Launch a Spark job in a transient EMR cluster using a Lambda function
Dhrubajyoti Mukherjee, Amazon Web Services
Summary
This pattern uses the Amazon EMR RunJobFlow API action to launch a transient cluster to run a Spark job from a Lambda function. A transient EMR cluster is designed to terminate as soon as the job is complete or if any error occurs. A transient cluster provides cost savings because it runs only during the computation time, and it provides scalability and flexibility in a cloud environment.
The transient EMR cluster is launched using the Boto3 API and the Python programming language in a Lambda function. The Lambda function, which is written in Python, provides the added flexibility of initiating the cluster when it is needed.
To demonstrate a sample batch computation and output, this pattern will launch a Spark job in an EMR cluster from a Lambda function and run a batch computation against the example sales data of a fictional company. The output of the Spark job will be a comma-separated values (CSV) file in Amazon Simple Storage Service (Amazon S3). The input data file, Spark .jar file, a code snippet, and an AWS CloudFormation template for a virtual private cloud (VPC) and AWS Identity and Access Management (IAM) roles to run the computation are provided as an attachment.
Prerequisites and limitations
Prerequisites
An active AWS account
Limitations
Only one Spark job can be initiated from the code at a time.
Product versions
Tested on Amazon EMR 6.0.0
Architecture
Target technology stack
Amazon EMR
AWS Lambda
Amazon S3
Apache Spark
Target architecture
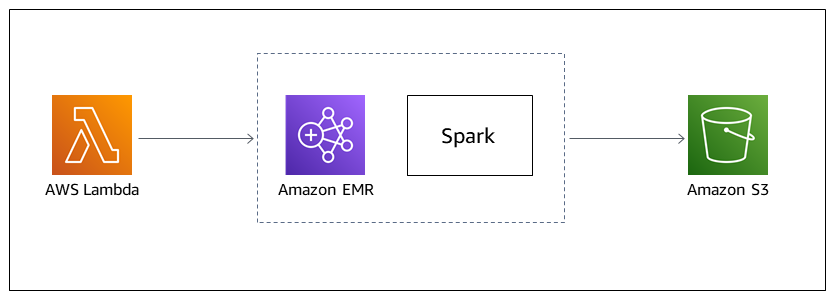
Automation and scale
To automate the Spark-EMR batch computation, you can use either of the following options.
Implement an Amazon EventBridge rule that can initiate the Lambda function in a cron schedule. For more information, see Tutorial: Schedule AWS Lambda functions using EventBridge.
Configure Amazon S3 event notifications to initiate the Lambda function on file arrival.
Pass the input parameters to the AWS Lambda function through the event body and Lambda environment variables.
Tools
AWS services
Amazon EMR is a managed cluster platform that simplifies running big data frameworks on AWS to process and analyze large amounts of data.
AWS Lambda is a compute service that helps you run code without needing to provision or manage servers. It runs your code only when needed and scales automatically, so you pay only for the compute time that you use.
Amazon Simple Storage Service (Amazon S3) is a cloud-based object storage service that helps you store, protect, and retrieve any amount of data.
Other tools
Apache Spark
is a multiple-language analytics engine for large-scale data processing.
Epics
| Task | Description | Skills required |
|---|---|---|
Create the IAM roles and the VPC. | If you already have the AWS Lambda and Amazon EMR IAM roles and a VPC, you can skip this step. To run the code, both the EMR cluster and the Lambda function require IAM roles. The EMR cluster also requires a VPC with a public subnet or a private subnet with a NAT gateway. To automatically create all the IAM roles and a VPC, deploy the attached AWS CloudFormation template as is, or you can create the roles and the VPC manually as specified in the Additional information section. | Cloud architect |
Note the AWS CloudFormation template output keys. | After the CloudFormation template has successfully deployed, navigate to the Outputs tab in the AWS CloudFormation console. Note the five output keys:
You will use the values from these keys when you create the Lambda function. | Cloud architect |
| Task | Description | Skills required |
|---|---|---|
Upload the Spark .jar file. | Upload the Spark .jar file to the S3 bucket that the AWS CloudFormation stack created. The bucket name is the same as the output key | General AWS |
| Task | Description | Skills required |
|---|---|---|
Create a Lambda function. | On the Lambda console, create a Python 3.9+ Lambda function with an execution role. The execution role policy must allow Lambda to launch an EMR cluster. (See the attached AWS CloudFormation template.) | Data engineer, Cloud engineer |
Copy and paste the code. | Replace the code in the | Data engineer, Cloud engineer |
Change the parameters in the code. | Follow the comments in the code to change the parameter values to match your AWS account. | Data engineer, Cloud engineer |
