Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Ikhtisar solusi
Kerangka kerja ML yang dapat diskalakan
Dalam bisnis dengan jutaan pelanggan yang tersebar di berbagai lini bisnis, alur kerja ML memerlukan integrasi data yang dimiliki dan dikelola oleh tim siloed menggunakan alat yang berbeda untuk membuka nilai bisnis. Bank berkomitmen untuk melindungi data nasabah mereka. Demikian pula, infrastruktur yang digunakan untuk pengembangan model ML juga tunduk pada standar keamanan yang tinggi. Keamanan tambahan ini menambah kompleksitas lebih lanjut dan berdampak pada waktu untuk menilai model ML baru. Dalam kerangka kerja ML yang dapat diskalakan, Anda dapat menggunakan toolset standar yang dimodernisasi untuk mengurangi upaya yang diperlukan untuk menggabungkan berbagai alat dan menyederhanakan proses untuk model ML baru. route-to-live
Secara tradisional, manajemen dan dukungan kegiatan ilmu data di industri FS dikendalikan oleh tim platform pusat yang mengumpulkan persyaratan, menyediakan sumber daya, dan memelihara infrastruktur untuk tim data di seluruh organisasi. Untuk meningkatkan skala penggunaan ML dalam tim federasi di seluruh organisasi, Anda dapat menggunakan kerangka kerja ML yang dapat diskalakan untuk menyediakan kemampuan swalayan bagi pengembang model dan jaringan pipa baru. Hal ini memungkinkan pengembang ini untuk menyebarkan infrastruktur modern, pra-disetujui, standar, dan aman. Pada akhirnya, kemampuan swalayan ini mengurangi ketergantungan organisasi Anda pada tim platform terpusat dan mempercepat waktu untuk menilai pengembangan model ML.
Kerangka kerja ML yang dapat diskalakan memungkinkan konsumen data (misalnya, ilmuwan data atau insinyur ML) untuk membuka nilai bisnis dengan memberi mereka kemampuan untuk melakukan hal berikut:
Jelajahi dan temukan data yang telah disetujui sebelumnya yang diperlukan untuk pelatihan model
Dapatkan akses ke data yang disetujui sebelumnya dengan cepat dan mudah
Gunakan data yang telah disetujui sebelumnya untuk membuktikan kelayakan model
Lepaskan model yang telah terbukti ke produksi untuk digunakan orang lain
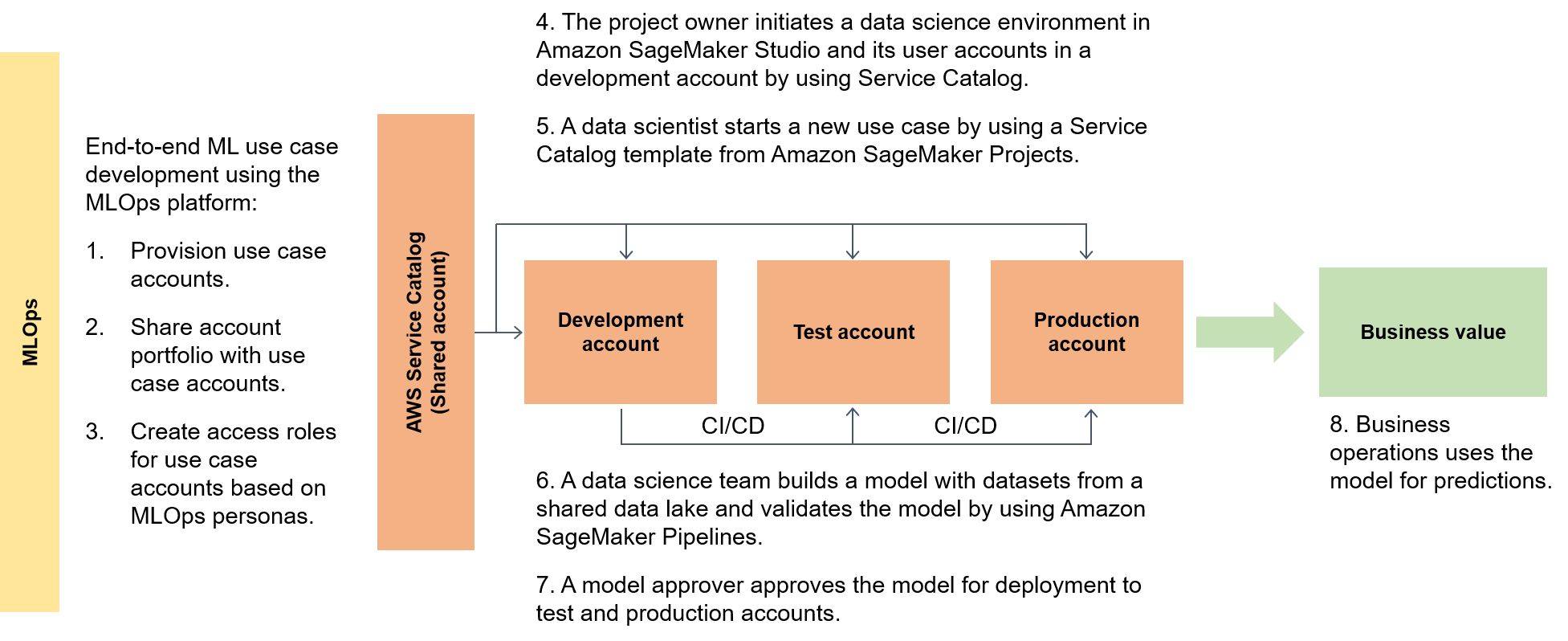
Diagram berikut menyoroti end-to-end alur kerangka kerja dan rute yang disederhanakan untuk hidup untuk kasus penggunaan ML.
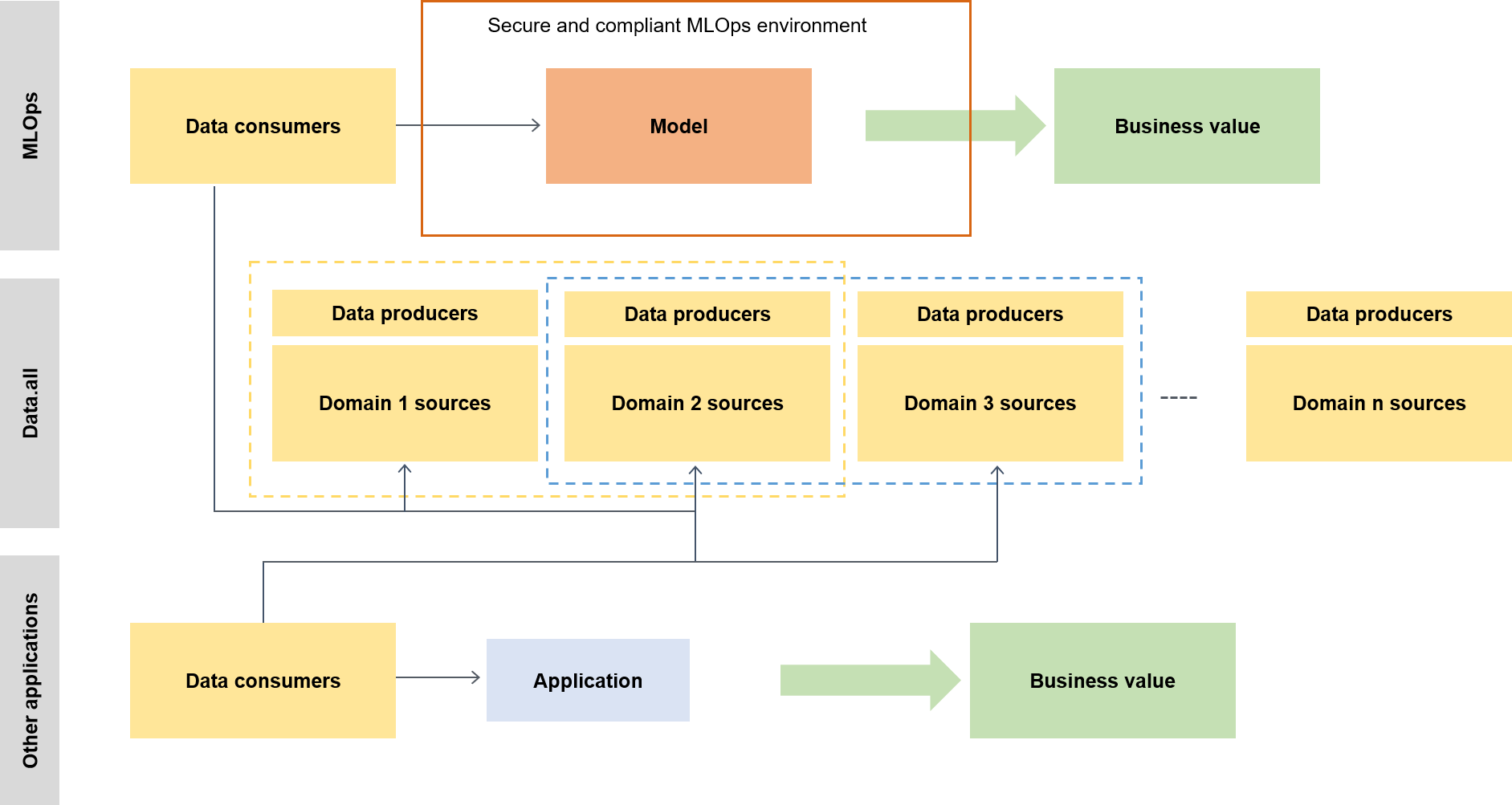
Dalam konteks yang lebih luas, konsumen data menggunakan akselerator tanpa server yang disebut data.all untuk sumber data di beberapa danau data dan kemudian menggunakan data untuk melatih model mereka, seperti yang diilustrasikan oleh diagram berikut.
Pada tingkat yang lebih rendah, kerangka kerja ML yang dapat diskalakan berisi yang berikut:
Penyebaran infrastruktur swalayan — Kurangi ketergantungan Anda pada tim terpusat.
Sistem manajemen paket Python Pusat - Buat paket Python yang telah disetujui sebelumnya tersedia untuk pengembangan model.
Pipa CI/CD untuk pengembangan dan promosi model - Kurangi waktu untuk hidup dengan memasukkan integrasi berkelanjutan dan jaringan pipa berkelanjutan (CI/CD) sebagai bagian dari templat infrastruktur Anda sebagai kode (IAc).
Kemampuan pengujian model — Manfaatkan pengujian unit, pengujian model, pengujian integrasi, dan fungsi end-to-end pengujian yang secara otomatis tersedia untuk model baru.
Model decoupling dan orkestrasi — Hindari komputasi yang tidak perlu dan buat penerapan Anda lebih kuat dengan memisahkan langkah-langkah model sesuai dengan persyaratan sumber daya komputasi dan orkestrasi berbagai langkah dengan menggunakan Amazon AI Pipelines. SageMaker
Standarisasi kode — Tingkatkan kualitas kode Anda dengan menggunakan integrasi CI/CD pipeline untuk memvalidasi standar Python Enhancement Proposal
(PEP 8). Pemantauan kualitas data dan model — Pastikan model Anda sesuai dengan persyaratan operasional dan dalam tingkat toleransi risiko Anda dengan menggunakan Amazon SageMaker AI Model Monitor untuk memantau penyimpangan data dan kualitas model Anda secara otomatis.
Pemantauan bias — Memungkinkan pemilik model Anda untuk membuat keputusan yang adil dan adil dengan secara otomatis memeriksa ketidakseimbangan data dan jika perubahan di dunia telah menimbulkan bias pada model Anda.
Hub pusat untuk metadata
Data.all
SageMaker validasi
Untuk membuktikan kemampuan SageMaker AI di berbagai pemrosesan data dan arsitektur ML, tim yang menerapkan kemampuan memilih, bersama dengan tim kepemimpinan perbankan, menggunakan kasus dengan kompleksitas yang bervariasi dari berbagai divisi pelanggan perbankan. Data kasus penggunaan dikaburkan dan tersedia di bucket data Amazon Simple Storage Service (Amazon
Saat migrasi model dari lingkungan pelatihan asli ke arsitektur SageMaker AI selesai, data lake yang dihosting cloud akan membuat data tersedia untuk dibaca oleh model produksi. Prediksi yang dihasilkan oleh model produksi kemudian ditulis kembali ke danau data.
Setelah kasus penggunaan kandidat dimigrasikan, kerangka kerja HTML yang dapat diskalakan mengambil garis dasar awal untuk metrik target. Anda dapat membandingkan baseline dengan pengaturan waktu lokal sebelumnya atau penyedia cloud lainnya sebagai bukti peningkatan waktu yang diaktifkan oleh kerangka kerja MS yang dapat diskalakan.
