Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Kasus penggunaan: Mengelola dan meningkatkan keterampilan staf perawatan kesehatan Anda
Menerapkan strategi transformasi bakat dan peningkatan keterampilan membantu tenaga kerja tetap mahir dalam menggunakan teknologi dan praktik baru dalam layanan medis dan perawatan kesehatan. Inisiatif peningkatan keterampilan proaktif memastikan bahwa profesional perawatan kesehatan dapat memberikan perawatan pasien berkualitas tinggi, mengoptimalkan efisiensi operasional, dan tetap mematuhi standar peraturan. Selain itu, transformasi bakat menumbuhkan budaya pembelajaran berkelanjutan. Ini sangat penting untuk beradaptasi dengan lanskap perawatan kesehatan yang berubah dan mengatasi tantangan kesehatan masyarakat yang muncul. Pendekatan pelatihan tradisional, seperti pelatihan berbasis kelas dan modul pembelajaran statis, menawarkan konten yang seragam kepada khalayak luas. Mereka sering tidak memiliki jalur pembelajaran yang dipersonalisasi, yang sangat penting untuk memenuhi kebutuhan spesifik dan tingkat kemahiran praktisi individu. one-size-fits-allStrategi ini dapat mengakibatkan pelepasan dan retensi pengetahuan yang kurang optimal.
Akibatnya, organisasi perawatan kesehatan harus merangkul solusi inovatif, terukur, dan berbasis teknologi yang dapat menentukan kesenjangan untuk setiap karyawan mereka dalam keadaan mereka saat ini dan keadaan masa depan yang potensial. Solusi ini harus merekomendasikan jalur pembelajaran yang sangat personal dan kumpulan konten pembelajaran yang tepat. Ini secara efektif mempersiapkan tenaga kerja untuk masa depan perawatan kesehatan.
Dalam industri perawatan kesehatan, Anda dapat menerapkan AI generatif untuk membantu Anda memahami dan meningkatkan tenaga kerja Anda. Melalui koneksi model bahasa besar (LLMs) dan retriever tingkat lanjut, organisasi dapat memahami keterampilan apa yang mereka miliki saat ini dan mengidentifikasi keterampilan kunci yang mungkin diperlukan di masa depan. Informasi ini membantu Anda menjembatani kesenjangan dengan mempekerjakan pekerja baru dan meningkatkan keterampilan tenaga kerja saat ini. Menggunakan Amazon Bedrock dan grafik pengetahuan, organisasi perawatan kesehatan dapat mengembangkan aplikasi khusus domain yang memfasilitasi pembelajaran berkelanjutan dan pengembangan keterampilan.
Pengetahuan yang diberikan oleh solusi ini membantu Anda mengelola bakat secara efektif, mengoptimalkan kinerja tenaga kerja, mendorong kesuksesan organisasi, mengidentifikasi keterampilan yang ada, dan menyusun strategi bakat. Solusi ini dapat membantu Anda melakukan tugas-tugas ini dalam beberapa minggu, bukan bulan.
Ikhtisar solusi
Solusi ini adalah kerangka transformasi bakat kesehatan yang terdiri dari komponen-komponen berikut:
-
Parser resume cerdas - Komponen ini dapat membaca resume kandidat dan secara tepat mengekstrak informasi kandidat, termasuk keterampilan. Solusi ekstraksi informasi cerdas yang dibuat menggunakan model Llama 2 yang disetel dengan baik di Amazon Bedrock pada kumpulan data pelatihan eksklusif yang mencakup resume dan profil bakat dari lebih dari 19 industri. Proses berbasis LLM ini menghemat ratusan jam dengan mengotomatiskan proses peninjauan manual resume dan mencocokkan kandidat teratas untuk membuka peran.
-
Grafik pengetahuan — Grafik pengetahuan yang dibangun di Amazon Neptunus, gudang informasi bakat terpadu termasuk taksonomi peran dan keterampilan organisasi serta industri, menangkap semantik bakat perawatan kesehatan menggunakan definisi keterampilan, peran dan propertinya, hubungan, dan kendala logis.
-
Ontologi keterampilan — Penemuan kedekatan keterampilan antara keterampilan kandidat dan keadaan ideal saat ini atau keterampilan keadaan masa depan (diambil menggunakan grafik pengetahuan) dicapai melalui algoritma ontologi yang mengukur kesamaan semantik antara keterampilan kandidat dan keterampilan status target.
-
Jalur dan konten pembelajaran — Komponen ini adalah mesin rekomendasi pembelajaran yang dapat merekomendasikan konten pembelajaran yang tepat dari katalog materi pembelajaran dari vendor mana pun berdasarkan kesenjangan keterampilan yang diidentifikasi. Mengidentifikasi jalur peningkatan keterampilan yang paling optimal untuk setiap kandidat dengan menganalisis kesenjangan keterampilan dan merekomendasikan konten pembelajaran yang diprioritaskan, untuk memungkinkan pengembangan profesional yang mulus dan berkelanjutan untuk setiap kandidat selama transisi ke peran baru.
Solusi otomatis berbasis cloud ini didukung oleh layanan pembelajaran mesin, grafik pengetahuan LLMs, dan Retrieval Augmented Generation (RAG). Ini dapat menskalakan untuk memproses puluhan atau ribuan resume dalam jumlah waktu minimum, membuat profil kandidat instan, mengidentifikasi kesenjangan dalam keadaan masa depan mereka saat ini atau potensial, dan kemudian secara efisien merekomendasikan konten pembelajaran yang tepat untuk menutup kesenjangan ini.
Gambar berikut menunjukkan end-to-end aliran kerangka kerja. Solusinya dibangun di atas fine-tuned di LLMs Amazon Bedrock. Ini LLMs mengambil data dari basis pengetahuan bakat perawatan kesehatan di Amazon Neptunus. Algoritma berbasis data membuat rekomendasi untuk jalur pembelajaran yang optimal untuk setiap kandidat.
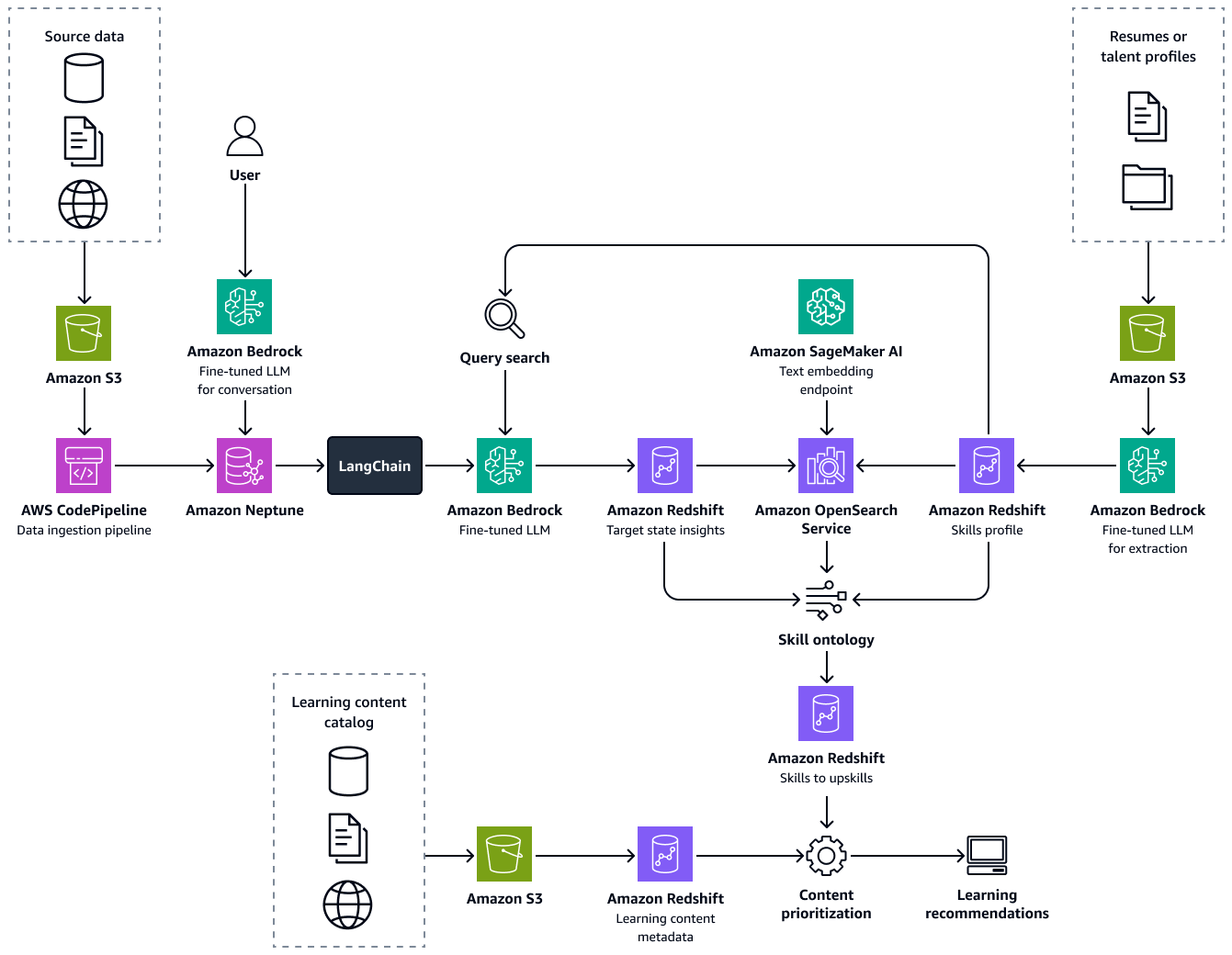
Membangun solusi ini terdiri dari langkah-langkah berikut:
Langkah 1: Mengekstrak informasi bakat dan membangun profil keterampilan
Pertama, Anda menyempurnakan model bahasa besar, seperti Llama 2, di Amazon Bedrock dengan kumpulan data khusus. Ini menyesuaikan LLM untuk kasus penggunaan. Selama pelatihan, Anda secara akurat dan konsisten mengekstrak atribut bakat utama dari resume kandidat atau profil bakat serupa. Atribut bakat ini termasuk keterampilan, judul peran saat ini, judul pengalaman dengan rentang tanggal, pendidikan, dan sertifikasi. Untuk informasi selengkapnya, lihat Menyesuaikan model Anda untuk meningkatkan kinerjanya untuk kasus penggunaan Anda di dokumentasi Amazon Bedrock.
Gambar berikut menunjukkan proses untuk menyempurnakan model resume-parsing dengan menggunakan Amazon Bedrock. Resume nyata dan sintetis dibuat diteruskan ke LLM untuk mengekstrak informasi kunci. Sekelompok ilmuwan data memvalidasi informasi yang diekstraksi terhadap teks mentah asli. Informasi yang diekstraksi kemudian digabungkan dengan menggunakan chain-of-thought
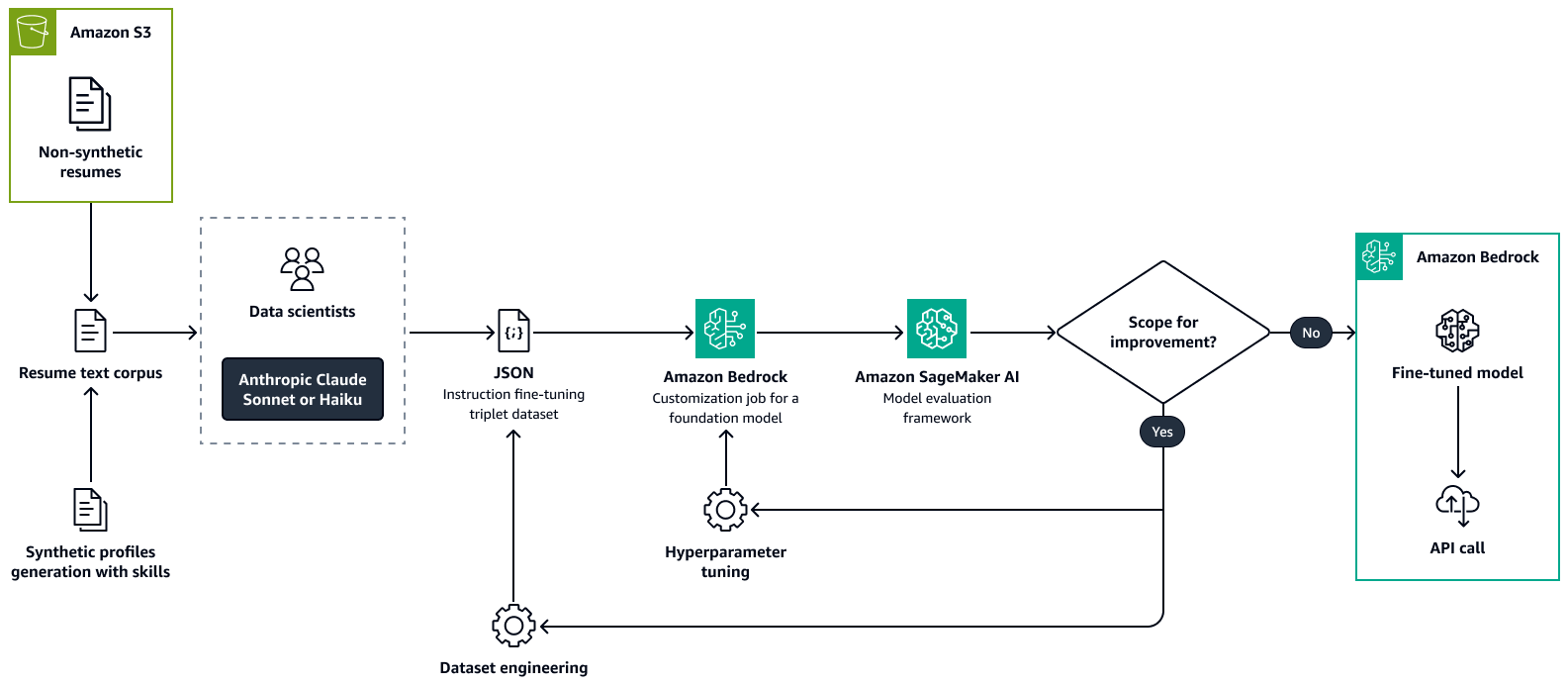
Langkah 2: Menemukan role-to-skill relevansi dari grafik pengetahuan
Selanjutnya, Anda membangun grafik pengetahuan yang merangkum keterampilan dan peran taksonomi organisasi Anda dan organisasi lain di industri perawatan kesehatan. Basis pengetahuan yang diperkaya ini bersumber dari bakat gabungan dan data organisasi di Amazon Redshift. Anda dapat mengumpulkan data bakat dari berbagai penyedia data pasar tenaga kerja dan dari sumber data terstruktur dan tidak terstruktur khusus organisasi, seperti sistem perencanaan sumber daya perusahaan (ERP), sistem informasi sumber daya manusia (HRIS), resume karyawan, deskripsi pekerjaan, dan dokumen arsitektur bakat.
Bangun grafik pengetahuan di Amazon Neptunus. Node mewakili keterampilan dan peran, dan tepi mewakili hubungan di antara mereka. Perkaya grafik ini dengan metadata untuk menyertakan detail seperti nama organisasi, industri, keluarga pekerjaan, jenis keterampilan, tipe peran, dan tag industri.
Selanjutnya, Anda mengembangkan aplikasi Graph Retrieval Augmented Generation (Graph RAG). Graph RAG adalah pendekatan RAG yang mengambil data dari database grafik. Berikut ini adalah komponen aplikasi Graph RAG:
-
Integrasi dengan LLM di Amazon Bedrock - Aplikasi ini menggunakan LLM di Amazon Bedrock untuk pemahaman bahasa alami dan pembuatan kueri. Pengguna dapat berinteraksi dengan sistem dengan menggunakan bahasa alami. Ini membuatnya dapat diakses oleh pemangku kepentingan non-teknis.
-
Orkestrasi dan pengambilan informasi — Gunakan atau LlamaIndex
LangChain orkestrator untuk memfasilitasi integrasi antara LLM dan grafik pengetahuan Neptunus. Mereka mengelola proses mengubah kueri bahasa alami menjadi kueri OpenCypher . Kemudian, mereka menjalankan kueri pada grafik pengetahuan. Gunakan teknik cepat untuk menginstruksikan LLM tentang praktik terbaik untuk membangun kueri OpenCypher. Ini membantu mengoptimalkan kueri untuk mengambil subgraf yang relevan, yang berisi semua entitas dan hubungan terkait tentang peran dan keterampilan yang ditanyakan. -
Pembuatan wawasan - LLM di Amazon Bedrock memproses data grafik yang diambil. Ini menghasilkan wawasan terperinci tentang keadaan saat ini dan memproyeksikan status masa depan untuk peran yang ditanyakan dan keterampilan terkait.
