Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Mengoptimalkan kinerja baca
Bagian ini membahas properti tabel yang dapat Anda atur untuk mengoptimalkan kinerja baca, terlepas dari mesin.
Partisi
Seperti halnya tabel Hive, Iceberg menggunakan partisi sebagai lapisan utama pengindeksan untuk menghindari membaca file metadata dan file data yang tidak perlu. Statistik kolom juga dipertimbangkan sebagai lapisan sekunder pengindeksan untuk lebih meningkatkan perencanaan kueri, yang mengarah ke waktu eksekusi keseluruhan yang lebih baik.
Partisi data Anda
Untuk mengurangi jumlah data yang dipindai saat menanyakan tabel Iceberg, pilih strategi partisi seimbang yang selaras dengan pola baca yang Anda harapkan:
-
Identifikasi kolom yang sering digunakan dalam kueri. Ini adalah kandidat partisi yang ideal. Misalnya, jika Anda biasanya meminta data dari hari tertentu, contoh alami dari kolom partisi akan menjadi kolom tanggal.
-
Pilih kolom partisi kardinalitas rendah untuk menghindari pembuatan partisi dalam jumlah berlebihan. Terlalu banyak partisi dapat meningkatkan jumlah file dalam tabel, yang dapat berdampak negatif pada kinerja kueri. Sebagai aturan praktis, “terlalu banyak partisi” dapat didefinisikan sebagai skenario di mana ukuran data di sebagian besar partisi kurang dari 2-5 kali nilai yang ditetapkan oleh.
target-file-size-bytes
catatan
Jika Anda biasanya melakukan kueri dengan menggunakan filter pada kolom kardinalitas tinggi (misalnya, id kolom yang dapat memiliki ribuan nilai), gunakan fitur partisi tersembunyi Iceberg dengan transformasi bucket, seperti yang dijelaskan di bagian berikutnya.
Gunakan partisi tersembunyi
Jika kueri Anda biasanya memfilter turunan kolom tabel, gunakan partisi tersembunyi alih-alih secara eksplisit membuat kolom baru untuk berfungsi sebagai partisi. Untuk informasi selengkapnya tentang fitur ini, lihat dokumentasi Iceberg
Misalnya, dalam kumpulan data yang memiliki kolom stempel waktu (misalnya,2023-01-01 09:00:00), alih-alih membuat kolom baru dengan tanggal yang diuraikan (misalnya,2023-01-01), gunakan transformasi partisi untuk mengekstrak bagian tanggal dari stempel waktu dan membuat partisi ini dengan cepat.
Kasus penggunaan yang paling umum untuk partisi tersembunyi adalah:
-
Partisi pada tanggal atau waktu, ketika data memiliki kolom stempel waktu. Iceberg menawarkan beberapa transformasi untuk mengekstrak bagian tanggal atau waktu dari stempel waktu.
-
Partisi pada fungsi hash kolom, ketika kolom partisi memiliki kardinalitas tinggi dan akan menghasilkan terlalu banyak partisi. Bucket transform Iceberg mengelompokkan beberapa nilai partisi menjadi lebih sedikit, partisi tersembunyi (bucket) dengan menggunakan fungsi hash pada kolom partisi.
Lihat transformasi partisi
Kolom yang digunakan untuk partisi tersembunyi dapat menjadi bagian dari predikat kueri melalui penggunaan fungsi SQL biasa seperti dan. year() month() Predikat juga dapat dikombinasikan dengan operator seperti BETWEEN danAND.
catatan
Iceberg tidak dapat melakukan pemangkasan partisi untuk fungsi yang menghasilkan tipe data yang berbeda; misalnya,. substring(event_time, 1, 10) =
'2022-01-01'
Gunakan evolusi partisi
Gunakan evolusi partisi Iceberg
Anda dapat menggunakan pendekatan ini ketika strategi partisi terbaik untuk tabel awalnya tidak jelas, dan Anda ingin memperbaiki strategi partisi Anda saat Anda mendapatkan lebih banyak wawasan. Penggunaan lain yang efektif dari evolusi partisi adalah ketika volume data berubah dan strategi partisi saat ini menjadi kurang efektif dari waktu ke waktu.
Untuk petunjuk tentang cara mengembangkan partisi, lihat ALTER TABLE ekstensi SQL
Ukuran file tuning
Mengoptimalkan kinerja kueri melibatkan meminimalkan jumlah file kecil di tabel Anda. Untuk kinerja kueri yang baik, kami biasanya merekomendasikan untuk menyimpan file Parket dan ORC lebih besar dari 100 MB.
Ukuran file juga memengaruhi perencanaan kueri untuk tabel Iceberg. Karena jumlah file dalam tabel meningkat, begitu juga ukuran file metadata. File metadata yang lebih besar dapat menghasilkan perencanaan kueri yang lebih lambat. Oleh karena itu, ketika ukuran tabel bertambah, tingkatkan ukuran file untuk mengurangi ekspansi eksponensial metadata.
Gunakan praktik terbaik berikut untuk membuat file berukuran benar di tabel Iceberg.
Tetapkan file target dan ukuran grup baris
Iceberg menawarkan parameter konfigurasi kunci berikut untuk menyetel tata letak file data. Kami menyarankan Anda menggunakan parameter ini untuk mengatur ukuran file target dan grup baris atau ukuran serangan.
Parameter |
Nilai default |
Komentar |
|---|---|---|
|
512 MB |
Parameter ini menentukan ukuran file maksimum yang akan dibuat Iceberg. Namun, file tertentu mungkin ditulis dengan ukuran yang lebih kecil dari batas ini. |
|
128 MB |
Baik Parket dan ORC menyimpan data dalam potongan sehingga mesin dapat menghindari membaca seluruh file untuk beberapa operasi. |
|
64 MB |
|
|
Tidak ada, untuk Iceberg versi 1.1 dan lebih rendah Hash, dimulai dengan Iceberg versi 1.2 |
Iceberg meminta Spark untuk mengurutkan data di antara tugasnya sebelum menulis ke penyimpanan. |
-
Berdasarkan ukuran tabel yang Anda harapkan, ikuti panduan umum ini:
-
Tabel kecil (hingga beberapa gigabyte) — Kurangi ukuran file target menjadi 128 MB. Juga kurangi grup baris atau ukuran garis (misalnya, menjadi 8 atau 16 MB).
-
Tabel sedang hingga besar (dari beberapa gigabyte hingga ratusan gigabyte) — Nilai default adalah titik awal yang baik untuk tabel ini. Jika kueri Anda sangat selektif, sesuaikan grup baris atau ukuran garis (misalnya, menjadi 16 MB).
-
Tabel yang sangat besar (ratusan gigabyte atau terabyte) — Tingkatkan ukuran file target menjadi 1024 MB atau lebih, dan pertimbangkan untuk meningkatkan grup baris atau ukuran garis jika kueri Anda biasanya menarik kumpulan data yang besar.
-
-
Untuk memastikan bahwa aplikasi Spark yang menulis ke tabel Iceberg membuat file berukuran tepat, atur
write.distribution-modeproperti ke salah satu atau.hashrangeUntuk penjelasan rinci tentang perbedaan antara mode ini, lihat Menulis Mode Distribusidalam dokumentasi Gunung Es.
Ini adalah pedoman umum. Kami menyarankan Anda menjalankan pengujian untuk mengidentifikasi nilai yang paling sesuai untuk tabel dan beban kerja spesifik Anda.
Jalankan pemadatan reguler
Konfigurasi dalam tabel sebelumnya menetapkan ukuran file maksimum yang dapat dibuat oleh tugas tulis, tetapi tidak menjamin bahwa file akan memiliki ukuran itu. Untuk memastikan ukuran file yang tepat, jalankan pemadatan secara teratur untuk menggabungkan file kecil menjadi file yang lebih besar. Untuk panduan terperinci tentang menjalankan pemadatan, lihat Pemadatan gunung es nanti di panduan ini.
Optimalkan statistik kolom
Iceberg menggunakan statistik kolom untuk melakukan pemangkasan file, yang meningkatkan kinerja kueri dengan mengurangi jumlah data yang dipindai oleh kueri. Untuk mendapatkan keuntungan dari statistik kolom, pastikan bahwa Iceberg mengumpulkan statistik untuk semua kolom yang sering digunakan dalam filter kueri.
Secara default, Iceberg mengumpulkan statistik hanya untuk 100 kolom pertama di setiap tabelwrite.metadata.metrics.max-inferred-column-defaults Jika tabel Anda memiliki lebih dari 100 kolom dan kueri Anda sering merujuk kolom di luar 100 kolom pertama (misalnya, Anda mungkin memiliki kueri yang memfilter pada kolom 132), pastikan bahwa Iceberg mengumpulkan statistik pada kolom tersebut. Ada dua opsi untuk mencapai ini:
-
Saat Anda membuat tabel Iceberg, susun ulang kolom sehingga kolom yang Anda butuhkan untuk kueri termasuk dalam rentang kolom yang ditetapkan oleh
write.metadata.metrics.max-inferred-column-defaults(default adalah 100).Catatan: Jika Anda tidak memerlukan statistik pada 100 kolom, Anda dapat menyesuaikan
write.metadata.metrics.max-inferred-column-defaultskonfigurasi ke nilai yang diinginkan (misalnya, 20) dan menyusun ulang kolom sehingga kolom yang perlu Anda baca dan tulis kueri termasuk dalam 20 kolom pertama di sisi kiri kumpulan data. -
Jika Anda hanya menggunakan beberapa kolom dalam filter kueri, Anda dapat menonaktifkan keseluruhan properti untuk koleksi metrik dan secara selektif memilih kolom individual untuk mengumpulkan statistik, seperti yang ditunjukkan dalam contoh ini:
.tableProperty("write.metadata.metrics.default", "none") .tableProperty("write.metadata.metrics.column.my_col_a", "full") .tableProperty("write.metadata.metrics.column.my_col_b", "full")
Catatan: Statistik kolom paling efektif ketika data diurutkan pada kolom tersebut. Untuk informasi selengkapnya, lihat bagian Mengatur urutan pengurutan nanti dalam panduan ini.
Pilih strategi pembaruan yang tepat
Gunakan copy-on-write strategi untuk mengoptimalkan kinerja baca, ketika operasi penulisan yang lebih lambat dapat diterima untuk kasus penggunaan Anda. Ini adalah strategi default yang digunakan oleh Iceberg.
C opy-on-write menghasilkan kinerja baca yang lebih baik, karena file langsung ditulis ke penyimpanan dengan cara yang dioptimalkan untuk dibaca. Namun, dibandingkan dengan merge-on-read, setiap operasi penulisan membutuhkan waktu lebih lama dan mengkonsumsi lebih banyak sumber daya komputasi. Ini menyajikan trade-off klasik antara latensi baca dan tulis. Biasanya, copy-on-write sangat ideal untuk kasus penggunaan di mana sebagian besar pembaruan ditempatkan di partisi tabel yang sama (misalnya, untuk pemuatan batch harian).
opy-on-write Konfigurasi C (write.update.mode,write.delete.mode, danwrite.merge.mode) dapat diatur pada tingkat tabel atau secara independen di sisi aplikasi.
Gunakan kompresi ZSTD
Anda dapat memodifikasi codec kompresi yang digunakan oleh Iceberg dengan menggunakan properti tabel. write.<file_type>.compression-codec Kami menyarankan Anda menggunakan codec kompresi ZSTD untuk meningkatkan kinerja keseluruhan pada tabel.
Secara default, Iceberg versi 1.3 dan sebelumnya menggunakan kompresi GZIP, yang memberikan kinerja baca/tulis lebih lambat dibandingkan dengan ZSTD.
Catatan: Beberapa mesin mungkin menggunakan nilai default yang berbeda. Ini adalah kasus untuk tabel Iceberg yang dibuat dengan Athena atau Amazon EMR versi 7.x.
Mengatur urutan sortir
Untuk meningkatkan kinerja baca pada tabel Iceberg, sebaiknya Anda mengurutkan tabel berdasarkan satu atau beberapa kolom yang sering digunakan dalam filter kueri. Penyortiran, dikombinasikan dengan statistik kolom Iceberg, dapat membuat pemangkasan file secara signifikan lebih efisien, yang menghasilkan operasi pembacaan yang lebih cepat. Penyortiran juga mengurangi jumlah permintaan Amazon S3 untuk kueri yang menggunakan kolom pengurutan dalam filter kueri.
Anda dapat mengatur urutan hierarkis di tingkat tabel dengan menjalankan pernyataan data definition language (DDL) dengan Spark. Untuk opsi yang tersedia, lihat dokumentasi Iceberg
Misalnya, dalam tabel yang dipartisi berdasarkan date (yyyy-mm-dd) di mana sebagian besar kueri difilteruuid, Anda dapat menggunakan opsi DDL Write Distributed By Partition Locally Ordered untuk memastikan bahwa Spark menulis file dengan rentang yang tidak tumpang tindih.
Diagram berikut menggambarkan bagaimana efisiensi statistik kolom meningkat ketika tabel diurutkan. Dalam contoh, tabel yang diurutkan hanya perlu membuka satu file, dan manfaat maksimal dari partisi dan file Iceberg. Dalam tabel yang tidak disortir, apa pun uuid berpotensi ada di file data apa pun, sehingga kueri harus membuka semua file data.
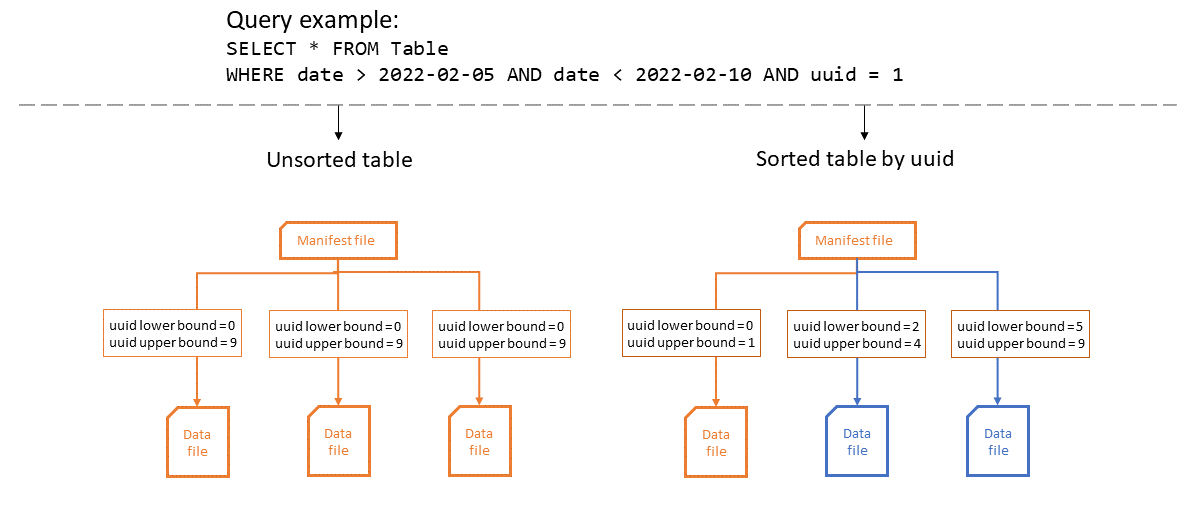
Mengubah urutan pengurutan tidak memengaruhi file data yang ada. Anda dapat menggunakan pemadatan Iceberg untuk menerapkan urutan pengurutan pada itu.
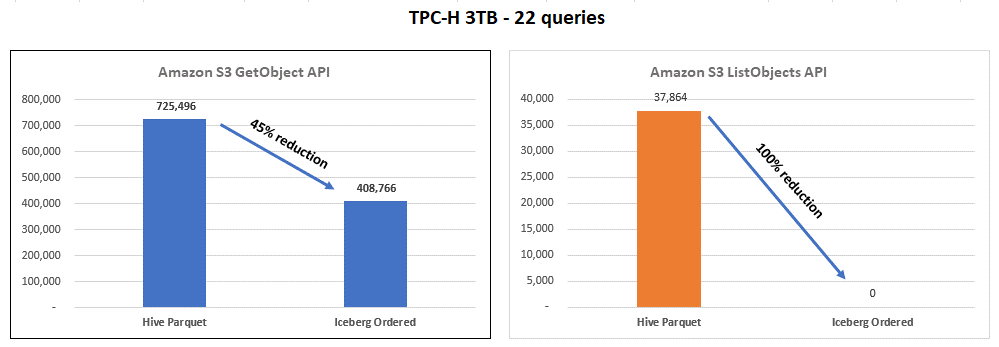
Menggunakan tabel yang diurutkan Iceberg dapat mengurangi biaya untuk beban kerja Anda, seperti yang diilustrasikan dalam grafik berikut.
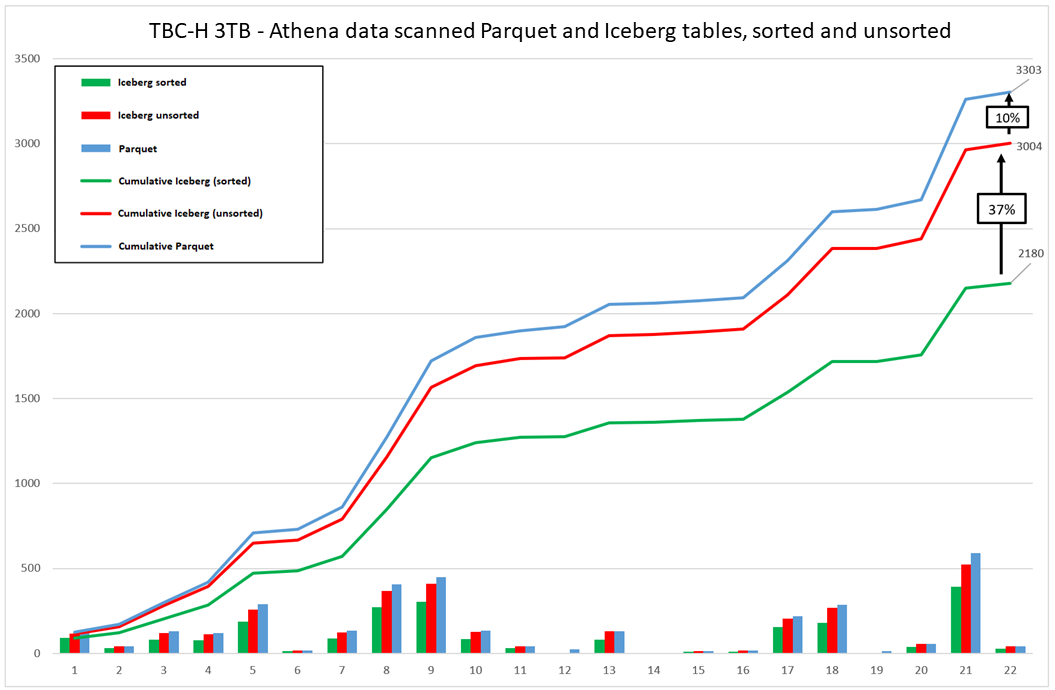
Grafik ini merangkum hasil menjalankan benchmark TPC-H untuk tabel Hive (Parquet) dibandingkan dengan tabel yang diurutkan Iceberg. Namun, hasilnya mungkin berbeda untuk kumpulan data atau beban kerja lainnya.