Langkah 1: Pengumpulan dan agregat data
Gambar berikut menunjukkan model mental untuk masalah prakiraan. Tujuannya adalah untuk memperkirakan deret waktuz_t ke masa depan, menggunakan sebanyak mungkin informasi yang relevan untuk membuat prakiraan seakurat mungkin. Oleh karena itu, langkah pertama dan paling penting adalah mengumpulkan sebanyak mungkin data yang benar.
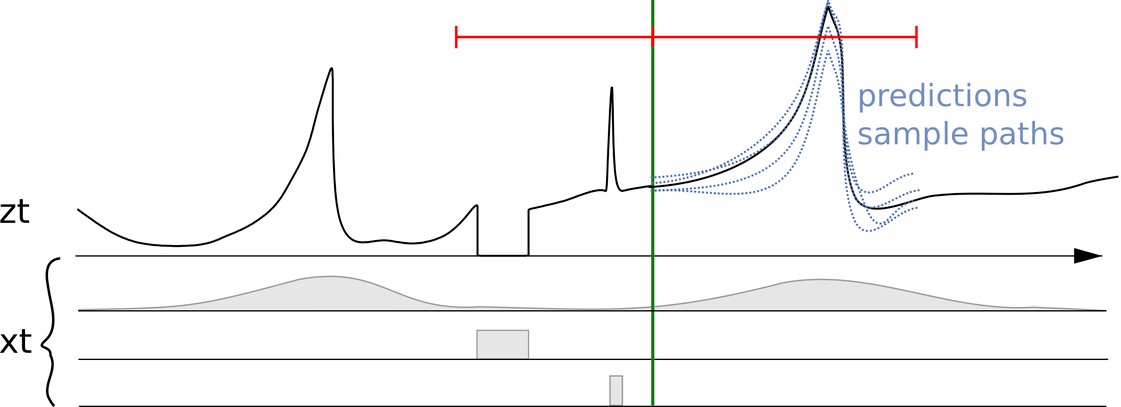
Seri waktu z_t bersama dengan fitur terkait atau ko-variabel acak (x_t) dan beberapa prakiraan
Pada gambar sebelumnya, beberapa prakiraan ditampilkan di sebelah kanan garis vertikal. Prakiraan ini adalah contoh dari distribusi prakiraan probabilistik (atau, sebaliknya, dapat digunakan untuk mewakili prakiraan probabilistik).
Informasi utama bisnis retail untuk dicatat adalah:
-
Data penjualan transaksi — Misalnya, unit penyimpanan stok (SKU), lokasi, tanda waktu, dan unit terjual.
-
Data mendetail item SKU — Metadata item. Contohnya termasuk warna, departemen, ukuran, dan sebagainya.
-
Data harga — Deret waktu harga setiap item dengan tanda waktu.
-
Data informasi promosi — Berbagai jenis promosi, baik untuk sekumpulan item (kategori) atau masing-masing item dengan tanda waktu.
-
Data informasi stok — Untuk setiap unit waktu, informasi tentang apakah SKU ada dalam stok atau dapat dibeli dibandingkan SKU tidak ada dalam stok.
-
Data lokasi — Lokasi item atau penjualan pada suatu titik waktu tertentu dapat direpresentasikan sebagai tali
location_idataustore_idsebagai geolokasi aktual. Geolokasi dapat berupa kode negara ditambah kode pos lima digit, ataulatitude_longitudekoordinat. Lokasi dianggap sebagai “dimensi” penjualan transaksional.
Di Amazon Forecast
Perhatikan bahwa informasi stok penting karena masalah ini berpusat pada prakiraan permintaan dan bukan penjualan, tetapi bisnis hanya mencatat penjualan. Ketika SKU tidak dalam stok, jumlah penjualan lebih rendah dari potensi permintaan, jadi penting untuk mengetahui dan mencatat kapan peristiwa tidak dalam stok tersebut terjadi.
