Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Ottimizzazione dei costi - Rete
Progettare sistemi per l'alta disponibilità (HA) è una best practice per raggiungere la resilienza e la tolleranza ai guasti. In pratica, ciò significa distribuire i carichi di lavoro e l'infrastruttura sottostante su più zone di disponibilità (AZs) in una determinata regione AWS. Garantire che queste caratteristiche siano presenti per il tuo ambiente Amazon EKS migliorerà l'affidabilità complessiva del tuo sistema. Inoltre, gli ambienti EKS saranno probabilmente composti anche da una varietà di costrutti (ad esempio VPCs), componenti (ad esempio) e integrazioni (ad esempio ECR e altri registri di contenitori ELBs).
La combinazione di sistemi ad alta disponibilità e altri componenti specifici dei casi d'uso può svolgere un ruolo significativo nel modo in cui i dati vengono trasferiti ed elaborati. Ciò avrà a sua volta un impatto sui costi sostenuti a causa del trasferimento e dell'elaborazione dei dati.
Le pratiche descritte di seguito vi aiuteranno a progettare e ottimizzare gli ambienti EKS al fine di ottenere un rapporto costo-efficacia per diversi domini e casi d'uso.
Comunicazione da Pod a Pod
A seconda della configurazione, la comunicazione di rete e il trasferimento di dati tra i pod possono avere un impatto significativo sul costo complessivo di esecuzione dei carichi di lavoro Amazon EKS. Questa sezione tratterà diversi concetti e approcci per mitigare i costi legati alla comunicazione tra pod, considerando al contempo le architetture ad alta disponibilità (HA), le prestazioni delle applicazioni e la resilienza.
Limitazione del traffico verso una zona di disponibilità
Il progetto Kubernetes iniziò fin dall'inizio a sviluppare costrutti compatibili con la topologia, tra cui etichette come kubernetes. io/hostname, topology.kubernetes.io/region, and topology.kubernetes.io/zoneassegnati ai nodi per abilitare funzionalità come la distribuzione del carico di lavoro tra domini di errore e fornitori di volumi con riconoscimento della topologia. Dopo la laurea in Kubernetes 1.17, le etichette sono state utilizzate anche per abilitare funzionalità di routing basate sulla topologia per la comunicazione da Pod a Pod.
Di seguito sono riportate alcune strategie su come controllare la quantità di traffico Cross-AZ tra i Pod del cluster EKS per ridurre i costi e minimizzare la latenza.
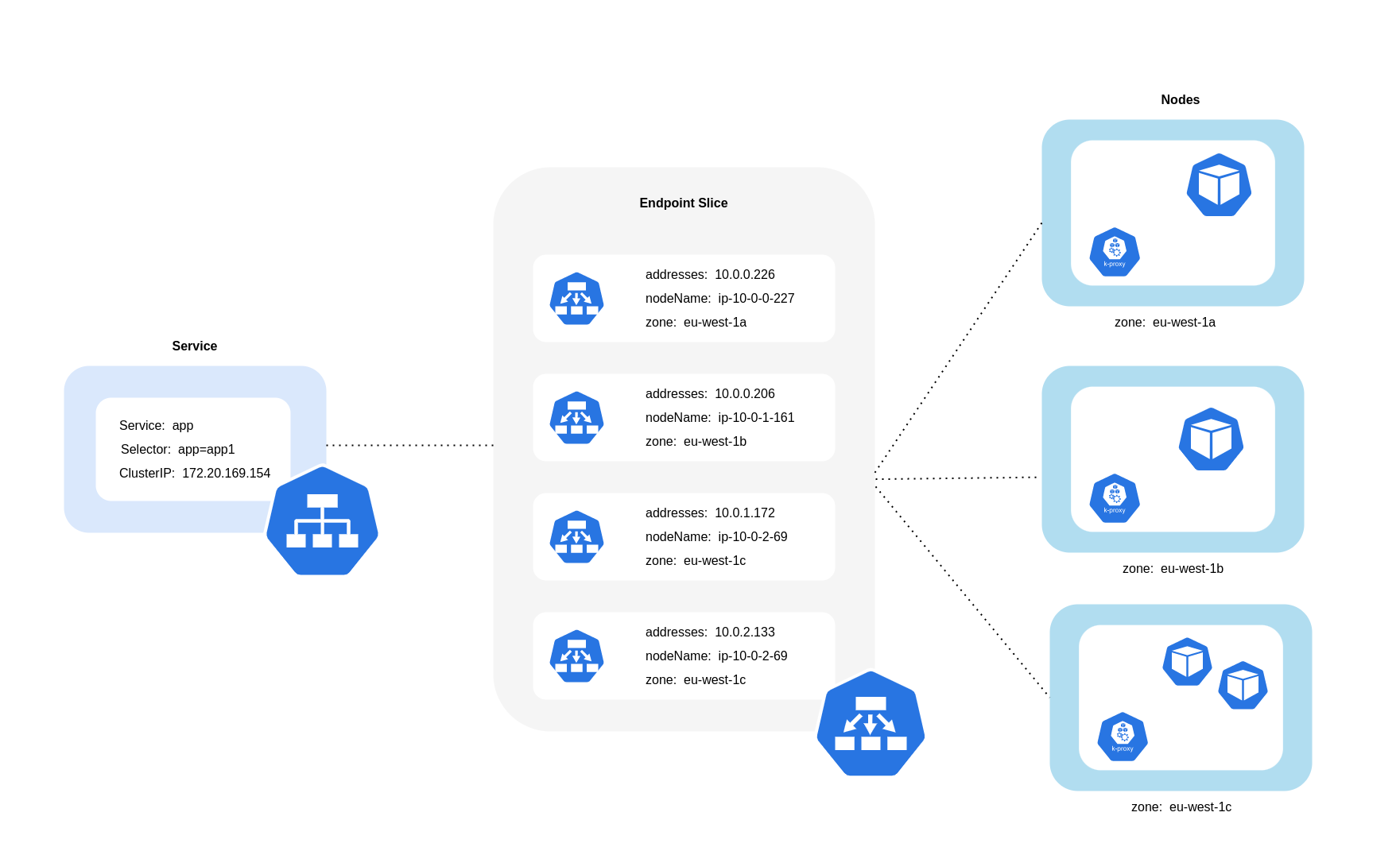
Come illustrato nel diagramma precedente, i Servizi sono lo strato di astrazione stabile della rete che riceve il traffico destinato ai tuoi Pod. Quando viene creato un servizio, ne vengono creati diversi. EndpointSlices Ciascuno EndpointSlice ha un elenco di endpoint contenente un sottoinsieme di indirizzi Pod insieme ai nodi su cui sono in esecuzione e qualsiasi altra informazione sulla topologia. Quando si utilizza Amazon VPC CNI, kube-proxy, un daemset in esecuzione su ogni nodo, mantiene le regole di rete per consentire la comunicazione Pod e il rilevamento dei servizi (un'alternativa basata su EBPF CNIs potrebbe non utilizzare kube-proxy ma fornire un comportamento equivalente). Svolge il ruolo di routing interno, ma lo fa in base a ciò che consuma dalla creazione. EndpointSlices
Su EKS, kube-proxy utilizza principalmente le regole NAT di iptables (o IPVS, in alternativa) per la distribuzione del traffico su tutti i pod del cluster, NFTables
Utilizzo del Topology Aware Routing (precedentemente noto come Topology Aware Hints)
Quando il routing con riconoscimento della topologiakube-proxyindirizzerà quindi il traffico da una zona a un endpoint in base ai suggerimenti applicati.
Il diagramma seguente mostra come EndpointSlices i suggerimenti siano organizzati in modo tale da kube-proxy poter sapere a quale destinazione devono andare in base al punto di origine zonale. Senza i suggerimenti, non esiste tale allocazione o organizzazione e il traffico verrà inoltrato a diverse destinazioni zonali indipendentemente dalla sua provenienza.
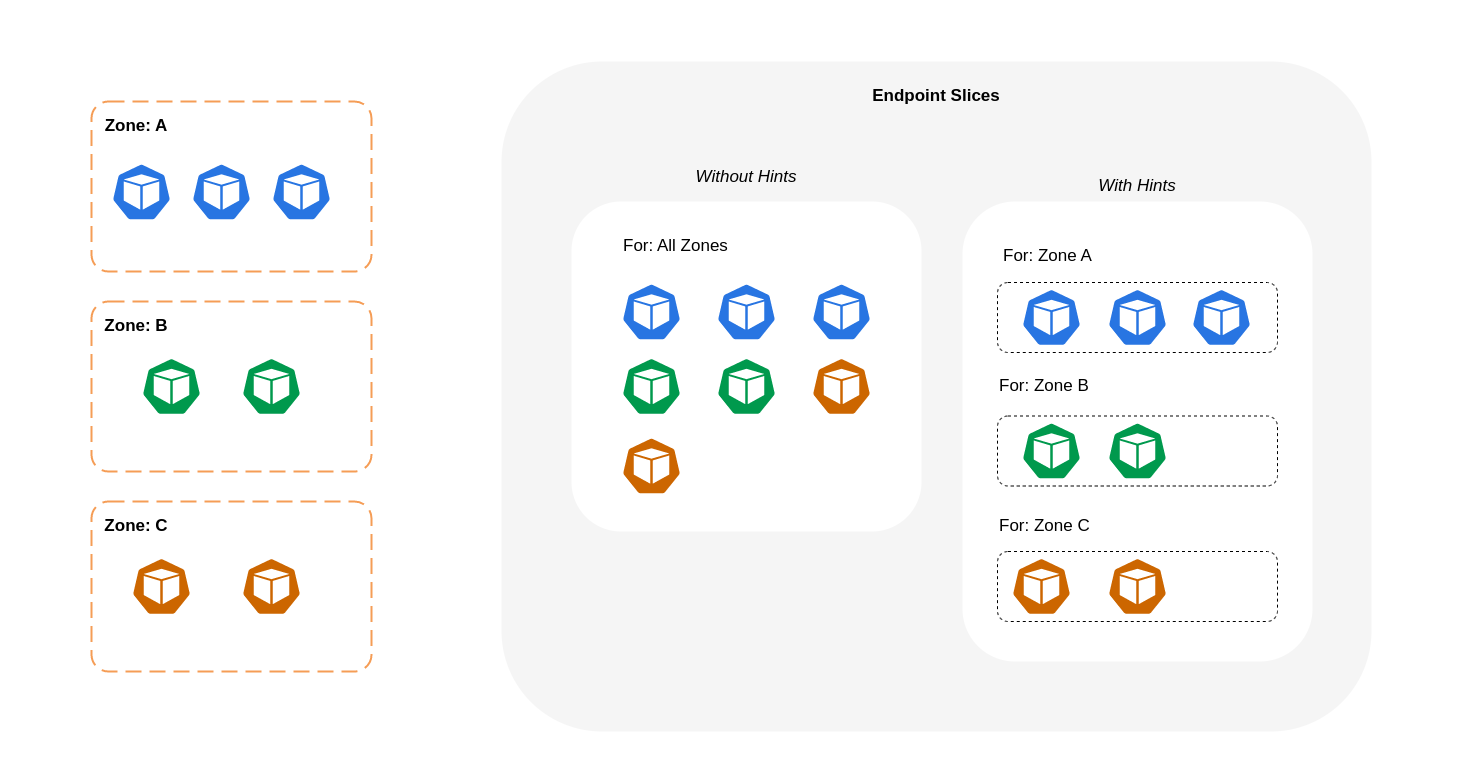
In alcuni casi, il EndpointSlice controller può applicare un suggerimento per una zona diversa, il che significa che l'endpoint potrebbe finire per servire il traffico proveniente da una zona diversa. La ragione di ciò è cercare di mantenere una distribuzione uniforme del traffico tra gli endpoint in zone diverse.
Di seguito è riportato un frammento di codice su come abilitare il routing con riconoscimento della topologia per un servizio.
apiVersion: v1 kind: Service metadata: name: orders-service namespace: ecommerce annotations: service.kubernetes.io/topology-mode: Auto spec: selector: app: orders type: ClusterIP ports: * protocol: TCP port: 3003 targetPort: 3003
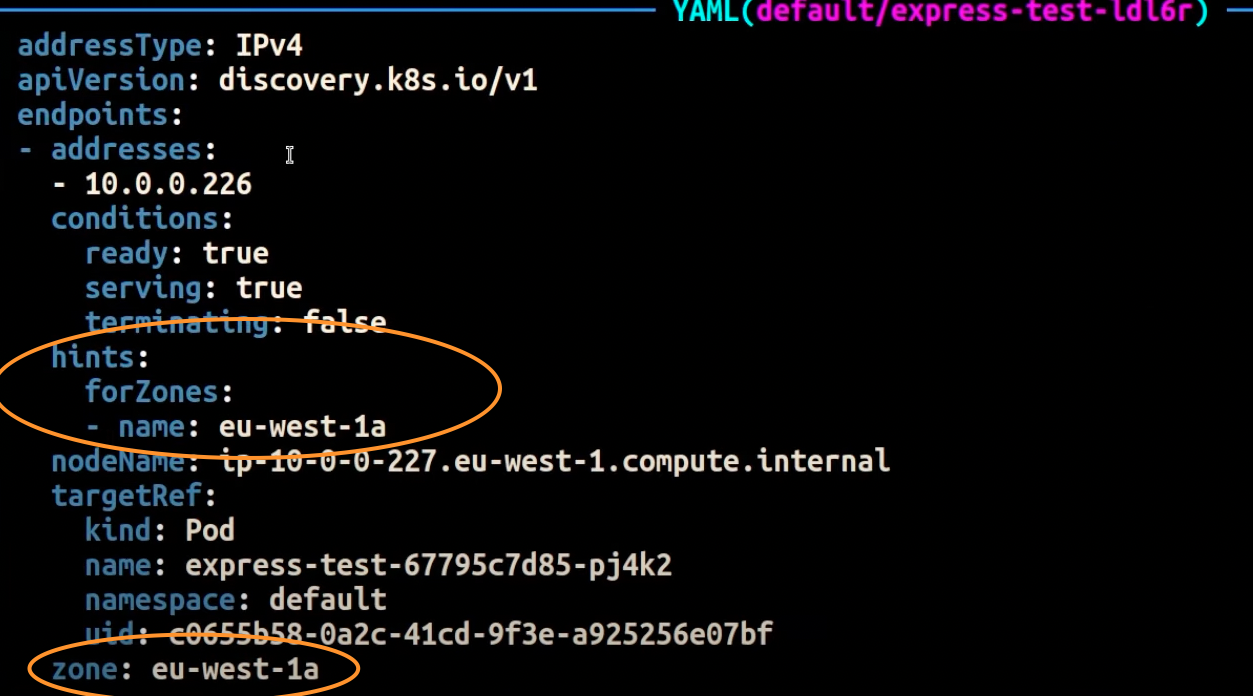
La schermata seguente mostra il risultato ottenuto dal EndpointSlice controller che ha applicato con successo un suggerimento a un endpoint per una replica Pod in esecuzione nell'AZ. eu-west-1a
Nota
È importante notare che il routing con riconoscimento della topologia è ancora in versione beta. Questa funzionalità offre prestazioni più prevedibili con carichi di lavoro distribuiti uniformemente su tutta la topologia del cluster, in quanto il controller alloca gli endpoint in modo proporzionale tra le zone, ma può saltare l'assegnazione dei suggerimenti quando le risorse dei nodi in una zona sono troppo squilibrate per evitare un sovraccarico eccessivo. Pertanto, si consiglia vivamente di utilizzarla insieme a vincoli di pianificazione che aumentano la disponibilità di un'applicazione come i vincoli di diffusione della topologia dei pod.
Utilizzo della distribuzione del traffico
Introdotto in Kubernetes 1.30 e reso disponibile a livello generale nella versione 1.33, Traffic Distribution offre un'alternativa più semplice al Topology Aware Routing per la preferenza del traffico
Di seguito è riportato un frammento di codice su come abilitare la distribuzione del traffico per un servizio.
apiVersion: v1 kind: Service metadata: name: orders-service namespace: ecommerce spec: trafficDistribution: PreferClose selector: app: orders type: ClusterIP ports: * protocol: TCP port: 3003 targetPort: 3003
Quando si abilita la distribuzione del traffico, emerge una sfida comune: gli endpoint all'interno di una singola AZ possono sovraccaricarsi se la maggior parte del traffico proviene dalla stessa zona. Questo sovraccarico può creare problemi significativi:
-
Un singolo Horizontal Pod Autoscaler (HPA) che gestisce un'implementazione Multi-AZ può rispondere scalando i pod tra diversi. AZs Tuttavia, questa azione non riesce a far fronte in modo efficace all'aumento del carico nella zona interessata.
-
Questa situazione a sua volta può portare a un'inefficienza delle risorse. Quando gli autoscaler dei cluster come Karpenter rilevano lo scale-out del pod tra diversi nodi AZs, possono fornire nodi aggiuntivi nell'area inalterata, con conseguente allocazione non necessaria delle risorse. AZs
Per superare questa sfida:
-
Crea implementazioni separate per zona, con una scalabilità indipendente HPAs l'una dall'altra.
-
Sfrutta i vincoli di diffusione della topologia per garantire la distribuzione del carico di lavoro nel cluster, il che aiuta a prevenire il sovraccarico degli endpoint nelle zone ad alto traffico.
Utilizzo di Autoscaler: assegna nodi a una zona di disponibilità specifica
Consigliamo vivamente di eseguire i carichi di lavoro in ambienti ad alta disponibilità su più piattaforme. AZs Ciò migliora l'affidabilità delle applicazioni, soprattutto quando si verifica un incidente o un problema con una zona di disponibilità. Se siete disposti a sacrificare l'affidabilità per ridurre i costi relativi alla rete, potete limitare i nodi a una singola AZ.
Per far funzionare tutti i tuoi Pod nella stessa AZ, esegui il provisioning dei nodi di lavoro nella stessa AZ o pianifica i Pod sui nodi di lavoro in esecuzione sulla stessa AZ. Per effettuare il provisioning dei nodi all'interno di una singola AZ, definisci un gruppo di nodi con sottoreti appartenenti alla stessa AZ con Cluster Autoscalertopology.kubernetes.io/zone e specifica l'AZ in cui desideri creare i nodi di lavoro. Ad esempio, lo snippet di Karpenter provisioner riportato di seguito esegue il provisioning dei nodi nella zona AZ us-west-2a.
Karpenter
apiVersion: karpenter.sh/v1 kind: Provisioner metadata: name: single-az spec: requirements: * key: "topology.kubernetes.io/zone"` operator: In values: ["us-west-2a"]
Cluster Autoscaler (CA)
apiVersion: eksctl.io/v1alpha5 kind: ClusterConfig metadata: name: my-ca-cluster region: us-east-1 version: "1.21" availabilityZones: * us-east-1a managedNodeGroups: * name: managed-nodes labels: role: managed-nodes instanceType: t3.medium minSize: 1 maxSize: 10 desiredCapacity: 1 ...
Utilizzo di Pod Assignment e Node Affinity
In alternativa, se hai nodi di lavoro in esecuzione in più nodi AZs, ogni nodo avrebbe l'etichetta topology.kubernetes.io/zonenodeSelector nodeAffinity Ad esempio, il seguente file manifest pianificherà il Pod all'interno di un nodo in esecuzione in AZ us-west-2a.
apiVersion: v1 kind: Pod metadata: name: nginx labels: env: test spec: nodeSelector: topology.kubernetes.io/zone: us-west-2a containers: * name: nginx image: nginx imagePullPolicy: IfNotPresent
Limitazione del traffico verso un nodo
Ci sono casi in cui limitare il traffico a livello zonale non è sufficiente. Oltre alla riduzione dei costi, potrebbe essere necessario ridurre la latenza di rete tra determinate applicazioni che hanno frequenti intercomunicazioni. Per ottenere prestazioni di rete ottimali e ridurre i costi, è necessario un modo per limitare il traffico a un nodo specifico. Ad esempio, il microservizio A dovrebbe sempre comunicare con il microservizio B sul nodo 1, anche nelle configurazioni ad alta disponibilità (HA). Se il Microservizio A sul Nodo 1 comunica con il Microservizio B sul Nodo 2, può avere un impatto negativo sulle prestazioni desiderate per le applicazioni di questo tipo, specialmente se il Nodo 2 si trova in una zona AZ completamente separata.
Utilizzo della politica sul traffico interno del servizio
Per limitare il traffico di rete Pod a un nodo, puoi utilizzare la politica sul traffico interno del ServizioLocal, il traffico sarà limitato agli endpoint sul nodo da cui proviene il traffico. Questa politica impone l'uso esclusivo degli endpoint locali del nodo. Di conseguenza, i costi relativi al traffico di rete per quel carico di lavoro saranno inferiori rispetto a quelli derivanti dalla distribuzione a livello di cluster. Inoltre, la latenza sarà inferiore, rendendo l'applicazione più performante.
Nota
È importante notare che questa funzionalità non può essere combinata con il routing con riconoscimento della topologia in Kubernetes.

Di seguito è riportato un frammento di codice su come impostare la politica interna sul traffico per un servizio.
apiVersion: v1 kind: Service metadata: name: orders-service namespace: ecommerce spec: selector: app: orders type: ClusterIP ports: * protocol: TCP port: 3003 targetPort: 3003 internalTrafficPolicy: Local
Per evitare comportamenti imprevisti dell'applicazione dovuti a cali di traffico, è necessario prendere in considerazione i seguenti approcci:
-
Eseguite un numero sufficiente di repliche per ciascuno dei Pod comunicanti
-
Utilizza le regole di affinità dei pod per la co-localizzazione dei Pod
comunicanti
In questo esempio, avete 2 repliche del Microservizio A e 3 repliche del Microservizio B. Se il Microservizio A ha le sue repliche distribuite tra i Nodi 1 e 2 e il Microservizio B ha tutte e 3 le sue repliche sul Nodo 3, non saranno in grado di comunicare a causa della politica interna sul traffico. Local Quando non sono disponibili endpoint locali a livello di nodo, il traffico viene interrotto.
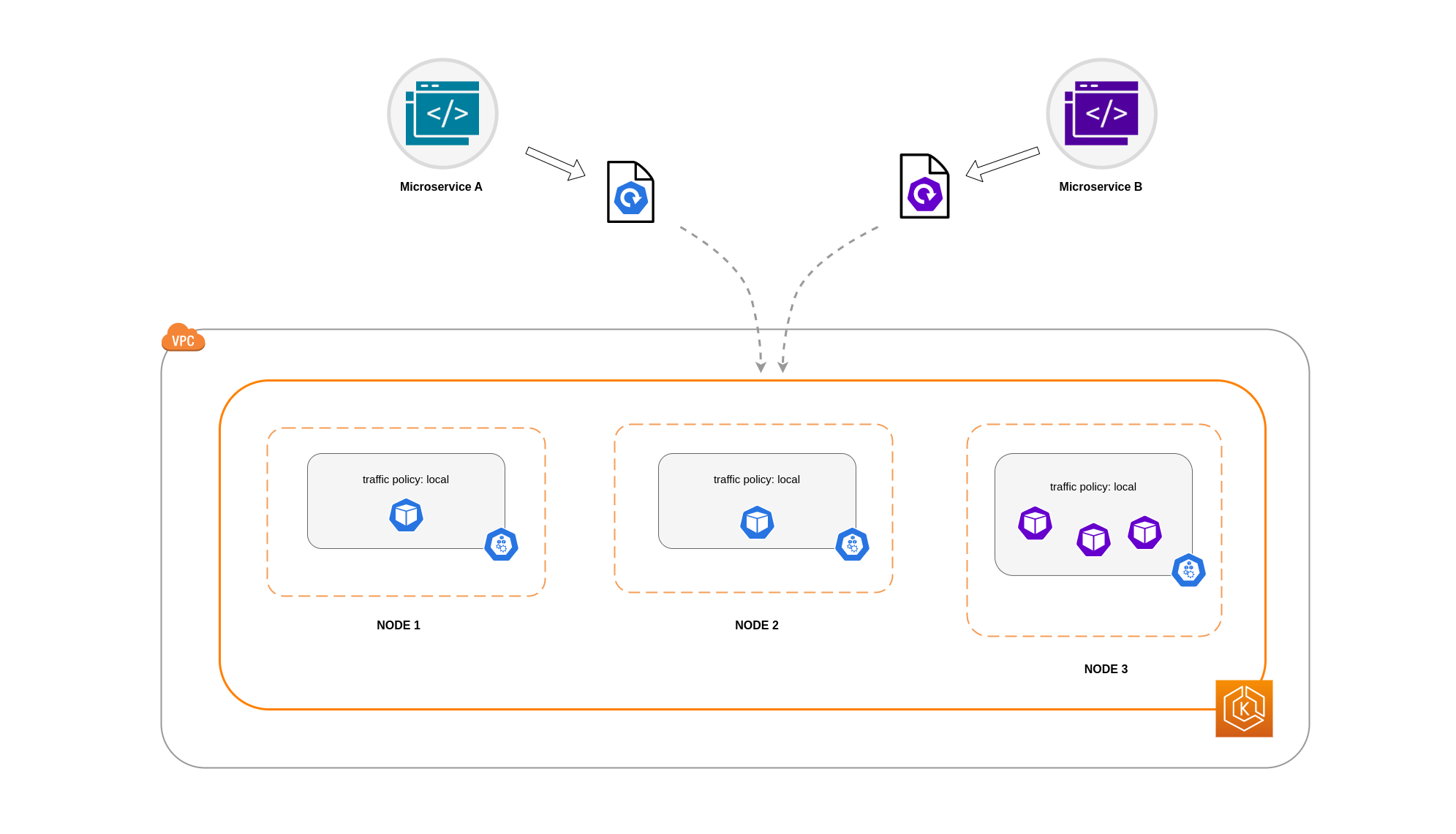
Se Microservice B ha 2 delle sue 3 repliche sui nodi 1 e 2, allora ci sarà comunicazione tra le applicazioni peer. Tuttavia, avresti comunque una replica isolata del Microservice B senza alcuna replica peer con cui comunicare.
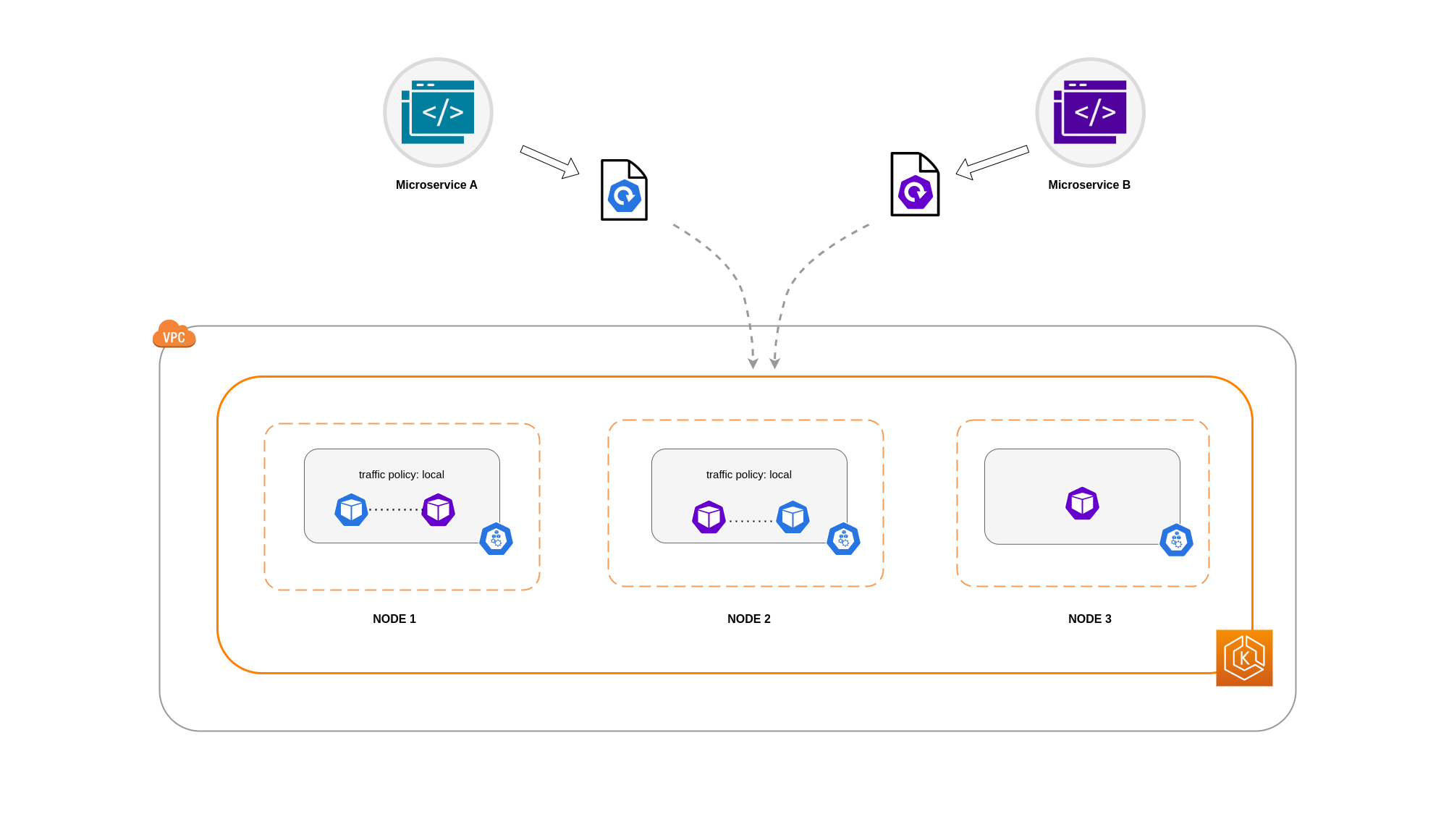
Nota
In alcuni scenari, una replica isolata come quella illustrata nel diagramma precedente potrebbe non essere motivo di preoccupazione se serve ancora a uno scopo (ad esempio soddisfare le richieste provenienti dal traffico esterno in entrata).
Utilizzo della policy sul traffico interno del servizio con vincoli di diffusione della topologia
L'utilizzo della politica interna sul traffico insieme ai vincoli di diffusione della topologia può essere utile per garantire il giusto numero di repliche per la comunicazione dei microservizi su nodi diversi.
apiVersion: apps/v1 kind: Deployment metadata: name: express-test spec: replicas: 6 selector: matchLabels: app: express-test template: metadata: labels: app: express-test tier: backend spec: topologySpreadConstraints: - maxSkew: 1 topologyKey: "topology.kubernetes.io/zone" whenUnsatisfiable: ScheduleAnyway labelSelector: matchLabels: app: express-test
Utilizzo della policy sul traffico interno del servizio con Pod Affinity Rules
Un altro approccio consiste nell'utilizzare le regole di affinità di Pod quando si utilizza la politica del traffico interno del Servizio. Con Pod affinity, puoi influenzare lo scheduler affinché collochino determinati Pod a causa della loro frequente comunicazione. Applicando rigidi vincoli di pianificazione (requiredDuringSchedulingIgnoredDuringExecution) su determinati Pod, otterrete risultati migliori per la co-locazione dei Pod quando lo Scheduler posiziona i Pod sui nodi.
apiVersion: apps/v1 kind: Deployment metadata: name: graphql namespace: ecommerce labels: app.kubernetes.io/version: "0.1.6" ... spec: serviceAccountName: graphql-service-account affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - orders topologyKey: "kubernetes.io/hostname"
Comunicazione da Load Balancer a Pod
I carichi di lavoro EKS sono in genere gestiti da un sistema di bilanciamento del carico che distribuisce il traffico ai Pod pertinenti del cluster EKS. L'architettura può comprendere bilanciatori di carico interni ed esterni. and/or A seconda dell'architettura e delle configurazioni del traffico di rete, la comunicazione tra i sistemi di bilanciamento del carico e i Pod può contribuire in modo significativo ai costi di trasferimento dei dati.
Puoi utilizzare AWS Load Balancer Controller
Quando si utilizza la modalità di istanza, NodePort verrà aperto un nodo su ogni nodo del cluster EKS. Il load balancer eseguirà quindi il proxy del traffico in modo uniforme tra i nodi. Se su un nodo è in esecuzione il Pod di destinazione, non verranno sostenuti costi di trasferimento dei dati. Tuttavia, se il Pod di destinazione si trova su un nodo separato e in una AZ diversa da quella che NodePort riceve il traffico, ci sarà un ulteriore hop di rete dal kube-proxy al Pod di destinazione. In tale scenario, verranno applicati costi di trasferimento dati Cross-AZ. A causa della distribuzione uniforme del traffico tra i nodi, è molto probabile che vengano applicati costi aggiuntivi per il trasferimento dei dati associati agli spostamenti del traffico di rete tra zone dai kube-proxy ai relativi Pod di destinazione.
Il diagramma seguente mostra un percorso di rete per il traffico che fluisce dal sistema di bilanciamento del carico al Pod di destinazione e successivamente dal Pod di destinazione su un NodePort nodo separato in una AZ kube-proxy diversa. Questo è un esempio dell'impostazione della modalità di istanza.
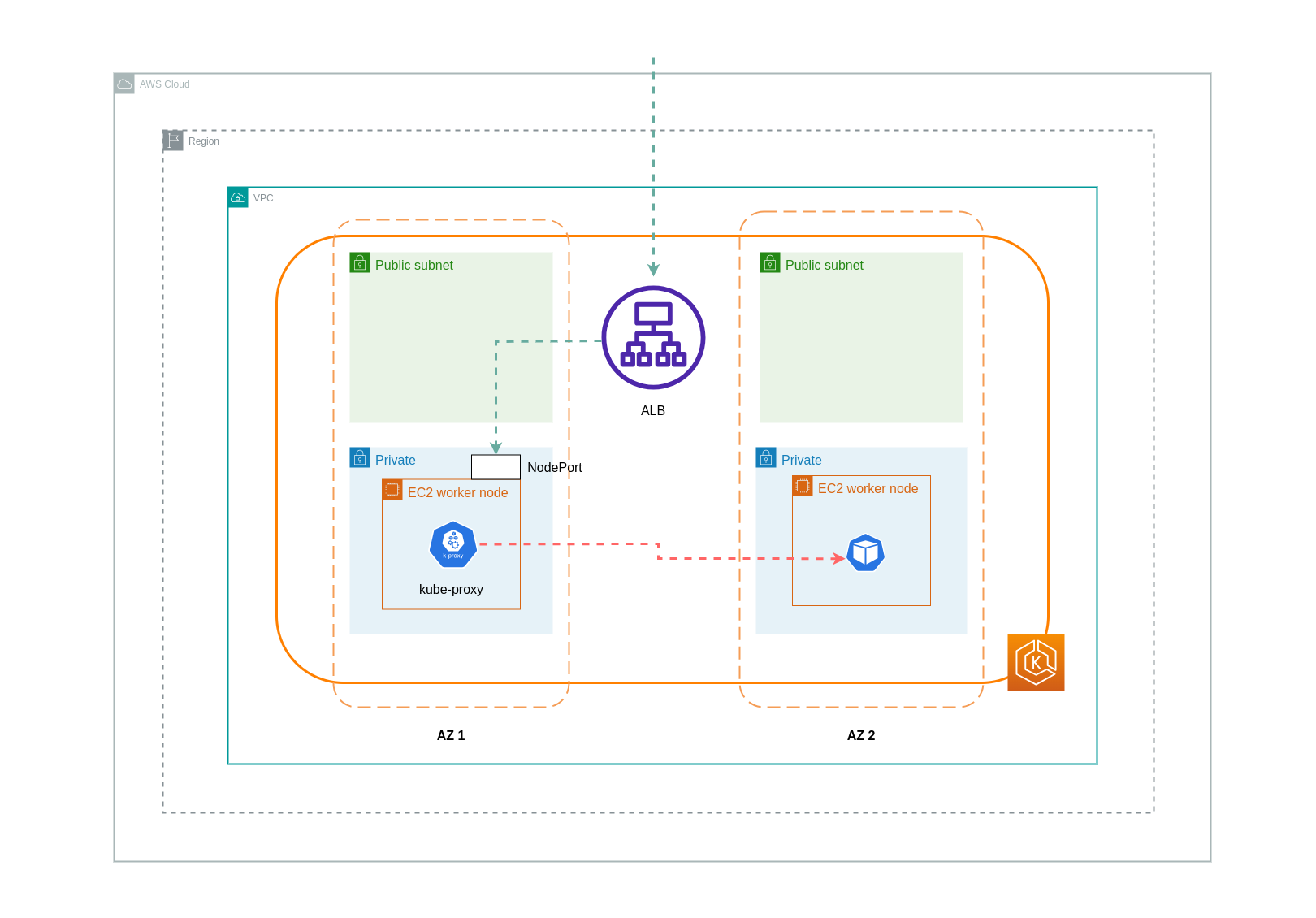
Quando si utilizza la modalità ip, il traffico di rete viene inoltrato dal load balancer direttamente al Pod di destinazione. Di conseguenza, questo approccio non prevede costi di trasferimento dei dati.
Nota
Si consiglia di impostare il sistema di bilanciamento del carico in modalità traffico IP per ridurre i costi di trasferimento dei dati. Per questa configurazione, è anche importante assicurarsi che il sistema di bilanciamento del carico sia distribuito su tutte le sottoreti del VPC.
Il diagramma seguente mostra i percorsi di rete per il traffico che scorre dal sistema di bilanciamento del carico ai Pods in modalità IP di rete.
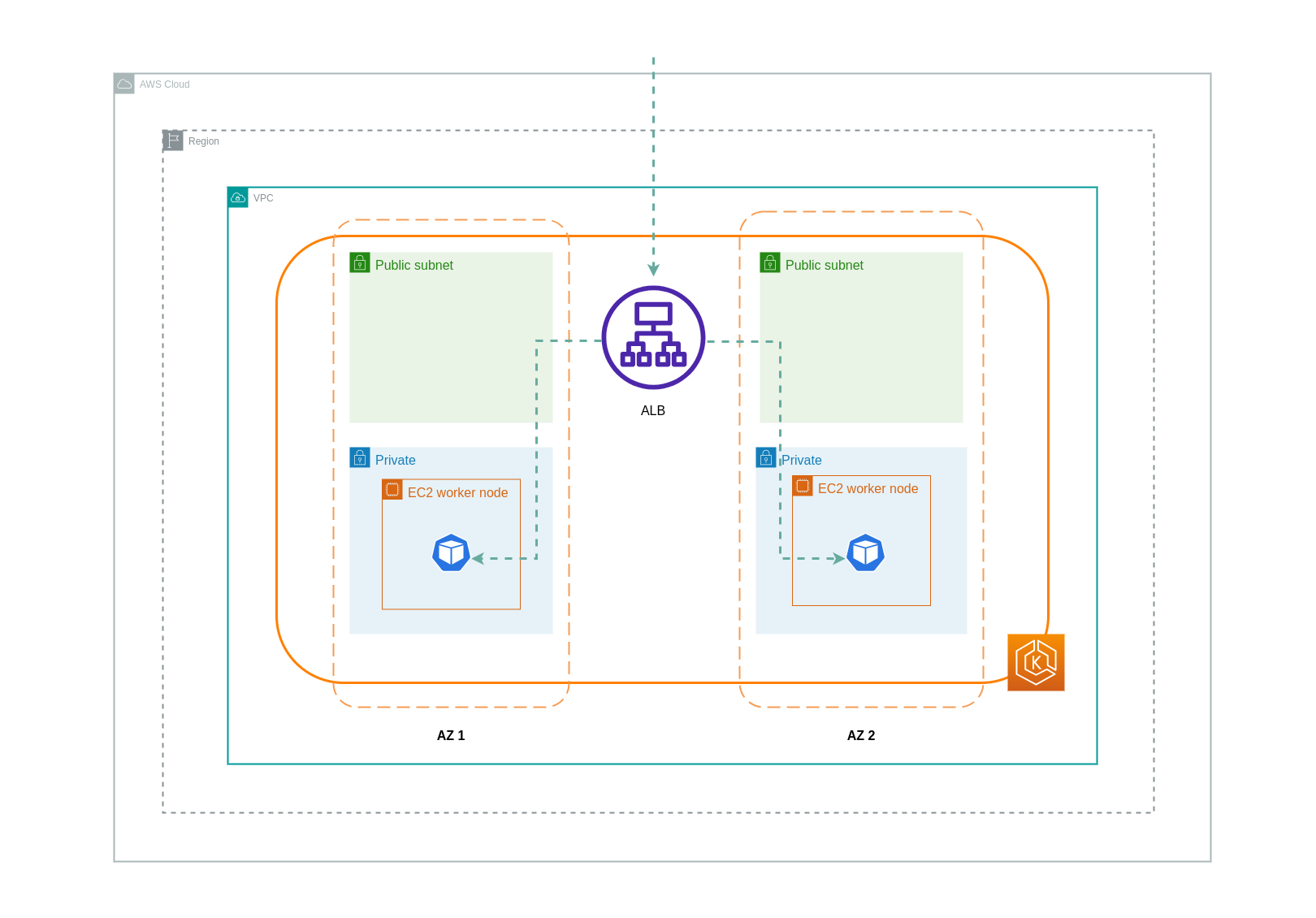
Trasferimento dati dal registro dei contenitori
Amazon ECR
Il trasferimento dei dati nel registro privato di Amazon ECR è gratuito. Il trasferimento di dati all'interno della regione non comporta alcun costo, ma il trasferimento di dati verso Internet e tra le regioni verrà addebitato alle tariffe di trasferimento dati Internet su entrambi i lati del trasferimento.
È necessario utilizzare la funzionalità di replica delle immagini ECRs integrata per replicare le immagini dei container pertinenti nella stessa regione dei carichi di lavoro. In questo modo la replica verrebbe addebitata una sola volta e tutte le immagini recuperate dalla stessa regione (intra-regione) sarebbero gratuite.
