Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Progettazione dello schema del profilo di gioco in DynamoDB
Caso d'uso aziendale profilo di gioco
In questo caso d'uso viene descritto l'utilizzo di DynamoDB per archiviare i profili dei giocatori per un sistema di gioco. Gli utenti (in questo caso, i giocatori) devono creare profili prima di poter interagire con molti giochi moderni, in particolare quelli online. I profili di gioco includono in genere i seguenti:
-
Informazioni di base come il nome utente
-
Dati di gioco come elementi e apparecchiature
-
Record di gioco come operazioni e attività
-
Informazioni social come elenchi di amici
Per soddisfare i requisiti granulari di accesso alle query di dati per questa applicazione, le chiavi primarie (chiave di partizione e chiave di ordinamento) utilizzeranno nomi generici (PK e SK) in modo da poter essere sovraccaricate con vari tipi di valori, come descritto di seguito.
I modelli di accesso per questa progettazione dello schema sono:
-
Ottenere l'elenco di amici di un utente
-
Ottenere tutte le informazioni di un giocatore
-
Ottenere l'elenco di elementi di un utente
-
Ottenere un elemento specifico dall'elenco di elementi dell'utente
-
Aggiornare il personaggio di un utente
-
Aggiornare il conteggio elementi per un utente
Le dimensioni del profilo di gioco possono variare in base ai giochi. La compressione di valori di attributi large permette la loro archiviazione nei limiti degli elementi in DynamoDB, riducendo così i costi. La strategia di gestione della velocità di trasmissione effettiva dipende da vari fattori quali: il numero di giocatori, il numero di partite giocate al secondo e la stagionalità del carico di lavoro. In genere, per un gioco appena lanciato, il numero di giocatori e il livello di popolarità sono sconosciuti, pertanto inizieremo con la modalità di velocità di trasmissione effettiva on demand.
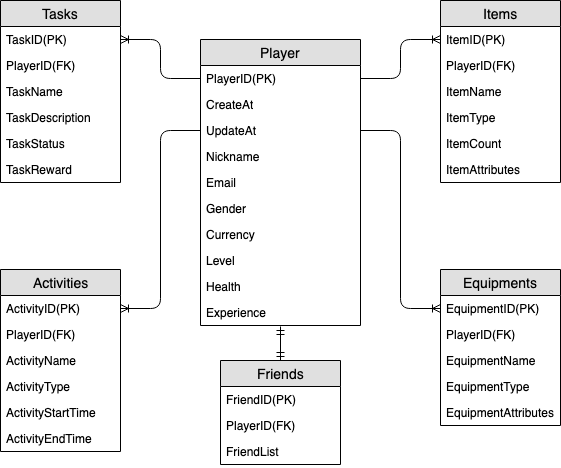
Diagramma delle relazioni tra entità del profilo di gioco
Questo è il diagramma delle relazioni tra entità (ERD) utilizzato per la progettazione dello schema del profilo di gioco.
Modelli di accesso del profilo di gioco
Questi sono i modelli di accesso che creeremo per la progettazione dello schema di social network.
-
getPlayerFriends -
getPlayerAllProfile -
getPlayerAllItems -
getPlayerSpecificItem -
updateCharacterAttributes -
updateItemCount
Evoluzione della progettazione dello schema del profilo di gioco
Dall'ERD precedente, possiamo vedere che si tratta di un tipo di one-to-many relazione di modellazione dei dati. In DynamoDB one-to-many, i modelli di dati possono essere organizzati in raccolte di elementi, il che è diverso dai tradizionali database relazionali in cui vengono create più tabelle e collegate tramite chiavi esterne. Una raccolta di elementi è un gruppo di elementi che condividono lo stesso valore della chiave di partizione ma hanno valori di chiave di ordinamento differenti. All'interno di una raccolta di elementi, ogni elemento dispone di un valore di chiave di ordinamento univoco che lo distingue dagli altri elementi. Tenendo questo a mente, utilizziamo il modello seguente per i valori HASH e RANGE per ogni tipo di entità.
Per iniziare, utilizziamo nomi generici come PK e SK per archiviare diversi tipi di entità nella stessa tabella in modo da rendere il modello orientato al futuro. Per una migliore leggibilità, possiamo includere prefissi per indicare il tipo di dati o includere un attributo arbitrario chiamato Entity_type o Type. Nell'esempio corrente, utilizziamo una stringa che inizia con player per archiviare player_ID come PK; utilizziamo entity name# come il prefisso di SK e aggiungiamo un attributo Type per indicare il tipo di entità di questo dato. Questo consente di supportare l'archiviazione di più tipi di entità in futuro e di utilizzare tecnologie avanzate come Overload di GSI e GSI Sparse per soddisfare più modelli di accesso.
Iniziamo implementando i modelli di accesso. I modelli di accesso come l'aggiunta di giocatori e l'aggiunta di apparecchiature possono essere realizzati tramite l'operazione PutItem, pertanto possiamo ignorarli. In questo documento ci concentreremo sui modelli di accesso tipici elencati in precedenza.
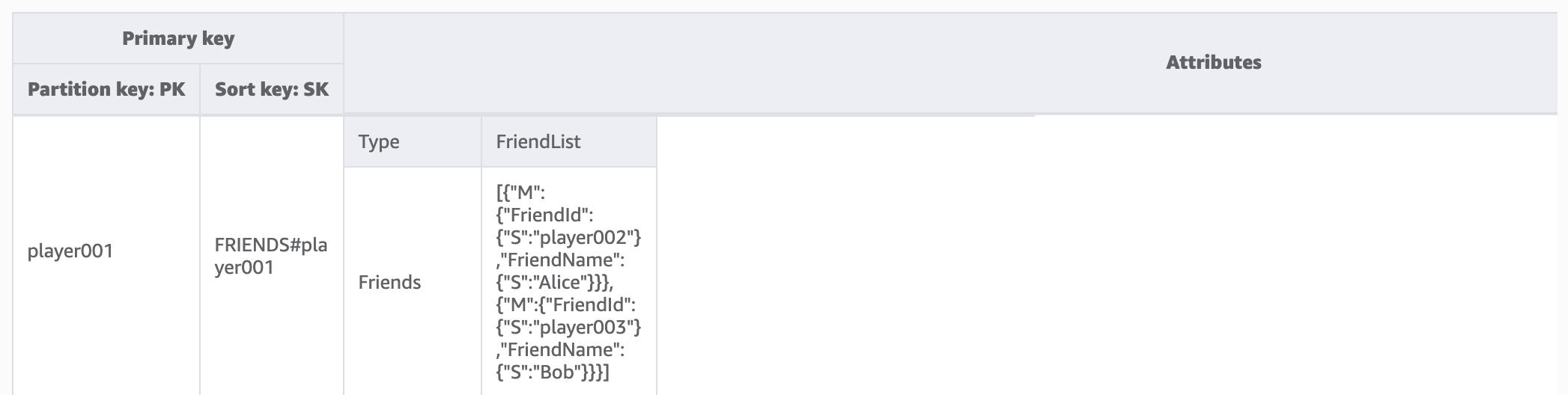
Fase 1: Gestire il modello di accesso 1 (getPlayerFriends)
Gestiamo il modello di accesso 1 (getPlayerFriends) con questa fase. Nella progettazione attuale, l'amicizia è semplice e il numero di amici nel gioco è limitato. Per semplicità, utilizziamo un tipo di dati di elenco per archiviare gli elenchi di amici (modellazione 1:1). In questa progettazione, utilizziamo GetItem per soddisfare questo modello di accesso. Nell'operazione GetItem, forniamo esplicitamente il valore della chiave di partizione e della chiave di ordinamento per ottenere un elemento specifico.
