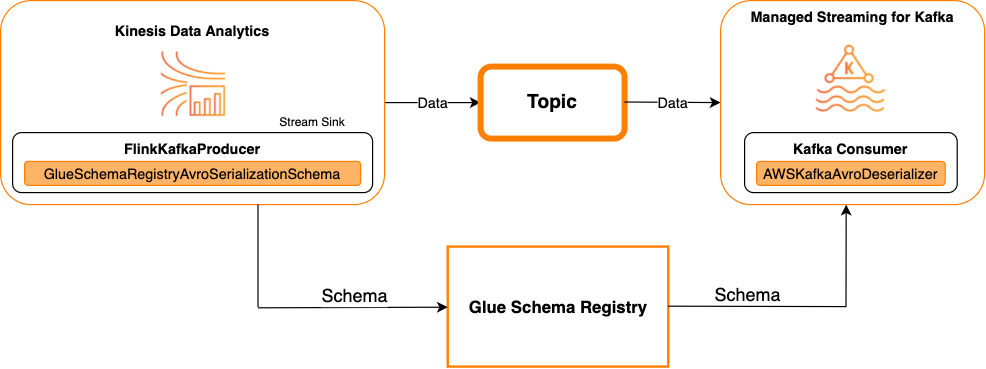
Untuk mengintegrasikan Kafka (atau Amazon MSK) dengan Managed Service untuk Apache Flink untuk Apache Flink, dengan Kafka sebagai sumber atau Kafka sebagai wastafel, buat perubahan kode di bawah ini. Tambahkan blok kode ditebalkan untuk kode Anda masing-masing di bagian analog.
Jika Kafka adalah sumbernya, maka gunakan kode deserializer (blok 2). Jika Kafka adalah sink-nya, maka gunakan kode serializer (blok 3).
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); String topic = "topic"; Properties properties = new Properties(); properties.setProperty("bootstrap.servers", "localhost:9092"); properties.setProperty("group.id", "test"); // block 1 Map<String, Object> configs = new HashMap<>(); configs.put(AWSSchemaRegistryConstants.AWS_REGION, "aws-region"); configs.put(AWSSchemaRegistryConstants.SCHEMA_AUTO_REGISTRATION_SETTING, true); configs.put(AWSSchemaRegistryConstants.AVRO_RECORD_TYPE, AvroRecordType.GENERIC_RECORD.getName()); FlinkKafkaConsumer<GenericRecord> consumer = new FlinkKafkaConsumer<>( topic, // block 2 GlueSchemaRegistryAvroDeserializationSchema.forGeneric(schema, configs), properties); FlinkKafkaProducer<GenericRecord> producer = new FlinkKafkaProducer<>( topic, // block 3 GlueSchemaRegistryAvroSerializationSchema.forGeneric(schema, topic, configs), properties); DataStream<GenericRecord> stream = env.addSource(consumer); stream.addSink(producer); env.execute();
Mengintegrasikan Kinesis Data Streams dengan Apache Flink
Anda dapat menggunakan Managed Service for Apache Flink untuk Apache Flink dengan Kinesis Data Streams sebagai sumber atau wastafel.
Kinesis Data Streams sebagai sebuah sumber
Diagram berikut menunjukkan integrasi Kinesis Data Streams dengan Managed Service untuk Apache Flink untuk Apache Flink, dengan Kinesis Data Streams sebagai sumber.
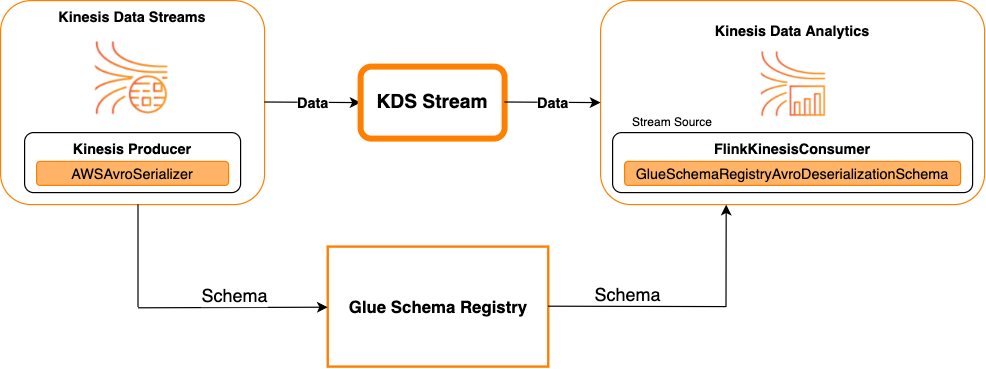
Kinesis Data Streams sebagai sebuah sink
Diagram berikut menunjukkan integrasi Kinesis Data Streams dengan Managed Service untuk Apache Flink untuk Apache Flink, dengan Kinesis Data Streams sebagai wastafel.