È possibile ridurre ulteriormente i costi di trasferimento dei dati associati all'estrazione di immagini da ECR (trasferimento dati in uscita) utilizzando Interface VPC Endpoints per connettersi agli archivi ECR locali. L'approccio alternativo di connessione all'endpoint AWS pubblico di ECR (tramite un gateway NAT e un Internet Gateway) comporterà costi di elaborazione e trasferimento dei dati più elevati. La prossima sezione tratterà la riduzione dei costi di trasferimento dei dati tra i carichi di lavoro e i servizi AWS in modo più dettagliato.
Se esegui carichi di lavoro con immagini particolarmente grandi, puoi creare Amazon Machine Images (AMIs) personalizzate con immagini di container prememorizzate nella cache. Ciò può ridurre il tempo iniziale di recupero dell'immagine e i potenziali costi di trasferimento dei dati da un registro di container ai nodi di lavoro EKS.
Trasferimento di dati verso Internet e servizi AWS
È pratica comune integrare i carichi di lavoro Kubernetes con altri servizi AWS o strumenti e piattaforme di terze parti tramite Internet. L'infrastruttura di rete sottostante utilizzata per instradare il traffico da e verso la destinazione pertinente può influire sui costi sostenuti nel processo di trasferimento dei dati.
Utilizzo dei gateway NAT
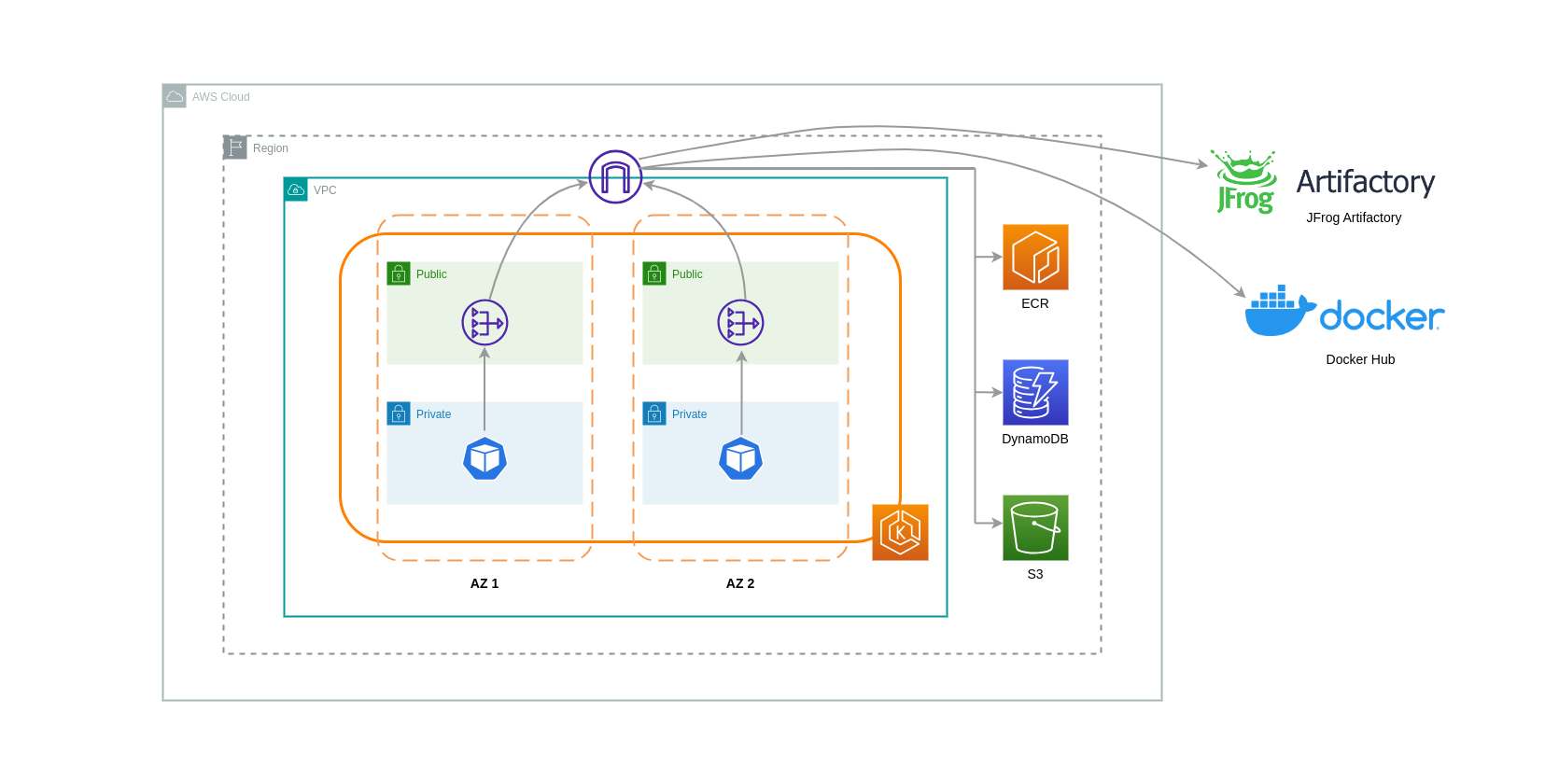
I gateway NAT sono componenti di rete che eseguono la traduzione degli indirizzi di rete (NAT). Il diagramma seguente mostra i pod in un cluster EKS che comunicano con altri servizi AWS (Amazon ECR, DynamoDB e S3) e piattaforme di terze parti. In questo esempio, i Pod vengono eseguiti in sottoreti private separate. AZs Per inviare e ricevere traffico da Internet, un gateway NAT viene distribuito nella sottorete pubblica di una AZ, che consente a qualsiasi risorsa con indirizzi IP privati di condividere un unico indirizzo IP pubblico per accedere a Internet. Questo gateway NAT a sua volta comunica con il componente Internet Gateway, consentendo l'invio dei pacchetti alla destinazione finale.
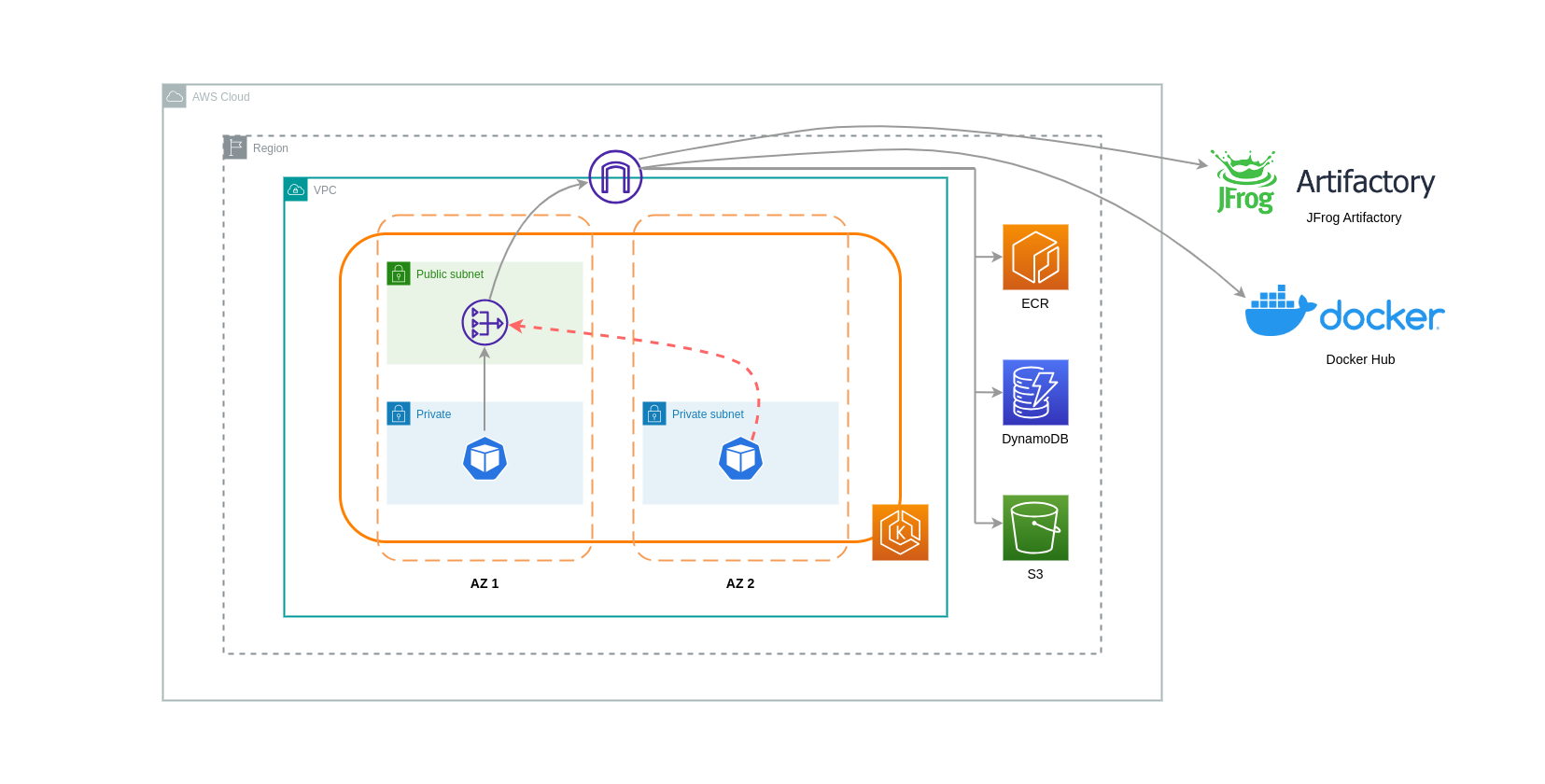
Quando si utilizzano i gateway NAT per questi casi d'uso, è possibile ridurre al minimo i costi di trasferimento dei dati implementando un gateway NAT in ogni AZ. In questo modo, il traffico indirizzato a Internet passerà attraverso il gateway NAT nella stessa zona, evitando il trasferimento di dati tra le AZ. Tuttavia, anche se risparmierete sul costo del trasferimento dei dati tra AZ, l'implicazione di questa configurazione è che dovrete sostenere il costo di un gateway NAT aggiuntivo nella vostra architettura.
Questo approccio consigliato è illustrato nel diagramma seguente.
Utilizzo di endpoint VPC
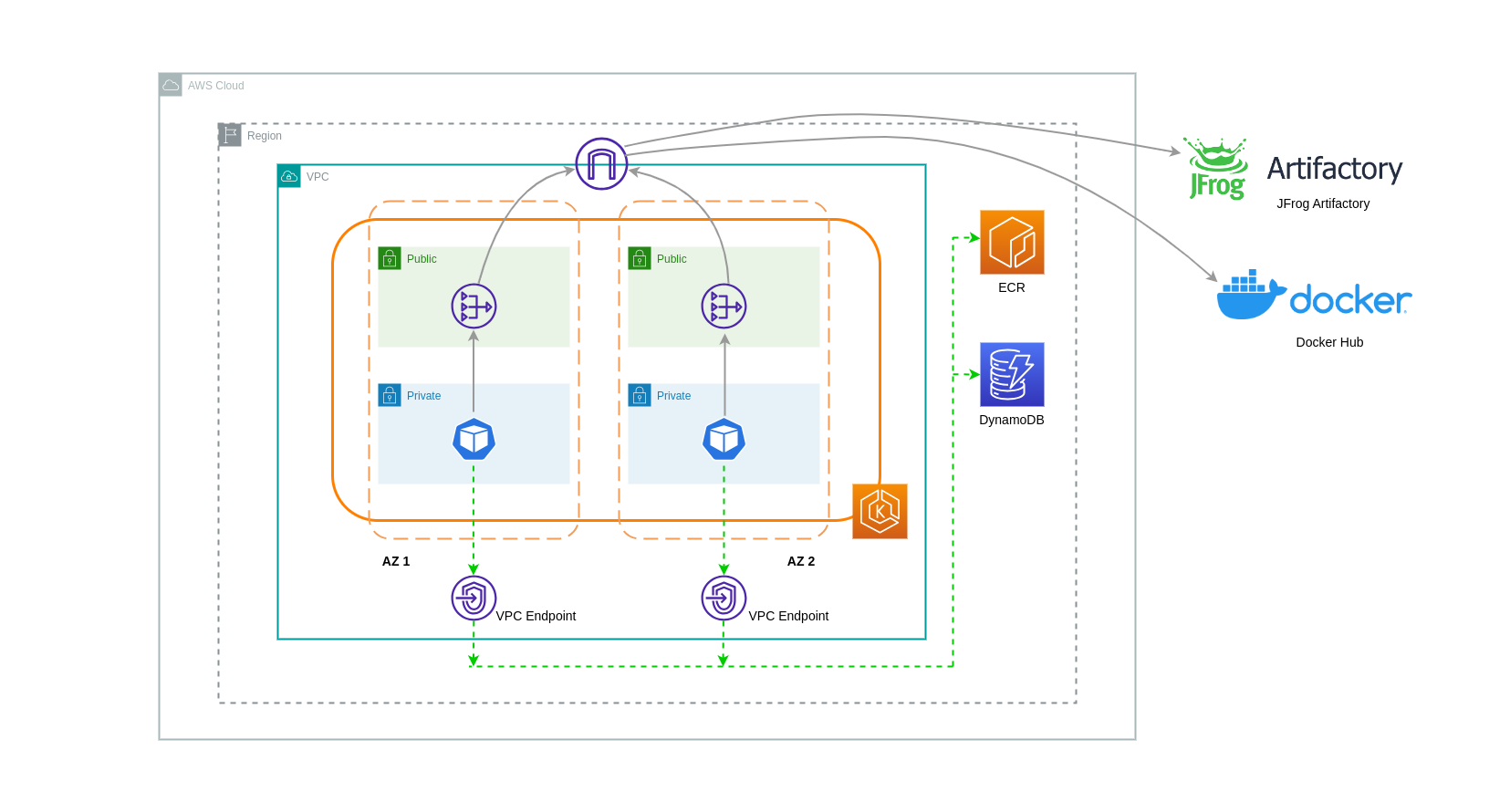
Per ridurre ulteriormente i costi in tali architetture, è necessario utilizzare gli endpoint VPC per stabilire la connettività tra i carichi di lavoro e i servizi AWS. Gli endpoint VPC consentono di accedere ai servizi AWS dall'interno di un VPC senza data/network che i pacchetti attraversino Internet. Tutto il traffico è interno e rimane all'interno della rete AWS. Esistono due tipi di endpoint VPC: gli endpoint VPC di interfaccia (supportati da molti servizi AWS) e gli endpoint VPC Gateway (supportati solo da S3 e DynamoDB).
Endpoint VPC gateway
Non ci sono costi orari o di trasferimento dati associati agli endpoint VPC Gateway. Quando si utilizzano gli endpoint VPC Gateway, è importante notare che non sono estendibili oltre i limiti del VPC. Non possono essere utilizzati nel peering VPC, nelle reti VPN o tramite Direct Connect.
Endpoint VPC di interfaccia
Gli endpoint VPC hanno una tariffa oraria e un costo
Il diagramma seguente mostra i pod che comunicano con i servizi AWS tramite endpoint VPC.