Tuttavia, se un gioco ha un gran numero di amici e le relazioni tra loro sono complesse (ad esempio le amicizie sono bidirezionali con una componente di invito e una di accettazione), sarebbe necessario utilizzare una many-to-many relazione per memorizzare ogni amico individualmente, in modo da scalare fino a una dimensione illimitata della lista di amici. E se il cambio di amicizia implica operare su più elementi contemporaneamente, le transazioni DynamoDB possono essere utilizzate per raggruppare più azioni e inviarle come un' all-or-nothingTransactWriteItemsunica operazione. TransactGetItems
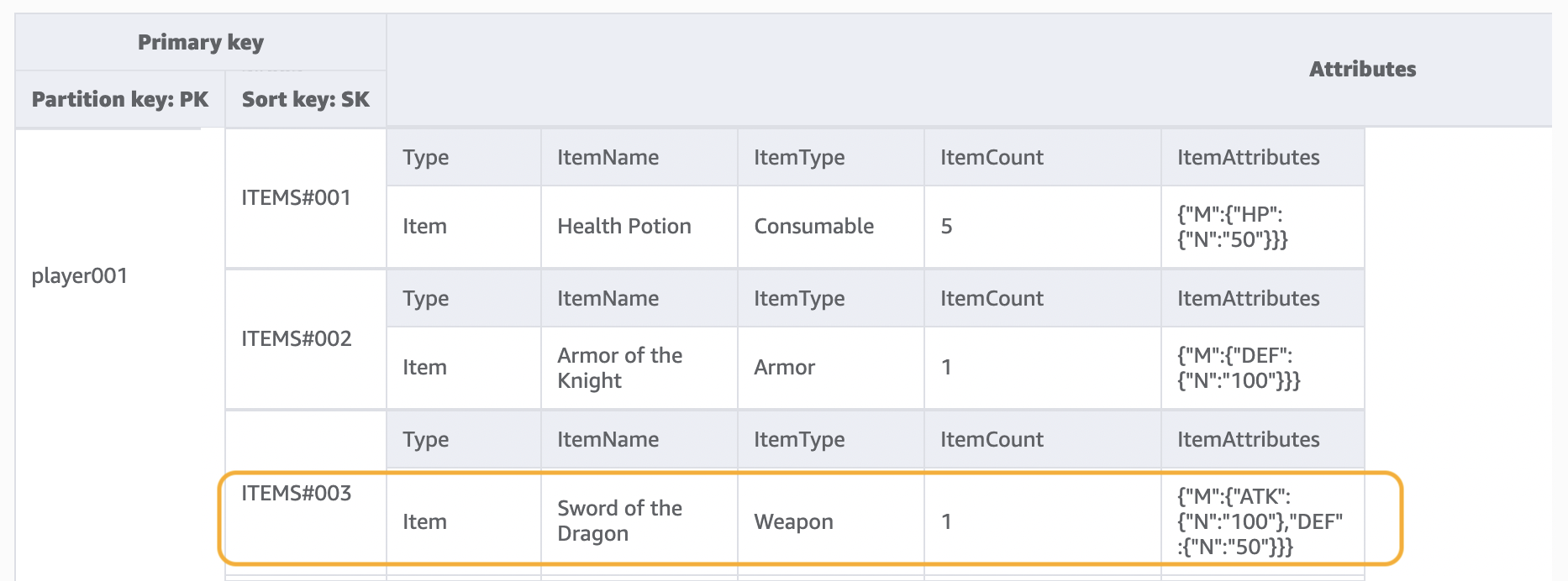
Fase 2: Gestire i modelli di accesso 2 (getPlayerAllProfile), 3 (getPlayerAllItems) e 4 (getPlayerSpecificItem)
Usiamo questa fase per gestire i modelli di accesso 2 (getPlayerAllProfile), 3 (getPlayerAllItems) e 4 (getPlayerSpecificItem). Ciò che accomuna questi tre modelli di accesso è una query di intervallo che utilizza l'operazione Query. A seconda dell'ambito della query, vengono usate Condizione chiave ed Espressioni filtro, comunemente utilizzate nello sviluppo pratico.
Nell'operazione Query, forniamo un singolo valore per Partition Key e otteniamo tutti gli elementi con tale valore Partition Key. Il modello di accesso 2 (getPlayerAllProfile) è implementato in questo modo. Facoltativamente, possiamo aggiungere un'espressione di condizione della chiave di ordinamento, ovvero una stringa che determina gli elementi da leggere dalla tabella. Il modello di accesso 3 (getPlayerAllItems) viene implementato aggiungendo la chiave di condizione della chiave di ordinamento begins_with ITEMS#. Inoltre, al fine di semplificare lo sviluppo del lato applicativo, possiamo utilizzare le espressioni di filtro per implementare il modello di accesso 4 (getPlayerSpecificItem).
Di seguito è riportato un esempio di pseudocodice che utilizza un'espressione di filtro che filtra gli elementi della categoria Weapon:
filterExpression: "ItemType = :itemType" expressionAttributeValues: {":itemType": "Weapon"}
Nota
Un'espressione di filtro viene applicata al termine di un'operazione Query, ma prima che i risultati vengano restituiti al client. Pertanto, una Query consuma la stessa quantità di capacità in lettura, a prescindere che sia presente un'espressione di filtro.
Se il modello di accesso consiste nell'eseguire query di un set di dati di grandi dimensioni e filtrare una grande quantità di dati per conservare solo un piccolo sottoinsieme di dati, l'approccio appropriato è progettare la Partition Key e la chiave di ordinamento DynamoDB in modo più efficace. Nell'esempio precedente, per ottenere un determinato ItemType, se sono presenti molti oggetti per ciascun giocatore e la richiesta di un determinato ItemType è un modello di accesso tipico, sarebbe più efficiente inserire ItemType in SK come una chiave composita. L'aspetto del modello di dati è simile a: ITEMS#ItemType#ItemId.
Fase 3: Gestire i modelli di accesso 5 (updateCharacterAttributes) e 6 (updateItemCount)
Utilizziamo questa fase per gestire i modelli di accesso 5 (updateCharacterAttributes) e 6 (updateItemCount). Quando il giocatore deve modificare il personaggio, ad esempio riducendo la valuta o modificando la quantità di una determinata arma nei suoi elementi, utilizza UpdateItem per implementare questi modelli di accesso. Per aggiornare la valuta di un giocatore ma garantire che non scenda mai al di sotto di un importo minimo, possiamo aggiungere Esempio CLI di espressione di condizione DynamoDB per ridurre il saldo solo se è maggiore o uguale all'importo minimo. Di seguito è riportato un esempio di pseudocodice:
UpdateExpression: "SET currency = currency - :amount" ConditionExpression: "currency >= :minAmount"

Durante lo sviluppo con DynamoDB e l'utilizzo di contatori atomici per diminuire l'inventario, possiamo garantire l'idempotenza utilizzando il blocco ottimistico. Di seguito è riportato un esempio di pseudocodice per contatori atomici:
UpdateExpression: "SET ItemCount = ItemCount - :incr" expression-attribute-values: '{":incr":{"N":"1"}}'

Inoltre, in uno scenario in cui il giocatore acquista un elemento con valuta, l'intero processo deve detrarre la valuta e aggiungere contemporaneamente un elemento. Possiamo utilizzare DynamoDB Transactions per raggruppare più azioni e inviarle come singola all-or-nothing TransactWriteItems operazione. TransactGetItems TransactWriteItemsè un'operazione di scrittura sincrona e idempotente che raggruppa fino a 100 azioni di scrittura in un'unica operazione. all-or-nothing Le operazioni vengono completate in modo atomico, in maniera tale che abbiano tutte esito positivo oppure abbiano tutte esito negativo. Le transazioni consentono di eliminare il rischio di duplicazione o di scomparsa della valuta. Per ulteriori informazioni sulle transazioni, consulta Esempio di transazioni di DynamoDB.
Tutti i modelli di accesso e il modo in cui la progettazione dello schema li affronta sono riassunti nella tabella seguente:
| Modello di accesso | table/GSI/LSI Base | Operazione | Valore della chiave di partizione | Valore della chiave di ordinamento | Altre condizioni/filtri |
