Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Praktik terbaik
Kami menyarankan Anda mengikuti praktik terbaik penyimpanan dan teknis. Praktik terbaik ini dapat membantu Anda mendapatkan hasil maksimal dari ariktur data-sentris Anda.
Praktik terbaik penyimpanan untuk data besar
Tabel berikut menjelaskan praktik terbaik umum untuk menyimpan file untuk beban pemrosesan data besar di Amazon S3. Kolom terakhir adalah contoh kebijakan siklus hidup yang dapat Anda atur. Jika Amazon S3 Intelligent-Tiering
Nama lapisan data | Deskripsi | Contoh strategi kebijakan siklus hidup |
Mentah | Berisi data mentah yang belum diproses Catatan: Untuk sumber data eksternal, lapisan data mentah biasanya merupakan salinan data 1:1, tetapi pada AWS data dapat dipartisi berdasarkan kunci berdasarkan Wilayah AWS atau tanggal selama proses konsumsi. | Setelah satu tahun, pindahkan file ke kelas penyimpanan IA standar S3. Setelah dua tahun di S3 Standard-IA, arsipkan file di Amazon Simple Storage Service Glacier (Amazon S3 Glacier). |
Stage | Berisi data olahan menengah yang dioptimalkan untuk konsumsi Contoh: CSV ke Apache Parquet mengonversi file mentah atau transformasi data | Anda dapat menghapus data setelah periode waktu yang ditentukan atau sesuai dengan persyaratan organisasi Anda. Anda dapat menghapus beberapa turunan data (misalnya, transformasi Apache Avro dari format JSON asli) dari data lake setelah waktu yang lebih singkat (misalnya, setelah 90 hari). |
Analitik | Berisi data agregat untuk kasus penggunaan spesifik Anda dalam format siap konsumsi Contoh: Apache Parquet | Anda dapat memindahkan data ke IA Standar S3, lalu menghapus data setelah periode waktu yang ditentukan atau sesuai dengan persyaratan organisasi Anda. |
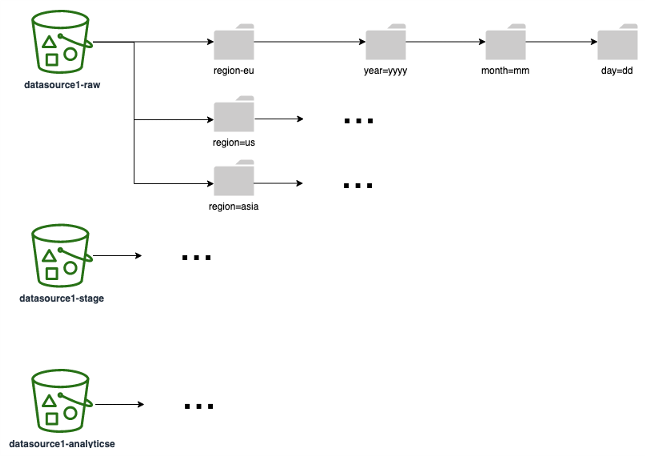
Diagram berikut menunjukkan contoh strategi partisi (sesuai dengan satu folder/awalan S3) yang dapat Anda gunakan di semua lapisan data. Kami menyarankan Anda memilih strategi partisi berdasarkan bagaimana data Anda digunakan di hilir. Misalnya, jika laporan dibuat berdasarkan data Anda (di mana kueri paling umum pada laporan memfilter hasil berdasarkan wilayah dan tanggal), pastikan untuk menyertakan wilayah dan tanggal sebagai partisi untuk meningkatkan kinerja kueri dan runtime.
Praktik terbaik teknis
Praktik terbaik teknis bergantung pada layanan AWS spesifik dan teknologi pemrosesan yang Anda gunakan untuk mendesain arsitektur data-sentris Anda. Namun, kami menyarankan Anda untuk mengingat praktik terbaik berikut. Praktik terbaik ini berlaku untuk kasus penggunaan pemrosesan data yang khas.
Luas | Praktik terbaik |
SQL | Kurangi jumlah data yang harus ditanyakan dengan memproyeksikan atribut pada data Anda. Alih-alih mengurai seluruh tabel, Anda dapat menggunakan proyeksi data untuk memindai dan mengembalikan hanya kolom tertentu yang diperlukan dalam tabel. Hindari gabungan besar jika memungkinkan karena gabungan antara beberapa tabel dapat secara signifikan mempengaruhi kinerja karena tuntutan sumber daya mereka yang intensif. |
Apache Spark | Optimalkan aplikasi Spark Optimalkan manajemen memori |
Desain database | Ikuti Praktik Terbaik Arsitektur untuk Database |
Pemangkasan data | Gunakan pemangkasan partisi sisi server dengan. |
Penskalaan | Memahami dan menerapkan penskalaan horizontal |
