Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Kontrol evakuasi yang dikendalikan pesawat
Pola pertama menggunakan operasi bidang data untuk mencegah melakukan pekerjaan di Availability Zone yang terkena dampak untuk mengurangi dampak suatu peristiwa. Namun, Anda mungkin menggunakan arsitektur yang tidak menggunakan penyeimbang muatan atau jika mengonfigurasi pemeriksaan kesehatan per host tidak layak dilakukan. Atau, Anda mungkin ingin mencegah kapasitas baru diterapkan ke Availability Zone yang terkena dampak melalui Penskalaan Otomatis atau penjadwalan pekerjaan normal.
Untuk mengatasi kedua situasi, tindakan bidang kontrol diperlukan untuk memperbarui konfigurasi sumber daya. Pola ini akan berfungsi untuk layanan apa pun yang konfigurasi jaringannya dapat diperbarui, misalnya, EC2 Auto Scaling, Amazon ECS, Lambda, dan lainnya. Ini membutuhkan kode penulisan untuk setiap layanan, tetapi logika bisnis mengikuti pola standar. Kode harus dijalankan secara lokal oleh operator menanggapi acara untuk meminimalkan dependensi yang diperlukan. Aliran dasar logika skrip ditunjukkan pada gambar berikut.
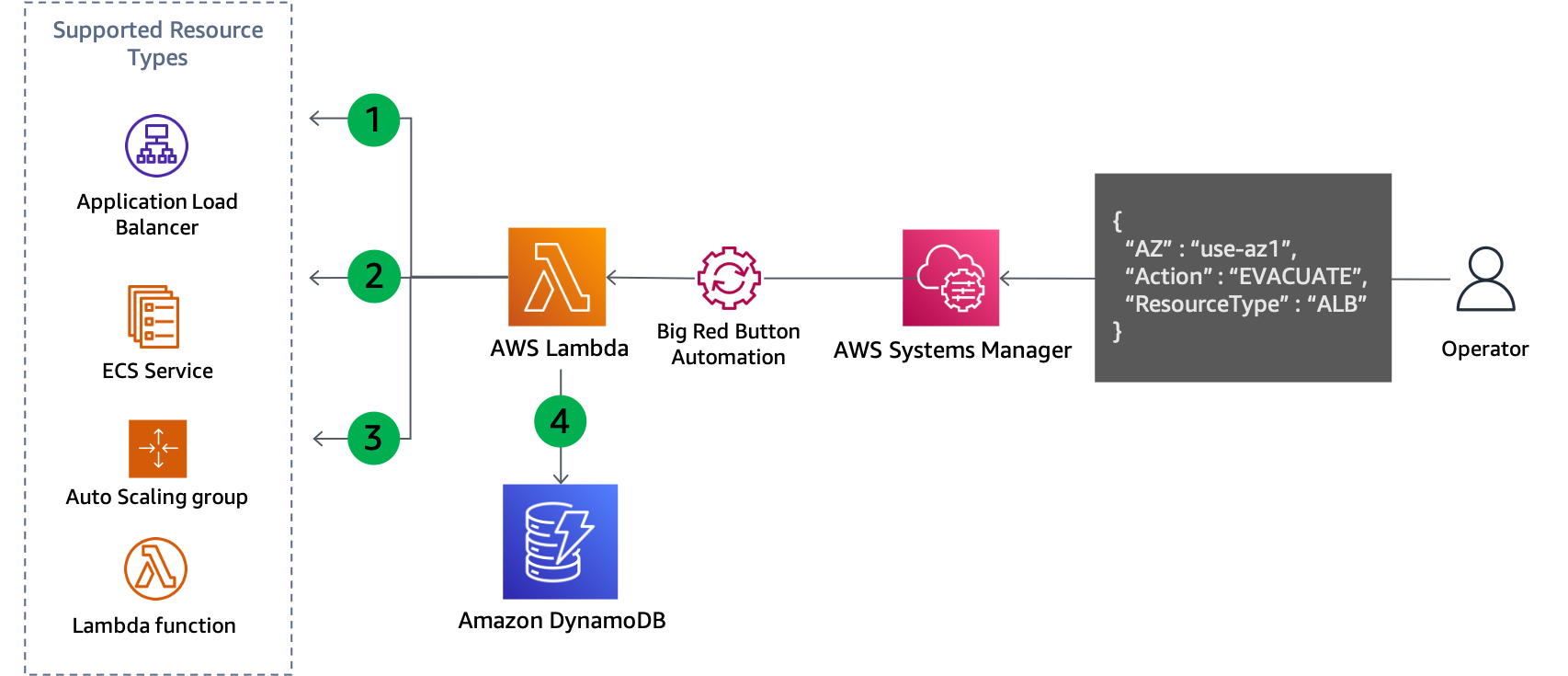
Kontrol pembaruan pesawat untuk mengevakuasi Availability Zone
-
Script mencantumkan semua sumber daya dari jenis yang ditentukan, seperti grup Auto Scaling, layanan ECS, atau fungsi Lambda, dan mengambil subnet mereka dari informasi sumber daya. Sumber daya yang didukung bergantung pada apa skrip telah dikonfigurasi untuk mendukung.
-
Ini menentukan subnet mana yang harus dihapus dengan membandingkan nama Availability Zone setiap subnet dengan ID Availability Zone yang dipetakan yang disediakan sebagai parameter input.
-
Konfigurasi jaringan sumber daya diperbarui untuk menghapus subnet yang diidentifikasi.
-
Rincian pembaruan dicatat dalam tabel DynamoDB. ID Availability Zone disimpan sebagaikunci partisidan ARN sumber daya atau nama disimpan sebagaimenyortir kunci. Subnet yang dihapus disimpan sebagai array string. Akhirnya, jenis sumber daya juga disimpan dan digunakan sebagai kunci hash untukIndeks Sekunder Global(GSI).
Karena langkah keempat mencatat pembaruan yang dibuat, pendekatan ini juga cocok untuk mudah dibalik ketika Anda siap untuk pulih, seperti yang ditunjukkan pada gambar berikut.
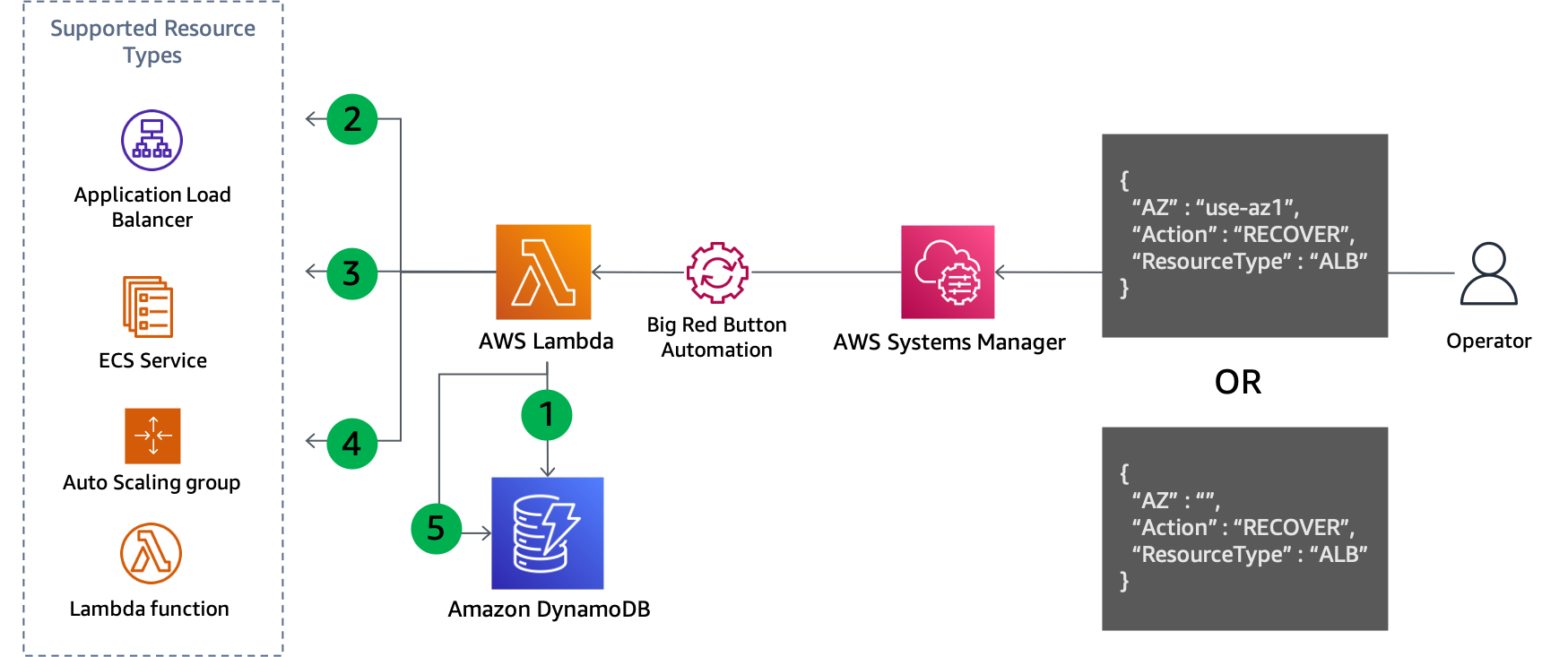
Kontrol pembaruan pesawat untuk pulih dari evakuasi Availability Zone
Langkah pemulihan:
-
Kueri GSI agar subnet dihapus untuk setiap sumber daya dari jenis yang ditentukan di Availability Zone yang ditentukan (atau semua Availability Zone jika tidak ditentukan).
-
Jelaskan setiap sumber daya yang ditemukan dalam kueri DynamoDB untuk mendapatkan konfigurasi jaringan saat ini.
-
Gabungkan subnet dari konfigurasi jaringan saat ini dengan yang diambil dari kueri DynamoDB.
-
Perbarui konfigurasi jaringan sumber daya dengan set subnet baru.
-
Hapus catatan dari tabel DynamoDB setelah pembaruan selesai dengan sukses.
Pola umum ini mencegah pekerjaan perutean ke Availability Zone yang terkena dampak dan mencegah kapasitas baru diterapkan di sana. Berikut ini adalah contoh bagaimana hal ini dicapai untuk layanan yang berbeda.
-
Lambda- Perbarui fungsiKonfigurasi VPCuntuk menghapus subnet di Availability Zone yang ditentukan.
-
Grup Penskalaan Otomatis—Hapus subnet dari konfigurasi ASGyang akan menggantikan kapasitas itu di Availability Zone yang tersisa.
-
Amazon ECS—Perbarui konfigurasi VPC layanan ECSuntuk menghapus subnet.
-
Amazon— Terapkannoda
ke node di Availability Zone yang terkena dampak untuk menggusur Pod yang ada dan mencegah Pod tambahan agar tidak dijadwalkan di sana.
Setiap layanan akan bereaksi berbeda terhadap pembaruan konfigurasi. Misalnya, Amazon ECS akan mengikutikonfigurasi penyebaran layanan setelah pembaruandan memicu penyebaran bergulir atau penyebaran biru/hijau tugas baru.
Pembaruan ini dapat mengalihkan pekerjaan ke Availability Zone yang sehat terlalu cepat untuk beberapa beban kerja. Saat dikonfigurasi agar stabil secara statis terhadap kegagalan (memiliki kapasitas yang cukup disediakan sebelumnya di Availability Zone yang tersisa untuk menangani pekerjaan Availability Zone yang terkena dampak), Anda mungkin juga ingin menghapus kapasitas secara bertahap dari Availability Zone yang terkena dampak.
Jika Anda berencana untuk memperbarui konfigurasi jaringan grup Auto Scaling yang merupakan grup target untuk penyeimbang muatan dengan penyeimbang muatan lintas zonadinonaktifkan, ikuti panduan ini.
Auto Scaling bereaksi terhadap perubahan ini menggunakanLogika penyeimbangan kembali Zona Ketersediaan. Ini akan meluncurkan instance di Availability Zone lain untuk memenuhi kapasitas yang Anda inginkan dan menghentikan instans di Availability Zone yang Anda hapus. Namun, load balancer akan terus membagi lalu lintas secara merata di setiap Availability Zone, termasuk yang Anda hapus dari ASG, sementara instans sedang dihentikan. Ini dapat menyebabkan kecoklatan dari kapasitas yang tersisa di Availability Zone tersebut hingga semua instance berhasil dihentikan di sana. Ini adalah masalah yang sama yang dijelaskan dalamIndependensi Zona Ketersediaantentang Ketidakseimbangan Zona Ketersediaan saat penyeimbangan beban lintas zona dinonaktifkan. Untuk mencegah hal ini terjadi, Anda dapat:
-
Selalu lakukan evakuasi Availability Zone Anda terlebih dahulu sehingga lalu lintas hanya dibagi di antara Availability Zone yang tersisa
-
Tentukanjumlah target sehat minimum dengan failover DNSuntuk mencocokkan jumlah target minimum yang diperlukan untuk Availability Zone tersebut.
Ini akan membantu memastikan lalu lintas tidak dikirim ke Availability Zone yang Anda hapus setelah instans mulai dihentikan.
