Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Fase pemrosesan
Amazon Textract mengekstrak konten file PDF sebagai string yang tidak dapat langsung digunakan oleh aplikasi hilir (misalnya, untuk menghasilkan statistik dengan menggabungkan angka). Nilai data yang diidentifikasi dan diubah dengan benar diperlukan karena dapat lebih mudah digunakan oleh aplikasi hilir Anda (misalnya, untuk memplot tren biaya sebagai deret waktu). Untuk menerapkan pemrosesan file PDF, satu file PDF dari setiap jenis file PDF baru harus diproses satu kali melalui Amazon Textract, yang kemudian menghasilkan file berformat JSON. Template
Setelah AWS Lambda fungsi dimulai padaFase konsumsi, ia menjalankan langkah-langkah yang ditunjukkan pada diagram berikut.
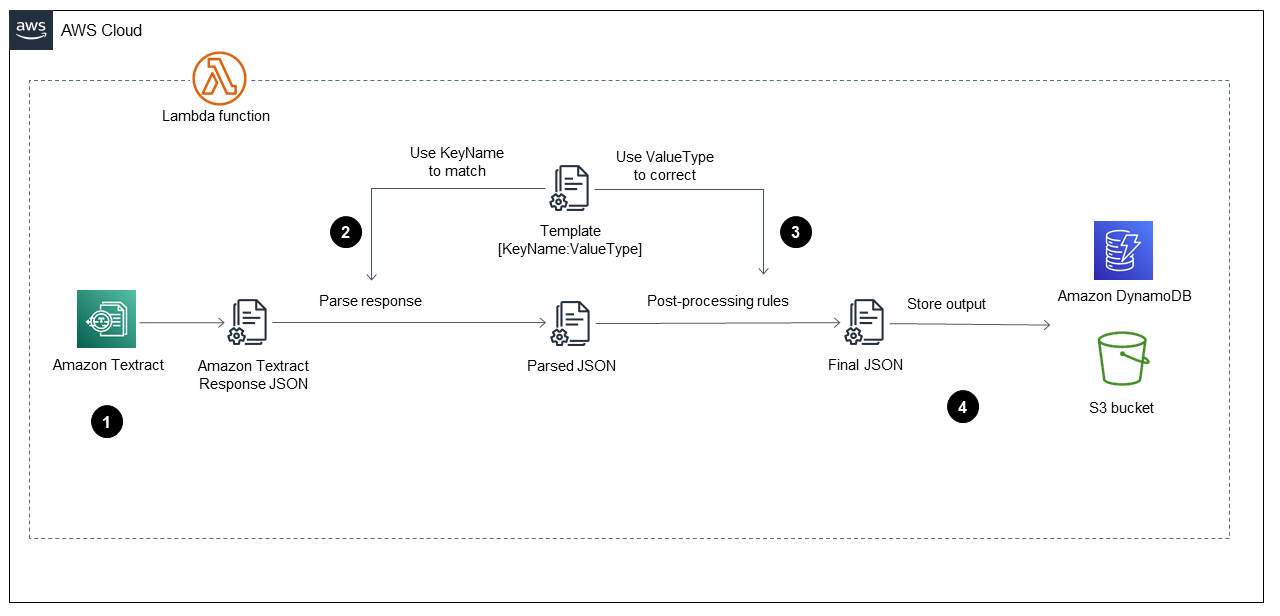
Diagram menunjukkan fungsi Lambda menerapkan langkah-langkah berikut:
-
Memanggil Amazon Ttract untuk memproses file PDF, mengekstrak konten, dan mengembalikan file berformat JSON.
-
Mengambil file JSON dan mengurai formulir dan tabel dengan menggunakan file
TemplateJSON yang telah ditentukan sebelumnya yang memiliki nama kunci dan jenis nilai yang benar untuk setiap bidang. Proses ini menyediakan file JSON yang diurai. -
Menerapkan aturan pasca-pemrosesan dan menggunakan file
TemplateJSON untuk mengoreksi setiap nilai dalam file JSON yang diurai. Ini menghasilkan fileFinalJSON. FileTemplateJSON yang telah ditentukan dapat disimpan di bucket S3. -
Menyimpan file
FinalJSON di Amazon DynamoDB sebagai satu catatan untuk setiap file PDF, selain satu file JSON untuk setiap file PDF dalam bucket keluaran S3.
Untuk step-by-step alur kerja yang menggunakan Amazon Ttract untuk secara otomatis mengekstrak konten dari file PDF dan memprosesnya menjadi output bersih, lihat polanya Ekstrak konten secara otomatis dari file PDF menggunakan Amazon Textract di AWS situs web Prescriptive Guidance. Pola menggunakan teknik pencocokan template untuk mengidentifikasi dengan benar bidang yang diperlukan, nama kunci, dan tabel, dan kemudian menerapkan koreksi pasca-pemrosesan untuk setiap tipe data.
Praktik terbaik untuk fase pemrosesan
Gunakan empat praktik terbaik berikut untuk memastikan fase pemrosesan yang sukses:
-
Buat file JSON template untuk setiap jenis file PDF yang ingin Anda proses. Anda dapat menyimpan file JSON template yang berbeda ini dalam bucket S3 yang dipanggil oleh fungsi Lambda. Jika Anda ingin memproses jenis file PDF yang berbeda dalam satu fungsi Lambda, Anda harus menggunakan pengidentifikasi unik untuk setiap jenis file PDF (misalnya, nama folder jenis file PDF di ember S3). Setelah fungsi Lambda dipanggil, ia mengambil file JSON template yang sesuai dan memprosesnya.
-
Siapkan mekanisme untuk melacak status setiap langkah secara akurat dalam fungsi Lambda. Misalnya, Anda dapat menambahkan
Successstatus setelah panggilan Amazon Textract, saat file JSON terakhir disimpan ke tabel Amazon DynamoDB, atau saat file PDF disimpan ke bucket S3. Anda juga dapat membuat tabel DynamoDB terpisah untuk melacak status setiap file PDF dalam langkah yang berbeda, yang memberikan visibilitas ke dalam proses. -
Kelola pelambatan dan koneksi terputus dengan secara otomatis mencoba kembali operasi yang gagal saat Anda memproses banyak file PDF secara batch. Pelambatan dapat terjadi di Amazon Textract jika koneksi Anda turun atau Anda melebihi jumlah maksimum transaksi per detik (TPS). Untuk informasi selengkapnya dan langkah-langkah untuk mencoba kembali operasi yang gagal secara otomatis, lihat Menangani panggilan terbatas dan koneksi terputus dalam dokumentasi Amazon Textract.
-
Jika Anda memiliki file PDF dengan beberapa halaman, Anda dapat menggunakan operasi asinkron untuk memproses seluruh file atau memecah file PDF menjadi satu halaman, menggunakan operasi sinkron untuk memproses setiap halaman, dan kemudian menggabungkan hasil setiap halaman. Untuk implementasi kode lengkap dari operasi asinkron, lihat Mendeteksi dan menganalisis teks dalam dokumen multihalaman dalam dokumentasi Amazon Textract. Untuk informasi selengkapnya tentang penggunaan operasi sinkron, lihat Mendeteksi dan menganalisis teks dalam dokumen satu halaman dalam dokumentasi Amazon Textract.
