Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Membuat gambar paket model
Paket model Amazon SageMaker AI adalah model pra-terlatih yang membuat prediksi dan tidak memerlukan pelatihan lebih lanjut oleh pembeli. Anda dapat membuat paket model di SageMaker AI dan mempublikasikan produk pembelajaran mesin Anda di AWS Marketplace. Bagian berikut Anda cara membuat paket model untuk AWS Marketplace. Ini termasuk membuat gambar kontainer dan membangun serta menguji gambar secara lokal.
Gambaran Umum
Paket model mencakup komponen-komponen berikut:
-
Gambar inferensi yang disimpan di Amazon Elastic Container Registry
(Amazon ECR) -
(Opsional) Artefak model, disimpan secara terpisah di Amazon
S3
catatan
Artefak model adalah file yang digunakan model Anda untuk membuat prediksi dan umumnya merupakan hasil dari proses pelatihan Anda sendiri. Artefak dapat berupa jenis file apa pun yang dibutuhkan oleh model Anda tetapi harus kompresi use.tar.gz. Untuk paket model, paket tersebut dapat dibundel dalam gambar inferensi Anda atau disimpan secara terpisah di Amazon SageMaker AI. Artefak model yang disimpan di Amazon S3 dimuat ke dalam wadah inferensi saat runtime. Saat mempublikasikan paket model Anda, artefak tersebut diterbitkan dan disimpan dalam bucket Amazon S3 AWS Marketplace milik yang tidak dapat diakses oleh pembeli secara langsung.
Tip
Jika model inferensi Anda dibangun dengan kerangka pembelajaran mendalam seperti Gluon, Keras,,,, TensorFlow -Lite MXNet PyTorch TensorFlow, atau ONNX, pertimbangkan untuk menggunakan Amazon AI Neo. SageMaker Neo dapat secara otomatis mengoptimalkan model inferensi yang diterapkan ke keluarga jenis instance cloud tertentu sepertiml.c4,ml.p2, dan lainnya. Untuk informasi selengkapnya, lihat Mengoptimalkan kinerja model menggunakan Neo di Panduan Pengembang Amazon SageMaker AI.
Diagram berikut menunjukkan alur kerja untuk menerbitkan dan menggunakan produk paket model.
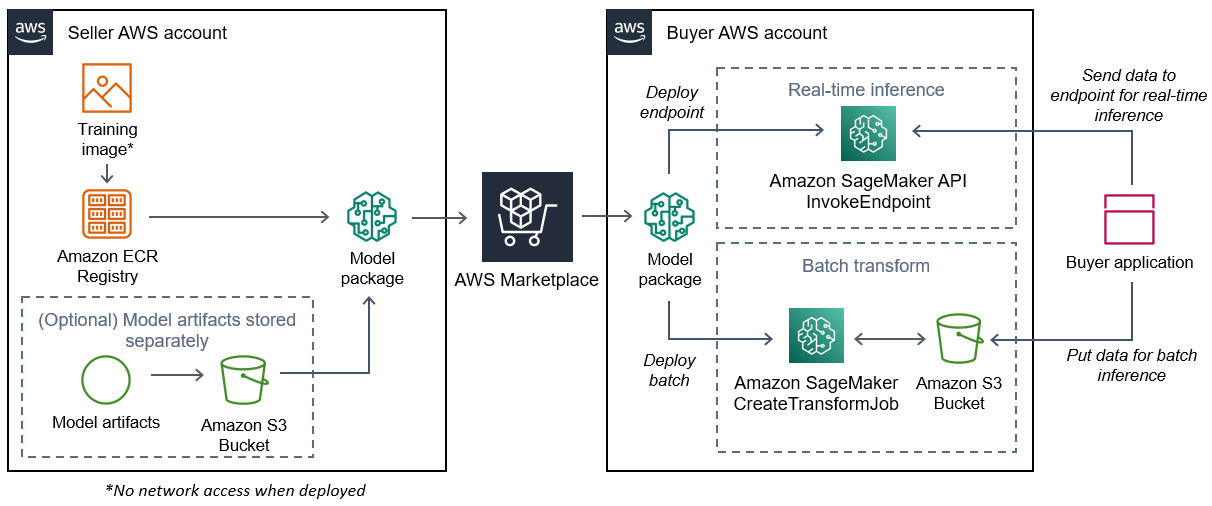
Alur kerja untuk membuat paket model SageMaker AI AWS Marketplace mencakup langkah-langkah berikut:
-
Penjual membuat gambar inferensi (tidak ada akses jaringan saat digunakan) dan mendorongnya ke Amazon ECR Registry.
Artefak model dapat dibundel dalam gambar inferensi atau disimpan secara terpisah di S3.
-
Penjual kemudian membuat sumber daya paket model di Amazon SageMaker AI dan menerbitkan produk ML-nya. AWS Marketplace
-
Pembeli berlangganan produk ML dan menyebarkan model.
catatan
Model ini dapat digunakan sebagai titik akhir untuk inferensi waktu nyata atau sebagai pekerjaan batch untuk mendapatkan prediksi untuk seluruh kumpulan data sekaligus. Untuk informasi selengkapnya, lihat Menerapkan Model untuk Inferensi.
-
SageMaker AI menjalankan gambar inferensi. Artefak model apa pun yang disediakan penjual yang tidak dibundel dalam gambar inferensi dimuat secara dinamis saat runtime.
-
SageMaker AI meneruskan data inferensi pembeli ke wadah dengan menggunakan titik akhir HTTP kontainer dan mengembalikan hasil prediksi.
Buat gambar inferensi untuk paket model
Bagian ini memberikan panduan untuk mengemas kode inferensi Anda ke dalam gambar inferensi untuk produk paket model Anda. Prosesnya terdiri dari langkah-langkah berikut:
Gambar inferensi adalah gambar Docker yang berisi logika inferensi Anda. Container saat runtime mengekspos titik akhir HTTP untuk memungkinkan SageMaker AI meneruskan data ke dan dari container Anda.
catatan
Berikut ini hanya satu contoh kode kemasan untuk gambar inferensi. Untuk informasi selengkapnya, lihat Menggunakan kontainer Docker dengan SageMaker AWS Marketplace
SageMaker AI dan contoh AI
Contoh berikut menggunakan layanan web, Flask
Langkah 1: Buat gambar wadah
Agar gambar inferensi kompatibel dengan SageMaker AI, image Docker harus mengekspos titik akhir HTTP. Saat container Anda berjalan, SageMaker AI meneruskan input pembeli untuk inferensi ke titik akhir HTTP container. Hasil inferensi dikembalikan di badan respons HTTP.
Panduan berikut menggunakan CLI Docker di lingkungan pengembangan menggunakan distribusi Linux Ubuntu.
Buat skrip server web
Contoh ini menggunakan server Python yang disebut Flask
catatan
Labu
Buat skrip server web Flask yang melayani dua titik akhir HTTP pada port TCP 8080 yang digunakan AI. SageMaker Berikut ini adalah dua titik akhir yang diharapkan:
-
/ping— SageMaker AI membuat permintaan HTTP GET ke titik akhir ini untuk memeriksa apakah wadah Anda sudah siap. Ketika penampung Anda siap, ia merespons permintaan HTTP GET di titik akhir ini dengan kode respons HTTP 200. -
/invocations— SageMaker AI membuat permintaan HTTP POST ke titik akhir ini untuk inferensi. Data input untuk inferensi dikirim dalam badan permintaan. Jenis konten yang ditentukan pengguna diteruskan di header HTTP. Tubuh respons adalah output inferensi. Untuk detail tentang batas waktu, lihatPersyaratan dan praktik terbaik untuk membuat produk pembelajaran mesin.
./web_app_serve.py
# Import modules import json import re from flask import Flask from flask import request app = Flask(__name__) # Create a path for health checks @app.route("/ping") def endpoint_ping(): return "" # Create a path for inference @app.route("/invocations", methods=["POST"]) def endpoint_invocations(): # Read the input input_str = request.get_data().decode("utf8") # Add your inference code between these comments. # # # # # # Add your inference code above this comment. # Return a response with a prediction response = {"prediction":"a","text":input_str} return json.dumps(response)
Pada contoh sebelumnya, tidak ada logika inferensi yang sebenarnya. Untuk gambar inferensi Anda yang sebenarnya, tambahkan logika inferensi ke dalam aplikasi web sehingga memproses input dan mengembalikan prediksi yang sebenarnya.
Gambar inferensi Anda harus berisi semua dependensi yang diperlukan karena tidak akan memiliki akses internet, juga tidak akan dapat melakukan panggilan ke salah satu. Layanan AWS
catatan
Kode yang sama ini dipanggil untuk inferensi real-time dan batch
Buat skrip untuk container run
Buat skrip bernama serve SageMaker AI berjalan saat menjalankan image container Docker. Script berikut memulai server web HTTP.
./serve
#!/bin/bash # Run flask server on port 8080 for SageMaker flask run --host 0.0.0.0 --port 8080
Buat Dockerfile
Buat Dockerfile dalam konteks build Anda. Contoh ini menggunakan Ubuntu 18.04, tetapi Anda dapat memulai dari gambar dasar apa pun yang berfungsi untuk kerangka kerja Anda.
./Dockerfile
FROM ubuntu:18.04 # Specify encoding ENV LC_ALL=C.UTF-8 ENV LANG=C.UTF-8 # Install python-pip RUN apt-get update \ && apt-get install -y python3.6 python3-pip \ && ln -s /usr/bin/python3.6 /usr/bin/python \ && ln -s /usr/bin/pip3 /usr/bin/pip; # Install flask server RUN pip install -U Flask; # Add a web server script to the image # Set an environment to tell flask the script to run COPY /web_app_serve.py /web_app_serve.py ENV FLASK_APP=/web_app_serve.py # Add a script that Amazon SageMaker AI will run # Set run permissions # Prepend program directory to $PATH COPY /serve /opt/program/serve RUN chmod 755 /opt/program/serve ENV PATH=/opt/program:${PATH}
DockerfileMenambahkan dua skrip yang dibuat sebelumnya ke gambar. Direktori serve skrip ditambahkan ke PATH sehingga dapat berjalan ketika wadah berjalan.
Package atau upload artefak model
Dua cara untuk menyediakan artefak model mulai dari melatih model hingga gambar inferensi adalah sebagai berikut:
-
Dikemas secara statis dengan gambar inferensi.
-
Dimuat secara dinamis saat runtime. Karena dimuat secara dinamis, Anda dapat menggunakan gambar yang sama untuk mengemas model pembelajaran mesin yang berbeda.
Jika Anda ingin mengemas artefak model Anda dengan gambar inferensi, sertakan artefak di. Dockerfile
Jika Anda ingin memuat artefak model secara dinamis, simpan artefak tersebut secara terpisah dalam file terkompresi (.tar.gz) di Amazon S3. Saat membuat paket model, tentukan lokasi file terkompresi, dan SageMaker AI mengekstrak dan menyalin konten ke direktori container /opt/ml/model/ saat menjalankan container Anda. Saat mempublikasikan paket model Anda, artefak tersebut diterbitkan dan disimpan dalam bucket Amazon S3 AWS Marketplace
milik yang tidak dapat diakses oleh pembeli secara langsung.
Langkah 2: Membangun dan menguji gambar secara lokal
Dalam konteks build, file berikut sekarang ada:
-
./Dockerfile -
./web_app_serve.py -
./serve -
Logika inferensi dan dependensi (opsional) Anda
Selanjutnya membangun, menjalankan, dan menguji image container.
Bangun citra
Jalankan perintah Docker dalam konteks build untuk membangun dan menandai gambar. Contoh ini menggunakan tagmy-inference-image.
sudo docker build --tag my-inference-image ./
Setelah menjalankan perintah Docker ini untuk membangun gambar, Anda akan melihat output saat Docker membangun gambar berdasarkan setiap baris di baris Anda. Dockerfile Setelah selesai, Anda akan melihat sesuatu yang mirip dengan yang berikut ini.
Successfully built abcdef123456
Successfully tagged my-inference-image:latestJalankan secara lokal
Setelah build selesai, Anda dapat menguji gambar secara lokal.
sudo docker run \ --rm \ --publish 8080:8080/tcp \ --detach \ --name my-inference-container \ my-inference-image \ serve
Berikut ini adalah detail tentang perintah:
-
--rm- Secara otomatis menghapus wadah setelah berhenti. -
--publish 8080:8080/tcp— Paparkan port 8080 untuk mensimulasikan port tempat SageMaker AI mengirimkan permintaan HTTP. -
--detach— Jalankan wadah di latar belakang. -
--name my-inference-container— Beri nama wadah yang sedang berjalan ini. -
my-inference-image— Jalankan gambar yang dibangun. -
serve— Jalankan skrip yang sama dengan yang dijalankan SageMaker AI saat menjalankan container.
Setelah menjalankan perintah ini, Docker membuat wadah dari gambar inferensi yang Anda buat dan menjalankannya di latar belakang. Wadah menjalankan serve skrip, yang meluncurkan server web Anda untuk tujuan pengujian.
Uji titik akhir HTTP ping
Saat SageMaker AI menjalankan wadah Anda, ia secara berkala melakukan ping ke titik akhir. Ketika titik akhir mengembalikan respons HTTP dengan kode status 200, itu memberi sinyal ke SageMaker AI bahwa wadah siap untuk inferensi. Anda dapat menguji ini dengan menjalankan perintah berikut, yang menguji titik akhir dan menyertakan header respons.
curl --include http://127.0.0.1:8080/ping
Contoh output adalah sebagai berikut.
HTTP/1.0 200 OK
Content-Type: text/html; charset=utf-8
Content-Length: 0
Server: MyServer/0.16.0 Python/3.6.8
Date: Mon, 21 Oct 2019 06:58:54 GMTUji titik akhir HTTP inferensi
Ketika penampung menunjukkan siap dengan mengembalikan kode status 200 ke ping Anda, SageMaker AI meneruskan data inferensi ke titik akhir /invocations HTTP melalui permintaan. POST Uji titik inferensi dengan menjalankan perintah berikut.
curl \ --request POST \ --data "hello world" \ http://127.0.0.1:8080/invocations
Contoh output adalah sebagai berikut.
{"prediction": "a", "text": "hello
world"}
Dengan dua titik akhir HTTP ini berfungsi, gambar inferensi sekarang kompatibel dengan SageMaker AI.
catatan
Model produk paket model Anda dapat digunakan dalam dua cara: real time dan batch. Di kedua penerapan, SageMaker AI menggunakan titik akhir HTTP yang sama saat menjalankan wadah Docker.
Untuk menghentikan wadah, jalankan perintah berikut.
sudo docker container stop my-inference-container
Ketika gambar inferensi Anda siap dan diuji, Anda dapat melanjutkanMengunggah gambar Anda ke Amazon Elastic Container Registry.
