Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Evakuasi data yang dikendalikan pesawat
Ada beberapa solusi yang dapat Anda terapkan untuk melakukan evakuasi Availability Zone menggunakan tindakan khusus bidang data. Bagian ini akan menjelaskan tiga dari mereka dan kasus penggunaan di mana Anda mungkin ingin memilih satu dari yang lain.
Saat menggunakan salah satu solusi ini, Anda perlu memastikan bahwa Anda memiliki kapasitas yang cukup di Availability Zone yang tersisa untuk menangani beban Availability Zone tempat Anda beralih. Yang paling tangguh adalah melakukan ini adalah dengan memiliki kapasitas yang diperlukan pra-penyediaan di setiap Availability Zone. Jika Anda menggunakan tiga Availability Zone, Anda akan memiliki 50% dari kapasitas yang diperlukan untuk menangani beban puncak yang digunakan di masing-masing Availability Zone, sehingga hilangnya Availability Zone tunggal akan tetap membuat Anda 100% dari kapasitas yang diperlukan tanpa harus bergantung pada bidang kontrol untuk menyediakan lebih banyak.
Selain itu, jika Anda menggunakan EC2 Auto Scaling, pastikan grup Auto Scaling (ASG) Anda tidak menskalakan selama shift, sehingga ketika shift berakhir, Anda masih memiliki kapasitas yang cukup dalam grup untuk menangani lalu lintas pelanggan Anda. Anda dapat melakukan ini dengan memastikan bahwa kapasitas minimum yang diinginkan ASG Anda dapat menangani beban pelanggan Anda saat ini. Anda juga dapat membantu memastikan bahwa ASG Anda tidak secara tidak sengaja menskalakan dengan menggunakan rata-rata dalam metrik Anda dibandingkan dengan metrik persentil outlier seperti P90 atau P99.
Selama shift, sumber daya yang tidak lagi melayani lalu lintas harus memiliki pemanfaatan yang sangat rendah, tetapi sumber daya lainnya akan meningkatkan pemanfaatannya dengan lalu lintas baru, menjaga rata-rata cukup konsisten, yang akan mencegah tindakan skala. Akhirnya, Anda juga dapat menggunakan pengaturan kesehatan grup target untukALBdanNLBuntuk menentukan failover DNS dengan persentase atau jumlah host sehat. Ini mencegah lalu lintas dialihkan ke Availability Zone yang tidak memiliki cukup host sehat.
Zonal Shift di Route 53 Aplikasi Recovery Controller (ARC)
Solusi pertama untuk penggunaan evakuasi Availability Zonepergeseran zona di Route 53 ARC. Solusi ini dapat digunakan untuk beban kerja permintaan/respons yang menggunakan NLB atau ALB sebagai titik masuknya lalu lintas pelanggan.
Ketika Anda mendeteksi bahwa Availability Zone telah mengalami gangguan, Anda dapat memulai pergeseran zonal dengan Route 53 ARC. Setelah operasi ini selesai dan respons DNS cache yang ada kedaluwarsa, semua permintaan baru hanya dialihkan ke sumber daya di Availability Zone yang tersisa. Gambar berikut menunjukkan bagaimana pergeseran zonal bekerja. Pada gambar berikut kita memiliki Route 53 alias record untukwww.example.comyang menunjuk kemy-example-nlb-4e2d1f8bb2751e6a.elb.us-east-1.amazonaws.com. Pergeseran zonal dilakukan untuk Availability Zone 3.
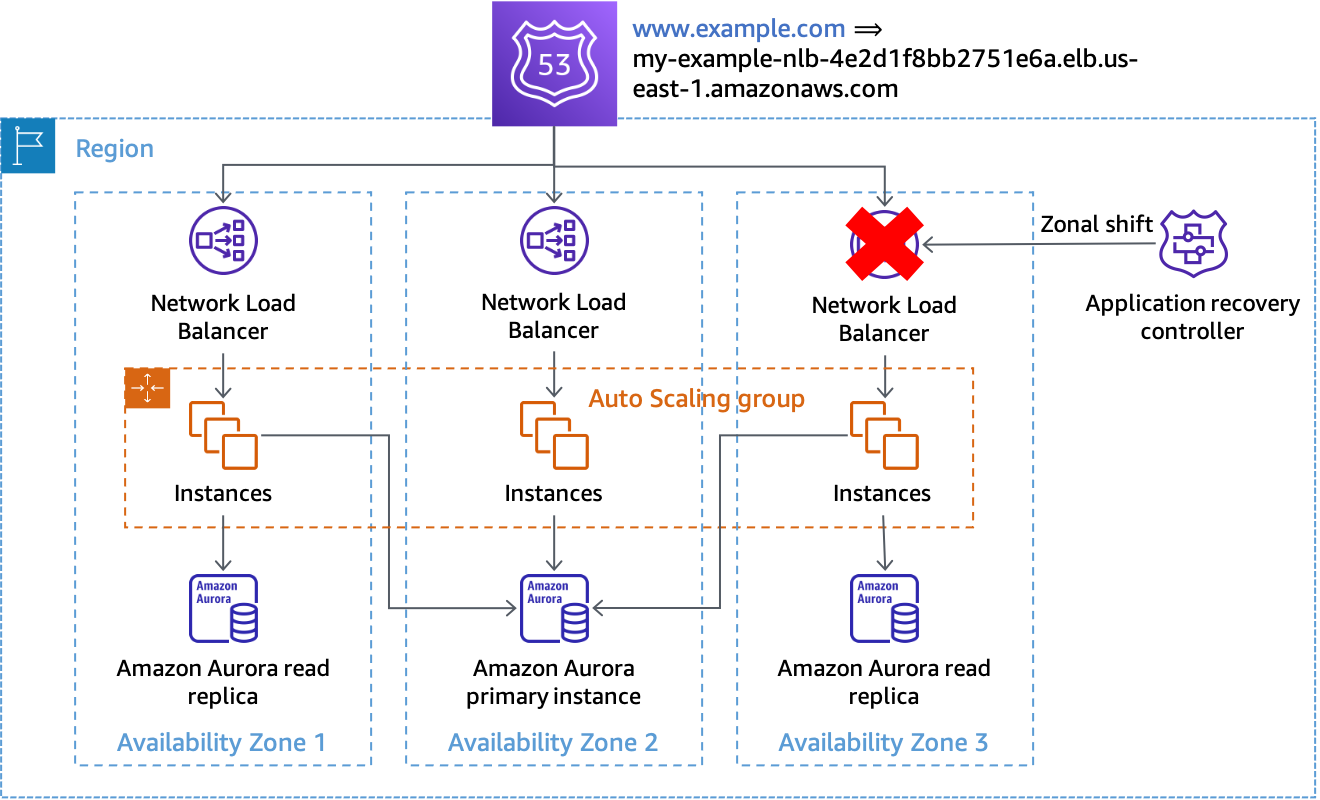
Pergeseran zonal
Dalam contoh, jika instance database utama tidak berada di Availability Zone 3, maka melakukan pergeseran zonal adalah satu-satunya tindakan yang diperlukan untuk mencapai hasil pertama untuk evakuasi, mencegah pekerjaan diproses di Availability Zone yang terkena dampak. Jika node utama berada di Availability Zone 3, maka Anda dapat melakukan failover yang dimulai secara manual (yang bergantung pada bidang kontrol Amazon RDS) dalam koordinasi dengan pergeseran zonal, jika Amazon RDS belum melakukan failover secara otomatis. Ini akan berlaku untuk semua solusi data yang dikendalikan pesawat di bagian ini.
Anda harus memulai pergeseran zonal menggunakan perintah CLI atau API untuk meminimalkan dependensi yang diperlukan untuk memulai evakuasi. Semakin sederhana proses evakuasi, semakin dapat diandalkan. Perintah spesifik dapat disimpan dalam runbook lokal yang dapat diakses oleh teknisi panggilan dengan mudah. Pergeseran zona adalah solusi yang paling disukai dan paling sederhana untuk mengevakuasi Availability Zone.
Rute 53 ARC
Solusi kedua menggunakan kemampuan Route 53 ARC untuk secara manual menentukan kesehatan catatan DNS tertentu. Solusi ini memiliki manfaat menggunakan pesawat data cluster Route 53 ARC yang sangat tersedia, sehingga tahan terhadap gangguan hingga dua yang berbedaWilayah AWS. Ini memiliki tradeoff biaya tambahan dan memerlukan beberapa konfigurasi tambahan catatan DNS. Untuk menerapkan pola ini, Anda perlu membuat catatan alias untukNama DNS khusus Zona Ketersediaandisediakan oleh load balancer (ALB atau NLB). Hal ini ditunjukkan pada tabel berikut.
Tabel 3: Route 53 catatan alias dikonfigurasi untuk nama DNS zonal load balancer
|
Kebijakan Routing: tertimbang Nama: Jenis: Nilai: Berat: Evaluasi Target Kesehatan: benar |
Kebijakan Routing:berbobot Nama: Jenis: Nilai Berat: Evaluasi Kesehatan Target: |
Kebijakan Routing:berbobot Nama: Jenis: Nilai Berat: Evaluasi Kesehatan Target: |
Untuk masing-masing data DNS ini, Anda akan mengkonfigurasi pemeriksaan kesehatan Route 53 yang terkait dengan Route 53 ARCkontrol perutean. Saat Anda ingin memulai evakuasi Availability Zone, atur status kontrol perutean keOff.AWSmenyarankan Anda melakukan ini menggunakan CLI atau API untuk meminimalkan dependensi yang diperlukan untuk memulai evakuasi Availability Zone. Sebagaipraktek terbaik, Anda harus menyimpan salinan lokal dari titik akhir cluster Route 53 ARC sehingga Anda tidak perlu mengambilnya dari bidang kontrol ARC saat Anda perlu melakukan evakuasi.
Untuk meminimalkan biaya saat menggunakan pendekatan ini, Anda dapat membuat satu klaster Route 53 ARC dan pemeriksaan kesehatan dalam satuAkun AWSdanbagikan pemeriksaan kesehatan dengan yang lainAkun AWSuse1-az1) alih-alih nama Availability Zone (misalnya,us-east-1a) untuk kontrol routing Anda. KarenaAWSmemetakan Availability Zone fisik secara acak ke nama Availability Zone untuk masing-masingAkun AWS, menggunakan AZ-ID menyediakan cara yang konsisten untuk merujuk ke lokasi fisik yang sama. Saat Anda memulai evakuasi Availability Zone, katakan untukuse1-az2, set rekaman Route 53 di masing-masingAkun AWSharus memastikan mereka menggunakan pemetaan AZ-ID untuk mengkonfigurasi pemeriksaan kesehatan yang tepat untuk setiap catatan NLB.
Misalnya, kita memiliki pemeriksaan kesehatan Route 53 yang terkait dengan kontrol routing Route 53 ARC untukuse1-az2, dengan ID0385ed2d-d65c-4f63-a19b-2412a31ef431. Jika berbedaAkun AWSyang ingin menggunakan pemeriksaan kesehatan ini,us-east-1cdipetakan keuse1-az2, Anda perlu menggunakanuse1-az2pemeriksaan kesehatan untuk catatanus-east-1c.load-balancer-name.elb.us-east-1.amazonaws.com. Anda akan menggunakan ID pemeriksaan kesehatan0385ed2d-d65c-4f63-a19b-2412a31ef431dengan catatan sumber daya yang ditetapkan.
Menggunakan endpoint HTTP yang dikelola sendiri
Anda juga dapat menerapkan solusi ini dengan mengelola endpoint HTTP Anda sendiri yang menunjukkan status Availability Zone tertentu. Ini memungkinkan Anda untuk menentukan secara manual kapan Availability Zone tidak sehat berdasarkan respons dari titik akhir HTTP. Solusi ini harganya lebih murah daripada menggunakan Route 53 ARC, tetapi lebih mahal daripada pergeseran zonal dan membutuhkan pengelolaan infrastruktur tambahan. Ini memiliki manfaat menjadi jauh lebih fleksibel untuk skenario yang berbeda.
Pola ini dapat digunakan dengan arsitektur NLB atau ALB dan pemeriksaan kesehatan Route 53. Ini juga dapat digunakan dalam arsitektur seimbang non-beban, seperti penemuan layanan atau sistem pemrosesan antrian di mana node pekerja melakukan pemeriksaan kesehatan mereka sendiri. Dalam skenario tersebut, host dapat menggunakan thread latar belakang di mana mereka secara berkala membuat permintaan ke endpoint HTTP dengan AZ-ID mereka (lihatLampiran A — Mendapatkan ID Availability Zone untuk rincian tentang bagaimana menemukan ini) dan menerima kembali respon tentang kesehatan Availability Zone.
Jika Availability Zone dinyatakan tidak sehat, mereka memiliki beberapa opsi tentang cara merespons. Mereka dapat memilih untuk gagal pemeriksaan kesehatan eksternal dari sumber seperti ELB, Route 53, atau pemeriksaan kesehatan khusus dalam arsitektur penemuan layanan sehingga mereka tampak tidak sehat untuk layanan tersebut. Mereka juga dapat segera merespons dengan kesalahan jika mereka menerima permintaan, memungkinkan klien untuk mundur dan mencoba lagi. Dalam arsitektur yang digerakkan oleh peristiwa, node dapat dengan sengaja gagal memproses pekerjaan, seperti dengan sengaja mengembalikan pesan SQS ke antrian. Dalam bekerja arsitektur router di mana jadwal layanan pusat bekerja pada host tertentu Anda juga dapat menggunakan pola ini. Router dapat memeriksa status Availability Zone sebelum memilih pekerja, titik akhir, atau sel. Dalam arsitektur penemuan layanan yang menggunakanAWS Cloud Map, kamu bisatemukan titik akhir dengan menyediakan filter dalam permintaan Anda
Gambar berikut menunjukkan bagaimana pendekatan ini dapat digunakan untuk beberapa jenis beban kerja.
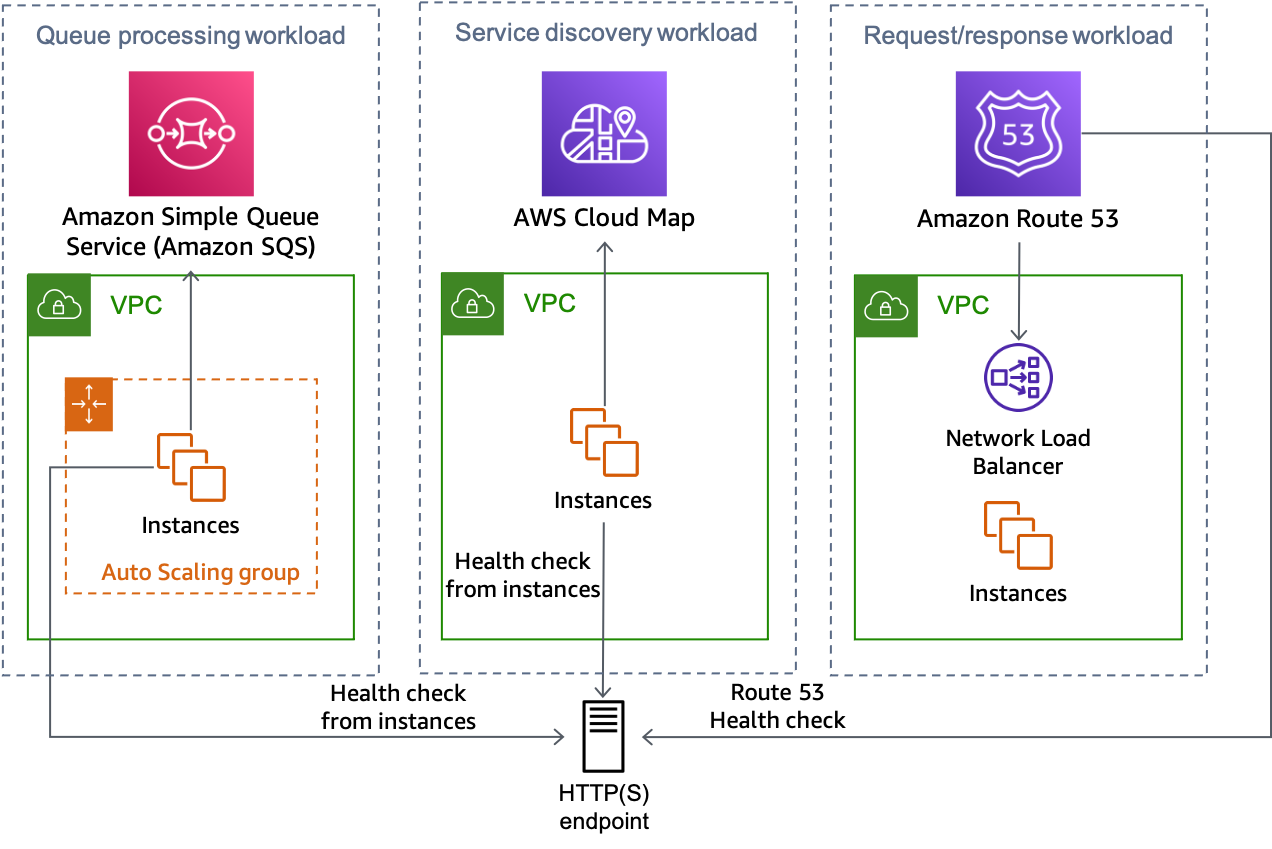
Beberapa jenis beban kerja semuanya dapat menggunakan solusi endpoint HTTP
Ada beberapa cara untuk menerapkan pendekatan endpoint HTTP, dua di antaranya diuraikan berikutnya.
Menggunakan Amazon S3
Pola ini awalnya disajikan dalam hal iniposting blog
Dalam skenario ini Anda akan membuat kumpulan data sumber daya Route 53 DNS untuk setiap catatan DNS zona sepertiRute 53 ARCskenario di atas serta pemeriksaan kesehatan terkait. Namun, untuk implementasi ini, alih-alih mengaitkan pemeriksaan kesehatan dengan kontrol routing Route 53 ARC, mereka dikonfigurasi untuk menggunakanTitik akhir HTTPdan terbalik untuk melindungi terhadap gangguan di Amazon S3 secara tidak sengaja memicu evakuasi. Pemeriksaan kesehatan dipertimbangkansehatketika objek tidak ada dantidak sehatketika objek hadir. Pengaturan ini ditunjukkan pada tabel berikut.
Tabel 4: Konfigurasi catatan DNS untuk menggunakan pemeriksaan kesehatan Route 53 per Availability Zone
|
Jenis pemeriksaan kesehatan: memonitor titik akhir Protokol: ID: URL: |
Jenis pemeriksaan kesehatan: memonitor titik akhir Protokol: ID: URL: |
Jenis pemeriksaan kesehatan: memonitor titik akhir Protokol: ID: URL: |
← | Pemeriksaan kesehatan |
| ↑ | ↑ | ↑ | ||
|
Kebijakan Routing: tertimbang Nama: Jenis: Nilai: Berat: Evaluasi Target Kesehatan: |
Kebijakan Routing:berbobot Nama: Jenis: Nilai: Berat: Evaluasi Kesehatan Target: |
Kebijakan Routing:berbobot Nama: Jenis: Nilai: Berat: Evaluasi Kesehatan Target: |
← | Tingkat atas, alias tertimbang merata Catatan A menunjuk ke titik akhir spesifik NLB AZ |
Mari kita asumsikan bahwa Availability Zoneus-east-1adipetakan keuse1-az3di akun di mana kita memiliki beban kerja di mana kita ingin melakukan evakuasi Availability Zone. Untuk kumpulan catatan sumber daya yang dibuat untukus-east-1a.load-balancer-name.elb.us-east-1.amazonaws.comakan mengaitkan pemeriksaan kesehatan yang menguji URLhttps://. Saat Anda ingin memulai evakuasi Availability Zone untukbucket-name.s3.us-east-1.amazonaws.com/use1-az3.txtuse1-az3, unggah file bernamause1-az3.txtke bucket menggunakan CLI atau API. File tidak perlu berisi konten apa pun, tetapi harus bersifat publik sehingga pemeriksaan kesehatan Route 53 dapat mengaksesnya. Gambar berikut menunjukkan implementasi ini digunakan untuk mengungsiuse1-az3.
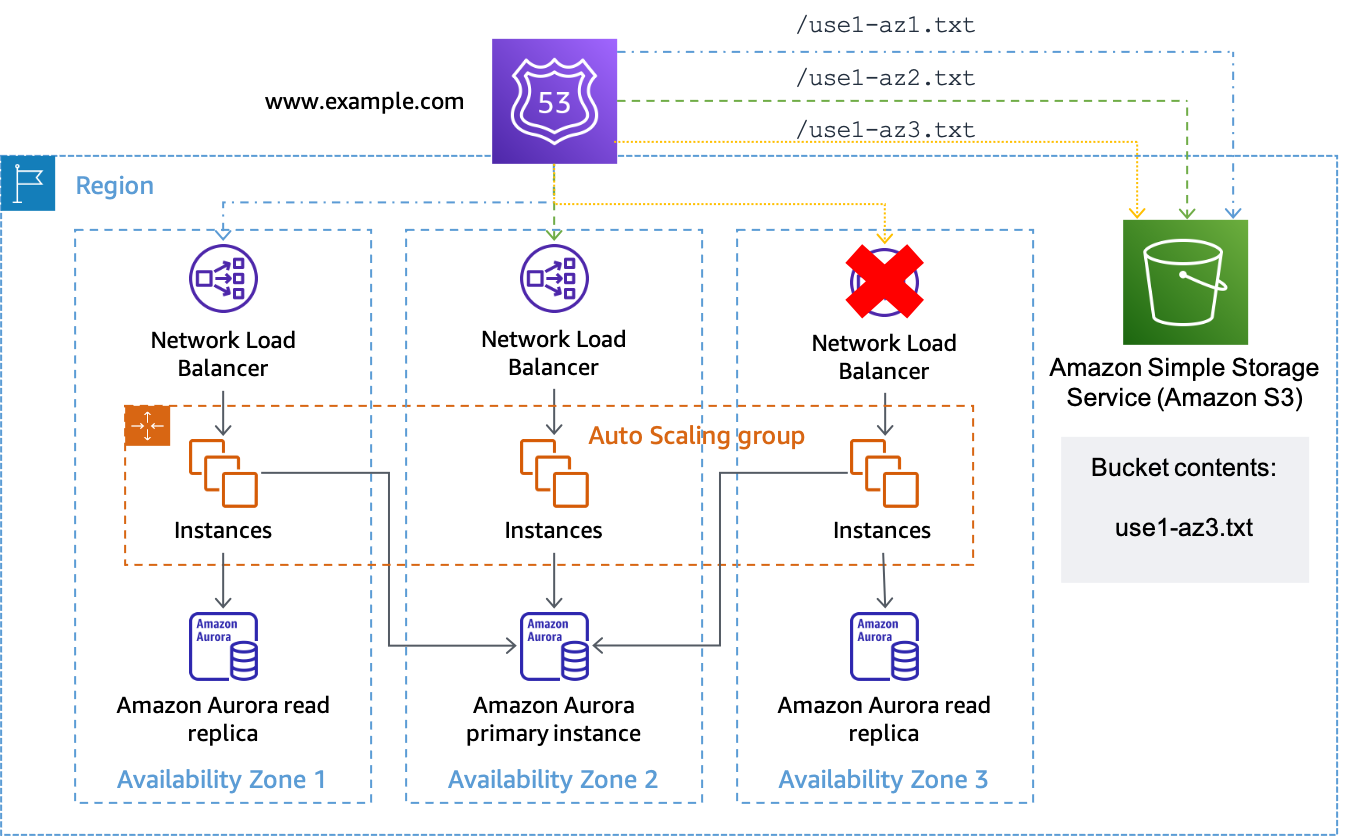
Menggunakan Amazon S3 sebagai target untuk pemeriksaan kesehatan Route 53
Menggunakan API Gateway dan DynamoDB
Implementasi kedua dari pola ini menggunakanGerbang API Amazon
Jika Anda menggunakan solusi ini dengan arsitektur NLB atau ALB, siapkan data DNS Anda dengan cara yang sama seperti contoh Amazon S3 di atas, kecuali ubah jalur pemeriksaan kesehatan untuk menggunakan titik akhir API Gateway dan menyediakanAZ-IDdi jalur URL. Misalnya, jika API Gateway dikonfigurasi dengan domain kustomaz-status.example.com, permintaan penuh untukuse1-az1akan terlihat sepertihttps://az-status.example.com/status/use1-az1. Saat Anda ingin memulai evakuasi Availability Zone, Anda dapat membuat atau memperbarui item DynamoDB menggunakan CLI atau API. Item menggunakanAZ-IDsebagai kunci utama dan kemudian memiliki atribut Boolean disebutHealthyyang digunakan menunjukkan bagaimana API Gateway merespons. Berikut ini adalah contoh kode yang digunakan dalam konfigurasi API Gateway untuk membuat penentuan ini.
#set($inputRoot = $input.path('$')) #if ($inputRoot.Item.Healthy['BOOL'] == (false)) #set($context.responseOverride.status = 500) #end
Jika atributnya adalahtrue(atau tidak ada), API Gateway merespons pemeriksaan kesehatan dengan HTTP 200, jika salah, itu merespons dengan HTTP 500. Implementasi ini ditunjukkan pada gambar berikut.
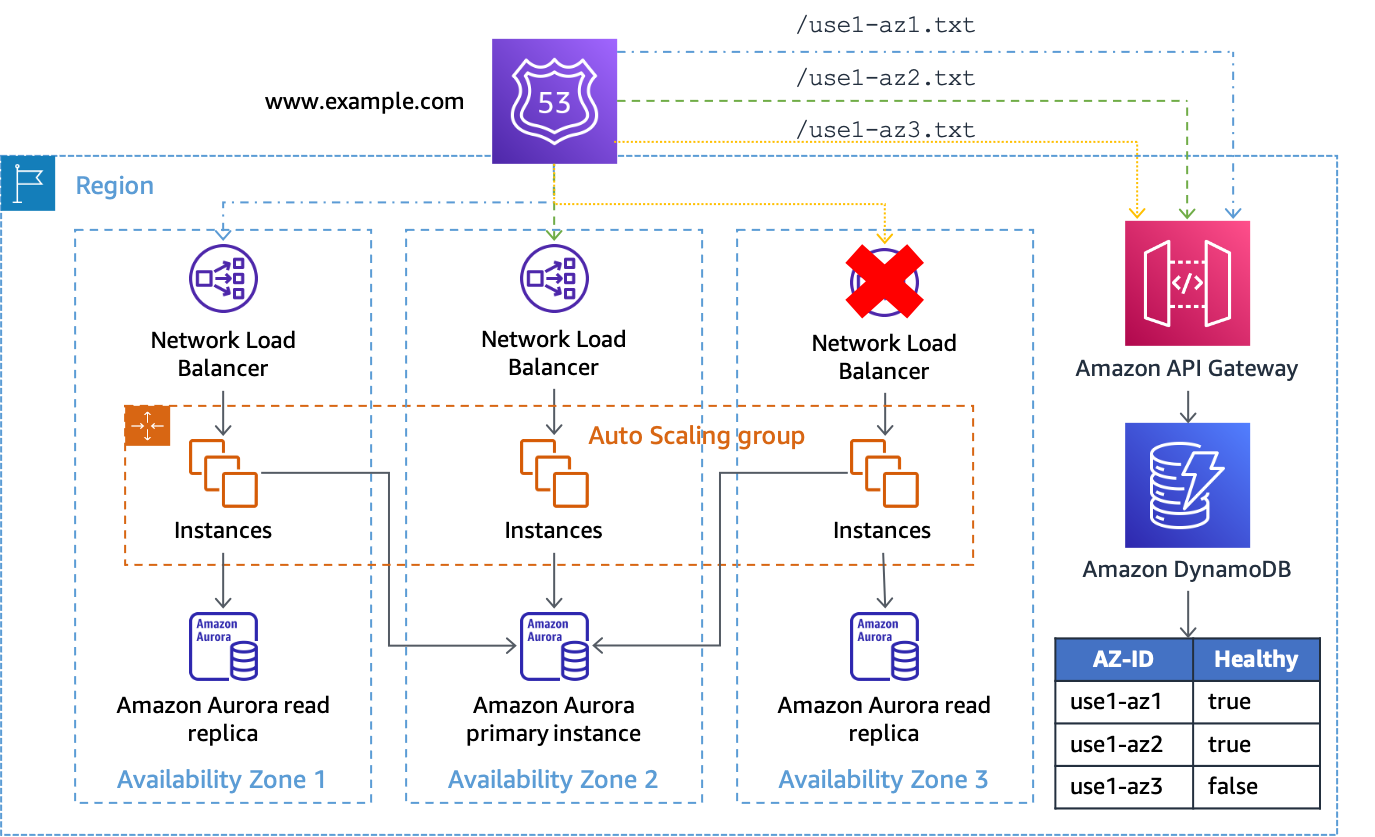
Menggunakan API Gateway dan DynamoDB sebagai target pemeriksaan kesehatan Route 53
Dalam solusi ini Anda perlu menggunakan API Gateway di depan DynamoDB sehingga Anda dapat membuat endpoint dapat diakses publik serta memanipulasi URL permintaan menjadiGetItempermintaan untuk DynamoDB. Solusinya juga memberikan fleksibilitas jika Anda ingin menyertakan data tambahan dalam permintaan. Misalnya, jika Anda ingin membuat status yang lebih terperinci, seperti per aplikasi, Anda dapat mengonfigurasi URL pemeriksaan kesehatan untuk memberikan ID aplikasi di jalur atau string kueri yang juga cocok dengan item DynamoDB.
Endpoint status Availability Zone dapat diterapkan secara terpusat sehingga beberapa sumber daya pemeriksaan kesehatan di seluruhAkun AWSsemua dapat menggunakan tampilan konsisten yang sama dari kesehatan Availability Zone (memastikan bahwa API Gateway REST API dan tabel DynamoDB Anda diskalakan untuk menangani beban) dan menghilangkan kebutuhan untuk berbagi pemeriksaan kesehatan Route 53.
Solusinya juga bisa diskalakan di beberapaWilayah AWSmenggunakanTabel global Amazon DynamoDB
Jika Anda membangun solusi untuk masing-masing host untuk digunakan sebagai mekanisme untuk menentukan kesehatan AZ mereka, sebagai alternatif, alih-alih menyediakan mekanisme tarik untuk pemeriksaan kesehatan, Anda dapat menggunakan pemberitahuan push. Salah satu cara untuk melakukannya adalah dengan topik SNS yang berlangganan konsumen Anda. Saat Anda ingin memicu pemutus arus, publikasikan pesan ke topik SNS yang menunjukkan Availability Zone mana yang terganggu. Pendekatan ini membuat tradeoff dengan mantan. Ini menghilangkan kebutuhan untuk membuat dan mengoperasikan infrastruktur API Gateway dan melakukan manajemen kapasitas. Ini juga berpotensi memberikan konvergensi yang lebih cepat dari status Availability Zone. Namun, ini menghilangkan kemampuan untuk melakukan kueri ad hoc dan bergantung padaKebijakan percobaan ulang pengiriman SNSuntuk memastikan setiap endpoint menerima notifikasi. Hal ini juga memerlukan setiap beban kerja atau layanan untuk membangun cara untuk menerima pemberitahuan SNS dan mengambil tindakan di atasnya.
Misalnya, setiap instans atau wadah EC2 baru yang diluncurkan perlu berlangganan topik dengan endpoint HTTP selama bootstrap. Kemudian, setiap instance perlu mengimplementasikan perangkat lunak yang mendengarkan titik akhir ini di mana notifikasi dikirimkan. Selain itu, jika instans dipengaruhi oleh peristiwa, instans mungkin tidak menerima notifikasi push dan terus berfungsi. Sedangkan, dengan pull notification, instance akan tahu apakah pull request gagal dan dapat memilih tindakan apa yang akan diambil sebagai respons.
Cara kedua untuk mengirim notifikasi push adalah dengan umur panjangWebSocketkoneksi. Amazon API Gateway dapat digunakan untuk menyediakanWebSocketAPIbahwa konsumen dapat terhubung dan menerima pesan kapandikirim oleh backend. DenganWebSocket, instans dapat melakukan penarikan berkala untuk memastikan koneksi mereka sehat dan juga menerima pemberitahuan push latensi rendah.
