Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Piano di controllo EKS
Amazon Elastic Kubernetes Service (EKS) è un servizio Kubernetes gestito che semplifica l'esecuzione di Kubernetes su AWS senza dover installare, utilizzare e mantenere il proprio piano di controllo Kubernetes o nodi di lavoro. Funziona a upstream di Kubernetes ed è certificato conforme a Kubernetes. Questa conformità garantisce che EKS supporti Kubernetes, proprio come la versione della community open source che puoi installare in locale o in APIs locale. EC2 Le applicazioni esistenti in esecuzione su Kubernetes upstream sono compatibili con Amazon EKS.
EKS gestisce automaticamente la disponibilità e la scalabilità dei nodi del piano di controllo Kubernetes e sostituisce automaticamente i nodi del piano di controllo non integri.
Architettura EKS
L'architettura EKS è progettata per eliminare ogni singolo punto di errore che possa compromettere la disponibilità e la durabilità del piano di controllo Kubernetes.
Il piano di controllo Kubernetes gestito da EKS funziona all'interno di un VPC gestito da EKS. Il piano di controllo EKS comprende i nodi del server dell'API Kubernetes, il cluster ecc. Nodi server API Kubernetes che eseguono componenti come il server API, lo scheduler e vengono eseguiti kube-controller-manager in un gruppo di auto-scaling. EKS esegue un minimo di due nodi server API in zone di disponibilità distinte (AZs) all'interno della regione AWS. Allo stesso modo, per motivi di durabilità, i nodi del server etcd funzionano anche in un gruppo di auto-scaling che si estende su tre. AZs EKS esegue un gateway NAT in ogni AZ, mentre i server API e i server etcd vengono eseguiti in una sottorete privata. Questa architettura garantisce che un evento in una singola AZ non influisca sulla disponibilità del cluster EKS.
Quando crei un nuovo cluster, Amazon EKS crea un endpoint ad alta disponibilità per il server API Kubernetes gestito che usi per comunicare con il cluster (utilizzando strumenti come). kubectl L'endpoint gestito utilizza NLB per bilanciare il carico dei server API Kubernetes. EKS fornisce anche due ENI diversi AZs per facilitare la comunicazione con i nodi di lavoro.
Connettività di rete EKS Data Plane
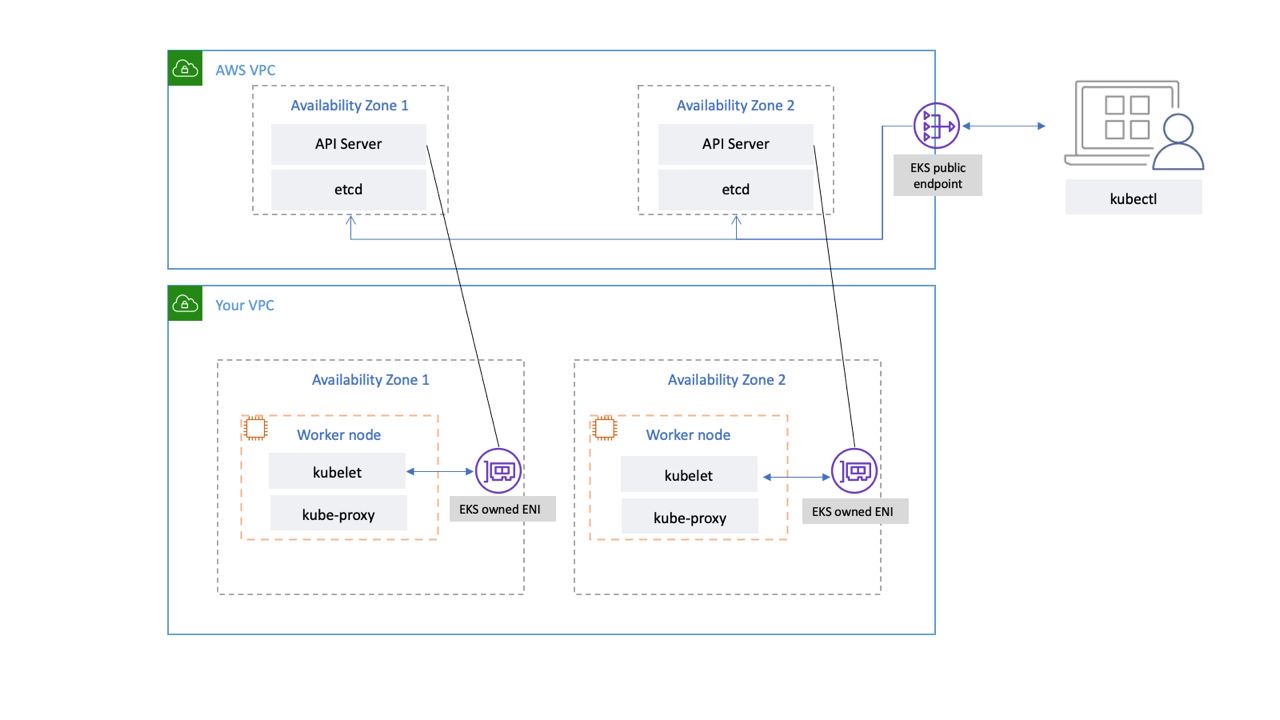
Puoi configurare se il server API del tuo cluster Kubernetes è raggiungibile dalla rete Internet pubblica (utilizzando l'endpoint pubblico) o tramite il tuo VPC (utilizzando EKS-Managed) o entrambi. ENIs
Indipendentemente dal fatto che utenti e nodi di lavoro si connettano al server API utilizzando l'endpoint pubblico o l'ENI gestito da EKS, esistono percorsi di connessione ridondanti.
Raccomandazioni
Esamina i seguenti consigli.
Monitora le metriche del piano di controllo
Il monitoraggio delle metriche dell'API Kubernetes può fornirti informazioni dettagliate sulle prestazioni del piano di controllo e identificare i problemi. Un piano di controllo non integro può compromettere la disponibilità dei carichi di lavoro in esecuzione all'interno del cluster. Ad esempio, controller scritti in modo errato possono sovraccaricare i server API, influendo sulla disponibilità dell'applicazione.
Kubernetes espone le metriche del piano di controllo sull'endpoint. /metrics
Puoi visualizzare le metriche esposte utilizzando: kubectl
kubectl get --raw /metrics
Queste metriche sono rappresentate in un formato di testo Prometheus.
Puoi usare Prometheus per raccogliere e archiviare queste metriche. A maggio 2020, è CloudWatch stato aggiunto il supporto per il monitoraggio delle metriche di Prometheus in Container Insights. CloudWatch Quindi puoi usare Amazon anche CloudWatch per monitorare il piano di controllo EKS. Puoi utilizzare Tutorial for Adding a New Prometheus Scrape Target: Prometheus KPI Server Metrics per raccogliere metriche e creare dashboard per monitorare il piano di controllo del cluster. CloudWatch
Puoi trovare le metriche del server dell'API Kubernetes qui.apiserver_request_duration_seconds può indicare quanto tempo impiegano le richieste API per l'esecuzione.
Prendi in considerazione il monitoraggio di queste metriche del piano di controllo:
Server API
| Parametro | Descrizione |
|---|---|
|
|
Contatore di richieste apiserver suddiviso per ogni verbo, valore di dry run, gruppo, versione, risorsa, ambito, componente e codice di risposta HTTP. |
|
|
Distribuzione della latenza di risposta in secondi per ogni verbo, valore dry run, gruppo, versione, risorsa, sottorisorsa, ambito e componente. |
|
|
Istogramma della latenza del controller di ammissione in secondi, identificato per nome e suddiviso per ogni operazione e risorsa e tipo di API (convalida o ammissione). |
|
|
Numero di accessi respinti dal webhook. Identificato per nome, operazione, rejection_code, tipo (validazione o ammissione), error_type (calling_webhook_error, apiserver_internal_error, no_error) |
|
|
Latenza della richiesta in secondi. Suddiviso per verbo e URL. |
|
|
Numero di richieste HTTP, partizionate per codice di stato, metodo e host. |
ecc.
| Parametro | Descrizione |
|---|---|
|
|
Latenza della richiesta Etcd in secondi per ogni operazione e tipo di oggetto. |
|
|
Dimensioni del database Etcd. |
Prendi in considerazione l'utilizzo della Kubernetes Monitoring Overview Dashboard
La seguente query Prometheus può essere utilizzata per monitorare la dimensione corrente di etcd. La query presuppone che sia richiesto un processo kube-apiserver per l'acquisizione delle metriche dall'endpoint API Metrics e che la versione EKS sia precedente alla v1.26.
max(etcd_db_total_size_in_bytes{job="kube-apiserver"} / (8 * 1024 * 1024 * 1024))
Importante
Quando il limite di dimensione del database viene superato, etcd emette un avviso di assenza di spazio e smette di accettare ulteriori richieste di scrittura. In altre parole, il cluster diventa di sola lettura e tutte le richieste di modifica degli oggetti, come la creazione di nuovi pod, la scalabilità delle distribuzioni, ecc., verranno rifiutate dal server API del cluster.
Autenticazione del cluster
EKS attualmente supporta due tipi di autenticazione: token di account bearer/service e autenticazione IAM che utilizza l'autenticazione tramite token
L'utente o il ruolo IAM che crea il cluster EKS ottiene automaticamente l'accesso completo al cluster. Puoi gestire l'accesso al cluster EKS modificando la configmap di aws-auth.
Se configuri male la aws-auth configmap e perdi l'accesso al cluster, puoi comunque utilizzare l'utente o il ruolo del creatore del cluster per accedere al tuo cluster EKS.
Nell'improbabile eventualità che non sia possibile utilizzare il servizio IAM nella regione AWS, è possibile utilizzare anche il token bearer dell'account del servizio Kubernetes per gestire il cluster.
Crea un super-admin account autorizzato a eseguire tutte le azioni nel cluster:
kubectl -n kube-system create serviceaccount super-admin
Crea un'associazione di ruoli che assegna il ruolo super-admin cluster-admin:
kubectl create clusterrolebinding super-admin-rb --clusterrole=cluster-admin --serviceaccount=kube-system:super-admin
Ottieni il segreto dell'account di servizio:
SECRET_NAME=`kubectl -n kube-system get serviceaccount/super-admin -o jsonpath='{.secrets[0].name}'`
Ottieni il token associato al segreto:
TOKEN=`kubectl -n kube-system get secret $SECRET_NAME -o jsonpath='{.data.token}'| base64 --decode`
Aggiungi l'account e il token di servizio akubeconfig:
kubectl config set-credentials super-admin --token=$TOKEN
Imposta il contesto corrente kubeconfig per utilizzare l'account super-admin:
kubectl config set-context --current --user=super-admin
La finale dovrebbe kubeconfig assomigliare a questa:
apiVersion: v1 clusters: - cluster: certificate-authority-data:<REDACTED> server: https://<CLUSTER>.gr7.us-west-2.eks.amazonaws.com name: arn:aws:eks:us-west-2:<account number>:cluster/<cluster name> contexts: - context: cluster: arn:aws:eks:us-west-2:<account number>:cluster/<cluster name> user: super-admin name: arn:aws:eks:us-west-2:<account number>:cluster/<cluster name> current-context: arn:aws:eks:us-west-2:<account number>:cluster/<cluster name> kind: Config preferences: {} users: #- name: arn:aws:eks:us-west-2:<account number>:cluster/<cluster name> # user: # exec: # apiVersion: client.authentication.k8s.io/v1alpha1 # args: # - --region # - us-west-2 # - eks # - get-token # - --cluster-name # - <<cluster name>> # command: aws # env: null - name: super-admin user: token: <<super-admin sa's secret>>
Webhook di ammissione
Kubernetes offre due tipi di webhook di ammissione: webhook di ammissione convalidanti
Per evitare di influire sulle operazioni critiche del cluster, evita di impostare webhook «catch-all» come i seguenti:
- name: "pod-policy.example.com" rules: - apiGroups: ["*"] apiVersions: ["*"] operations: ["*"] resources: ["*"] scope: "*"
In alternativa, assicurati che il webhook abbia una policy di fail-open con un timeout inferiore a 30 secondi per assicurarti che, se il webhook non è disponibile, non comprometta i carichi di lavoro critici del cluster.
Blocca i pod con unsafe sysctls
Sysctlè un'utilità Linux che consente agli utenti di modificare i parametri del kernel durante l'esecuzione. Questi parametri del kernel controllano vari aspetti del comportamento del sistema operativo, come la rete, il file system, la memoria virtuale e la gestione dei processi.
Kubernetes consente di sysctl assegnare profili per i Pod. Kubernetes si classifica come sicuro e non sicuro. systcls sysctlsI namespace sono sicuri nel contenitore o nel Pod e la loro impostazione non influisce sugli altri Pod sul nodo o sul nodo stesso. Al contrario, i sysctls non sicuri sono disabilitati per impostazione predefinita poiché possono potenzialmente interrompere altri Pod o rendere instabile il nodo.
Poiché gli unsafe sysctls sono disabilitati per impostazione predefinita, il kubelet non creerà un Pod con un profilo non sicuro. sysctl Se crei un Pod di questo tipo, lo scheduler assegnerà ripetutamente tali Pod ai nodi, mentre il nodo non riesce ad avviarlo. Questo ciclo infinito alla fine mette a dura prova il piano di controllo del cluster, rendendolo instabile.
Prendi in considerazione l'utilizzo di OPA Gatekeepersysctls
Gestione degli aggiornamenti del cluster
Da aprile 2021, il ciclo di rilascio di Kubernetes è stato modificato da quattro versioni all'anno (una volta al trimestre) a tre versioni all'anno. Una nuova versione secondaria (come 1. 21 o 1. 22) viene rilasciato all'incirca ogni quindici settimane.
Connettività degli endpoint del cluster
Quando lavori con Amazon EKS (Elastic Kubernetes Service), potresti riscontrare timeout o errori di connessione durante eventi come il ridimensionamento o l'applicazione di patch del piano di controllo di Kubernetes. Questi eventi possono causare la sostituzione delle istanze kube-apiserver, con la potenziale conseguenza della restituzione di indirizzi IP diversi durante la risoluzione del nome di dominio completo. Questo documento descrive le migliori pratiche per gli utenti dell'API Kubernetes per mantenere una connettività affidabile.
Nota
L'implementazione di queste best practice può richiedere aggiornamenti alle configurazioni o agli script dei client per gestire efficacemente le nuove strategie di risoluzione e riprovare il DNS.
Il problema principale deriva dalla memorizzazione nella cache DNS lato client e dalla potenziale presenza di indirizzi IP obsoleti degli endpoint EKS: NLB pubblico per endpoint pubblici o X-ENI per endpoint privati. Quando le istanze kube-apiserver vengono sostituite, il Fully Qualified Domain Name (FQDN) può trasformarsi in nuovi indirizzi IP. Tuttavia, a causa delle impostazioni DNS Time to Live (TTL), che sono impostate su 60 secondi nella zona Route 53 gestita da AWS, i client possono continuare a utilizzare indirizzi IP obsoleti per un breve periodo di tempo.
Per mitigare questi problemi, gli utenti delle API Kubernetes (come kubectl, CI/CD pipeline e applicazioni personalizzate) devono implementare le seguenti best practice:
-
Implementare la risoluzione DNS
-
Implementa nuovi tentativi con Backoff e Jitter. Ad esempio, consulta questo articolo
intitolato Failures Happen -
Implementa i timeout dei client. Imposta i timeout appropriati per evitare che le richieste di lunga durata blocchino l'applicazione. Tieni presente che alcune librerie client Kubernetes, in particolare quelle generate dai generatori OpenAPI, potrebbero non consentire di impostare facilmente timeout personalizzati.
-
Esempio 1 con kubectl:
kubectl get pods --request-timeout 10s # default: no timeout
-
Esempio 2 con Python: il client Kubernetes
fornisce un parametro _request_timeout
-
Implementando queste best practice, puoi migliorare in modo significativo l'affidabilità e la resilienza delle tue applicazioni quando interagisci con l'API Kubernetes. Ricorda di testare accuratamente queste implementazioni, specialmente in condizioni di errore simulate, per assicurarti che si comportino come previsto durante gli eventi di scalabilità o applicazione delle patch effettivi.
Esecuzione di cluster di grandi dimensioni
EKS monitora attivamente il carico sulle istanze del piano di controllo e le ridimensiona automaticamente per garantire prestazioni elevate. Tuttavia, è necessario tenere conto dei potenziali problemi e limiti di prestazioni all'interno di Kubernetes e delle quote nei servizi AWS quando si eseguono cluster di grandi dimensioni.
-
Secondo i test eseguiti dal team, i cluster con più di 1000 servizi potrebbero presentare una latenza di rete utilizzando
iptablesla modalitàkube-proxyin. ProjectCalicoLa soluzione è passare alla modalità di esecuzione kube-proxy in ipvs modalità. -
È inoltre possibile che si verifichi una limitazione delle richieste EC2 API se il CNI deve richiedere gli indirizzi IP per i Pods o se è necessario creare nuove istanze frequentemente. EC2 Puoi ridurre le chiamate EC2 API configurando il CNI per memorizzare nella cache gli indirizzi IP. È possibile utilizzare tipi di EC2 istanze più grandi per ridurre gli eventi di EC2 scalabilità.
Risorse aggiuntive:
