Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Arsitektur
Diagram berikut menggambarkan arsitektur solusi yang dijelaskan dalam panduan ini. AWS Glue Pekerjaan membaca data dari bucket Amazon Simple Storage Service (Amazon S3), yang merupakan layanan penyimpanan objek berbasis cloud yang membantu Anda menyimpan, melindungi, dan mengambil data. Anda dapat memulai AWS Glue Spark SQL pekerjaan melalui AWS Management Console, AWS Command Line Interface (AWS CLI), atau AWS Glue API. The AWS Glue Spark SQL job memproses data mentah dalam bucket Amazon S3 dan kemudian menyimpan data yang diproses dalam bucket yang berbeda.
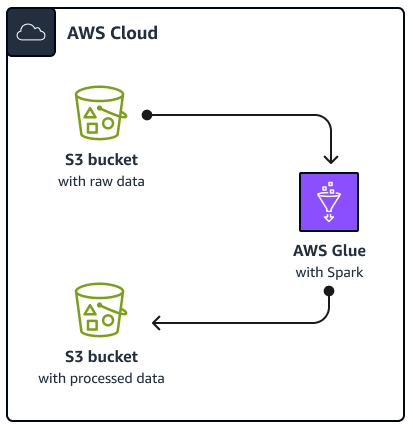
Misalnya tujuan, panduan ini menjelaskan dasar AWS GlueSpark SQL pekerjaan, yang ditulis dalam Python and Spark SQL (PySpark). AWS Glue Pekerjaan ini digunakan untuk menunjukkan praktik terbaik untuk Spark SQL penyetelan. Meskipun panduan ini berfokus pada AWS Glue, praktik terbaik dalam panduan ini juga berlaku untuk Amazon EMR Spark SQL pekerjaan.
Diagram berikut menggambarkan siklus hidup Spark SQL kueri. Bagian Spark SQL Catalyst Optimizer menghasilkan rencana kueri. Query plan adalah serangkaian langkah, seperti instruksi, yang digunakan untuk mengakses data dalam sistem database relasional SQL. Untuk mengembangkan kinerja yang dioptimalkan Spark
SQL rencana kueri, langkah pertama adalah melihat EXPLAIN rencana, menafsirkan rencana, dan kemudian menyetel rencana. Anda dapat menggunakan Spark SQL antarmuka pengguna (UI) atau Spark SQL Server Sejarah untuk memvisualisasikan rencana.
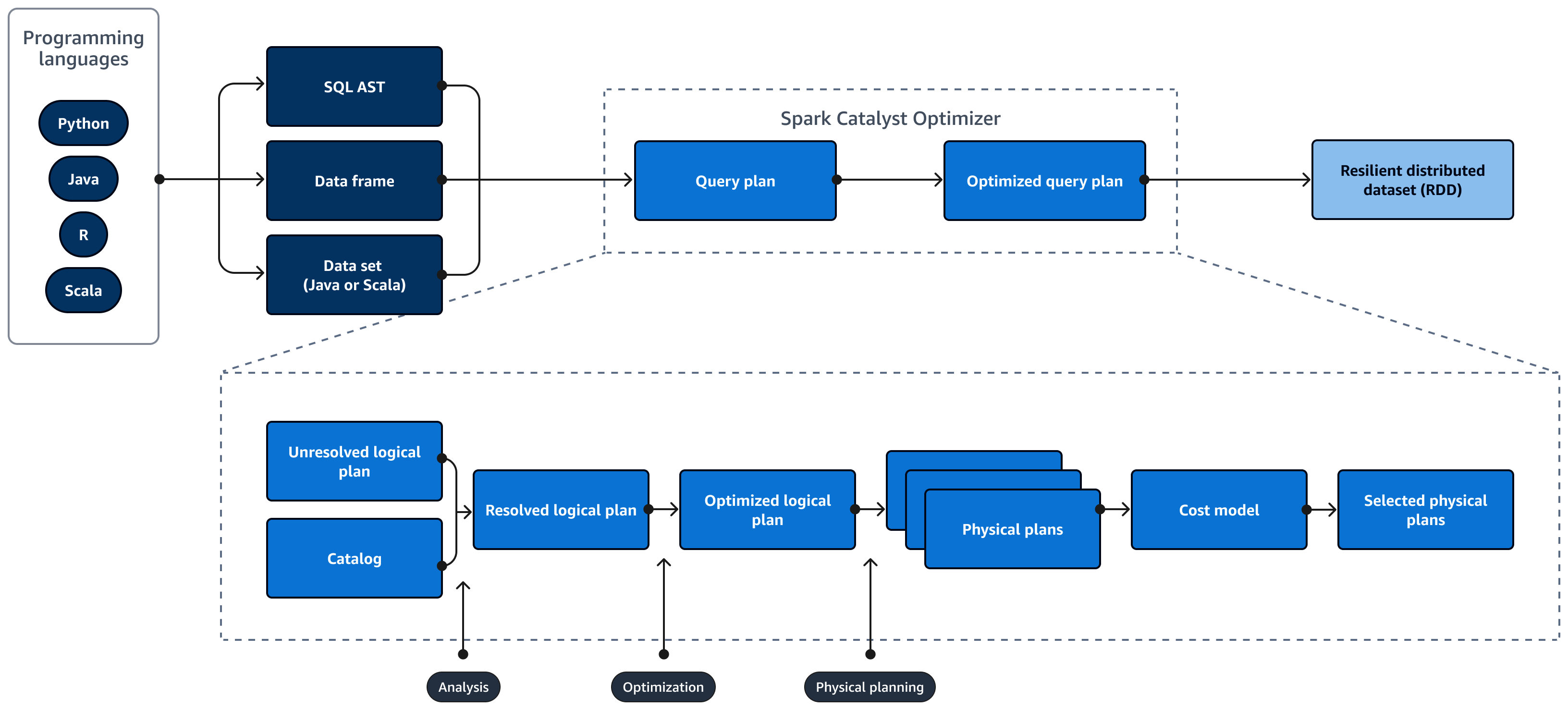
Spark Catalyst Optimizer mengubah rencana kueri awal menjadi rencana kueri yang dioptimalkan sebagai berikut:
-
Analisis dan deklaratif APIs — Fase analisis adalah langkah pertama. Rencana logis yang belum terselesaikan, di mana objek yang direferensikan dalam kueri SQL tidak diketahui atau tidak cocok dengan tabel input, dihasilkan dengan atribut dan tipe data yang tidak terikat. Bagian Spark SQL Catalyst Optimizer kemudian menerapkan seperangkat aturan untuk membangun rencana logis. Parser SQL dapat menghasilkan SQL Abstract Syntax Tree (AST) dan memberikan ini sebagai masukan untuk rencana logis. Input mungkin juga berupa bingkai data atau objek dataset yang dibangun dengan menggunakan API. Tabel berikut menunjukkan kapan Anda harus menggunakan SQL, frame data, atau dataset.
