REL09-BP04 Melakukan pemulihan data secara berkala untuk memverifikasi integritas dan proses pencadangan
Validasikan bahwa implementasi proses pencadangan Anda memenuhi Sasaran Waktu Pemulihan (RTO) dan Sasaran Titik Pemulihan (RPO) dengan melakukan uji pemulihan.
Hasil yang Diinginkan: Data dari cadangan dipulihkan secara berkala dengan menggunakan mekanisme yang ditentukan dengan baik untuk memverifikasi bahwa pemulihan tersebut dapat dilakukan dalam sasaran waktu pemulihan (RTO) yang ditetapkan untuk beban kerja. Pastikan bahwa pemulihan dari pencadangan menghasilkan sumber daya yang berisi data asli tanpa ada data yang rusak atau tidak dapat diakses, serta dengan kehilangan data dalam sasaran titik pemulihan (RPO).
Anti-pola umum:
-
Memulihkan cadangan, tetapi tidak mengambil data atau membuat kueri data apa pun untuk memastikan bahwa data hasil pemulihan dapat digunakan.
-
Dengan anggapan bahwa cadangan sudah ada.
-
Dengan anggapan bahwa cadangan sistem dapat dioperasikan sepenuhnya dan data dapat dipulihkan dari sistem.
-
Dengan anggapan bahwa waktu untuk memulihkan data dari cadangan termasuk dalam RTO untuk beban kerja.
-
Dengan anggapan bahwa data dalam cadangan termasuk dalam RPO untuk beban kerja
-
Melakukan pemulihan apabila diperlukan, tanpa menggunakan runbook, atau di luar prosedur otomatis yang ditetapkan.
Manfaat menerapkan praktik terbaik ini: Pengujian pemulihan cadangan akan memverifikasi bahwa data dapat dipulihkan saat dibutuhkan tanpa perlu khawatir data akan hilang atau rusak, bahwa pemulihan dapat dilakukan dalam RTO untuk beban kerja, dan kehilangan data apa pun masih termasuk dalam RPO untuk beban kerja.
Tingkat risiko yang terjadi jika praktik terbaik ini tidak diterapkan: Sedang
Panduan implementasi
Pengujian kemampuan pencadangan dan pemulihan akan meningkatkan keyakinan Anda pada kemampuan untuk menjalankan tindakan ini selama terjadi pemadaman (outage). Pulihkan cadangan ke lokasi baru secara berkala dan lakukan pengujian untuk memastikan integritas data. Beberapa pengujian umum yang harus dilakukan adalah memeriksa apakah semua data tersedia, tidak mengalami kerusakan, dapat diakses, dan setiap kehilangan data masih termasuk dalam RPO untuk beban kerja. Pengujian tersebut dapat juga membantu memastikan apakah mekanisme pemulihan cukup cepat untuk mengakomodasi RTO beban kerja.
Dengan menggunakan AWS, Anda dapat mempertahankan lingkungan pengujian dan memulihkan cadangan Anda untuk menilai kemampuan RTO dan RPO, serta menjalankan pengujian pada konten dan integritas data.
Selain itu, Amazon RDS dan Amazon DynamoDB dapat memungkinkan pemulihan titik waktu (PITR). Dengan menggunakan pencadangan yang berkelanjutan, Anda dapat memulihkan set data ke statusnya sesuai dengan waktu dan tanggal yang ditentukan.
Jika semua data tersedia, tidak mengalami kerusakan, dapat diakses, dan kehilangan data apa pun masih termasuk dalam RPO untuk beban kerja. Pengujian tersebut dapat juga membantu memastikan apakah mekanisme pemulihan cukup cepat untuk mengakomodasi RTO beban kerja.
AWS Elastic Disaster Recovery menawarkan snapshot pemulihan titik waktu volume Amazon EBS secara berkelanjutan. Saat server sumber direplikasi, status point-in-time dicatat dari waktu ke waktu berdasarkan kebijakan yang dikonfigurasi. Pemulihan Bencana Elastis dapat membantu Anda untuk memverifikasi integritas snapshot ini dengan meluncurkan instans untuk tujuan pengujian dan latihan tanpa mengarahkan lalu lintas.
Langkah-langkah implementasi
-
Identifikasi sumber data yang dicadangkan saat ini dan lokasi penyimpanan cadangan tersebut. Untuk panduan implementasi, lihat REL09-BP01 Mengidentifikasi dan mencadangkan data yang perlu dicadangkan, atau melakukan reproduksi ulang data dari sumber.
-
Menetapkan kriteria untuk validasi data untuk masing-masing sumber data. Jenis data yang berbeda akan memiliki properti data yang berbeda, yang dapat memerlukan mekanisme validasi yang berbeda. Pertimbangkan bagaimana data ini dapat divalidasi sebelum Anda yakin untuk menggunakannya dalam produksi. Beberapa cara umum untuk memvalidasi data adalah dengan menggunakan data dan properti pencadangan seperti jenis data, format, checksum, ukuran, atau gabungan darinya dengan logika validasi kustom. Misalnya, hal ini dapat dilakukan dengan perbandingan nilai checksum antara sumber daya yang dipulihkan dan sumber data pada waktu cadangan dibuat.
-
Menetapkan RTO dan RPO untuk memulihkan data berdasarkan tingkat kekritisan data. Untuk panduan implementasi, lihat REL13-BP01 Menetapkan sasaran pemulihan untuk waktu henti dan kehilangan data.
-
Menilai kemampuan pemulihan Anda. Tinjau strategi pencadangan dan pemulihan untuk memahami apakah hal tersebut memenuhi RTO dan RPO, serta sesuaikan strategi sesuai keperluan. Dengan menggunakan AWS Resilience Hub, Anda dapat menjalankan penilaian terhadap beban kerja Anda. Penilaian tersebut mengevaluasi konfigurasi aplikasi terhadap kebijakan dan pelaporan ketahanan jika target RTO dan RPO dapat dipenuhi.
-
Lakukan penyimpanan kembali pengujian dengan menggunakan proses yang ditetapkan saat ini yang digunakan dalam produksi untuk pemulihan data. Proses ini bergantung pada cara sumber data asli dicadangkan, format dan lokasi penyimpanan cadangan tersebut, atau apakah data diproduksi ulang dari sumber-sumber lainnya. Misalnya, jika Anda menggunakan sebuah layanan terkelola seperti AWS Backup, hal ini mungkin sesederhana memulihkan cadangan ke sumber daya baru. Jika Anda menggunakan AWS Elastic Disaster Recovery, maka Anda dapat meluncurkan latihan pemulihan.
-
Validasi pemulihan data dari sumber daya yang dipulihkan berdasarkan kriteria validasi data yang sebelumnya Anda buat. Apakah data yang direstorasi dan dipulihkan memiliki sebagian besar catatan atau item terbaru pada waktu pencadangan? Apakah data ini masih termasuk dalam RPO untuk beban kerja?
-
Ukur waktu yang diperlukan untuk menyimpan kembali dan melakukan pemulihan dan kemudian bandingkan dengan RTO Anda yang sudah ditetapkan. Apakah data ini masih termasuk dalam RTO untuk beban kerja? Misalnya, bandingkan stempel waktu dari kapan proses restorasi dimulai dan kapan validasi pemulihan selesai untuk menghitung waktu yang diperlukan proses ini. Semua panggilan API AWS diberi stempel waktu dan informasi ini tersedia di AWS CloudTrail. Meskipun informasi ini dapat menyediakan detail waktu kapan proses pemulihan dimulai, namun stempel waktu akhir yang menunjukkan kapan validasi diselesaikan harus dicatat berdasarkan logika validasi Anda. Jika Anda menggunakan proses otomatis, maka layanan-layanan seperti Amazon DynamoDB
dapat digunakan untuk menyimpan informasi ini. Selain itu, banyak layanan AWS yang menyediakan riwayat peristiwa yang berisi informasi dengan yang dilengkapi stempel waktu tentang kapan tindakan-tindakan diambil. Dalam AWS Backup, tindakan pembuatan cadangan dan penyimpanan kembali disebut sebagai tugas, dan tugas tersebut berisi informasi stempel waktu sebagai bagian dari metadata yang dapat digunakan untuk mengukur waktu yang diperlukan untuk pemulihan. -
Berikan notifikasi untuk pemangku kepentingan jika validasi data gagal, atau jika waktu yang diperlukan untuk pemulihan melebihi RTO yang ditetapkan untuk beban kerja. Saat menerapkan otomatisasi untuk melakukan langkah ini, seperti di lab ini
, layanan-layanan seperti Amazon Simple Notification Service (Amazon SNS) dapat digunakan untuk mengirim pemberitahuan push seperti email atau SMS kepada para pemangku kepentingan. Pesan-pesan ini juga dapat dipublikasikan ke aplikasi perpesanan seperti Amazon Chime, Slack, atau Microsoft Teams atau digunakan untuk membuat tugas sebagai OpsItems dengan menggunakan AWS Systems Manager OpsCenter. -
Otomatiskan proses ini untuk menjalankannya secara berkala. Sebagai contoh, layanan-layanan seperti AWS Lambda atau State Machine di AWS Step Functions dapat digunakan untuk melakukan otomatisasi proses pemulihan, dan Amazon EventBridge dapat digunakan untuk menginvokasi alur kerja otomatisasi ini secara berkala seperti yang ditampilkan dalam diagram arsitektur di bawah ini. Pelajari cara Mengotomatiskan validasi pemulihan data dengan AWS Backup
. Selain itu, lab Well-Architected ini memberikan pengalaman langsung tentang satu cara untuk melakukan otomatisasi untuk beberapa langkah yang diuraikan di sini.
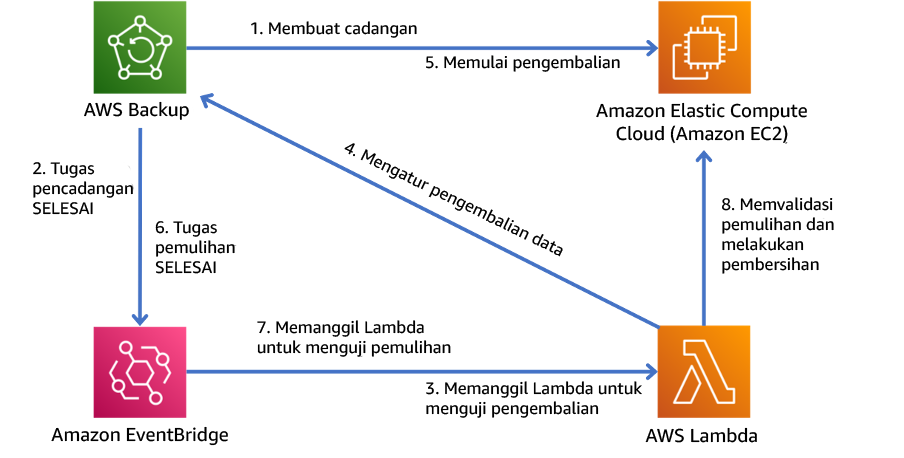
Gambar 9. Proses pencadangan dan pemulihan otomatis
Tingkat upaya untuk Rencana Implementasi: Sedang hingga tinggi tergantung pada kompleksitas kriteria validasinya.
Sumber daya
Dokumen terkait:
