Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Ottimizzazione dei parametri di memoria per Aurora PostgreSQL
In Amazon Aurora PostgreSQL, puoi utilizzare diversi parametri che controllano la quantità di memoria utilizzata per varie attività di elaborazione. Se un'attività richiede più memoria della quantità impostata per un determinato parametro, Aurora PostgreSQL utilizza altre risorse per l'elaborazione, ad esempio scrivendo su disco. Ciò può causare il rallentamento o il potenziale arresto del cluster database Aurora PostgreSQL, con un errore di memoria insufficiente.
L'impostazione predefinita per ogni parametro di memoria può in genere gestire le attività di elaborazione previste. Tuttavia, è anche possibile ottimizzare i parametri correlati alla memoria del cluster database Aurora PostgreSQL . Questa ottimizzazione garantisce che venga allocata una quantità di memoria sufficiente per l'elaborazione del carico di lavoro specifico.
Di seguito sono disponibili informazioni sui parametri che controllano la gestione della memoria. Sono incluse anche informazioni su come valutare l'utilizzo della memoria.
Controllo e impostazione dei valori dei parametri
I parametri che è possibile impostare per gestire la memoria e valutare l'utilizzo della memoria del cluster database Aurora PostgreSQL includono i seguenti:
work_mem: specifica la quantità di memoria utilizzata dal cluster database Aurora PostgreSQL per le operazioni di ordinamento interno e le tabelle hash prima di scrivere su file del disco temporanei.log_temp_files: registra la data di creazione di file temporanei, i nomi file e le dimensioni. Quando questo parametro è attivato, una voce di registro viene memorizzata per ogni file temporaneo creato. Attivarlo per visualizzare la frequenza di scrittura nel disco del cluster database Aurora PostgreSQL. Dopo aver raccolto informazioni sulla generazione di file temporanei del cluster database Aurora PostgreSQL, disattivarlo nuovamente per evitare una registrazione eccessiva.logical_decoding_work_mem: specifica la quantità di memoria (in kilobyte) che deve essere utilizzata da ogni buffer di riordino interno prima di essere trasferita su disco. Questa memoria viene utilizzata per la decodifica logica, ovvero il processo per creare una replica. Tale processo viene eseguito convertendo i dati dal file WAL (Write-Ahead Log) nell’output di streaming logico richiesto dal target.Il valore di questo parametro crea un singolo buffer della dimensione specificata per ogni connessione di replica. Per impostazione predefinita, è 65536 KB. Dopo aver riempito questo buffer, l'eccesso viene scritto su disco come un file. Per ridurre al minimo l'attività del disco, puoi impostare il valore di questo parametro su un valore molto più alto di quello di
work_mem.
Questi sono tutti parametri dinamici, quindi puoi modificarli per la sessione corrente. A questo scopo, esegui la connessione al cluster database Aurora PostgreSQL con psql e usando l’istruzione SET, come mostrato di seguito.
SET parameter_name TO parameter_value;Le impostazioni della sessione vengono mantenute solo per la durata della sessione. Quando la sessione scade, l’impostazione del parametro viene ripristinata nel gruppo di parametri cluster database. Prima di modificare qualsiasi parametro, controlla innanzitutto i valori correnti eseguendo una query della tabella pg_settings, come riportato di seguito.
SELECT unit, setting, max_val FROM pg_settings WHERE name='parameter_name';
Ad esempio, per trovare il valore del parametro work_mem, esegui la connessione all'istanza di scrittura del cluster database Aurora PostgreSQL ed esegui la query seguente.
SELECT unit, setting, max_val, pg_size_pretty(max_val::numeric) FROM pg_settings WHERE name='work_mem';unit | setting | max_val | pg_size_pretty ------+----------+-----------+---------------- kB | 1024 | 2147483647| 2048 MB (1 row)
La modifica delle impostazioni dei parametri in modo che vengano mantenuti richiede l'utilizzo di un gruppo di parametri cluster DB personalizzato. Dopo aver provato il cluster database Aurora PostgreSQL con valori diversi per questi parametri utilizzando l’istruzione SET, puoi creare un gruppo di parametri personalizzati e applicarlo al cluster database Aurora PostgreSQL. Per ulteriori informazioni, consulta Gruppi di parametri per Amazon Aurora.
Comprendere il parametro memoria di lavoro
Il parametro memoria di lavoro (work_mem) specifica la quantità massima di memoria utilizzabile da Aurora PostgreSQL per elaborare query complesse. Le query complesse includono quelle che implicano operazioni di ordinamento o raggruppamento, in altre parole, le query che utilizzano le seguenti clausole:
ORDER BY
DISTINCT
GROUP BY
JOIN (MERGE e HASH)
Il pianificatore query influenza indirettamente la modalità di utilizzo della memoria di lavoro nel cluster database Aurora PostgreSQL. Il pianificatore query genera piani di esecuzione per l'elaborazione delle istruzioni SQL. Un piano specifico potrebbe suddividere una query complessa in più unità di lavoro che possono essere eseguite in parallelo. Quando possibile, Aurora PostgreSQL utilizza la quantità di memoria specificata nel parametro work_mem per ogni sessione prima della scrittura su disco per ogni processo parallelo.
Più utenti di database che eseguono più operazioni simultaneamente e generano più unità di lavoro in parallelo possono esaurire la memoria di lavoro allocata del cluster database Aurora PostgreSQL. Ciò può portare alla creazione di un numero eccessivo di file temporanei e di I/O del disco o, peggio, può causare un errore di memoria insufficiente.
Identificazione dell'uso di file temporanei
Ogni volta che la memoria richiesta per l'elaborazione delle query supera il valore specificato nel parametro work_mem, i dati di lavoro vengono scaricati su disco in un file temporaneo. Per visualizzare la frequenza di questo evento, attiva il parametro log_temp_files. Il parametro è disattivato (è impostato su -1) per impostazione predefinita. Per acquisire tutte le informazioni sui file temporanei, imposta questo parametro su 0. Imposta log_temp_files su qualsiasi altro numero intero positivo per acquisire informazioni sui file temporanei per file uguali o superiori a tale quantità di dati (in kilobyte). Nell'immagine seguente, è riportato un esempio da AWS Management Console.
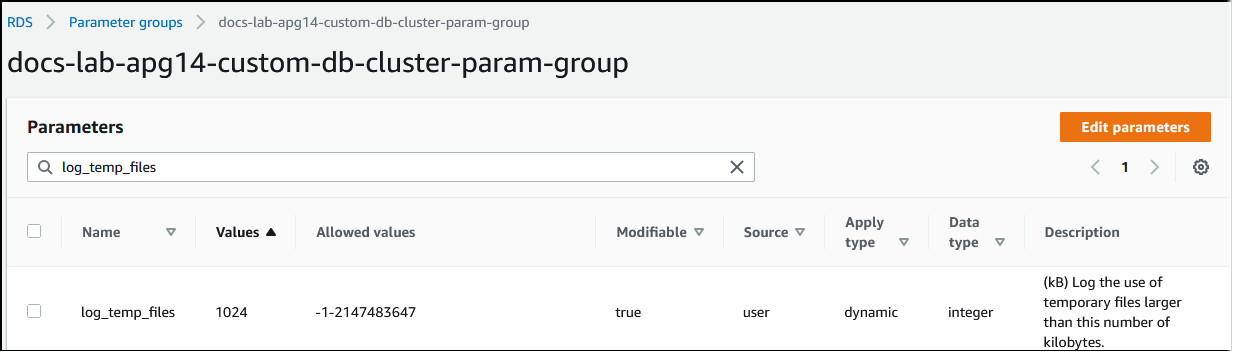
Dopo aver configurato la registrazione dei file temporanei, puoi effettuare un test con il carico di lavoro per vedere se l'impostazione della memoria di lavoro è sufficiente. Puoi anche simulare un carico di lavoro usando pgbench, una semplice applicazione di benchmarking della community PostgreSQL.
L'esempio seguente inizializza (-i) pgbench creando le tabelle e le righe necessarie per eseguire i test. In questo esempio, il fattore di dimensionamento (-s 50) crea 50 righe nella tabella pgbench_branches, 500 righe in pgbench_tellers e 5.000.000 di righe nella tabella pgbench_accounts nel database labdb.
pgbench -U postgres -h your-cluster-instance-1.111122223333.aws-regionrds.amazonaws.com -p 5432 -i -s 50 labdb
Password:
dropping old tables...
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
creating tables...
generating data (client-side)...
5000000 of 5000000 tuples (100%) done (elapsed 15.46 s, remaining 0.00 s)
vacuuming...
creating primary keys...
done in 61.13 s (drop tables 0.08 s, create tables 0.39 s, client-side generate 54.85 s, vacuum 2.30 s, primary keys 3.51 s)Dopo aver inizializzato l'ambiente, puoi eseguire il benchmark per un periodo di tempo specifico (-T) e il numero di client (-c). In questo esempio viene utilizzata anche l’opzione -d per generare informazioni di debug mentre le transazioni vengono elaborate dal cluster database Aurora PostgreSQL.
pgbench -h -U postgresyour-cluster-instance-1.111122223333.aws-regionrds.amazonaws.com -p 5432 -d -T 60 -c 10labdbPassword:*******pgbench (14.3) starting vacuum...end. transaction type: <builtin: TPC-B (sort of)> scaling factor: 50 query mode: simple number of clients: 10 number of threads: 1 duration: 60 s number of transactions actually processed: 1408 latency average = 398.467 ms initial connection time = 4280.846 ms tps = 25.096201 (without initial connection time)
Per ulteriori informazioni su pgbench, consulta pgbench
Puoi usare il metacomando psql (\d) per elencare le relazioni quali tabelle, viste e indici creati da pgbench.
labdb=>\d pgbench_accountsTable "public.pgbench_accounts" Column | Type | Collation | Nullable | Default ----------+---------------+-----------+----------+--------- aid | integer | | not null | bid | integer | | | abalance | integer | | | filler | character(84) | | | Indexes: "pgbench_accounts_pkey" PRIMARY KEY, btree (aid)
Come mostrato nell'output, la tabella pgbench_accounts è indicizzata sulla colonna aid. Per garantire che questa query successiva utilizzi la memoria di lavoro, esegui una query su qualsiasi colonna non indicizzata, come quella mostrata nell'esempio seguente.
postgres=>SELECT * FROM pgbench_accounts ORDER BY bid;
Controlla se il registro contiene file temporanei. A questo scopo, apri la AWS Management Console, scegli l'istanza cluster database Aurora PostgreSQL, quindi seleziona la scheda Registri ed eventi. Visualizza i registri nella console o scaricali per ulteriori analisi. Come mostrato nell'immagine seguente, la dimensione dei file temporanei necessari per elaborare la query indica che è opportuno valutare se aumentare la quantità specificata per il parametro work_mem.
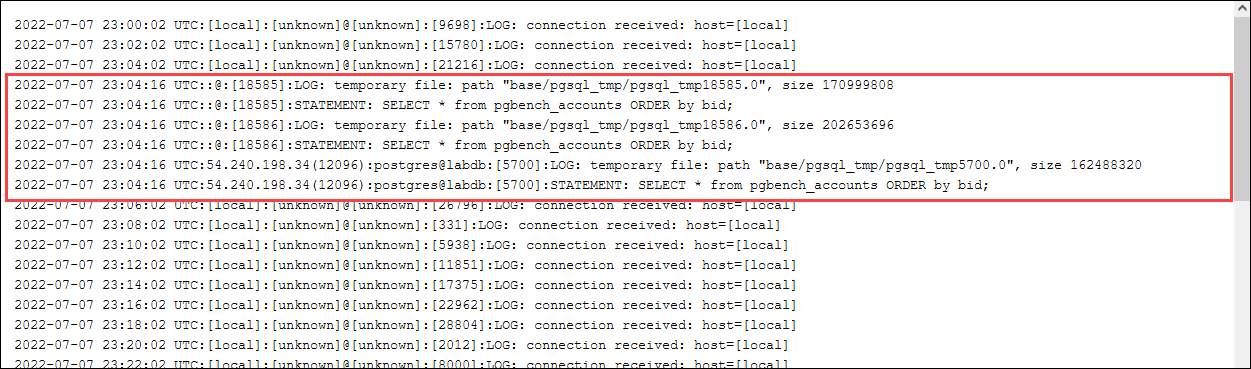
Puoi configurare questo parametro in modo diverso per singoli e gruppi, in base alle esigenze operative. Ad esempio, puoi impostare il parametro work_mem su 8 GB per il ruolo denominato dev_team.
postgres=>ALTER ROLEdev_teamSET work_mem=‘8GB';
Con questa impostazione per work_mem, a qualsiasi ruolo che è un membro del ruolo dev_team sono assegnati fino a 8 GB di memoria di lavoro.
Utilizzo degli indici per tempo di risposta più rapido
Se le query richiedono troppo tempo per restituire i risultati, puoi verificare che l’uso degli indici sia quello previsto. Innanzitutto, attiva \timing, il metacomando psql, come segue.
postgres=>\timing on
Dopo aver attivato la tempistica, utilizza una semplice istruzione SELECT.
postgres=>SELECT COUNT(*) FROM (SELECT * FROM pgbench_accounts ORDER BY bid) AS accounts;count ------- 5000000 (1 row) Time: 3119.049 ms (00:03.119)
Come mostrato nell'output, questa query ha richiesto poco più di 3 secondi per il completamento. Per migliorare il tempo di risposta, crea un indice su pgbench_accounts, come riportato di seguito.
postgres=>CREATE INDEX ON pgbench_accounts(bid);CREATE INDEX
Esegui nuovamente la query e osserva che tempo di risposta è inferiore. In questo esempio, la query è stata completata all’incirca 5 volte più velocemente, in circa mezzo secondo.
postgres=>SELECT COUNT(*) FROM (SELECT * FROM pgbench_accounts ORDER BY bid) AS accounts;count ------- 5000000 (1 row) Time: 567.095 ms
Regolazione della memoria di lavoro per la decodifica logica
La replica logica è disponibile in tutte le versioni di Aurora PostgreSQL sin dalla sua introduzione in PostgreSQL versione 10. Quando si configura la replica logica, è anche possibile impostare il parametro logical_decoding_work_mem per specificare la quantità di memoria utilizzabile dal processo di decodifica logica per il processo di decodifica e streaming.
Durante la decodifica logica, i record WAL (Write-Ahead Log) vengono convertiti in istruzioni SQL che vengono quindi inviate a un'altra destinazione per la replica logica o un'altra attività. Quando una transazione viene scritta nel WAL e quindi convertita, l'intera transazione deve rientrare nel valore specificato per logical_decoding_work_mem. Questo parametro è impostato su 65536 KB per impostazione predefinita. L’eventuale overflow viene scritto su disco. Ciò significa che deve essere riletto dal disco prima di poter essere inviato alla destinazione, rallentando così il processo complessivo.
È possibile valutare l'entità dell’overflow di transazione nel carico di lavoro corrente in un momento specifico utilizzando la funzione aurora_stat_file come mostrato nell'esempio seguente.
SELECT split_part (filename, '/', 2) AS slot_name, count(1) AS num_spill_files, sum(used_bytes) AS slot_total_bytes, pg_size_pretty(sum(used_bytes)) AS slot_total_size FROM aurora_stat_file() WHERE filename like '%spill%' GROUP BY 1;slot_name | num_spill_files | slot_total_bytes | slot_total_size ------------+-----------------+------------------+----------------- slot_name | 590 | 411600000 | 393 MB (1 row)
Questa query restituisce il numero e la dimensione dei file spill sul cluster database Aurora PostgreSQL quando la query viene richiamata. Per i carichi di lavoro a esecuzione più lunga, è possibile che sul disco non siano ancora presenti file spill. Per profilare i carichi di lavoro con esecuzione a lungo termine, è opportuno creare una tabella per acquisire le informazioni sui file spill durante l'esecuzione del carico di lavoro. È possibile creare la tabella come indicato di seguito.
CREATE TABLE spill_file_tracking AS SELECT now() AS spill_time,* FROM aurora_stat_file() WHERE filename LIKE '%spill%';
Per vedere come vengono utilizzati i file spill durante la replica logica, configura un autore e un sottoscrittore e quindi avvia una semplice replica. Per ulteriori informazioni, consulta Configurazione della replica logica per il cluster database Aurora PostgreSQL. Con la replica in corso, puoi creare un processo che acquisisce il set di risultati dalla funzione file spill aurora_stat_file(), come riportato di seguito.
INSERT INTO spill_file_tracking SELECT now(),* FROM aurora_stat_file() WHERE filename LIKE '%spill%';
Usa il seguente comando psql per eseguire il processo una volta al secondo.
\watch 0.5
Mentre il processo è in esecuzione, esegui la connessione all'istanza di scrittura da un'altra sessione psql. Utilizza la seguente serie di istruzioni per eseguire un carico di lavoro che supera la configurazione di memoria e causa la creazione di file spill in Aurora PostgreSQL.
labdb=>CREATE TABLE my_table (a int PRIMARY KEY, b int);CREATE TABLElabdb=>INSERT INTO my_table SELECT x,x FROM generate_series(0,10000000) x;INSERT 0 10000001labdb=>UPDATE my_table SET b=b+1;UPDATE 10000001
Queste istruzioni richiedono diversi minuti per il completamento. Al termine, premi contemporaneamente i tasti Ctrl e C per interrompere la funzione di monitoraggio. Quindi utilizza il seguente comando per creare una tabella che contenga le informazioni relative all'utilizzo dei file spill del cluster database Aurora PostgreSQL.
SELECT spill_time, split_part (filename, '/', 2) AS slot_name, count(1) AS spills, sum(used_bytes) AS slot_total_bytes, pg_size_pretty(sum(used_bytes)) AS slot_total_size FROM spill_file_tracking GROUP BY 1,2 ORDER BY 1;spill_time | slot_name | spills | slot_total_bytes | slot_total_size ------------------------------+-----------------------+--------+------------------+----------------- 2022-04-15 13:42:52.528272+00 | replication_slot_name | 1 | 142352280 | 136 MB 2022-04-15 14:11:33.962216+00 | replication_slot_name | 4 | 467637996 | 446 MB 2022-04-15 14:12:00.997636+00 | replication_slot_name | 4 | 569409176 | 543 MB 2022-04-15 14:12:03.030245+00 | replication_slot_name | 4 | 569409176 | 543 MB 2022-04-15 14:12:05.059761+00 | replication_slot_name | 5 | 618410996 | 590 MB 2022-04-15 14:12:07.22905+00 | replication_slot_name | 5 | 640585316 | 611 MB (6 rows)
L'output mostra che l'esecuzione dell'esempio ha creato cinque file spill che utilizzano 611 MB di memoria. Per evitare di scrivere su disco, è consigliabile impostare il parametro logical_decoding_work_mem per la dimensione di memoria successiva più elevata, 1024.