Launch the function to initiate the cluster. | Launch the function to initiate the creation of a transient EMR cluster with the Spark .jar file provided. It will run the Spark job and terminate automatically when the job is complete. | Data engineer, Cloud engineer |
Check the EMR cluster status. | After the EMR cluster is initiated, it appears in the Amazon EMR console under the Clusters tab. Any errors while launching the cluster or running the job can be be checked accordingly. | Data engineer, Cloud engineer |
| Task | Description | Skills required |
|---|---|---|
Upload the Spark .jar file. | Download the Spark .jar file from the Attachments section and upload it to the S3 bucket. | Data engineer, Cloud engineer |
Upload the input dataset. | Upload the attached | Data engineer, Cloud engineer |
Paste the Lambda code and change the parameters. | Copy the code from the Tools section, and paste the code in a Lambda function, replacing the code | Data engineer, Cloud engineer |
Launch the function and verify the output. | After the Lambda function initiates the cluster with the provided Spark job, it generates a .csv file in the S3 bucket. | Data engineer, Cloud engineer |
Related resources
Additional information
Code
""" Copy paste the following code in your Lambda function. Make sure to change the following key parameters for the API as per your account -Name (Name of Spark cluster) -LogUri (S3 bucket to store EMR logs) -Ec2SubnetId (The subnet to launch the cluster into) -JobFlowRole (Service role for EC2) -ServiceRole (Service role for Amazon EMR) The following parameters are additional parameters for the Spark job itself. Change the bucket name and prefix for the Spark job (located at the bottom). -s3://your-bucket-name/prefix/lambda-emr/SparkProfitCalc.jar (Spark jar file) -s3://your-bucket-name/prefix/fake_sales_data.csv (Input data file in S3) -s3://your-bucket-name/prefix/outputs/report_1/ (Output location in S3) """ import boto3 client = boto3.client('emr') def lambda_handler(event, context): response = client.run_job_flow( Name='spark_job_cluster', LogUri='s3://your-bucket-name/prefix/logs', ReleaseLabel='emr-6.0.0', Instances={ 'MasterInstanceType': 'm5.xlarge', 'SlaveInstanceType': 'm5.large', 'InstanceCount': 1, 'KeepJobFlowAliveWhenNoSteps': False, 'TerminationProtected': False, 'Ec2SubnetId': 'subnet-XXXXXXXXXXXXXX' }, Applications=[{'Name': 'Spark'}], Configurations=[ {'Classification': 'spark-hive-site', 'Properties': { 'hive.metastore.client.factory.class': 'com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory'} } ], VisibleToAllUsers=True, JobFlowRole='EMRLambda-EMREC2InstanceProfile-XXXXXXXXX', ServiceRole='EMRLambda-EMRRole-XXXXXXXXX', Steps=[ { 'Name': 'flow-log-analysis', 'ActionOnFailure': 'TERMINATE_CLUSTER', 'HadoopJarStep': { 'Jar': 'command-runner.jar', 'Args': [ 'spark-submit', '--deploy-mode', 'cluster', '--executor-memory', '6G', '--num-executors', '1', '--executor-cores', '2', '--class', 'com.aws.emr.ProfitCalc', 's3://your-bucket-name/prefix/lambda-emr/SparkProfitCalc.jar', 's3://your-bucket-name/prefix/fake_sales_data.csv', 's3://your-bucket-name/prefix/outputs/report_1/' ] } } ] )
IAM roles and VPC creation
To launch the EMR cluster in a Lambda function, a VPC and IAM roles are needed. You can set up the VPC and IAM roles by using the AWS CloudFormation template in the Attachments section of this pattern, or you can manually create them by using the following links.
The following IAM roles are required to run Lambda and Amazon EMR.
Lambda execution role
A Lambda function's execution role grants it permission to access AWS services and resources.
Service role for Amazon EMR
The Amazon EMR role defines the allowable actions for Amazon EMR when provisioning resources and performing service-level tasks that are not performed in the context of an Amazon Elastic Compute Cloud (Amazon EC2) instance running within a cluster. For example, the service role is used to provision EC2 instances when a cluster launches.
Service role for EC2 instances
The service role for cluster EC2 instances (also called the EC2 instance profile for Amazon EMR) is a special type of service role that is assigned to every EC2 instance in an Amazon EMR cluster when the instance launches. Application processes that run on top of Apache Hadoop assume this role for permissions to interact with other AWS services.
VPC and subnet creation
You can create a VPC from the VPC console.
Attachments
To access additional content that is associated with this document, unzip the following file: attachment.zip