Set data lain yang perlu dipertimbangkan termasuk jumlah kunjungan ke halaman web, informasi mendetail tentang istilah pencarian, media sosial, dan informasi cuaca. Sering kali memiliki data yang tersedia untuk masa lalu dan untuk masa depan itu penting untuk dapat menggunakan data ini dalam model. Hal ini adalah persyaratan dari banyak model prakiraan dan backtesting (dijelaskan di bagian Langkah 4: Evaluasi prakiraan).
Untuk beberapa masalah prakiraan, frekuensi data mentah secara alami sesuai dengan masalah prakiraan. Contohnya antara lain, permintaan volume server, yang diambil sampelnya berdasarkan menit, saat Anda ingin memperkirakan frekuensi menit.
Data sering dicatat pada frekuensi yang lebih kecil, atau hanya pada tanda waktu acak dalam suatu rentang waktu, tetapi masalah prakiraan berada pada granularitas lebih besar. Hal ini umum terjadi dalam studi kasus retail, di mana data penjualan biasanya dicatat sebagai data transaksional; misalnya, format terdiri dari tanda waktu dengan granularitas sangat kecil ketika penjualan terjadi. Dalam kasus penggunaan prakiraan, granularitas rendah ini mungkin tidak diperlukan, dan mungkin lebih tepat untuk mengumpulkan data ini menjadi penjualan per jam atau harian. Di sini, tingkat agregasi sesuai dengan masalah di langkah selanjutnya; misalnya, manajemen inventaris atau perencanaan sumber daya.
Contoh
Pada gambar berikut, grafik kiri menunjukkan contoh data penjualan mentah pelanggan yang dapat dimasukkan ke Amazon Forecast sebagai file comma separated value (CSV). Dalam contoh ini, data penjualan ditetapkan pada kisi waktu harian yang lebih kecil, dan masalahnya adalah memperkirakan permintaan mingguan pada kisi waktu yang lebih besar ke masa depan. Amazon Forecast melakukan agregasi nilai harian pada minggu tertentu dalam panggilan API create_predictor.
Hasilnya mengubah data mentah menjadi kumpulan deret waktu yang terbentuk dengan baik dengan frekuensi mingguan tetap. Grafik kanan menggambarkan agregasi ini pada deret waktu target menggunakan metode agregasi penjumlahan default. Metode agregasi lainnya termasuk rata-rata, maksimum, minimum, atau memilih satu titik (misalnya, yang pertama). Granularitas dan metode agregasi harus dipilih sedemikian rupa sehingga paling cocok dengan kasus penggunaan data bisnis. Dalam contoh ini, nilai agregat selaras dengan agregasi mingguan. Metode agregasi lainnya dapat diatur oleh pengguna menggunakan tombol FeaturizationMethodParameters dari parameter FeaturizationConfig di API create_predictor.
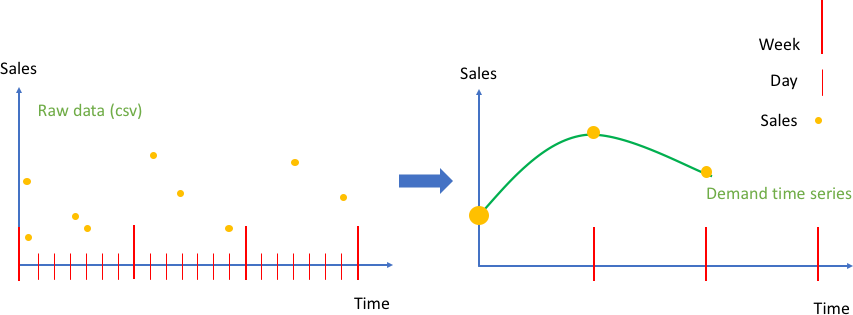
Agregasi data penjualan mentah sebagai peristiwa (kiri), ke deret waktu yang berdurasi sama (kanan)
