Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Filtraggio dei dati per le integrazioni Zero-ETL di
Le integrazioni Zero-ETL di Aurora supportano il filtraggio dei dati, che consente di controllare quali dati vengono replicati dal di origine (cluster Aurora DB) al data warehouse di destinazione. Invece di replicare l'intero database, puoi applicare uno o più filtri per includere o escludere selettivamente tabelle specifiche. Ciò consente di ottimizzare le prestazioni di archiviazione e di interrogazione assicurando che vengano trasferiti solo i dati pertinenti. Attualmente, il filtraggio è limitato ai livelli di database e tabella. Il filtraggio a livello di colonna e riga non è supportato.
Il filtraggio dei dati può essere utile quando si desidera:
-
Unisci determinate tabelle da due o più cluster di di origine diversi e non avrai bisogno di dati completi da nessuno dei due cluster di .
-
Risparmia sui costi eseguendo analisi utilizzando solo un sottoinsieme di tabelle anziché un'intera flotta di database.
-
Filtra le informazioni sensibili, come numeri di telefono, indirizzi o dettagli delle carte di credito, da determinate tabelle.
Puoi aggiungere filtri di dati a un'integrazione zero-ETL utilizzando AWS Management Console, the AWS Command Line Interface (AWS CLI) o l'API Amazon RDS.
Se l'integrazione ha come destinazione un cluster fornito, per utilizzare il filtraggio dei dati è necessario che il cluster utilizzi la patch 180 o una versione successiva.
Argomenti
Formato di un filtro dati
È possibile definire più filtri per una singola integrazione. Ogni filtro include o esclude tutte le tabelle di database esistenti e future che corrispondono a uno dei modelli nell'espressione del filtro. Le integrazioni Zero-ETL di Aurora utilizzano
Ogni filtro ha i seguenti elementi:
| Elemento | Descrizione |
|---|---|
| Tipo di filtro |
Un tipo di |
| Espressione filtro |
Un elenco di modelli separati da virgole. Le espressioni devono utilizzare la sintassi del filtro Maxwell |
| Pattern |
È possibile specificare nomi letterali o definire espressioni regolari. NotaPer Aurora MySQL RDS for MySQL che nel nome della tabella. Per Aurora PostgreSQL RDS per PostgreSQL. Non è possibile includere filtri o denylist a livello di colonna. Una singola integrazione può avere un massimo di 99 pattern totali. Nella console, è possibile inserire modelli all'interno di una singola espressione di filtro o distribuirli tra più espressioni. Un singolo pattern non può superare i 256 caratteri di lunghezza. |
Importante
Se si seleziona un database di origine Aurora PostgreSQL Source DB cluster RDS per PostgreSQL. Come minimo, il modello deve includere un singolo database (database-name.*.*
L'immagine seguente mostra la struttura dei filtri di dati Aurora MySQL RDS per MySQL