Untuk mengintegrasikan Kinesis Data Streams dengan Managed Service untuk Apache Flink untuk Apache Flink, dengan Kinesis Data Streams sebagai sumber atau Kinesis Data Streams sebagai sink, buat perubahan kode di bawah ini. Tambahkan blok kode ditebalkan untuk kode Anda masing-masing di bagian analog.
Jika Kinesis Data Streams adalah sumbernya, maka gunakan kode deserializer (blok 2). Jika Kinesis Data Streams adalah sink-nya, maka gunakan kode serializer (blok 3).
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); String streamName = "stream"; Properties consumerConfig = new Properties(); consumerConfig.put(AWSConfigConstants.AWS_REGION, "aws-region"); consumerConfig.put(AWSConfigConstants.AWS_ACCESS_KEY_ID, "aws_access_key_id"); consumerConfig.put(AWSConfigConstants.AWS_SECRET_ACCESS_KEY, "aws_secret_access_key"); consumerConfig.put(ConsumerConfigConstants.STREAM_INITIAL_POSITION, "LATEST"); // block 1 Map<String, Object> configs = new HashMap<>(); configs.put(AWSSchemaRegistryConstants.AWS_REGION, "aws-region"); configs.put(AWSSchemaRegistryConstants.SCHEMA_AUTO_REGISTRATION_SETTING, true); configs.put(AWSSchemaRegistryConstants.AVRO_RECORD_TYPE, AvroRecordType.GENERIC_RECORD.getName()); FlinkKinesisConsumer<GenericRecord> consumer = new FlinkKinesisConsumer<>( streamName, // block 2 GlueSchemaRegistryAvroDeserializationSchema.forGeneric(schema, configs), properties); FlinkKinesisProducer<GenericRecord> producer = new FlinkKinesisProducer<>( // block 3 GlueSchemaRegistryAvroSerializationSchema.forGeneric(schema, topic, configs), properties); producer.setDefaultStream(streamName); producer.setDefaultPartition("0"); DataStream<GenericRecord> stream = env.addSource(consumer); stream.addSink(producer); env.execute();
Kasus Penggunaan: Integrasi dengan AWS Lambda
Kasus penggunaan: AWS Glue Data Catalog
Tabel AWS Glue mendukung skema yang Anda dapat tentukan secara manual atau dengan me-referensi ke Registri Skema AWS Glue. Registri Skema terintegrasi dengan Katalog Data untuk memungkinkan Anda untuk secara opsional menggunakan skema yang disimpan dalam Registri Skema saat membuat atau memperbarui tabel atau partisi AWS Glue dalam Katalog Data. Untuk mengidentifikasi sebuah definisi skema dalam Registri Skema, minimal, Anda perlu mengetahui ARN dari skema yang ia menjadi bagiannya. Sebuah versi skema dari sebuah skema, yang berisi definisi skema, dapat direferensikan oleh UUID atau versi nomor. Selalu ada satu versi skema, yakni versi "terbaru", yang dapat dicari tanpa mengetahui nomor versi atau UUID.
Ketika memanggil operasi CreateTable atau UpdateTable, Anda akan memberikan sebuah struktur TableInput yang berisi StorageDescriptor, yang mungkin memiliki sebuah SchemaReference ke skema yang sudah ada di Registri Skema. Demikian pula, ketika Anda memanggil GetTable or GetPartition APIs, respons mungkin berisi skema dan. SchemaReference Ketika sebuah tabel atau partisi dibuat menggunakan sebuah referensi skema, Katalog Data akan mencoba untuk mengambil skema tersebut untuk referensi skema ini. Jika ia tidak dapat menemukan skema di Registri Skema, maka ia akan mengembalikan sebuah skema kosong di respons GetTable; jika tidak, responsnya akan memiliki skema dan referensi skema.
Anda juga dapat melakukan tindakan dari konsol AWS Glue.
