Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Mendeteksi objek dan konsep
Bagian ini memberikan informasi untuk mendeteksi label dalam citra dan video dengan Amazon Rekognition Image dan Amazon Rekognition Video.
Label atau tag adalah objek atau konsep (termasuk adegan dan tindakan) yang ditemukan dalam gambar atau video berdasarkan isinya. Misalnya, gambar orang di pantai tropis mungkin berisi label seperti Pohon Palem (objek), Pantai (adegan), Lari (aksi), dan Outdoor (konsep).
Label didukung oleh operasi deteksi label Rekognition
Untuk mengunduh daftar label dan kotak pembatas objek sebelumnya, klik di sini.
catatan
Amazon Rekognition membuat prediksi biner gender (pria, wanita, gadis, dll.) berdasarkan penampilan fisik seseorang dalam citra tertentu. Prediksi semacam ini tidak dirancang untuk mengategorikan identitas gender seseorang, dan Anda tidak seharusnya menggunakan Amazon Rekognition untuk membuat penentuan seperti itu. Misalnya, seorang aktor pria yang mengenakan wig berambut panjang serta anting-anting untuk suatu peran mungkin diprediksi sebagai perempuan.
Menggunakan Amazon Rekognition untuk membuat prediksi biner gender paling cocok untuk kasus penggunaan jika statistik distribusi gender agregat perlu dianalisis tanpa mengidentifikasi pengguna tertentu. Misalnya, persentase pengguna perempuan dibandingkan dengan laki-laki di platform media sosial.
Kami tidak menyarankan penggunaan prediksi biner gender untuk membuat keputusan yang memengaruhi hak, privasi, atau akses seseorang ke layanan.
Amazon Rekognition mengembalikan label dalam bahasa Inggris. Anda dapat menggunakan Amazon Translate
Diagram berikut menunjukkan urutan operasi panggilan, tergantung pada tujuan Anda untuk menggunakan Gambar Rekognition Amazon atau operasi Video Rekognition Amazon:
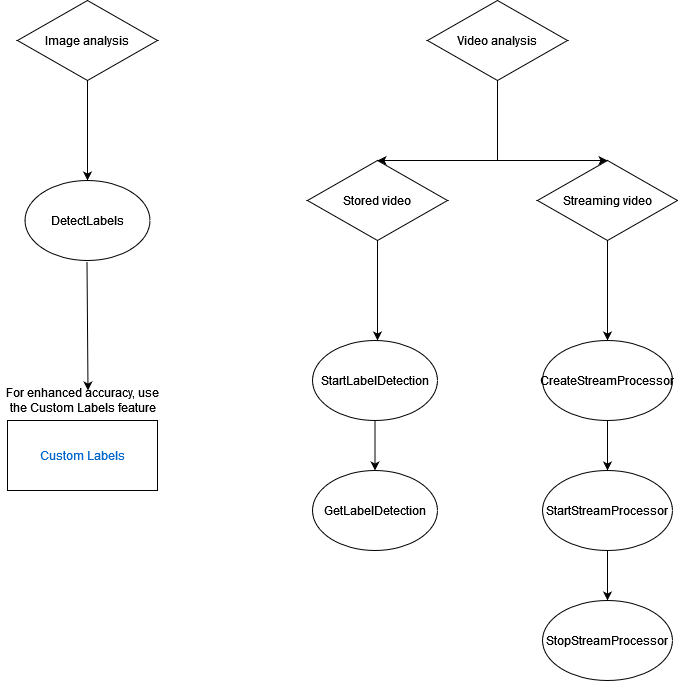
Objek Respons Label
Kotak Pembatas
Amazon Rekognition Image dan Amazon Rekognition Video dapat mengembalikan kotak pembatas untuk label objek umum seperti mobil, furnitur, pakaian atau hewan peliharaan. Informasi kotak pembatas tidak dikembalikan untuk label objek yang kurang lazim. Anda dapat menggunakan kotak pembatas untuk menemukan lokasi objek yang tepat dalam citra, menghitung instans objek yang terdeteksi, atau mengukur ukuran objek menggunakan dimensi kotak pembatas.
Misalnya, pada citra berikut, Amazon Rekognition Image mampu mendeteksi keberadaan seseorang, papan luncur, mobil yang terparkir dan informasi lainnya. Amazon Rekognition Image juga mengembalikan kotak pembatas untuk seseorang yang terdeteksi, dan benda-benda lain yang terdeteksi seperti mobil dan roda.

Skor Keyakinan
Video Rekognition Amazon dan Gambar Rekognition Amazon memberikan skor persentase untuk seberapa besar kepercayaan Amazon Rekognition terhadap keakuratan setiap label yang terdeteksi.
Induk
Amazon Rekognition Image dan Amazon Rekognition Video menggunakan taksonomi hierarkis label leluhur untuk mengategorikan label. Misalnya, seseorang yang berjalan di seberang jalan mungkin terdeteksi sebagai Pejalan Kaki. Label induk untuk Pejalan Kaki adalah Orang. Kedua label ini dikembalikan dalam respons. Semua label leluhur dikembalikan dan label yang diberikan berisi daftar induknya dan label leluhur lainnya. Misalnya, label kakek-nenek dan kakek-nenek buyut, jika ada. Anda dapat menggunakan label induk untuk membangun grup label terkait dan mengizinkan kueri label serupa dalam satu atau beberapa citra. Sebagai contoh, kueri untuk semua Kendaraan mungkin mengembalikan mobil dari satu citra dan sepeda motor dari citra lainya.
Kategori
Gambar Rekognition Amazon dan Video Rekognition Amazon mengembalikan informasi tentang kategori label. Label adalah bagian dari kategori yang mengelompokkan label individu berdasarkan fungsi dan konteks umum, seperti 'Kendaraan dan Otomotif' dan 'Makanan dan Minuman'. Kategori label dapat berupa subkategori dari kategori induk.
Alias
Selain mengembalikan label, Amazon Rekognition Image dan Amazon Rekognition Video mengembalikan alias apa pun yang terkait dengan label. Alias adalah label dengan arti atau label yang sama yang dapat dipertukarkan secara visual dengan label utama yang dikembalikan. Misalnya, 'Telepon Seluler' adalah alias 'Ponsel'.
Di versi sebelumnya, Amazon Rekognition Image mengembalikan alias seperti 'Ponsel' dalam daftar nama label utama yang sama yang berisi 'Ponsel'. Amazon Rekognition Image sekarang mengembalikan 'Ponsel' di bidang yang disebut “alias” dan 'Ponsel' dalam daftar nama label utama. Jika aplikasi Anda bergantung pada struktur yang dikembalikan oleh Rekognition versi sebelumnya, Anda mungkin perlu mengubah respons saat ini yang dikembalikan oleh operasi deteksi label gambar atau video ke dalam struktur respons sebelumnya, di mana semua label dan alias dikembalikan sebagai label utama.
Jika Anda perlu mengubah respons saat ini dari DetectLabels API (untuk deteksi label dalam gambar) menjadi struktur respons sebelumnya, lihat contoh kode diMengubah respon DetectLabels.
Jika Anda perlu mengubah respons saat ini dari GetLabelDetection API (untuk deteksi label dalam video yang disimpan) ke dalam struktur respons sebelumnya, lihat contoh kode diMengubah Respon GetLabelDetection .
Properti Gambar
Amazon Rekognition Image mengembalikan informasi tentang kualitas gambar (ketajaman, kecerahan, dan kontras) untuk seluruh gambar. Ketajaman dan kecerahan juga dikembalikan untuk latar depan dan latar belakang gambar. Image Properties juga dapat digunakan untuk mendeteksi warna dominan dari seluruh gambar, latar depan, latar belakang, dan objek dengan kotak pembatas.