Gambar berikut menunjukkan langkah-langkah untuk membangun grafik pengetahuan dari sumber data. Anda meneruskan data sumber terstruktur dan tidak terstruktur ke pipeline konsumsi data. Pipeline mengekstrak dan mengubah informasi menjadi formasi beban massal CSV yang kompatibel dengan Amazon Neptunus. API pemuat massal mengunggah file CSV yang disimpan dalam bucket Amazon S3 ke grafik pengetahuan Neptunus. Untuk kueri pengguna yang terkait dengan status talent future, peran yang relevan, atau keterampilan, LLM yang disetel dengan baik di Amazon Bedrock berinteraksi dengan grafik pengetahuan melalui a LangChain orkestrator. Orkestrator mengambil konteks yang relevan dari grafik pengetahuan dan mendorong respons ke tabel wawasan di Amazon Redshift. Bagian LangChain orkestrator, seperti Graph QAChain
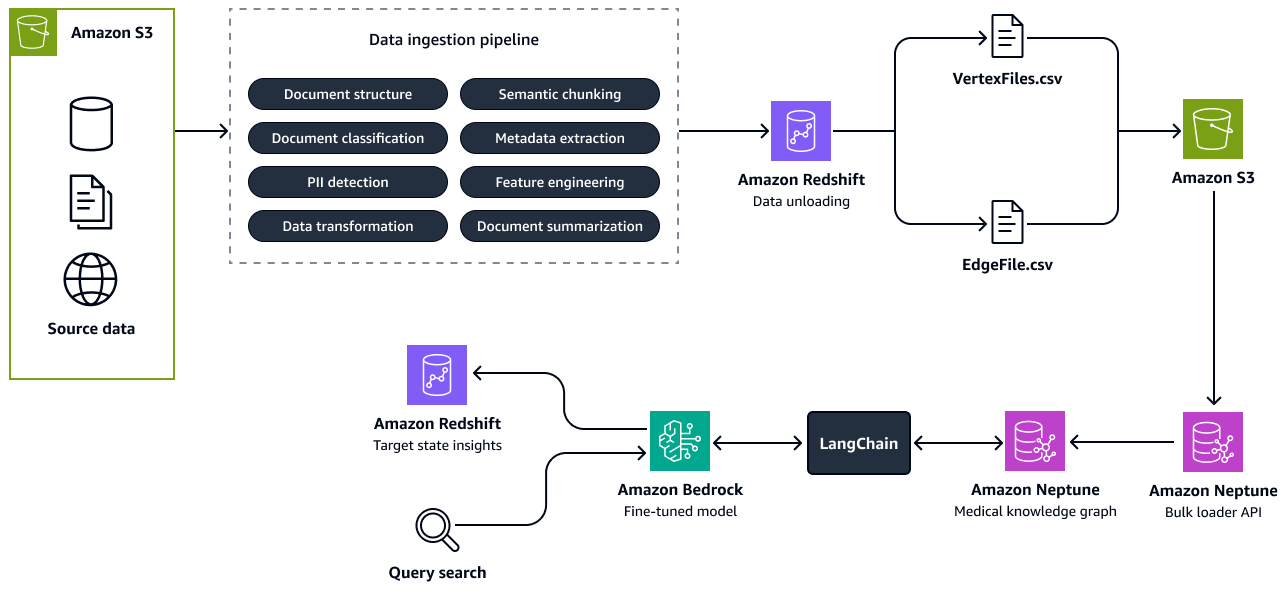
Langkah 3: Mengidentifikasi kesenjangan keterampilan dan merekomendasikan pelatihan
Pada langkah ini, Anda secara akurat menghitung kedekatan antara keadaan profesional kesehatan saat ini dan peran negara masa depan yang potensial. Untuk melakukan ini, Anda melakukan analisis afinitas keterampilan dengan membandingkan set keterampilan individu dengan peran pekerjaan. Dalam database vektor OpenSearch Layanan Amazon, Anda menyimpan informasi taksonomi keterampilan dan metadata keterampilan, seperti deskripsi keterampilan, jenis keterampilan, dan kelompok keterampilan. Gunakan model penyematan Amazon Bedrock, seperti model Amazon Titan Text Embeddings, untuk menyematkan keterampilan kunci yang diidentifikasi ke dalam vektor. Melalui pencarian vektor, Anda mengambil deskripsi keterampilan keadaan saat ini dan keterampilan status target dan melakukan analisis ontologi. Analisis ini memberikan skor kedekatan antara pasangan keterampilan status saat ini dan target. Untuk setiap pasangan, Anda menggunakan skor ontologi yang dihitung untuk mengidentifikasi kesenjangan dalam afinitas keterampilan. Kemudian, Anda merekomendasikan jalur optimal untuk peningkatan keterampilan, yang dapat dipertimbangkan kandidat selama transisi peran.
Untuk setiap peran, merekomendasikan konten pembelajaran yang benar untuk meningkatkan keterampilan atau reskilling melibatkan pendekatan sistematis yang dimulai dengan membuat katalog konten pembelajaran yang komprehensif. Katalog ini, yang Anda simpan dalam database Amazon Redshift, menggabungkan konten dari berbagai penyedia dan menyertakan metadata, seperti durasi konten, tingkat kesulitan, dan mode pembelajaran. Langkah selanjutnya adalah mengekstrak keterampilan kunci yang ditawarkan oleh setiap konten dan kemudian memetakannya ke keterampilan individu yang diperlukan untuk peran target. Anda mencapai pemetaan ini dengan menganalisis cakupan yang disediakan oleh konten melalui analisis kedekatan keterampilan. Analisis ini menilai seberapa dekat keterampilan yang diajarkan oleh konten selaras dengan keterampilan yang diinginkan untuk peran tersebut. Metadata memainkan peran penting dalam memilih konten yang paling tepat untuk setiap keterampilan, memastikan bahwa peserta didik menerima rekomendasi khusus yang sesuai dengan kebutuhan belajar mereka. Gunakan LLMs di Amazon Bedrock untuk mengekstrak keterampilan dari metadata konten, melakukan rekayasa fitur, dan memvalidasi rekomendasi konten. Ini meningkatkan akurasi dan relevansi dalam proses peningkatan keterampilan atau reskilling.
Penyelarasan dengan Kerangka AWS Well-Architected
Solusinya sejalan dengan keenam pilar dari AWS Well-Architected
-
Keunggulan operasional - Pipa modular dan otomatis meningkatkan keunggulan operasional. Komponen utama dari pipa dipisahkan dan otomatis, memungkinkan pembaruan model yang lebih cepat dan pemantauan yang lebih mudah. Selain itu, jaringan pipa pelatihan otomatis mendukung rilis model yang disetel dengan lebih cepat.
-
Keamanan — Solusi ini memproses informasi yang sensitif dan dapat diidentifikasi secara pribadi (PII), seperti data dalam resume dan profil bakat. Dalam AWS Identity and Access Management (IAM), terapkan kebijakan kontrol akses berbutir halus dan pastikan bahwa hanya personel yang berwenang yang memiliki akses ke data ini.
-
Keandalan — Penggunaan solusi Layanan AWS, seperti Neptunus, Amazon Bedrock, dan Service OpenSearch , yang memberikan toleransi kesalahan, ketersediaan tinggi, dan akses tanpa gangguan ke wawasan bahkan selama permintaan tinggi.
-
Efisiensi kinerja - Disesuaikan dalam basis data vektor LLMs Amazon Bedrock dan OpenSearch Service dirancang untuk memproses kumpulan data besar dengan cepat dan akurat untuk memberikan rekomendasi pembelajaran yang dipersonalisasi secara tepat waktu.
-
Optimalisasi biaya — Solusi ini menggunakan pendekatan RAG, yang mengurangi kebutuhan akan pra-pelatihan model yang berkelanjutan. Alih-alih menyempurnakan seluruh model berulang kali, sistem hanya menyempurnakan proses tertentu, seperti mengekstraksi informasi dari resume dan menyusun output. Ini menghasilkan penghematan biaya yang signifikan. Dengan meminimalkan frekuensi dan skala pelatihan model intensif sumber daya dan dengan menggunakan layanan pay-per-use cloud, organisasi kesehatan dapat mengoptimalkan biaya operasional mereka sambil mempertahankan kinerja tinggi.
-
Keberlanjutan — Solusi ini menggunakan layanan cloud-native yang dapat diskalakan yang mengalokasikan sumber daya komputasi secara dinamis. Ini mengurangi konsumsi energi dan dampak lingkungan sambil tetap mendukung inisiatif transformasi bakat berskala besar dan intensif data.