Untuk melakukan operasi ini dan membuat, memperbarui, atau melihat informasi skema, Anda harus memberikan peran IAM kepada pengguna panggilan yang memberikan izin untuk API. GetSchemaVersion
Menambahkan tabel atau memperbarui skema untuk tabel
Menambahkan sebuah tabel baru dari skema yang ada mengikat tabel ke versi skema tertentu. Setelah versi skema baru didaftarkan, Anda dapat memperbarui definisi tabel ini dari halaman Lihat tabel di konsol AWS Glue atau menggunakan API UpdateTable tindakan (Python: update_table).
Menambahkan tabel dari skema yang ada
Anda dapat membuat sebuah tabel AWS Glue dari versi skema dalam registri dengan menggunakan konsol AWS Glue atau API CreateTable.
API AWS Glue
Ketika memanggil API CreateTable, Anda akan memberikan sebuah TableInput yang berisi StorageDescriptor yang memiliki SchemaReference ke sebuah skema yang sudah ada di Registri Skema.
Konsol AWS Glue
Untuk membuat sebuah tabel dari konsol AWS Glue:
-
Masuk ke AWS Management Console dan buka AWS Glue konsol di https://console.aws.amazon.com/glue/
. Di panel navigasi, pada Katalog data, pilih Tabel.
Di menu Tambahkan Tabel, pilih Tambahkan tabel dari skema yang ada.
Mengkonfigurasi properti tabel dan penyimpanan data sebagaimana dalam Panduan Developer AWS Glue.
Di halaman Pilih skema Glue, pilih Registri tempat skema berada.
Pilih Nama skema dan pilih Versi skema yang akan diterapkan.
Tinjau pratinjau skema, dan pilih Selanjutnya.
Tinjau dan buat tabel.
Skema dan versi yang diterapkan ke tabel muncul di kolom Skema Glue dalam daftar tabel. Anda dapat melihat tabel tersebut untuk melihat lebih detail.
Memperbarui skema untuk tabel
Ketika sebuah versi skema baru tersedia, Anda mungkin ingin memperbarui skema tabel menggunakan API UpdateTable tindakan (Python: update_table) atau konsol AWS Glue.
penting
Ketika memperbarui skema untuk sebuah tabel yang sudah ada yang memiliki skema AWS Glue yang ditentukan secara manual, skema baru yang direferensikan dalam Registri Skema mungkin tidak kompatibel. Hal ini dapat menyebabkan tugas Anda gagal.
API AWS Glue
Ketika memanggil API UpdateTable, Anda akan memberikan sebuah TableInput yang berisi StorageDescriptor yang memiliki SchemaReference ke sebuah skema yang sudah ada di Registri Skema.
Konsol AWS Glue
Untuk memperbarui skema untuk sebuah tabel dari konsol AWS Glue:
-
Masuk ke AWS Management Console dan buka AWS Glue konsol di https://console.aws.amazon.com/glue/
. Di panel navigasi, pada Katalog data, pilih Tabel.
Melihat tabel dari daftar tabel.
Klik Perbarui skema di kotak yang memberitahu Anda tentang versi baru.
Tinjau perbedaan antara skema saat ini dan skema baru.
Pilih Tampilkan semua perbedaan skema untuk melihat detail lebih lanjut.
Pilih Simpan tabel untuk menyetujui versi baru.
Kasus penggunaan: AWS Glue streaming
AWS Gluestreaming mengkonsumsi data dari sumber streaming dan melakukan operasi ETL sebelum menulis ke sink output. Sumber streaming input dapat ditentukan menggunakan Tabel Data atau langsung dengan menentukan konfigurasi sumber.
AWS Gluestreaming mendukung tabel Katalog Data untuk sumber streaming yang dibuat dengan skema yang ada di Registri AWS Glue Skema. Anda dapat membuat skema di AWS Glue Schema Registry dan membuat AWS Glue tabel dengan sumber streaming menggunakan skema ini. AWS GlueTabel ini dapat digunakan sebagai input ke pekerjaan AWS Glue streaming untuk deserialisasi data dalam aliran input.
Satu hal yang perlu diperhatikan di sini adalah ketika AWS Glue skema di Registri Skema berubah, Anda perlu memulai ulang pekerjaan AWS Glue streaming yang perlu mencerminkan perubahan dalam skema.
Kasus penggunaan: Apache Kafka Streams
API Apache Kafka Streams adalah sebuah perpustakaan klien untuk memproses dan menganalisis data yang disimpan di Apache Kafka. Bagian ini menjelaskan integrasi Apache Kafka Streams dengan Registri Skema AWS Glue, yang memungkinkan Anda untuk mengelola dan menegakkan skema pada aplikasi streaming data Anda. Untuk informasi lebih lanjut tentang Apache Kafka Streams, lihat Apache Kafka Streams
Integrasi dengan Library SerDes
Ada sebuah kelas GlueSchemaRegistryKafkaStreamsSerde yang dapat Anda konfigurasikan dengan sebuah aplikasi Streams.