Berikut ini adalah contoh ImageProperties data yang terkandung dalam respons DetectLabels operasi untuk gambar yang sedang berlangsung:
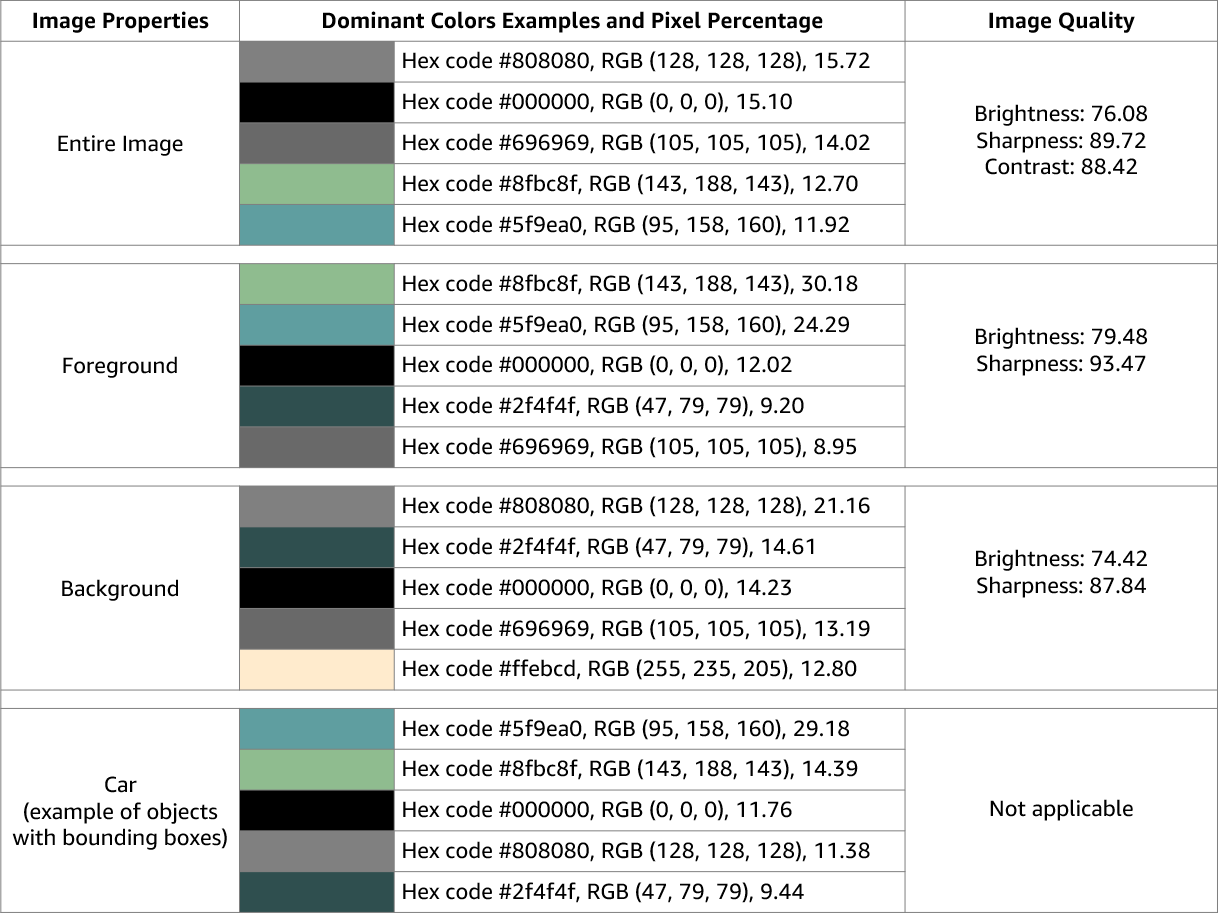
Properti Gambar tidak tersedia untuk Amazon Rekognition Video.
Versi Model
Amazon Rekognition Image dan Amazon Rekognition Video mengembalikan versi model deteksi label yang digunakan untuk mendeteksi label dalam citra atau video yang disimpan.
Filter Inklusi dan Pengecualian
Anda dapat memfilter hasil yang ditampilkan oleh Amazon Rekognition Image dan operasi deteksi label Amazon Rekognition Video. Filter hasil dengan memberikan kriteria filtrasi untuk label dan kategori. Filter label bisa inklusif atau eksklusif.
Lihat Mendeteksi label dalam citra untuk informasi lebih lanjut mengenai penyaringan hasil yang diperoleh denganDetectLabels.
Lihat Mendeteksi label dalam video untuk informasi lebih lanjut mengenai penyaringan hasil yang diperoleh olehGetLabelDetection.
Menyortir dan Mengagregasikan Hasil
Hasil yang diperoleh dari operasi Video Rekognition Amazon tertentu dapat diurutkan dan dikumpulkan menurut stempel waktu dan segmen video. Saat mengambil hasil pekerjaan Deteksi Label atau Moderasi Konten, dengan GetLabelDetection atau GetContentModeration masing-masing, Anda dapat menggunakan AggregateBy argumen SortBy dan untuk menentukan bagaimana Anda ingin hasil Anda dikembalikan. Anda dapat menggunakan SortBy dengan TIMESTAMP atau NAME (nama Label), dan menggunakan TIMESTAMPS atau SEGMENTS dengan AggregateBy argumen.
