Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Penurunan suhu
Dalam masalah klasifikasi, probabilitas yang diprediksi (softmax output) diasumsikan mewakili probabilitas kebenaran sejati untuk kelas yang diprediksi. Namun, meskipun asumsi ini mungkin masuk akal untuk model satu dekade yang lalu, itu tidak benar untuk model jaringan saraf modern saat ini (Guo dkk. 2017). Hilangnya hubungan antara model yang memprediksi probabilitas dan kepercayaan prediksi model akan mencegah penerapan model jaringan saraf modern menjadi masalah dunia nyata, seperti dalam sistem pengambilan keputusan. Dengan tepat mengetahui skor kepercayaan dari prediksi model adalah salah satu pengaturan kontrol risiko paling penting yang diperlukan untuk membangun aplikasi pembelajaran mesin yang kuat dan dapat dipercaya.
Model jaringan saraf modern cenderung memiliki arsitektur besar dengan jutaan parameter pembelajaran. Distribusi prediksi probabilitas dalam model semacam itu seringkali sangat miring ke 1 atau 0, yang berarti bahwa model terlalu percaya diri dan nilai absolut dari probabilitas ini bisa jadi tidak berarti. (Masalah ini independen dari apakah ketidakseimbangan kelas hadir dalam dataset.) Berbagai metode kalibrasi untuk menciptakan skor kepercayaan prediksi telah dikembangkan dalam sepuluh tahun terakhir melalui langkah-langkah pasca-pemrosesan untuk mengkalibrasi ulang probabilitas naif model. Bagian ini menjelaskan satu metode kalibrasi yang disebutPenurunan suhu, yang merupakan teknik sederhana namun efektif untuk mengkalibrasi ulang probabilitas prediksi (Guo dkk. 2017). Penskalaan suhu adalah versi parameter tunggal dari Platt Logistic Scaling (Platt 1999).
Penskalaan suhu menggunakan parameter skalar tunggalT > 0, di manaTadalah suhu, untuk rescale skor logit sebelum menerapkan fungsi softmax, seperti yang ditunjukkan pada gambar berikut. Karena samaTdigunakan untuk semua kelas, output softmax dengan penskalaan memiliki hubungan monotonik dengan output unscaled. SaatT= 1, Anda memulihkan probabilitas asli dengan fungsi softmax default. Dalam model terlalu percaya diri di manaT > 1, probabilitas kalibrasi ulang memiliki nilai yang lebih rendah daripada probabilitas asli, dan mereka lebih merata antara 0 dan 1.
Metode untuk mendapatkan suhu optimalTuntuk model terlatih adalah melalui meminimalkan kemungkinan log negatif untuk dataset validasi diadakan-out.
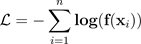
Sebaiknya Anda mengintegrasikan metode penskalaan suhu sebagai bagian dari proses pelatihan model: Setelah pelatihan model selesai, ekstrak nilai suhuTdengan menggunakan dataset validasi, dan kemudian rescale nilai logit dengan menggunakanTdalam fungsi softmax. Berdasarkan percobaan dalam tugas klasifikasi teks menggunakan model berbasis BERT, suhuTbiasanya skala antara 1,5 dan 3.
Gambar berikut menggambarkan metode penskalaan suhu, yang berlaku nilai suhuTsebelum melewati skor logit ke fungsi softmax.
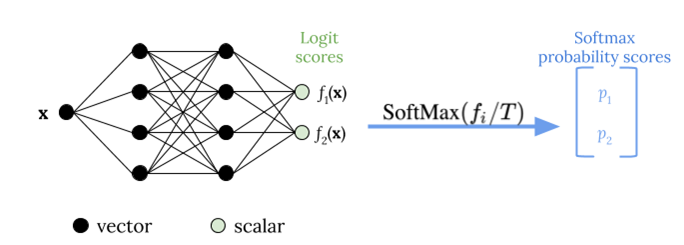
Probabilitas yang dikalibrasi dengan penskalaan suhu kira-kira dapat mewakili skor kepercayaan prediksi model. Hal ini dapat dievaluasi secara kuantitatif dengan membuat diagram keandalan (Guo dkk. 2017), yang mewakili keselarasan antara distribusi akurasi yang diharapkan dan distribusi prediksi probabilitas.
Penskalaan suhu juga telah dievaluasi sebagai cara efektif untuk mengukur ketidakpastian prediktif total dalam probabilitas yang dikalibrasi, tetapi tidak kuat dalam menangkap ketidakpastian epistemik dalam skenario seperti drift data (Ovadia et al. 2019). Mengingat kemudahan implementasi, kami menyarankan agar Anda menerapkan penskalaan suhu pada output model deep learning Anda untuk membangun solusi yang kuat untuk mengukur ketidakpastian prediktif.
