Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Apa itu Amazon Managed Service untuk Apache Flink?
Dengan Amazon Managed Service untuk Apache Flink, Anda dapat menggunakan Java, Scala, Python, atau SQL untuk memproses dan menganalisis data streaming. Layanan ini memungkinkan Anda untuk membuat dan menjalankan kode terhadap sumber streaming dan sumber statis untuk melakukan analitik deret waktu, memberi umpan dasbor waktu nyata, dan metrik.
Anda dapat membangun aplikasi dengan bahasa pilihan Anda di Managed Service for Apache Flink menggunakan pustaka open-source berdasarkan Apache Flink.
Managed Service for Apache Flink menyediakan infrastruktur dasar untuk aplikasi Apache Flink Anda. Ini menangani kemampuan inti seperti penyediaan sumber daya komputasi, ketahanan failover AZ, komputasi paralel, penskalaan otomatis, dan pencadangan aplikasi (diimplementasikan sebagai pos pemeriksaan dan snapshot). Anda dapat menggunakan fitur pemrograman Flink tingkat tinggi (seperti operator, fungsi, sumber, dan sink) dengan cara yang sama seperti Anda menggunakannya ketika meng-host infrastruktur Flink Anda sendiri.
Tentukan antara menggunakan Managed Service untuk Apache Flink atau Managed Service untuk Apache Flink Studio
Anda memiliki dua opsi untuk menjalankan pekerjaan Flink Anda dengan Amazon Managed Service untuk Apache Flink. Dengan Managed Service for Apache Flink, Anda membangun aplikasi Flink di Java, Scala, atau Python (dan tertanam SQL) menggunakan IDE pilihan Anda dan Apache Flink Datastream atau Table. APIs Dengan Managed Service for Apache Flink Studio, Anda dapat secara interaktif menanyakan aliran data secara real time dan dengan mudah membangun dan menjalankan aplikasi pemrosesan aliran menggunakan SQL, Python, dan Scala standar.
Anda dapat memilih metode mana yang paling sesuai dengan kasus penggunaan Anda. Jika Anda tidak yakin, bagian ini akan menawarkan panduan tingkat tinggi untuk membantu Anda.
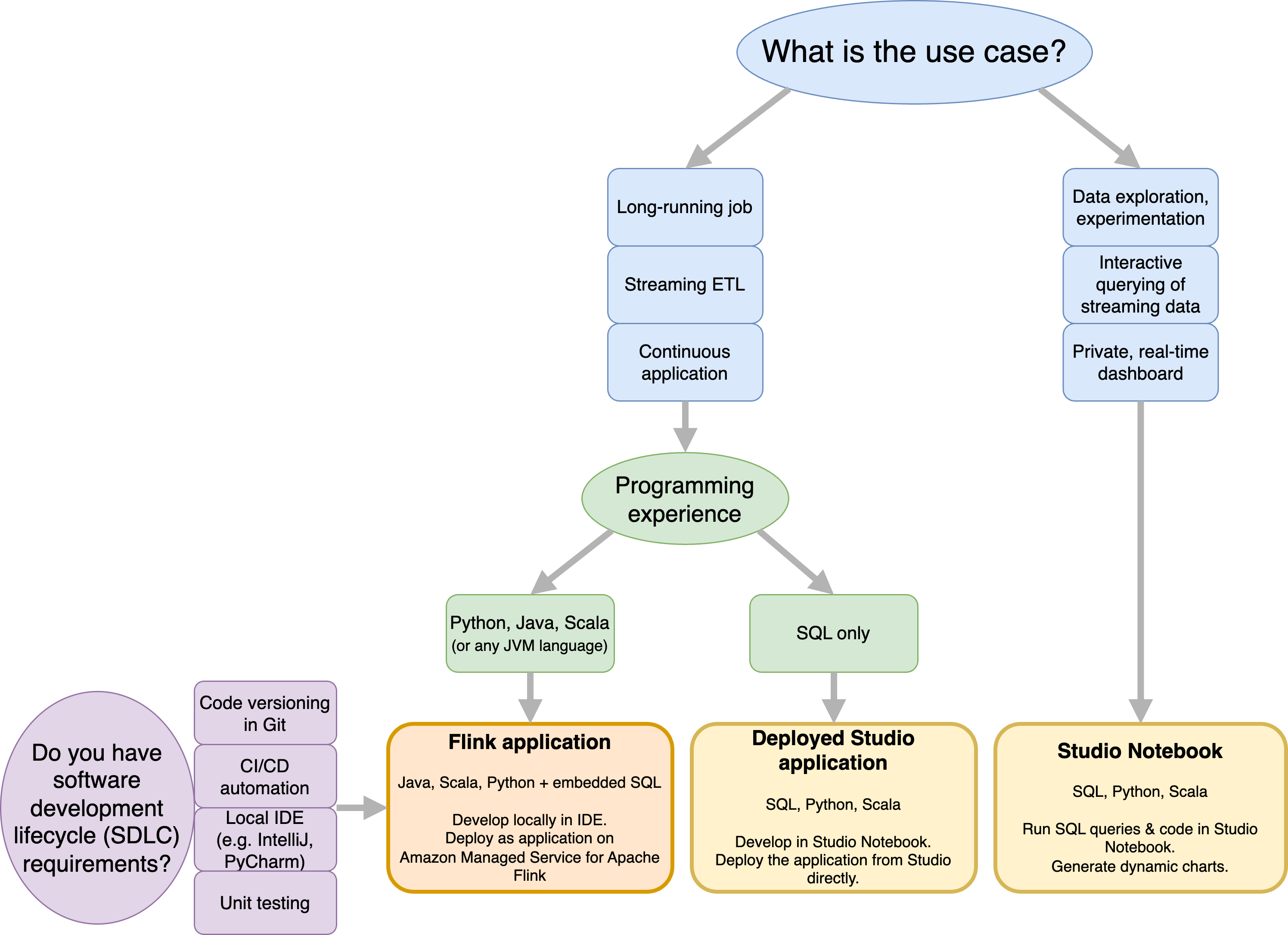
Sebelum memutuskan apakah akan menggunakan Amazon Managed Service untuk Apache Flink atau Amazon Managed Service untuk Apache Flink Studio Anda harus mempertimbangkan kasus penggunaan Anda.
Jika Anda berencana untuk mengoperasikan aplikasi yang berjalan lama yang akan melakukan beban kerja seperti Streaming ETL atau Aplikasi Berkelanjutan, Anda harus mempertimbangkan untuk menggunakan Layanan Terkelola untuk Apache Flink. Ini karena Anda dapat membuat aplikasi Flink Anda menggunakan Flink APIs langsung di IDE pilihan Anda. Mengembangkan secara lokal dengan IDE Anda juga memastikan Anda dapat memanfaatkan proses dan perkakas umum siklus hidup pengembangan perangkat lunak (SDLC) seperti pembuatan versi kode di Git, otomatisasi, atau pengujian unit. CI/CD
Jika Anda tertarik dengan eksplorasi data ad-hoc, ingin menanyakan data streaming secara interaktif, atau membuat dasbor real-time pribadi, Managed Service for Apache Flink Studio akan membantu Anda memenuhi tujuan ini hanya dengan beberapa klik. Pengguna yang akrab dengan SQL dapat mempertimbangkan untuk menerapkan aplikasi yang berjalan lama dari Studio secara langsung.
catatan
Anda dapat mempromosikan notebook Studio Anda ke aplikasi yang sudah berjalan lama. Namun, jika Anda ingin mengintegrasikan dengan alat SDLC Anda seperti pembuatan versi kode pada Git CI/CD dan otomatisasi, atau teknik seperti pengujian unit, kami merekomendasikan Layanan Terkelola untuk Apache Flink menggunakan IDE pilihan Anda.
Pilih Apache Flink APIs mana yang akan digunakan dalam Managed Service untuk Apache Flink
Anda dapat membangun aplikasi menggunakan Java, Python, dan Scala di Managed Service untuk Apache Flink menggunakan Apache Flink APIs dalam IDE pilihan Anda. Anda dapat menemukan panduan tentang cara membangun aplikasi menggunakan Flink Datastream dan Table API dalam dokumentasi. Anda dapat memilih bahasa tempat Anda membuat aplikasi Flink dan yang APIs Anda gunakan untuk memenuhi kebutuhan aplikasi dan operasi Anda dengan sebaik-baiknya. Jika Anda tidak yakin, bagian ini memberikan panduan tingkat tinggi untuk membantu Anda.
Pilih API Flink
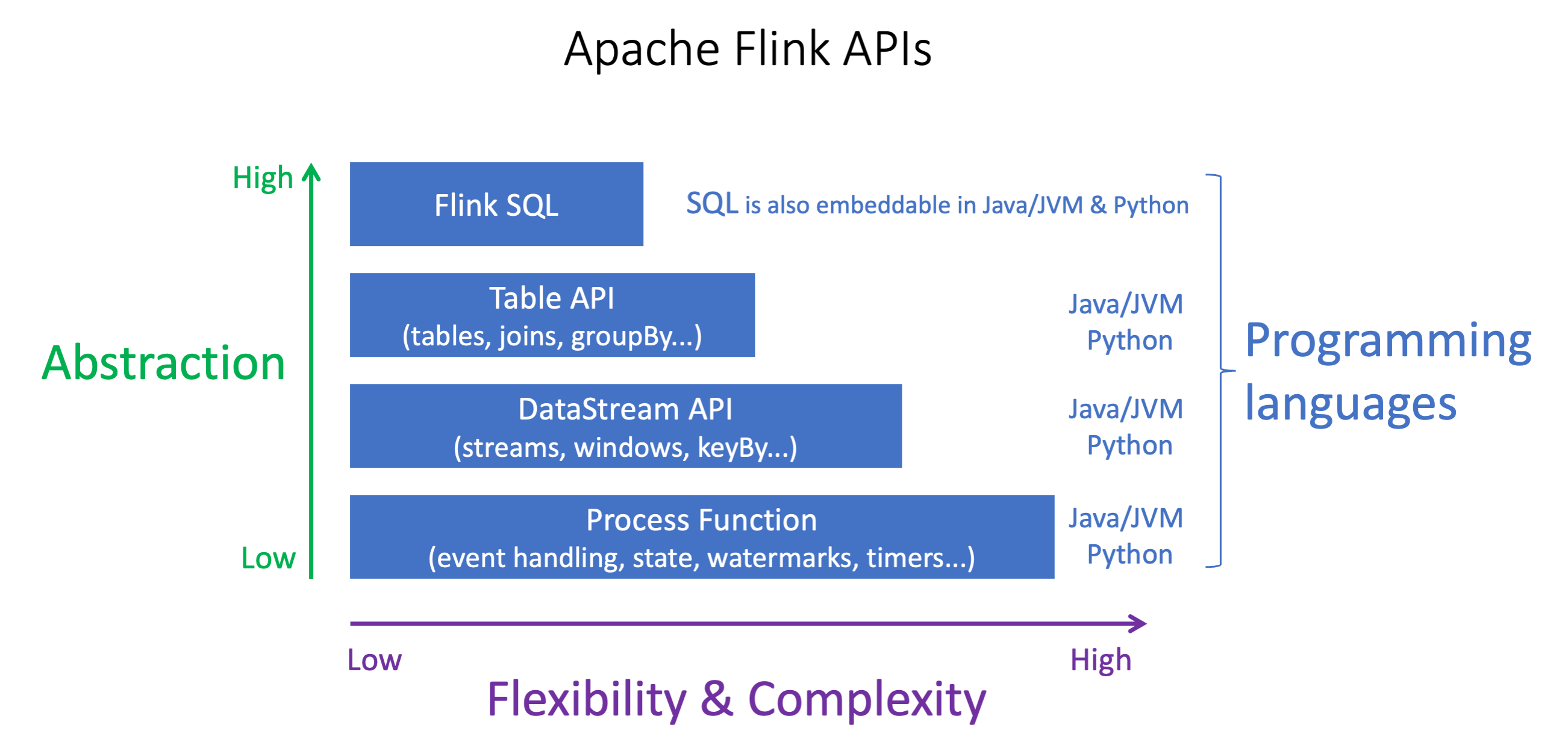
Apache Flink APIs memiliki tingkat abstraksi yang berbeda yang dapat mempengaruhi bagaimana Anda memutuskan untuk membangun aplikasi Anda. Mereka ekspresif dan fleksibel dan dapat digunakan bersama untuk membangun aplikasi Anda. Anda tidak harus menggunakan hanya satu Flink API. Anda dapat mempelajari lebih lanjut tentang Flink APIs di dokumentasi Apache Flink
Flink menawarkan empat tingkat abstraksi API: Flink SQL, Table API, DataStream API, dan Process Function, yang digunakan bersama dengan API. DataStream Ini semua didukung di Amazon Managed Service untuk Apache Flink. Dianjurkan untuk memulai dengan tingkat abstraksi yang lebih tinggi jika memungkinkan, namun beberapa fitur Flink hanya tersedia dengan Datastream API di mana Anda dapat membuat aplikasi Anda di Java, Python, atau Scala. Anda harus mempertimbangkan untuk menggunakan Datastream API jika:
Anda memerlukan kontrol berbutir halus atas negara
Anda ingin memanfaatkan kemampuan untuk memanggil database eksternal atau titik akhir secara asinkron (misalnya untuk inferensi)
Anda ingin menggunakan pengatur waktu khusus (misalnya untuk menerapkan jendela khusus atau penanganan acara terlambat)