|---|---|---|---|---|---|
| getPlayerFriends | Tabella di base | GetItem | PK=PlayerID | SK=“FRIENDS#playerID” | |
| ProfilogetPlayerAll | Tabella di base | Query | PK=PlayerID | ||
| getPlayerAllOggetti | Tabella di base | Query | PK=PlayerID | SK begins_with “ITEMS#” | |
| getPlayerSpecificOggetto | Tabella di base | Query | PK=PlayerID | SK begins_with “ITEMS#” | FilterExpression: "ItemType =:itemType»: {«:itemType» expressionAttributeValues: «Arma»} |
| updateCharacterAttributes | Tabella di base | UpdateItem | PK=PlayerID | SK=“#METADATA#playerID” | UpdateExpression: «SET currency = currency -:amount»: «valuta >=:minAmount» ConditionExpression |
| updateItemCount | Tabella di base | UpdateItem | PK=PlayerID | SK =“ITEMS#ItemID” | espressione di aggiornamento: «SET ItemCount = ItemCount -:incr»: '{» :incr» expression-attribute-values: {"N» :"1"}}' |
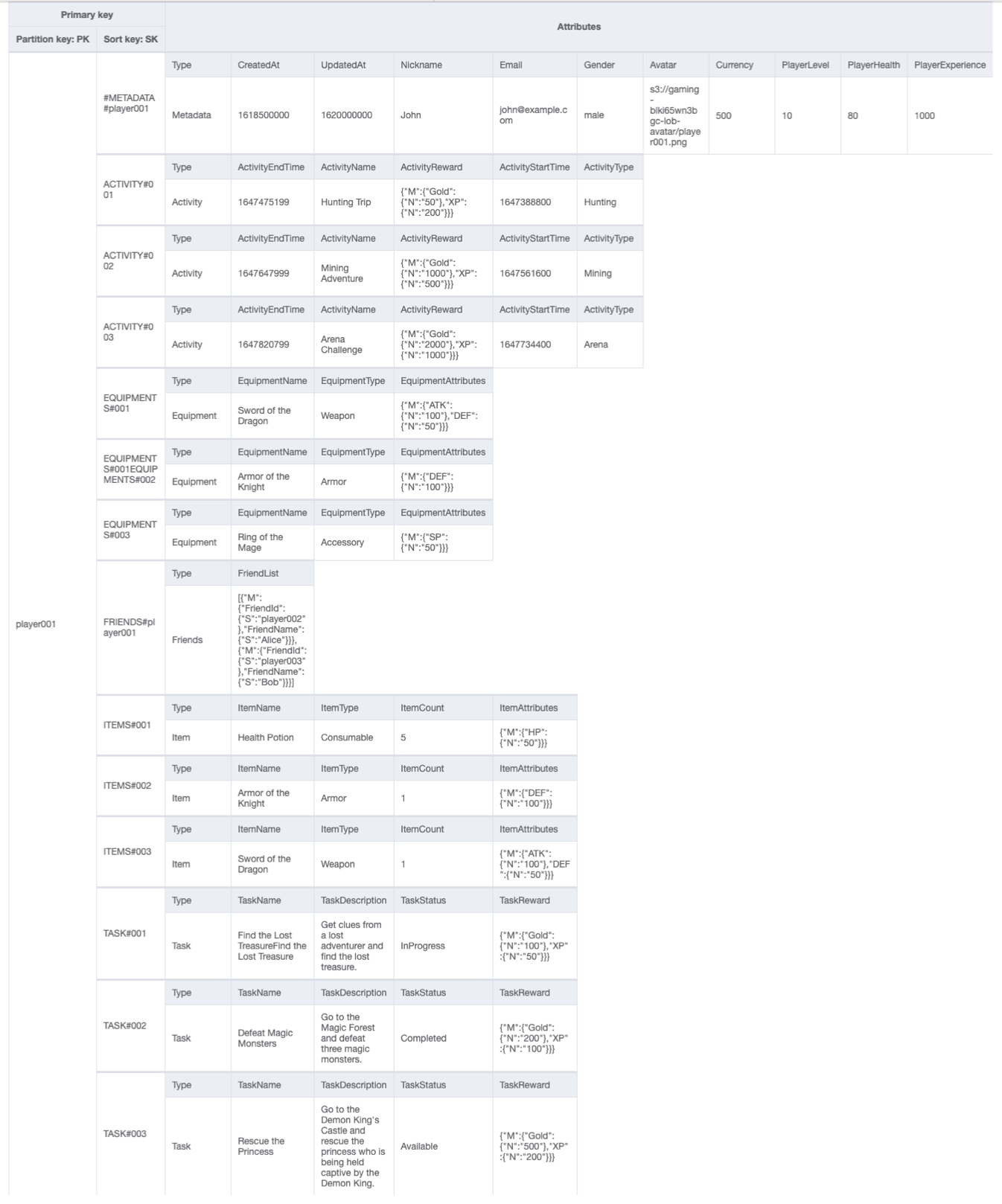
Schema finale del profilo di gioco
Di seguito è riportata la progettazione dello schema finale. Per scaricare questo schema come file JSON, consulta Esempi di DynamoDB
Tabella di base:
Utilizzo di NoSQL Workbench con questa progettazione dello schema
Puoi importare questo schema finale in NoSQL Workbench, uno strumento visivo che fornisce funzionalità di modellazione dei dati, visualizzazione dei dati e sviluppo di query per DynamoDB, per esplorare e modificare ulteriormente il tuo nuovo progetto. Per iniziare, segui queste fasi:
-
Scarica NoSQL Workbench. Per ulteriori informazioni, consulta Download di NoSQL Workbench per DynamoDB.
-
Scarica il file dello schema JSON elencato in precedenza, che si trova già nel formato del modello NoSQL Workbench.
-
Importa il file dello schema JSON in NoSQL Workbench. Per ulteriori informazioni, consulta Importazione di un modello di dati esistente.
-
Dopo che è stato importato in NOSQL Workbench, puoi modificare il modello di dati. Per ulteriori informazioni, consulta Modifica di un modello di dati esistente.
-
Per visualizzare il tuo modello di dati, aggiungere dati di esempio o importare dati di esempio da un file CSV, utilizza la funzionalità Data Visualizer di NoSQL Workbench.
