Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Retriever untuk alur kerja RAG
Bagian ini menjelaskan cara membuat retriever. Anda dapat menggunakan solusi pencarian semantik yang dikelola sepenuhnya, seperti Amazon Kendra, atau Anda dapat membuat pencarian semantik kustom dengan menggunakan database vektor. AWS
Sebelum Anda meninjau opsi retriever, pastikan Anda memahami tiga langkah proses pencarian vektor:
-
Anda memisahkan dokumen yang perlu diindeks menjadi bagian-bagian yang lebih kecil. Ini disebut chunking.
-
Anda menggunakan proses yang disebut embedding
untuk mengubah setiap potongan menjadi vektor matematika. Kemudian, Anda mengindeks setiap vektor dalam database vektor. Pendekatan yang Anda gunakan untuk mengindeks dokumen memengaruhi kecepatan dan akurasi pencarian. Pendekatan pengindeksan tergantung pada database vektor dan opsi konfigurasi yang disediakannya. -
Anda mengonversi kueri pengguna menjadi vektor dengan menggunakan proses yang sama. Retriever mencari database vektor untuk vektor yang mirip dengan vektor kueri pengguna. Kesamaan
dihitung dengan menggunakan metrik seperti jarak Euclidean, jarak kosinus, atau produk titik.
Panduan ini menjelaskan cara menggunakan layanan berikut Layanan AWS atau pihak ketiga untuk membuat lapisan pengambilan kustom pada AWS:
Amazon Kendra
Amazon Kendra adalah layanan pencarian cerdas yang dikelola sepenuhnya yang menggunakan pemrosesan bahasa alami dan algoritme pembelajaran mesin canggih untuk mengembalikan jawaban spesifik atas pertanyaan penelusuran dari data Anda. Amazon Kendra membantu Anda secara langsung menyerap dokumen dari berbagai sumber dan menanyakan dokumen setelah berhasil disinkronkan. Proses sinkronisasi menciptakan infrastruktur yang diperlukan untuk membuat pencarian vektor pada dokumen yang dicerna. Oleh karena itu, Amazon Kendra tidak memerlukan tiga langkah tradisional dari proses pencarian vektor. Setelah sinkronisasi awal, Anda dapat menggunakan jadwal yang ditentukan untuk menangani konsumsi yang sedang berlangsung.
Berikut ini adalah keuntungan menggunakan Amazon Kendra untuk RAG:
-
Anda tidak perlu memelihara database vektor karena Amazon Kendra menangani seluruh proses pencarian vektor.
-
Amazon Kendra berisi konektor bawaan untuk sumber data populer, seperti database, perayap situs web, bucket Amazon S3, instans, dan instance. Microsoft SharePoint Atlassian Confluence Konektor yang dikembangkan oleh AWS Mitra tersedia, seperti konektor untuk Box danGitLab.
-
Amazon Kendra menyediakan pemfilteran daftar kontrol akses (ACL) yang hanya mengembalikan dokumen yang dapat diakses pengguna akhir.
-
Amazon Kendra dapat meningkatkan respons berdasarkan metadata, seperti tanggal atau repositori sumber.
Gambar berikut menunjukkan contoh arsitektur yang menggunakan Amazon Kendra sebagai lapisan pengambilan sistem RAG. Untuk informasi selengkapnya, lihat Membangun aplikasi AI Generatif dengan akurasi tinggi dengan cepat pada data perusahaan menggunakan Amazon KendraLangChain,, dan model bahasa besar

