Skenario 5: Pemantauan data telemetri waktu nyata dengan Apache Kafka
ABC1Cabs adalah perusahaan layanan pemesanan taksi online. Semua taksi memiliki perangkat IoT yang mengumpulkan data telemetri dari kendaraan. Saat ini, ABC1Cabs menjalankan klaster Apache Kafka yang dirancang untuk konsumsi peristiwa waktu nyata, mengumpulkan metrik kondisi sistem, pelacakan aktivitas, dan mengumpankan data ke platform Apache Spark Streaming yang dibangun di klaster Hadoop secara on-premise.
ABC1Cabs menggunakan OpenSearch Dashboards untuk metrik bisnis, debugging, pemberitahuan, dan membuat dasbor lainnya. Mereka tertarik dengan Amazon MSK, Amazon EMR with Spark Streaming, dan OpenSearch Service with OpenSearch Dashboards. Kebutuhan mereka adalah mengurangi overhead admin dalam memelihara klaster Apache Kafka dan Hadoop, sambil menggunakan perangkat lunak sumber terbuka dan API yang sudah dikenal untuk mengorkestrasi alur data mereka. Diagram arsitektur berikut menampilkan solusi mereka di AWS.
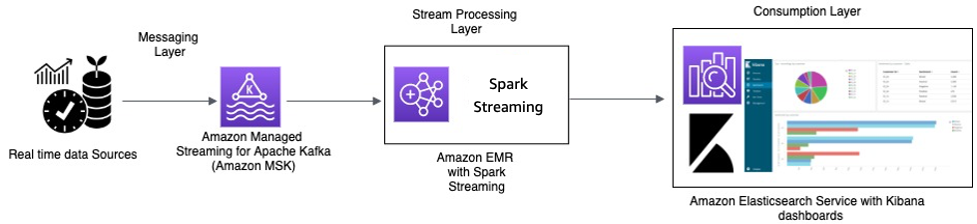
Pemrosesan waktu nyata dengan Amazon MSK dan pemrosesan Aliran menggunakan Apache Spark Streaming di Amazon EMR dan Amazon OpenSearch Service with OpenSearch Dashboards
Perangkat IoT taksi mengumpulkan data telemetri dan mengirimnya ke hub sumber. Hub sumber dikonfigurasi untuk mengirim data secara waktu nyata ke Amazon MSK. Menggunakan API pustaka produsen Apache Kafka, Amazon MSK dikonfigurasi untuk mengalirkan data ke dalam klaster Amazon EMR. Klaster Amazon EMR memiliki klien Kafka dan Spark Streaming yang telah diinstal untuk dapat mengonsumsi dan memproses aliran data.
Spark Streaming memiliki konektor sink yang dapat menulis data langsung ke indeks yang didefinisikan di Elasticsearch. Klaster Elasticsearch dengan OpenSearch Dashboards dapat digunakan untuk metrik dan dasbor. Amazon MSK, Amazon EMR with Spark Streaming, dan OpenSearch Service with OpenSearch Dashboards adalah layanan terkelola, tempat AWS mengelola pekerjaan berat yang tidak terdiferensiasi dalam manajemen infrastruktur terhadap berbagai klaster, yang memungkinkan Anda membangun aplikasi menggunakan perangkat lunak sumber terbuka yang sudah dikenal dengan beberapa klik . Bagian selanjutnya akan mengamati lebih dekat layanan tersebut.
Amazon Managed Streaming for Apache Kafka (Amazon MSK)
Apache Kafka adalah platform sumber terbuka yang memungkinkan pelanggan menangkap data pengaliran seperti peristiwa clickstream, transaksi, peristiwa IoT, serta log aplikasi dan mesin. Dengan informasi ini, Anda dapat mengembangkan aplikasi yang melakukan analitik waktu nyata, menjalankan transformasi berkelanjutan, serta mendistribusikan data ini ke danau data dan basis data secara waktu nyata.
Anda dapat menggunakan Kafka sebagai penyimpanan data pengaliran untuk memisahkan aplikasi dari produsen dan konsumen serta memungkinkan transfer data yang dapat diandalkan di antara kedua komponen. Meskipun Kafka adalah platform pengaliran dan olahpesan data korporasi yang populer, layanan ini dapat sulit untuk disiapkan, diskalakan, dan dikelola dalam produksi.
Amazon MSK menangani tugas-tugas pengelolaan ini dan memudahkan untuk menyiapkan, mengonfigurasi, dan menjalankan Kafka, bersama dengan Apache Zookeeper, dalam lingkungan yang mengikuti praktik terbaik untuk ketersediaan dan keamanan yang tinggi. Anda masih dapat menggunakan operasi bidang kontrol Kafka dan operasi bidang data untuk mengelola produksi dan konsumsi data.
Karena Amazon MSK menjalankan dan mengelola Apache Kafka sumber terbuka, layanan ini memudahkan pelanggan untuk memigrasikan dan menjalankan aplikasi Apache Kafka yang ada di AWS tanpa perlu melakukan perubahan pada kode aplikasi mereka.
Penskalaan
Amazon MSK menawarkan operasi penskalaan sehingga pengguna dapat menskalakan klaster secara aktif saat klaster berjalan. Saat membuat klaster Amazon MSK, Anda dapat menentukan jenis instans broker pada peluncuran klaster. Anda dapat memulai dengan beberapa broker dalam klaster Amazon MSK. Kemudian, dengan menggunakan AWS Management Console atau AWS CLI, Anda dapat menskalakan hingga ratusan broker per klaster.
Atau, Anda dapat menskalakan klaster Anda dengan mengubah ukuran atau kelompok broker Apache Kafka Anda. Dengan mengubah ukuran atau kelompok broker, Anda memiliki fleksibilitas untuk menyesuaikan kapasitas komputasi klaster Amazon MSK Anda sesuai dengan perubahan beban kerja. Gunakan spreadsheet Amazon MSK Sizing and Pricing
Setelah membuat klaster Amazon MSK, Anda dapat meningkatkan jumlah penyimpanan EBS per broker, kecuali mengurangi penyimpanan. Volume penyimpanan tetap tersedia selama operasi penaikan skala ini. Layanan ini menawarkan dua jenis operasi penskalaan: Penskalaan Otomatis dan Penskalaan Manual.
Amazon MSK mendukung ekspansi otomatis penyimpanan klaster Anda sebagai respons terhadap peningkatan penggunaan sesuai dengan kebijakan Penskalaan Otomatis Aplikasi. Kebijakan penskalaan otomatis Anda menetapkan pemanfaatan disk target dan kapasitas penskalaan maksimum.
Ambang batas pemanfaatan penyimpanan membantu Amazon MSK memicu operasi penskalaan otomatis. Untuk meningkatkan penyimpanan menggunakan penskalaan manual, tunggu sampai klaster berada dalam status ACTIVE. Penskalaan penyimpanan memiliki periode pendinginan selama setidaknya enam jam di antara peristiwa. Meskipun operasi ini menyediakan penyimpanan tambahan dengan segera, layanan ini melakukan optimasi pada klaster Anda yang dapat memakan waktu hingga 24 jam atau lebih.
Durasi optimasi ini sebanding dengan ukuran penyimpanan Anda. Selain itu, layanan ini juga menawarkan replikasi Multi-Zona Ketersediaan dalam Wilayah AWS untuk menyediakan Ketersediaan Tinggi.
Konfigurasi
Amazon MSK menyediakan konfigurasi default untuk broker, topik, dan node Apache Zookeeper. Anda juga dapat membuat konfigurasi kustom dan menggunakannya untuk membuat klaster Amazon MSK baru atau memperbarui klaster yang ada. Saat Anda membuat klaster MSK tanpa menentukan konfigurasi Amazon MSK kustom, Amazon MSK membuat dan menggunakan konfigurasi default. Untuk daftar nilai default, lihat Konfigurasi Apache Kafka ini.
Untuk tujuan pemantauan, Amazon MSK mengumpulkan metrik Apache Kafka dan mengirimkannya ke Amazon CloudWatch, tempat Anda dapat melihatnya. Metrik yang Anda konfigurasikan untuk klaster MSK secara otomatis dikumpulkan dan didorong ke CloudWatch. Memantau lag konsumen memungkinkan Anda mengidentifikasi konsumen yang lambat atau macet serta tidak mengikuti data terbaru yang tersedia dalam suatu topik. Jika perlu, Anda kemudian dapat melakukan tindakan perbaikan, seperti penskalaan atau reboot konsumen tersebut.
Bermigrasi ke Amazon MSK
Migrasi dari on-premise ke Amazon MSK dapat dicapai dengan salah satu metode berikut.
-
MirrorMaker2.0 — MirrorMaker2.0 (MM2) MM2 adalah mesin replikasi data multi-klaster berdasarkan kerangka kerja Apache Kafka Connect. MM2 adalah kombinasi dari konektor sumber dan konektor sink Apache Kafka. Anda dapat menggunakan klaster MM2 tunggal untuk memigrasikan data di antara sejumlah klaster. MM2 secara otomatis mendeteksi topik dan partisi baru, sambil memastikan konfigurasi topik disinkronkan di antara klaster. MM2 mendukung ACL migrasi, konfigurasi topik, dan terjemahan offset. Untuk detail selengkapnya terkait migrasi, lihat Memigrasi Klaster Menggunakan MirrorMaker Apache Kafka. MM2 digunakan untuk kasus penggunaan yang terkait dengan replikasi konfigurasi topik dan terjemahan offset secara otomatis.
-
Apache Flink — MM2 mendukung semantik setidaknya sekali. Catatan dapat diduplikasi ke tujuan dan konsumen diharapkan akan bersifat idempoten untuk menangani catatan duplikat. Dalam skenario yang memerlukan semantik persis sekali, pelanggan dapat menggunakan Apache Flink. Layanan ini memberikan alternatif untuk mencapai semantik persis sekali.
Apache Flink juga dapat digunakan untuk skenario saat data memerlukan tindakan pemetaan atau transformasi sebelum dikirim ke klaster tujuan. Apache Flink menyediakan konektor untuk Apache Kafka dengan sumber dan sink yang dapat membaca data dari satu klaster Apache Kafka dan menulis ke yang lain. Apache Flink dapat dijalankan di AWS dengan meluncurkan klaster Amazon EMR atau dengan menjalankan Apache Flink sebagai aplikasi menggunakan Amazon Kinesis Data Analytics.
-
AWS Lambda — Dengan dukungan untuk Apache Kafka sebagai sumber peristiwa untuk AWS Lambda
, pelanggan sekarang dapat mengonsumsi pesan dari topik melalui fungsi Lambda. Layanan AWS Lambda secara internal melakukan polling untuk catatan atau pesan baru dari sumber peristiwa, lalu secara sinkron memanggil fungsi Lambda target untuk mengonsumsi pesan-pesan ini. Lambda membaca pesan dalam batch dan menyediakan batch pesan ke fungsi Anda dalam muatan peristiwa untuk diproses. Pesan yang dikonsumsi kemudian dapat ditransformasi dan/atau ditulis langsung ke klaster Amazon MSK tujuan Anda.
Amazon EMR with Spark Streaming
Amazon EMR
Amazon EMR menyediakan kemampuan Spark dan dapat digunakan untuk memulai pengaliran Spark untuk mengonsumsi data dari Kafka. Spark Streaming adalah ekstensi dari API Spark inti yang memungkinkan pemrosesan aliran data langsung aliran yang dapat diskalakan, memiliki throughput tinggi, dan toleran terhadap kesalahan.
Anda dapat membuat klaster Amazon EMR menggunakan AWS Command Line Interface
Data yang diproses dapat didorong keluar ke sistem file, basis data, dan dasbor langsung.
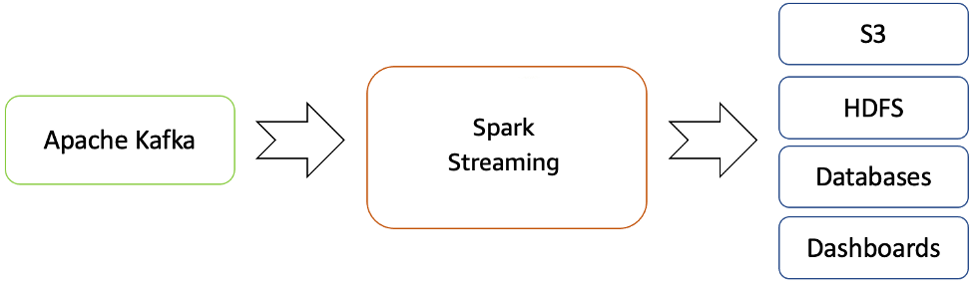
Alur pengaliran waktu nyata dari Apache Kafka ke ekosistem Hadoop
Secara default, Apache Spark Streaming memiliki model proses mikro-batch. Namun, sejak Spark 2.3 dirilis, Apache telah memperkenalkan mode pemrosesan latensi rendah baru yang disebut Continuous Processing, yang dapat mencapai latensi ujung ke ujung satu milidetik dengan jaminan paling sedikit sekali.
Tanpa mengubah operasi Dataset/DataFrames dalam kueri Anda, Anda dapat memilih mode berdasarkan persyaratan aplikasi Anda. Beberapa manfaat dari Spark Streaming adalah:
-
Ekstensi ini menghadirkan API terintegrasi bahasa
Apache Spark ke pemrosesan aliran, sehingga memungkinkan Anda menulis tugas pengaliran dengan cara yang sama seperti menulis tugas batch. -
Ekstensi ini mendukung Java, Scala, dan Python.
-
Ekstensi ini dapat memulihkan pekerjaan dan status operator yang hilang (seperti sliding window) tanpa konfigurasi dan kode tambahan dari Anda.
-
Dengan menjalankan di Spark, Spark Streaming memungkinkan Anda menggunakan kembali kode yang sama untuk pemrosesan batch, menggabungkan aliran berdasarkan data historis, atau menjalankan kueri ad hoc pada status aliran dan membangun aplikasi interaktif yang canggih, bukan hanya analitik.
-
Setelah aliran data diproses dengan Spark Streaming, OpenSearch Sink Connector dapat digunakan untuk menulis data ke klaster OpenSearch Service, lalu OpenSearch Service with OpenSearch Dashboards dapat digunakan sebagai lapisan konsumsi.
Amazon OpenSearch Service with OpenSearch Dashboards
OpenSearch Service adalah layanan terkelola yang memudahkan deployment, pengoperasian, dan penskalaan klaster OpenSearch di AWS Cloud. OpenSearch adalah mesin pencarian dan analitik sumber terbuka yang populer untuk kasus penggunaan seperti analitik log, pemantauan aplikasi waktu nyata, dan analitik clickstream.
OpenSearch Dashboards
OpenSearch Dashboards menyediakan integrasi yang kuat dengan OpenSearch
Ringkasan
Dengan Apache Kafka yang ditawarkan sebagai layanan terkelola di AWS, Anda dapat fokus pada konsumsi daripada mengelola koordinasi di antara broker, yang biasanya memerlukan pemahaman mendetail tentang Apache Kafka. Fitur seperti ketersediaan tinggi, skalabilitas broker, dan kontrol akses granular dikelola oleh platform Amazon MSK.
ABC1Cabs memanfaatkan sejumlah layanan ini untuk membangun aplikasi produksi tanpa memerlukan keahlian manajemen infrastruktur. Mereka dapat fokus pada lapisan pemrosesan untuk mengonsumsi data dari Amazon MSK dan menyebarkan secara lebih lanjut ke lapisan visualisasi.
Spark Streaming di Amazon EMR dapat membantu analitik data pengaliran secara waktu nyata, dan publikasi di OpenSearch Dashboards