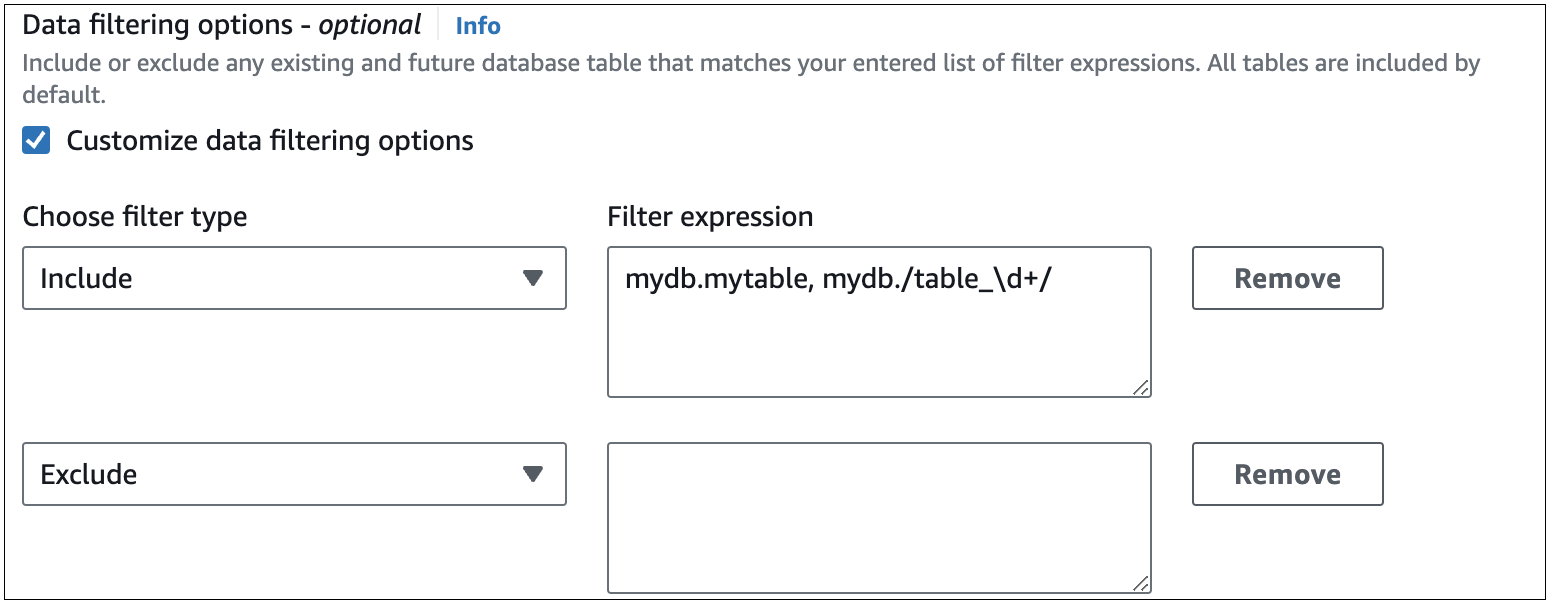
Importante
Non includere informazioni di identificazione personale, riservate o sensibili nei modelli di filtro.
Filtri di dati in AWS CLI
Quando si utilizza AWS CLI per aggiungere un filtro dati, la sintassi è leggermente diversa da quella della console. È necessario assegnare un tipo di filtro (IncludeoExclude) a ciascun pattern singolarmente, in modo da non poter raggruppare più pattern in un unico tipo di filtro.
Ad esempio, nella console è possibile raggruppare i seguenti modelli separati da virgole in un'unica istruzione: Include
mydb.mytable,mydb./table_\d+/
mydb.myschema.mytable,mydb.myschema./table_\d+/
Tuttavia, quando si utilizza il AWS CLI, lo stesso filtro dati deve avere il seguente formato:
'include:mydb.mytable, include:mydb./table_\d+/'
'include:mydb.myschema.mytable, include:mydb.myschema./table_\d+/'
Logica dei filtri
Se non specifichi alcun filtro di dati nella tua integrazione, Aurora presuppone un filtro predefinito include:*.* di, che replica tutte le tabelle nel data warehouse di destinazione. Tuttavia, se aggiungi almeno un filtro, la logica predefinita passa aexclude:*.*, che esclude tutte le tabelle per impostazione predefinita. Ciò consente di definire in modo esplicito quali database e tabelle includere nella replica.
Ad esempio, se si definisce il seguente filtro:
'include: db.table1, include: db.table2'
Aurora valuta il filtro come segue:
'exclude:*.*, include: db.table1, include: db.table2'
Pertanto, Aurora esegue solo table1 table2 repliche dal database db denominato al data warehouse di destinazione.
Precedenza dei filtri
Aurora valuta i filtri di dati nell'ordine specificato. In AWS Management Console, elabora le espressioni di filtro da sinistra a destra e dall'alto verso il basso. Un secondo filtro o un modello individuale che segue il primo può sostituirlo.
Ad esempio, se il primo filtro èInclude books.stephenking, include solo la stephenking tabella del books database. Tuttavia, se si aggiunge un secondo filtroExclude books.*, questo sostituisce il primo filtro. Ciò impedisce che le tabelle dell'booksindice vengano replicate nel data warehouse di destinazione.
Quando si specifica almeno un filtro, la logica parte dal presupposto, per impostazione exclude:*.* predefinita, che esclude automaticamente tutte le tabelle dalla replica. Come procedura ottimale, definisci i filtri dal più ampio al più specifico. Inizia con una o più Include istruzioni per specificare i dati da replicare, quindi aggiungi Exclude filtri per rimuovere selettivamente determinate tabelle.
Lo stesso principio si applica ai filtri definiti utilizzando. AWS CLI Aurora valuta questi modelli di filtro nell'ordine in cui li specifichi, quindi un modello potrebbe sovrascrivere quello specificato in precedenza.
Gli esempi seguenti mostrano come funziona il filtraggio dei dati per Aurora, esempi MySQL, , integrazioni zero-ETL:
-
Includi tutti i database e tutte le tabelle:
'include: *.*' -
Includi tutte le tabelle all'interno del
booksdatabase:'include: books.*' -
Escludi tutte le tabelle denominate
mystery:'include: *.*, exclude: *.mystery' -
Includi due tabelle specifiche all'interno del
booksdatabase:'include: books.stephen_king, include: books.carolyn_keene' -
Includi tutte le tabelle del
booksdatabase, ad eccezione di quelle contenenti la sottostringamystery:'include: books.*, exclude: books./.*mystery.*/' -
Include tutte le tabelle del
booksdatabase, ad eccezione di quelle che iniziano conmystery:'include: books.*, exclude: books./mystery.*/' -
Include tutte le tabelle del
booksdatabase, ad eccezione di quelle che terminano conmystery:'include: books.*, exclude: books./.*mystery/' -
Include tutte le tabelle del
booksdatabase che iniziano contable_, ad eccezione di quella denominatatable_stephen_king. Ad esempio,table_moviesotable_booksverrebbe replicato, ma nontable_stephen_king.'include: books./table_.*/, exclude: books.table_stephen_king'
Gli esempi seguenti mostrano come funziona il filtraggio dei dati per le integrazioni Aurora PostgreSQL RDS per
-
booksIncludi tutte le tabelle all'interno del database:'include: books.*.*' -
Escludi tutte le tabelle denominate
mysterynelbooksdatabase:'include: books.*.*, exclude: books.*.mystery' -
Includi una tabella all'interno del
booksdatabase nellomysteryschema e una tabella all'interno delemployeedatabase nellofinanceschema:'include: books.mystery.stephen_king, include: employee.finance.benefits' -
Includi tutte le tabelle del
booksdatabase escience_fictiondello schema, ad eccezione di quelle contenenti la sottostringaking:'include: books.science_fiction.*, exclude: books.*./.*king.*/ -
Include tutte le tabelle del
booksdatabase, ad eccezione di quelle con un nome di schema che inizia consci:'include: books.*.*, exclude: books./sci.*/.*' -
Include tutte le tabelle del
booksdatabase, ad eccezione di quelle dellomysteryschema che termina conking:'include: books.*.*, exclude: books.mystery./.*king/' -
Include tutte le tabelle del
booksdatabase che iniziano contable_, ad eccezione di quella denominatatable_stephen_king. Ad esempio,table_moviesnellofictionschema etable_booksnellomysteryschema vengono replicati, ma nontable_stephen_kingin nessuno dei due schemi:'include: books.*./table_.*/, exclude: books.*.table_stephen_king'
Aggiungere filtri di dati a un'integrazione
Puoi configurare il filtraggio dei dati utilizzando AWS Management Console l'API AWS CLI Amazon RDS o la.
Importante
Se aggiungi un filtro dopo aver creato un'integrazione, Aurora lo considera come se fosse sempre esistito. Rimuove tutti i dati nel data warehouse di destinazione che non corrispondono ai nuovi criteri di filtro e risincronizza tutte le tabelle interessate.
Per aggiungere filtri di dati a un'integrazione zero-ETL
Accedi a AWS Management Console e apri la console Amazon RDS all'indirizzo https://console.aws.amazon.com/rds/
. -
Nel pannello di navigazione, scegli Integrazioni zero-ETL. Seleziona l'integrazione a cui desideri aggiungere filtri di dati, quindi scegli Modifica.
-
In Source, aggiungi una o più
ExcludeistruzioniIncludee.L'immagine seguente mostra un esempio di filtri di dati per un'integrazione MySQL:
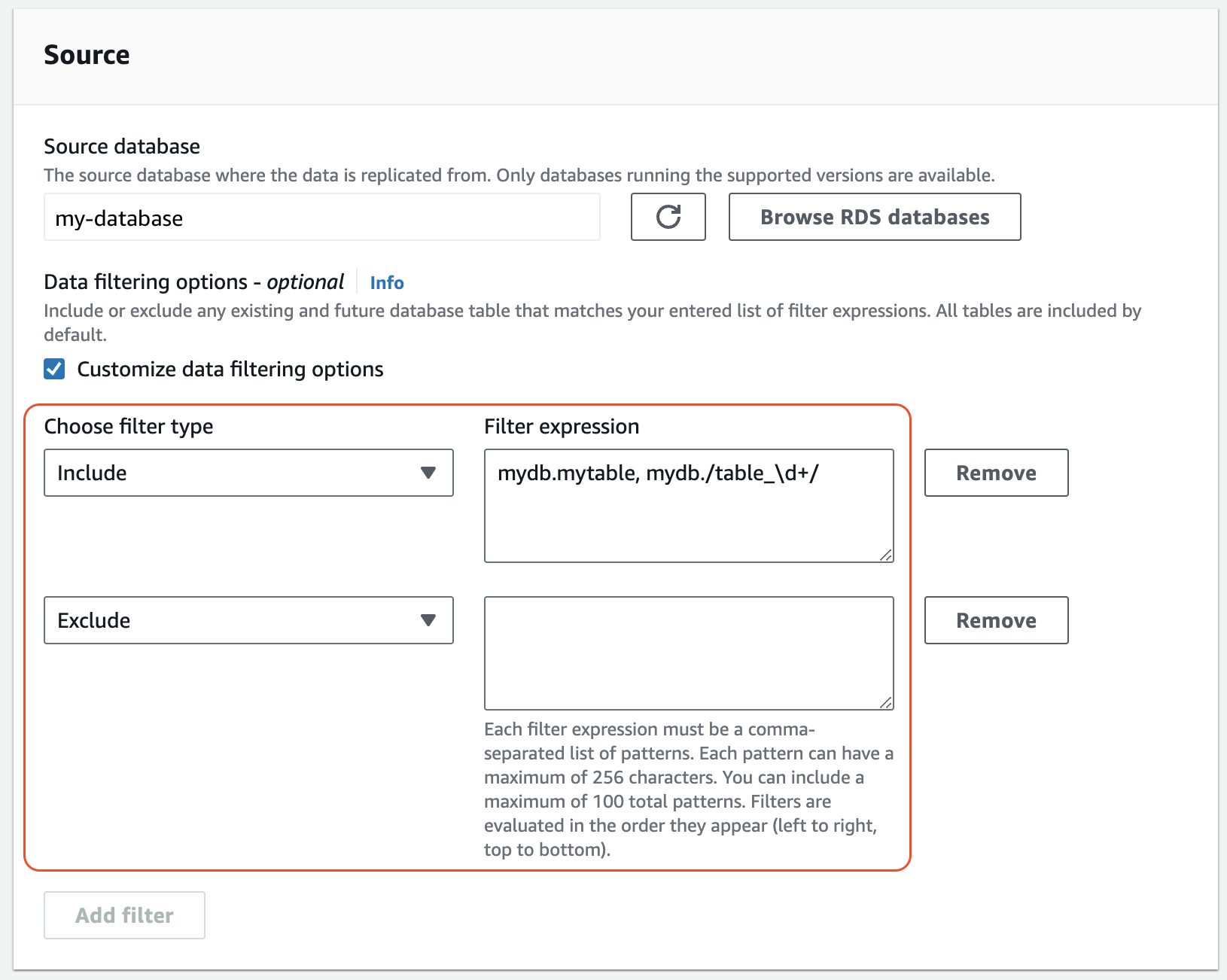
-
Quando sei soddisfatto delle modifiche, scegli Continua e salva le modifiche.
Per aggiungere filtri di dati a un'integrazione zero-ETL utilizzando AWS CLI, chiama il comando modify-integration.--data-filter parametro con un elenco separato da virgole di filtri Maxwell. Include Exclude
L'esempio seguente aggiunge modelli di filtro a. my-integration
Per LinuxmacOS, oUnix:
aws rds modify-integration \ --integration-identifiermy-integration\ --data-filter'include: foodb.*, exclude: foodb.tbl, exclude: foodb./table_\d+/'
Per Windows:
aws rds modify-integration ^ --integration-identifiermy-integration^ --data-filter'include: foodb.*, exclude: foodb.tbl, exclude: foodb./table_\d+/'
Per modificare un'integrazione zero-ETL utilizzando l'API RDS, chiama l'operazione. ModifyIntegration Specificate l'identificatore di integrazione e fornite un elenco di modelli di filtro separati da virgole.
Rimozione dei filtri di dati da un'integrazione
Quando rimuovi un filtro dati da un'integrazione, Aurora rivaluta i filtri rimanenti come se il filtro rimosso non fosse mai esistito. Quindi replica tutti i dati precedentemente esclusi che ora soddisfano i criteri nel data warehouse di destinazione. Ciò attiva una risincronizzazione di tutte le tabelle interessate.