Kode contoh aplikasi Kafka Streams
Untuk menggunakan Registri Skema AWS Glue dalam aplikasi Apache Kafka Streams:
Konfigurasikan aplikasi Kafka Streams.
final Properties props = new Properties(); props.put(StreamsConfig.APPLICATION_ID_CONFIG, "avro-streams"); props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); props.put(StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG, 0); props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName()); props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, AWSKafkaAvroSerDe.class.getName()); props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); props.put(AWSSchemaRegistryConstants.AWS_REGION, "aws-region"); props.put(AWSSchemaRegistryConstants.SCHEMA_AUTO_REGISTRATION_SETTING, true); props.put(AWSSchemaRegistryConstants.AVRO_RECORD_TYPE, AvroRecordType.GENERIC_RECORD.getName()); props.put(AWSSchemaRegistryConstants.DATA_FORMAT, DataFormat.AVRO.name());Buat sebuah pengaliran dari topik avro-input.
StreamsBuilder builder = new StreamsBuilder(); final KStream<String, GenericRecord> source = builder.stream("avro-input");Proses catatan data (contoh memfilter catatan-catatanyang nilai dari favorite_color adalah merah muda atau di mana nilainya adalah 15).
final KStream<String, GenericRecord> result = source .filter((key, value) -> !"pink".equals(String.valueOf(value.get("favorite_color")))); .filter((key, value) -> !"15.0".equals(String.valueOf(value.get("amount"))));Tulis hasilnya kembali ke topik avro-output.
result.to("avro-output");Mulai aplikasi Apache Kafka Streams.
KafkaStreams streams = new KafkaStreams(builder.build(), props); streams.start();
Hasil implementasi
Hasil ini menunjukkan proses penyaringan catatan yang disaring dalam langkah 3 sebagai favorite_color "merah muda" atau nilai "15,0".
Catatan sebelum penyaringan:
{"name": "Sansa", "favorite_number": 99, "favorite_color": "white"} {"name": "Harry", "favorite_number": 10, "favorite_color": "black"} {"name": "Hermione", "favorite_number": 1, "favorite_color": "red"} {"name": "Ron", "favorite_number": 0, "favorite_color": "pink"} {"name": "Jay", "favorite_number": 0, "favorite_color": "pink"} {"id": "commute_1","amount": 3.5} {"id": "grocery_1","amount": 25.5} {"id": "entertainment_1","amount": 19.2} {"id": "entertainment_2","amount": 105} {"id": "commute_1","amount": 15}
Catatan setelah penyaringan:
{"name": "Sansa", "favorite_number": 99, "favorite_color": "white"} {"name": "Harry", "favorite_number": 10, "favorite_color": "black"} {"name": "Hermione", "favorite_number": 1, "favorite_color": "red"} {"name": "Ron", "favorite_number": 0, "favorite_color": "pink"} {"id": "commute_1","amount": 3.5} {"id": "grocery_1","amount": 25.5} {"id": "entertainment_1","amount": 19.2} {"id": "entertainment_2","amount": 105}
Kasus penggunaan: Apache Kafka Connect
Integrasi Apache Kafka Connect dengan Registri Skema AWS Glue memungkinkan Anda untuk mendapatkan informasi skema dari konektor. Konverter Apache Kafka menentukan format data dalam Apache Kafka dan bagaimana menerjemahkannya ke data Apache Kafka Connect. Setiap pengguna Apache Kafka Connect akan diharuskan mengkonfigurasi konverter ini berdasarkan format data yang mereka inginkan di saat dimuat dari atau disimpan ke Apache Kafka. Dengan cara ini, Anda dapat menentukan konverter Anda sendiri untuk menerjemahkan data Apache Kafka Connect ke dalam jenis data yang digunakan dalam Registri Skema AWS Glue (misalnya: Avro) dan memanfaatkan serializer kami untuk mendaftarkan skemanya dan melakukan serialisasi. Kemudian konverter juga dapat menggunakan deserializer kami untuk melakukan deserialisasi data yang diterima dari Apache Kafka dan mengubahnya kembali ke data Apache Kafka Connect. Contoh diagram alur kerja ditunjukkan di bawah ini.
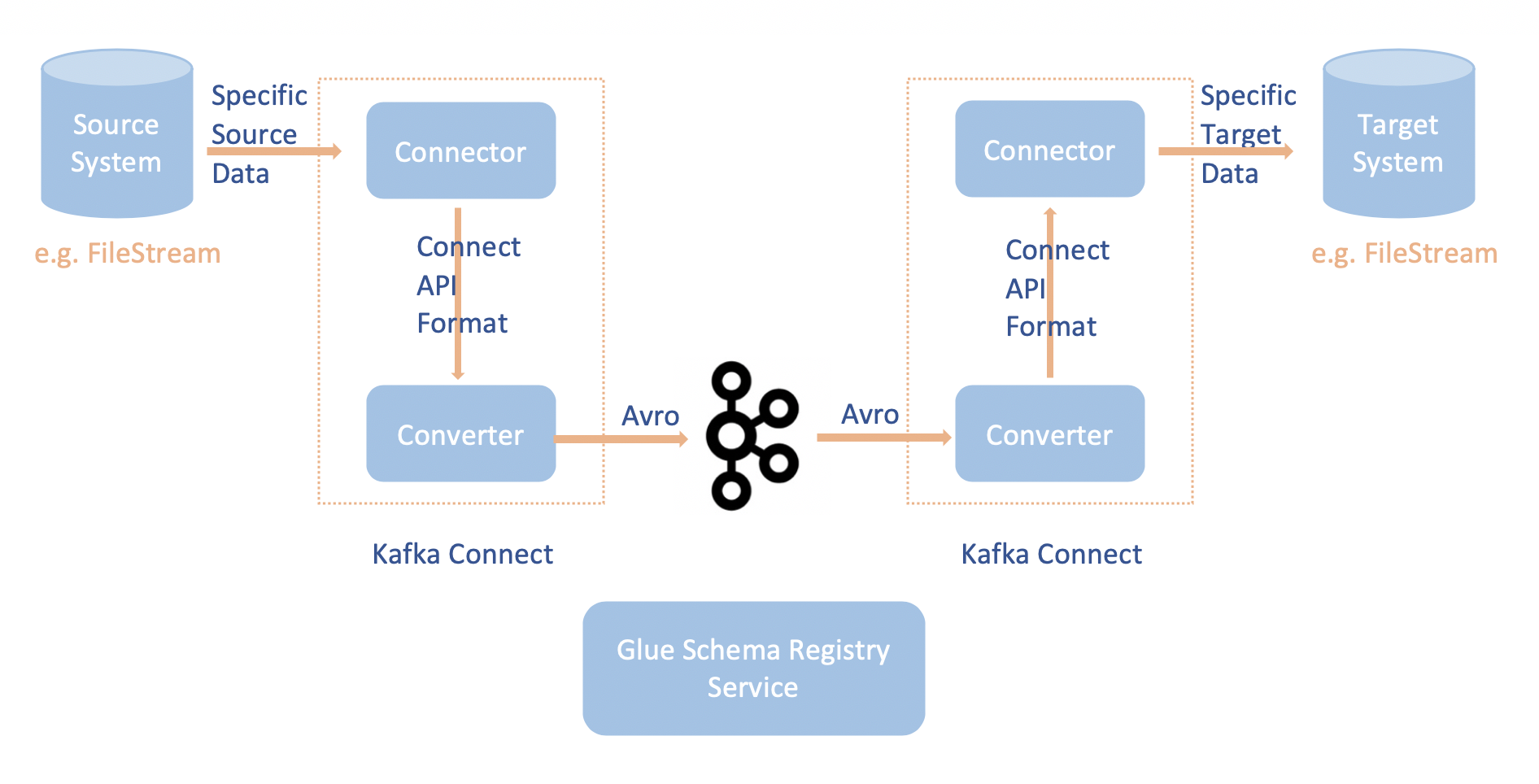
Menginstal proyek
aws-glue-schema-registrydengan mengkloning Repositori Github untuk Registri Skema AWS Glue. git clone git@github.com:awslabs/aws-glue-schema-registry.git cd aws-glue-schema-registry mvn clean install mvn dependency:copy-dependenciesJika Anda berencana untuk menggunakan Apache Kafka Connect dalam Mode Standalone, maka perbarui connect-standalone.properties dengan menggunakan langkah-langkah dalam petunjuk di bawah ini. Jika Anda berencana menggunakan Apache Kafka Connect dalam mode Distributed, perbarui connect-avro-distributed.properties menggunakan instruksi yang sama.
Tambahkan properti ini juga ke file properti connect Apache Kafka:
key.converter.region=aws-regionvalue.converter.region=aws-regionkey.converter.schemaAutoRegistrationEnabled=true value.converter.schemaAutoRegistrationEnabled=true key.converter.avroRecordType=GENERIC_RECORD value.converter.avroRecordType=GENERIC_RECORDTambahkan perintah di bawah ini ke bagian Mode peluncuran di kafka-run-classbawah.sh:
-cp $CLASSPATH:"<your AWS GlueSchema Registry base directory>/target/dependency/*"
Tambahkan perintah di bawah ini ke bagian Mode peluncuran di kafka-run-classbawah.sh
-cp $CLASSPATH:"<your AWS GlueSchema Registry base directory>/target/dependency/*"Seharusnya terlihat seperti ini:
# Launch mode if [ "x$DAEMON_MODE" = "xtrue" ]; then nohup "$JAVA" $KAFKA_HEAP_OPTS $KAFKA_JVM_PERFORMANCE_OPTS $KAFKA_GC_LOG_OPTS $KAFKA_JMX_OPTS $KAFKA_LOG4J_OPTS -cp $CLASSPATH:"/Users/johndoe/aws-glue-schema-registry/target/dependency/*" $KAFKA_OPTS "$@" > "$CONSOLE_OUTPUT_FILE" 2>&1 < /dev/null & else exec "$JAVA" $KAFKA_HEAP_OPTS $KAFKA_JVM_PERFORMANCE_OPTS $KAFKA_GC_LOG_OPTS $KAFKA_JMX_OPTS $KAFKA_LOG4J_OPTS -cp $CLASSPATH:"/Users/johndoe/aws-glue-schema-registry/target/dependency/*" $KAFKA_OPTS "$@" fiJika menggunakan bash, jalankan perintah di bawah ini untuk menyiapkan CLASSPATH Anda di bash_profile Anda. Untuk shell yang lain, perbarui lingkungannya sesuai dengan itu.
echo 'export GSR_LIB_BASE_DIR=<>' >>~/.bash_profile echo 'export GSR_LIB_VERSION=1.0.0' >>~/.bash_profile echo 'export KAFKA_HOME=<your Apache Kafka installation directory>' >>~/.bash_profile echo 'export CLASSPATH=$CLASSPATH:$GSR_LIB_BASE_DIR/avro-kafkaconnect-converter/target/schema-registry-kafkaconnect-converter-$GSR_LIB_VERSION.jar:$GSR_LIB_BASE_DIR/common/target/schema-registry-common-$GSR_LIB_VERSION.jar:$GSR_LIB_BASE_DIR/avro-serializer-deserializer/target/schema-registry-serde-$GSR_LIB_VERSION.jar' >>~/.bash_profile source ~/.bash_profile(Opsional) Jika Anda ingin menguji dengan sebuah sumber file sederhana, maka lakukan kloning pada konektor sumber file.
git clone https://github.com/mmolimar/kafka-connect-fs.git cd kafka-connect-fs/Pada konfigurasi konektor sumber, edit format data ke Avro, pembaca file ke
AvroFileReaderdan perbarui contoh objek Avro dari path file yang Anda gunakan untuk membacanya. Misalnya:vim config/kafka-connect-fs.propertiesfs.uris=<path to a sample avro object> policy.regexp=^.*\.avro$ file_reader.class=com.github.mmolimar.kafka.connect.fs.file.reader.AvroFileReaderInstal konektor sumber.
mvn clean package echo "export CLASSPATH=\$CLASSPATH:\"\$(find target/ -type f -name '*.jar'| grep '\-package' | tr '\n' ':')\"" >>~/.bash_profile source ~/.bash_profilePerbarui properti sink pada
<your Apache Kafka installation directory>/config/connect-file-sink.propertiesfile=<output file full path> topics=<my topic>
Mulai Konektor Sumber (dalam contoh ini, ia adalah konektor sumber file).
$KAFKA_HOME/bin/connect-standalone.sh $KAFKA_HOME/config/connect-standalone.properties config/kafka-connect-fs.propertiesJalankan Konektor Sink (dalam contoh ini ia adalah konektor sink file).
$KAFKA_HOME/bin/connect-standalone.sh $KAFKA_HOME/config/connect-standalone.properties $KAFKA_HOME/config/connect-file-sink.propertiesUntuk contoh penggunaan Kafka Connect, lihat run-local-tests skrip.sh di bawah folder integration-tests di repositori Github
untuk Schema Registry. AWS Glue
