Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Arsitektur untuk meramalkan permintaan pengiriman
Gambar berikut menunjukkan alur kerja solusi, termasuk konsumsi data, persiapan data, pembuatan model, dan output akhir dan pemantauan.
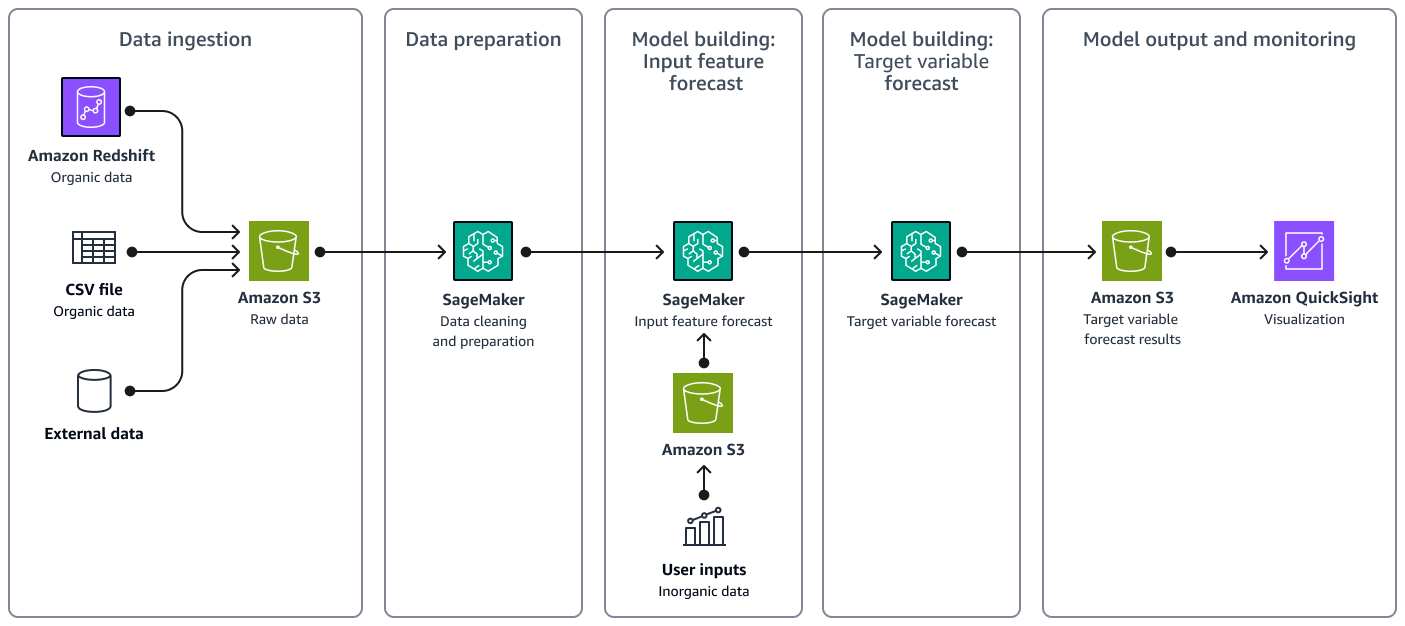
Arsitektur solusi mencakup komponen utama berikut:
-
Konsumsi data - Anda menyimpan data organik dan data eksternal di Amazon Simple Storage Service (Amazon S3).
-
Persiapan data — Amazon SageMaker AI membersihkan data dan menyiapkannya untuk pelatihan model ML. Untuk informasi selengkapnya, lihat Mempersiapkan data dalam dokumentasi SageMaker AI.
-
Pembuatan model: Prakiraan fitur input - penggunaan SageMaker AI Prophet
untuk menghasilkan perkiraan deret waktu untuk setiap fitur input. Anda memeriksa hasil perkiraan. Jika diperlukan, Anda memberikan input pengguna untuk menimpa perkiraan fitur. -
Pembuatan model: Perkiraan variabel target - SageMaker AI membuat model regresi untuk inferensi dengan menggunakan fitur input yang dimodifikasi.
-
Output dan pemantauan model - Model regresi mengeluarkan hasil perkiraan ke Amazon S3. Anda dapat memvisualisasikan ramalan di Amazon QuickSight. Analis dapat memantau hasil perkiraan dan mengevaluasi akurasi dengan membandingkan perkiraan dengan volume permintaan aktual.
Seluruh pipa pemrosesan dari konsumsi data hingga keluaran model akhir dapat diatur untuk berjalan secara otomatis. Misalnya, Anda dapat mengaturnya untuk berjalan secara otomatis setiap bulan untuk perkiraan permintaan bulanan. Jika Anda membutuhkan perkiraan untuk lebih dari satu produk, Anda dapat menjalankan pipeline secara paralel untuk beberapa produk. Untuk informasi selengkapnya, lihat Menerapkan MLOps dalam dokumentasi SageMaker AI.