SQL Bingkai data Set Data Kesalahan sintaks Waktu Aktif Waktu kompilasi Waktu kompilasi Kesalahan analisis Waktu Aktif Waktu Aktif Waktu kompilasi Untuk informasi lebih lanjut tentang jenis input, tinjau hal-hal berikut:
-
API dataset menyediakan versi yang diketik. Ini mengurangi kinerja karena ketergantungan yang besar pada fungsi lambda yang ditentukan pengguna. RDD atau dataset diketik secara statis. Misalnya, ketika Anda mendefinisikan RDD, Anda perlu secara eksplisit memberikan definisi skema.
-
API bingkai data menyediakan operasi relasional yang tidak diketik. Bingkai data diketik secara dinamis. Mirip dengan RDD, ketika Anda menentukan bingkai data, skema tetap sama. Data masih terstruktur. Namun, informasi ini hanya tersedia saat runtime. Hal ini memungkinkan compiler untuk menulis pernyataan seperti SQL dan mendefinisikan kolom baru dengan cepat. Misalnya, dapat menambahkan kolom ke bingkai data yang ada tanpa perlu mendefinisikan kelas baru untuk setiap operasi.
-
A Spark SQL kueri dievaluasi untuk kesalahan sintaks dan analisis selama runtime, yang menyediakan runtime lebih cepat.
-
-
Katalog -Spark SQL menggunakan Apache Hive Metastore (HMS) untuk mengelola metadata entitas relasional persisten, seperti database, tabel, kolom, dan partisi.
-
Optimisasi — Pengoptimal menulis ulang rencana kueri dengan menggunakan heuristik dan biaya. Ini melakukan hal berikut untuk menghasilkan rencana logis yang dioptimalkan:
-
Kolom plum
-
Mendorong predikat ke bawah
-
Penataan ulang bergabung
-
-
Rencana fisik dan perencana — Spark SQL Catalyst Optimizer mengubah rencana logis menjadi satu set rencana fisik. Ini berarti mengubah apa menjadi bagaimana.
-
Rencana fisik yang dipilih - Spark SQL Catalyst Optimizer memilih rencana fisik yang paling hemat biaya.
-
Rencana kueri yang dioptimalkan - Spark SQL menjalankan rencana kueri yang dioptimalkan kinerja dan dioptimalkan biaya. Spark SQL Manajemen Memori melacak penggunaan memori dan mendistribusikan memori antara tugas dan operator. Bagian Spark SQL Mesin Tungsten secara substansif dapat meningkatkan memori dan efisiensi CPU untuk Spark SQL aplikasi. Ini juga mengimplementasikan pemrosesan model data biner, dan beroperasi langsung pada data biner. Ini melewati kebutuhan deserialisasi dan secara signifikan mengurangi overhead yang terkait dengan konversi data dan deserialisasi.