Untuk model foundation, Anda dapat menggunakan Amazon Bedrock atau LLM yang digunakan melalui Amazon AI. SageMaker JumpStart Anda dapat menggunakan AWS Lambda with LangChain
OpenSearch Layanan Amazon
Amazon OpenSearch Service menyediakan algoritme HTML bawaan untuk penelusuran k-terdekat (k-NN) untuk melakukan pencarian
Berikut ini adalah keuntungan menggunakan OpenSearch Service untuk pencarian vektor:
-
Ini memberikan kontrol penuh atas database vektor, termasuk membangun pencarian vektor terukur dengan menggunakan OpenSearch Serverless.
-
Ini memberikan kontrol atas strategi chunking.
-
Ini menggunakan algoritma perkiraan tetangga terdekat (ANN) dari perpustakaan Non-Metric Space Library (NMSLIB)
, Faiss , dan Apache Lucene untuk menyalakan pencarian K-nn. Anda dapat mengubah algoritme berdasarkan kasus penggunaan. Untuk informasi selengkapnya tentang opsi untuk menyesuaikan pencarian vektor melalui OpenSearch Layanan, lihat kemampuan database vektor Amazon OpenSearch Service dijelaskan (posting AWS blog). -
OpenSearch Tanpa server terintegrasi dengan basis pengetahuan Amazon Bedrock sebagai indeks vektor.
Amazon Aurora PostgreSQL dan pgvector
Amazon Aurora PostgreSQL Compatible Edition adalah mesin database relasional terkelola sepenuhnya yang membantu Anda mengatur, mengoperasikan, dan menskalakan penerapan PostgreSQL. pgvector adalah ekstensi
Berikut ini adalah keuntungan menggunakan pgvector dan Aurora PostgreSQL kompatibel:
-
Ini mendukung pencarian tetangga terdekat yang tepat dan perkiraan. Ini juga mendukung metrik kesamaan berikut: jarak L2, produk dalam, dan jarak kosinus.
-
Ini mendukung Inverted File dengan Flat Compression (IVFFlat)
dan Hierarchical Navigable Small Worlds ( HNSW) pengindeksan. -
Anda dapat menggabungkan pencarian vektor dengan kueri atas data spesifik domain yang tersedia dalam instance PostgreSQL yang sama.
-
Aurora PostgreSQL kompatibel dioptimalkan untuk dan menyediakan caching berjenjang. I/O Untuk beban kerja yang melebihi memori instans yang tersedia, pgvector dapat meningkatkan kueri per detik untuk pencarian vektor hingga 8 kali.
Analisis Amazon Neptunus
Amazon Neptune Analytics adalah mesin database grafik yang dioptimalkan untuk memori untuk analitik. Ini mendukung perpustakaan algoritma analitik grafik yang dioptimalkan, kueri grafik latensi rendah, dan kemampuan pencarian vektor dalam traversal grafik. Ini juga memiliki pencarian kesamaan vektor bawaan. Ini menyediakan satu titik akhir untuk membuat grafik, memuat data, memanggil kueri, dan melakukan pencarian kesamaan vektor. Untuk informasi selengkapnya tentang cara membangun sistem berbasis RAG yang menggunakan Neptunus Analytics, lihat Menggunakan grafik pengetahuan untuk membangun aplikasi GraphRag dengan Amazon Bedrock dan Amazon
Berikut ini adalah keuntungan menggunakan Neptune Analytics:
-
Anda dapat menyimpan dan mencari embeddings dalam kueri grafik.
-
Jika Anda mengintegrasikan Neptunus Analytics LangChain dengan, arsitektur ini mendukung kueri grafik bahasa alami.
-
Arsitektur ini menyimpan dataset grafik besar dalam memori.
Amazon MemoryDB
Amazon MemoryDB adalah layanan database dalam memori yang tahan lama yang memberikan kinerja sangat cepat. Semua data Anda disimpan dalam memori, yang mendukung pembacaan mikrodetik, latensi tulis milidetik satu digit, dan throughput tinggi. Pencarian vektor untuk MemoryDB memperluas fungsionalitas MemoryDB dan dapat digunakan bersama dengan fungsionalitas MemoryDB yang ada. Untuk informasi lebih lanjut, lihat Pertanyaan menjawab dengan LLM dan repositori RAG
Diagram berikut menunjukkan arsitektur sampel yang menggunakan MemoryDB sebagai database vektor.

Berikut ini adalah keuntungan menggunakan MemoryDB:
-
Ini mendukung algoritma pengindeksan Flat dan HNSW. Untuk informasi lebih lanjut, lihat Pencarian vektor untuk Amazon MemoryDB sekarang tersedia secara umum
di Blog Berita AWS -
Ini juga dapat bertindak sebagai memori penyangga untuk model pondasi. Ini berarti bahwa pertanyaan yang dijawab sebelumnya diambil dari buffer alih-alih melalui proses pengambilan dan pembuatan lagi. Diagram berikut menunjukkan proses ini.
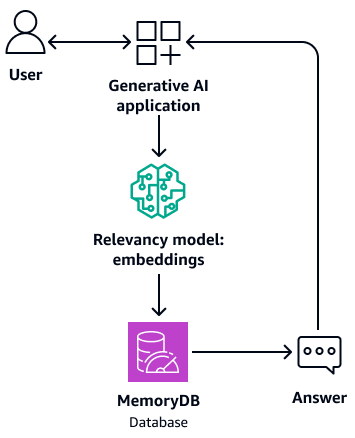
-
Karena menggunakan database dalam memori, arsitektur ini menyediakan waktu kueri milidetik satu digit untuk pencarian semantik.
-
Ini menyediakan hingga 33.000 kueri per detik pada penarikan 95-99% dan 26.500 kueri per detik dengan penarikan lebih dari 99%. Untuk informasi lebih lanjut, lihat AWS re:Invent 2023 - Pencarian vektor latensi ultra-rendah untuk
video Amazon MemoryDB aktif. YouTube
Amazon DocumentDB
Amazon DocumentDB (dengan kompatibilitas MongoDB) adalah layanan database yang cepat, andal, dan dikelola sepenuhnya. Ini membuatnya mudah untuk mengatur, mengoperasikan, dan menskalakan basis data MongoDB yang kompatibel di cloud. Pencarian vektor untuk Amazon DocumentDB menggabungkan fleksibilitas dan kemampuan query yang kaya dari database dokumen berbasis JSON dengan kekuatan pencarian vektor. Untuk informasi lebih lanjut, lihat Pertanyaan menjawab dengan LLM dan repositori RAG
Diagram berikut menunjukkan contoh arsitektur yang menggunakan Amazon DocumentDB sebagai database vektor.

Diagram menunjukkan alur kerja berikut:
-
Pengguna mengirimkan kueri ke aplikasi AI generatif.
-
Aplikasi AI generatif melakukan pencarian kesamaan di database vektor Amazon DocumentDB dan mengambil ekstrak dokumen yang relevan.
-
Aplikasi AI generatif memperbarui kueri pengguna dengan konteks yang diambil dan mengirimkan prompt ke model pondasi target.
-
Model dasar menggunakan konteks untuk menghasilkan respons terhadap pertanyaan pengguna dan mengembalikan respons.
-
Aplikasi AI generatif mengembalikan respons kepada pengguna.
Berikut ini adalah keuntungan menggunakan Amazon DocumentDB:
-
Ini mendukung metode HNSW dan IVFFlat pengindeksan.
-
Ini mendukung hingga 2.000 dimensi dalam data vektor dan mendukung metrik jarak produk Euclidean, cosinus, dan titik.
-
Ini memberikan waktu respons milidetik.
Pinecone
Pinecone
Diagram berikut menunjukkan arsitektur sampel yang menggunakan Pinecone sebagai database vektor.

Diagram menunjukkan alur kerja berikut:
-
Pengguna mengirimkan kueri ke aplikasi AI generatif.
-
Aplikasi AI generatif melakukan pencarian kesamaan dalam database Pinecone vektor dan mengambil ekstrak dokumen yang relevan.
-
Aplikasi AI generatif memperbarui kueri pengguna dengan konteks yang diambil dan mengirimkan prompt ke model pondasi target.
-
Model dasar menggunakan konteks untuk menghasilkan respons terhadap pertanyaan pengguna dan mengembalikan respons.
-
Aplikasi AI generatif mengembalikan respons kepada pengguna.
Berikut ini adalah keuntungan menggunakanPinecone:
-
Ini adalah database vektor yang dikelola sepenuhnya dan menghilangkan biaya pengelolaan infrastruktur Anda sendiri.
-
Ini menyediakan fitur tambahan penyaringan, pembaruan indeks langsung, dan peningkatan kata kunci (pencarian hibrida).
MongoDB Atlas
MongoDB
Atlas
Untuk informasi selengkapnya tentang cara menggunakan pencarian MongoDB Atlas vektor untuk RAG, lihat Retrieval-Augmented Generation with, LangChain Amazon SageMaker AI JumpStart, dan MongoDB Atlas Semantic Search

Berikut ini adalah keuntungan menggunakan pencarian MongoDB Atlas vektor:
-
Anda dapat menggunakan implementasi yang ada MongoDB Atlas untuk menyimpan dan mencari embeddings vektor.
-
Anda dapat menggunakan MongoDBQuery API
untuk menanyakan embeddings vektor. -
Anda dapat secara mandiri menskalakan pencarian vektor dan database.
-
Penyematan vektor disimpan di dekat data sumber (dokumen), yang meningkatkan kinerja pengindeksan.
Weaviate
Weaviate
Berikut ini adalah keuntungan menggunakanWeaviate:
-
Ini adalah open source dan didukung oleh komunitas yang kuat.
-
Itu dibangun untuk pencarian hibrida (baik vektor dan kata kunci).
-
Anda dapat menerapkannya sebagai penawaran perangkat lunak terkelola AWS sebagai layanan (SaaS) atau sebagai klaster Kubernetes.