-
Anda ingin dapat memodifikasi alur aplikasi Anda tanpa mengatur ulang status
catatan
Memilih bahasa dengan DataStream API:
SQL dapat disematkan dalam aplikasi Flink apa pun, terlepas dari bahasa pemrograman yang dipilih.
Jika Anda berencana untuk menggunakan DataStream API, tidak semua konektor didukung dengan Python.
Jika Anda membutuhkan rendah- latency/high-throughput you should consider Java/Scala terlepas dari API.
Jika Anda berencana untuk menggunakan Async IO di Process Functions API, Anda harus menggunakan Java.
Pilihan API juga dapat memengaruhi kemampuan Anda untuk mengembangkan logika aplikasi tanpa harus mengatur ulang status. Ini tergantung pada fitur tertentu, kemampuan untuk mengatur UID pada operator, yang hanya tersedia di DataStream API untuk Java dan Python. Untuk informasi selengkapnya, lihat Mengatur UUIDs Untuk Semua Operator
Memulai aplikasi data streaming
Anda dapat memulai dengan membuat Layanan Terkelola untuk aplikasi Apache Flink yang terus membaca dan memproses data streaming. Selanjutnya, tulis kode Anda menggunakan IDE pilihan Anda, dan uji dengan data streaming langsung. Anda juga dapat mengonfigurasi tujuan di mana Anda ingin Layanan Terkelola untuk Apache Flink untuk mengirim hasilnya.
Sebaiknya mulai dengan membaca bagian berikut:
Secara altenatif, Anda dapat memulai dengan membuat Managed Service for Apache Flink Studio notebook yang memungkinkan Anda untuk secara interaktif menanyakan aliran data secara real time, dan dengan mudah membangun dan menjalankan aplikasi pemrosesan aliran menggunakan SQL standar, Python, dan Scala. Dengan beberapa klik Konsol Manajemen AWS, Anda dapat meluncurkan notebook tanpa server untuk menanyakan aliran data dan mendapatkan hasil dalam hitungan detik. Sebaiknya mulai dengan membaca bagian berikut:
