Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Memulai dengan tabel Apache Iceberg di Amazon Athena SQL
Amazon Athena menyediakan dukungan bawaan untuk Apache Iceberg. Anda dapat menggunakan Iceberg tanpa langkah atau konfigurasi tambahan kecuali untuk menyiapkan prasyarat layanan yang dirinci di bagian Memulai dokumentasi Athena. Bagian ini memberikan pengantar singkat untuk membuat tabel di Athena. Untuk informasi lebih lanjut, lihat Bekerja dengan tabel Apache Iceberg dengan menggunakan Athena SQL nanti dalam panduan ini.
Anda dapat membuat tabel Iceberg AWS dengan menggunakan mesin yang berbeda. Tabel itu bekerja dengan mulus. Layanan AWS Untuk membuat tabel Iceberg pertama Anda dengan Athena SQL, Anda dapat menggunakan kode boilerplate berikut.
CREATE TABLE <table_name> ( col_1 string, col_2 string, col_3 bigint, col_ts timestamp) PARTITIONED BY (col_1, <<<partition_transform>>>(col_ts)) LOCATION 's3://<bucket>/<folder>/<table_name>/' TBLPROPERTIES ( 'table_type' ='ICEBERG' )
Bagian berikut memberikan contoh pembuatan tabel Gunung Es yang dipartisi dan tidak dipartisi di Athena. Untuk informasi lebih lanjut, lihat sintaks Iceberg yang dirinci dalam dokumentasi Athena.
Membuat tabel yang tidak dipartisi
Contoh pernyataan berikut menyesuaikan kode SQL boilerplate untuk membuat tabel Iceberg yang tidak dipartisi di Athena. Anda dapat menambahkan pernyataan ini ke editor kueri di Athenaconsole untuk membuat tabel
CREATE TABLE athena_iceberg_table ( color string, date string, name string, price bigint, product string, ts timestamp) LOCATION 's3://DOC_EXAMPLE_BUCKET/ice_warehouse/iceberg_db/athena_iceberg_table/' TBLPROPERTIES ( 'table_type' ='ICEBERG' )
Untuk step-by-step petunjuk penggunaan editor kueri, lihat Memulai dokumentasi Athena.
Membuat tabel yang dipartisi
Pernyataan berikut membuat tabel dipartisi berdasarkan tanggal dengan menggunakan konsep Iceberg tentang partisi tersembunyi.day() transformasi untuk mendapatkan partisi harian, menggunakan dd-mm-yyyy format, dari kolom stempel waktu. Iceberg tidak menyimpan nilai ini sebagai kolom baru dalam kumpulan data. Sebagai gantinya, nilainya diturunkan dengan cepat saat Anda menulis atau menanyakan data.
CREATE TABLE athena_iceberg_table_partitioned ( color string, date string, name string, price bigint, product string, ts timestamp) PARTITIONED BY (day(ts)) LOCATION 's3://DOC_EXAMPLE_BUCKET/ice_warehouse/iceberg_db/athena_iceberg_table/' TBLPROPERTIES ( 'table_type' ='ICEBERG' )
Membuat tabel dan memuat data dengan pernyataan CTAS tunggal
Dalam contoh yang dipartisi dan tidak dipartisi di bagian sebelumnya, tabel Iceberg dibuat sebagai tabel kosong. Anda dapat memuat data ke tabel dengan menggunakan MERGE pernyataan INSERT atau. Atau, Anda dapat menggunakan CREATE TABLE AS SELECT (CTAS) pernyataan untuk membuat dan memuat data ke dalam tabel Iceberg dalam satu langkah.
CTAS adalah cara terbaik di Athena untuk membuat tabel dan memuat data dalam satu pernyataan. Contoh berikut menggambarkan bagaimana menggunakan CTAS untuk membuat tabel Iceberg (iceberg_ctas_table) dari tabel Hive/Parquet () yang ada di Athena. hive_table
CREATE TABLE iceberg_ctas_table WITH ( table_type = 'ICEBERG', is_external = false, location = 's3://DOC_EXAMPLE_BUCKET/ice_warehouse/iceberg_db/iceberg_ctas_table/' ) AS SELECT * FROM "iceberg_db"."hive_table" limit 20 --- SELECT * FROM "iceberg_db"."iceberg_ctas_table" limit 20
Untuk mempelajari lebih lanjut tentang CTAS, lihat dokumentasi Athena CTAS.
Memasukkan, memperbarui, dan menghapus data
Athena mendukung berbagai cara penulisan data ke tabel Iceberg dengan menggunakan pernyataanINSERT INTO,, UPDATEMERGE INTO, dan M. DELETE FRO
Catatan:UPDATE,MERGE INTO, dan DELETE FROM gunakan merge-on-read pendekatan dengan penghapusan posisi. copy-on-write Pendekatan saat ini tidak didukung di Athena SQL.
Misalnya, pernyataan berikut digunakan INSERT INTO untuk menambahkan data ke tabel Iceberg:
INSERT INTO "iceberg_db"."ice_table" VALUES ( 'red', '222022-07-19T03:47:29', 'PersonNew', 178, 'Tuna', now() ) SELECT * FROM "iceberg_db"."ice_table" where color = 'red' limit 10;
Contoh output:

Untuk informasi lebih lanjut, lihat dokumentasi Athena.
Menanyakan tabel Iceberg
Anda dapat menjalankan query SQL reguler terhadap tabel Iceberg Anda dengan menggunakan Athena SQL, seperti yang diilustrasikan dalam contoh sebelumnya.
Selain pertanyaan biasa, Athena juga mendukung kueri perjalanan waktu untuk tabel Iceberg. Seperti yang telah dibahas sebelumnya, Anda dapat mengubah catatan yang ada melalui pembaruan atau penghapusan di tabel Iceberg, sehingga lebih mudah menggunakan kueri perjalanan waktu untuk melihat kembali ke versi tabel yang lebih lama berdasarkan stempel waktu atau ID snapshot.
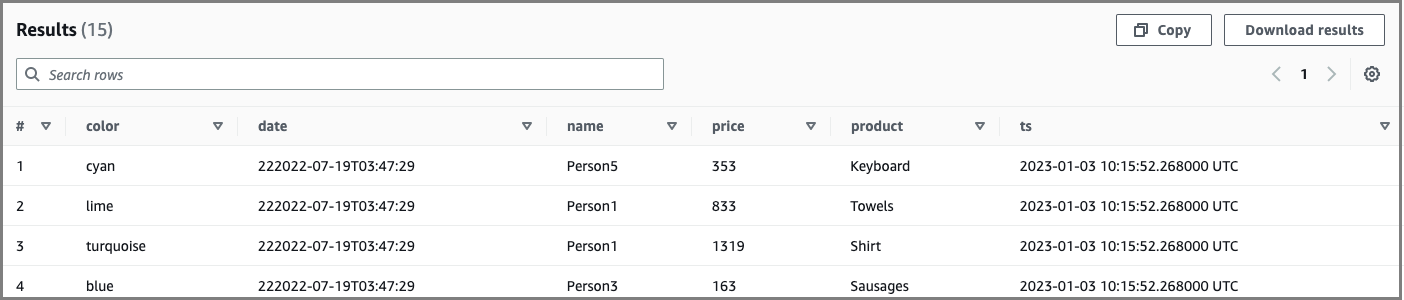
Misalnya, pernyataan berikut memperbarui nilai warna untukPerson5, dan kemudian menampilkan nilai sebelumnya dari 4 Januari 2023:
UPDATE ice_table SET color='new_color' WHERE name='Person5' SELECT * FROM "iceberg_db"."ice_table" FOR TIMESTAMP AS OF TIMESTAMP '2023-01-04 12:00:00 UTC'
Contoh output:
Untuk sintaks dan contoh tambahan kueri perjalanan waktu, lihat dokumentasi Athena.
Anatomi tabel gunung es
Sekarang setelah kita membahas langkah-langkah dasar bekerja dengan tabel Iceberg, mari selami lebih dalam detail dan desain meja Iceberg yang rumit.
Untuk mengaktifkan fitur yang dijelaskan sebelumnya dalam panduan ini, Iceberg dirancang dengan lapisan hierarkis data dan file metadata. Lapisan ini mengelola metadata secara cerdas untuk mengoptimalkan perencanaan dan eksekusi kueri.
Diagram berikut menggambarkan organisasi tabel Gunung Es melalui dua perspektif: yang Layanan AWS digunakan untuk menyimpan tabel dan penempatan file di Amazon S3.
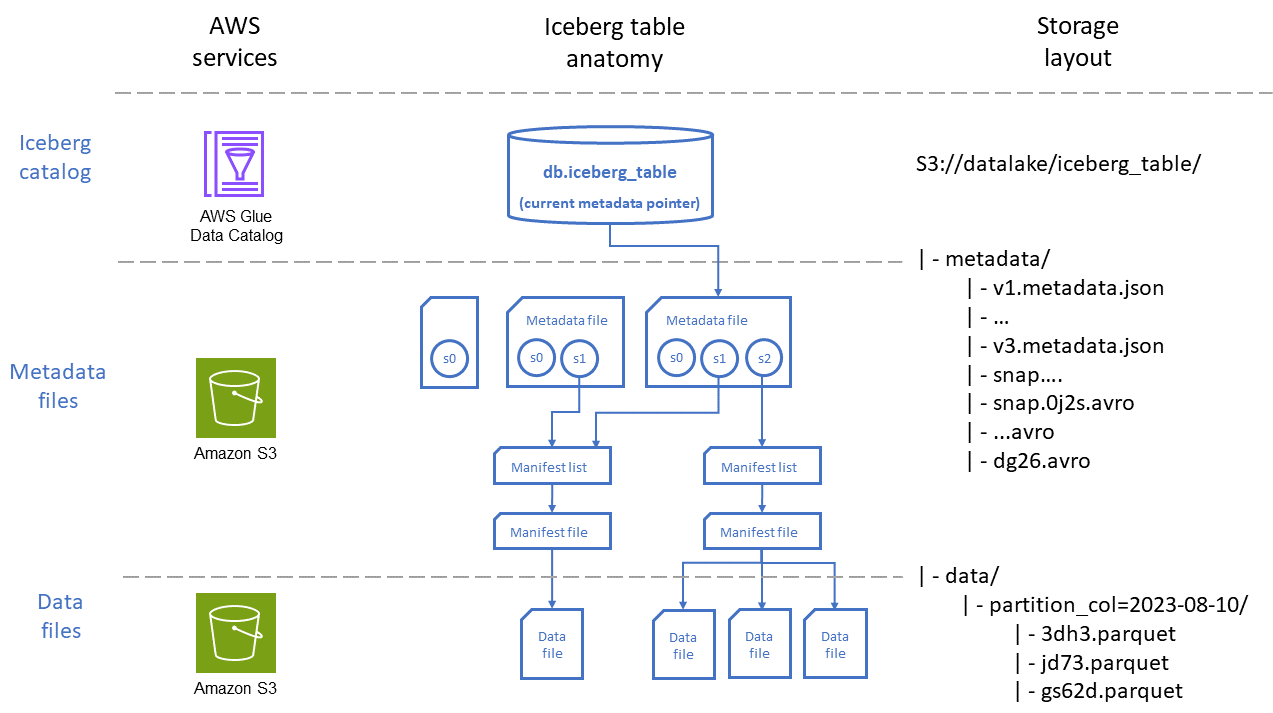
Seperti yang ditunjukkan pada diagram, tabel Gunung Es terdiri dari tiga lapisan utama:
-
Katalog Iceberg: AWS Glue Data Catalog terintegrasi secara native dengan Iceberg dan, untuk sebagian besar kasus penggunaan, merupakan opsi terbaik untuk beban kerja yang berjalan. AWS Layanan yang berinteraksi dengan tabel Iceberg (misalnya, Athena) menggunakan katalog untuk menemukan versi snapshot tabel saat ini, baik untuk membaca atau menulis data.
-
Lapisan metadata: File metadata, yaitu file manifes dan file daftar manifes, melacak informasi seperti skema tabel, strategi partisi, dan lokasi file data, serta statistik tingkat kolom seperti rentang minimum dan maksimum untuk catatan yang disimpan di setiap file data. File metadata ini disimpan di Amazon S3 dalam jalur tabel.
-
File manifes berisi catatan untuk setiap file data, termasuk lokasi, format, ukuran, checksum, dan informasi relevan lainnya.
-
Daftar manifes menyediakan indeks file manifes. Seiring bertambahnya jumlah file manifes dalam tabel, memecah informasi tersebut menjadi subbagian yang lebih kecil membantu mengurangi jumlah file manifes yang perlu dipindai oleh kueri.
-
File metadata berisi informasi tentang seluruh tabel Iceberg, termasuk daftar manifes, skema, metadata partisi, file snapshot, dan file lain yang digunakan untuk mengelola metadata tabel.
-
-
Lapisan data: Lapisan ini berisi file yang memiliki catatan data yang akan dijalankan oleh kueri. File-file ini dapat disimpan dalam berbagai format, termasuk Apache Parquet, Apache
Avro, dan Apache ORC. -
File data berisi catatan data untuk tabel.
-
Hapus file yang menyandikan penghapusan tingkat baris dan perbarui operasi dalam tabel Iceberg. Iceberg memiliki dua jenis file hapus, seperti yang dijelaskan dalam dokumentasi Iceberg
. File-file ini dibuat oleh operasi dengan menggunakan merge-on-read mode.
-