Trasferimento di dati tra VPCs
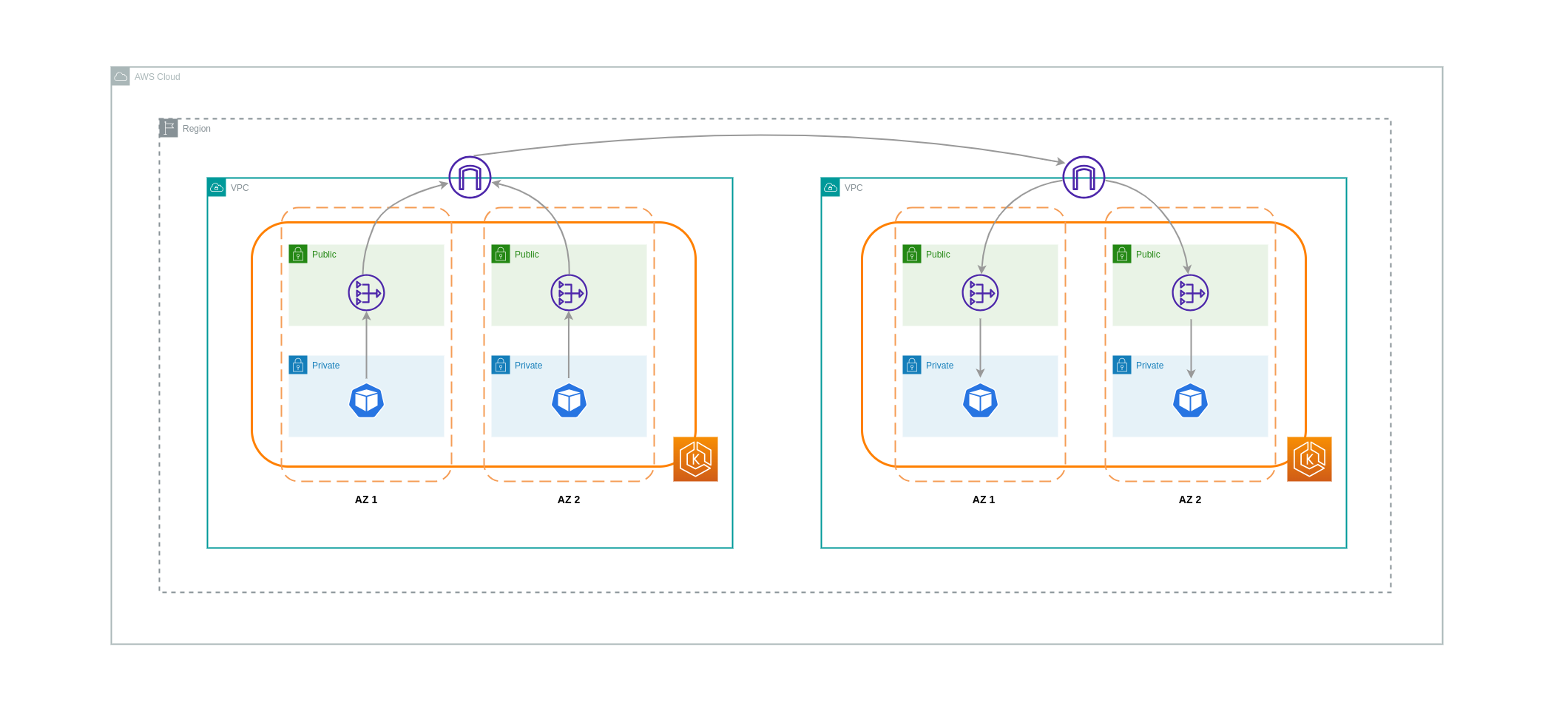
In alcuni casi, potresti avere carichi di lavoro distinti VPCs (all'interno della stessa regione AWS) che devono comunicare tra loro. Ciò può essere ottenuto consentendo al traffico di attraversare la rete Internet pubblica attraverso gli Internet Gateway collegati ai rispettivi gateway. VPCs Tale comunicazione può essere abilitata implementando componenti dell'infrastruttura come EC2 istanze, gateway NAT o istanze NAT in sottoreti pubbliche. Tuttavia, una configurazione che include questi componenti comporterà costi per i dati in entrata e in uscita da. processing/transferring VPCs Se il traffico da e verso la zona separata si VPCs sposta AZs, verrà addebitato un costo aggiuntivo per il trasferimento dei dati. Il diagramma seguente illustra una configurazione che utilizza i gateway NAT e i gateway Internet per stabilire la comunicazione tra carichi di lavoro diversi. VPCs
Connessioni peering VPC
Per ridurre i costi per questi casi d'uso, puoi utilizzare il peering VPC. Con una connessione peering VPC, non ci sono costi di trasferimento dati per il traffico di rete che rimane all'interno della stessa AZ. In caso di incrocio di traffico AZs, verrà addebitato un costo. Tuttavia, l'approccio VPC Peering è consigliato per una comunicazione economica tra carichi di lavoro separati all'interno della stessa regione AWS. VPCs Tuttavia, è importante notare che il peering VPC è efficace principalmente per la connettività VPC 1:1 perché non consente il networking transitivo.
Il diagramma seguente è una rappresentazione di alto livello della comunicazione dei carichi di lavoro tramite una connessione peering VPC.

Connessioni di rete transitive
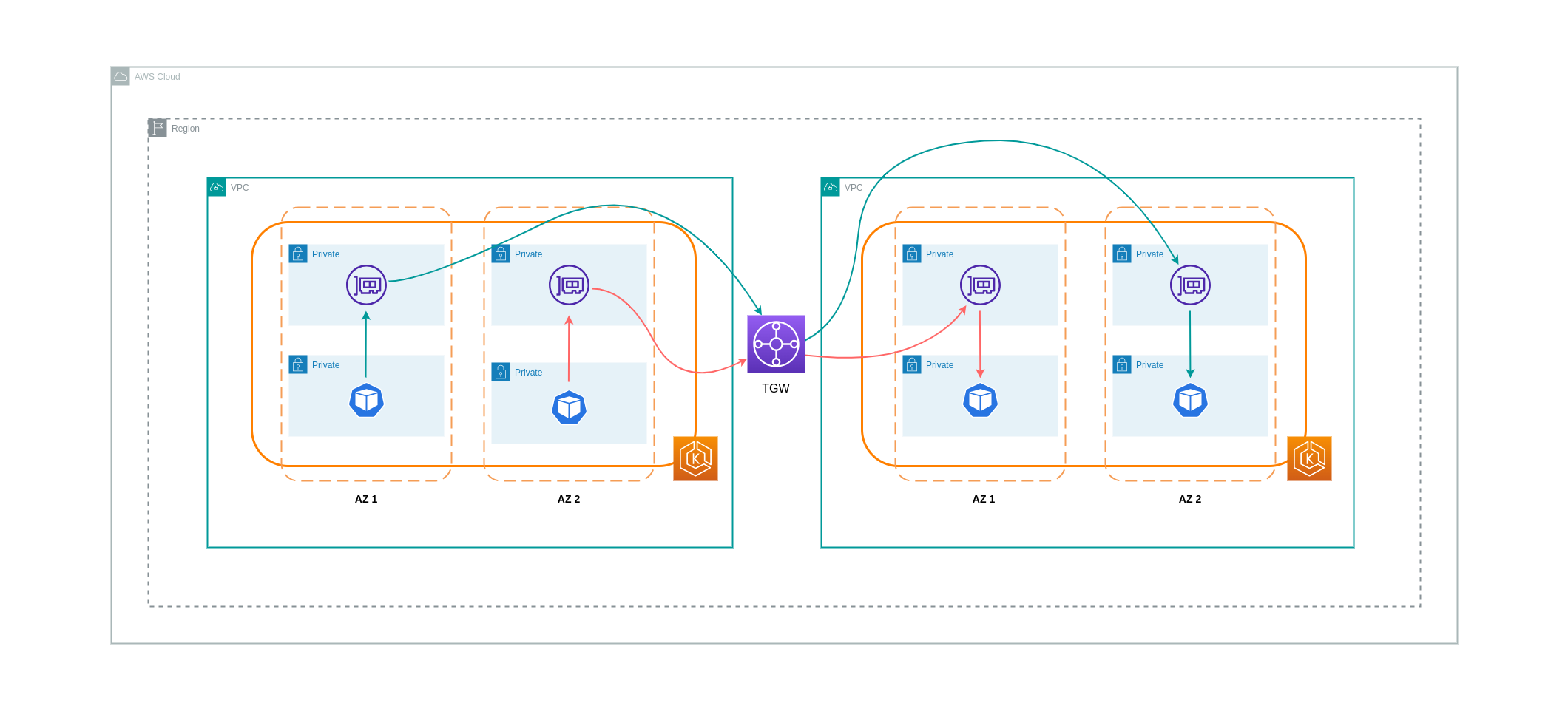
Come indicato nella sezione precedente, le connessioni peering VPC non consentono la connettività di rete transitiva. Se desideri connetterne 3 o più VPCs con requisiti di rete transitivi, allora dovresti usare un Transit Gateway (TGW). Ciò ti consentirà di superare i limiti del peering VPC o qualsiasi sovraccarico operativo associato alla presenza di più connessioni peering VPC tra più connessioni. VPCs La fatturazione viene effettuata su base oraria
Il diagramma seguente mostra il traffico inter-AZ che scorre attraverso un TGW tra carichi di lavoro in diverse ma VPCs all'interno della stessa regione AWS.
Utilizzo di una Service Mesh
Le service mesh offrono potenti funzionalità di rete che possono essere utilizzate per ridurre i costi relativi alla rete negli ambienti cluster EKS. Tuttavia, è necessario considerare attentamente le attività operative e la complessità che una service mesh introdurrà nel proprio ambiente se ne adotterà una.
Limitazione del traffico alle zone di disponibilità
Utilizzo della distribuzione ponderata per località di Istio
Istio consente di applicare le politiche di rete al traffico dopo il routing. Questa operazione viene eseguita utilizzando le regole di destinazione
Nota
Prima di implementare la distribuzione ponderata per località, è necessario iniziare a comprendere i modelli di traffico di rete e le implicazioni che la politica della regola di destinazione può avere sul comportamento dell'applicazione. Pertanto, è importante disporre di meccanismi di tracciamento distribuiti con strumenti come AWS
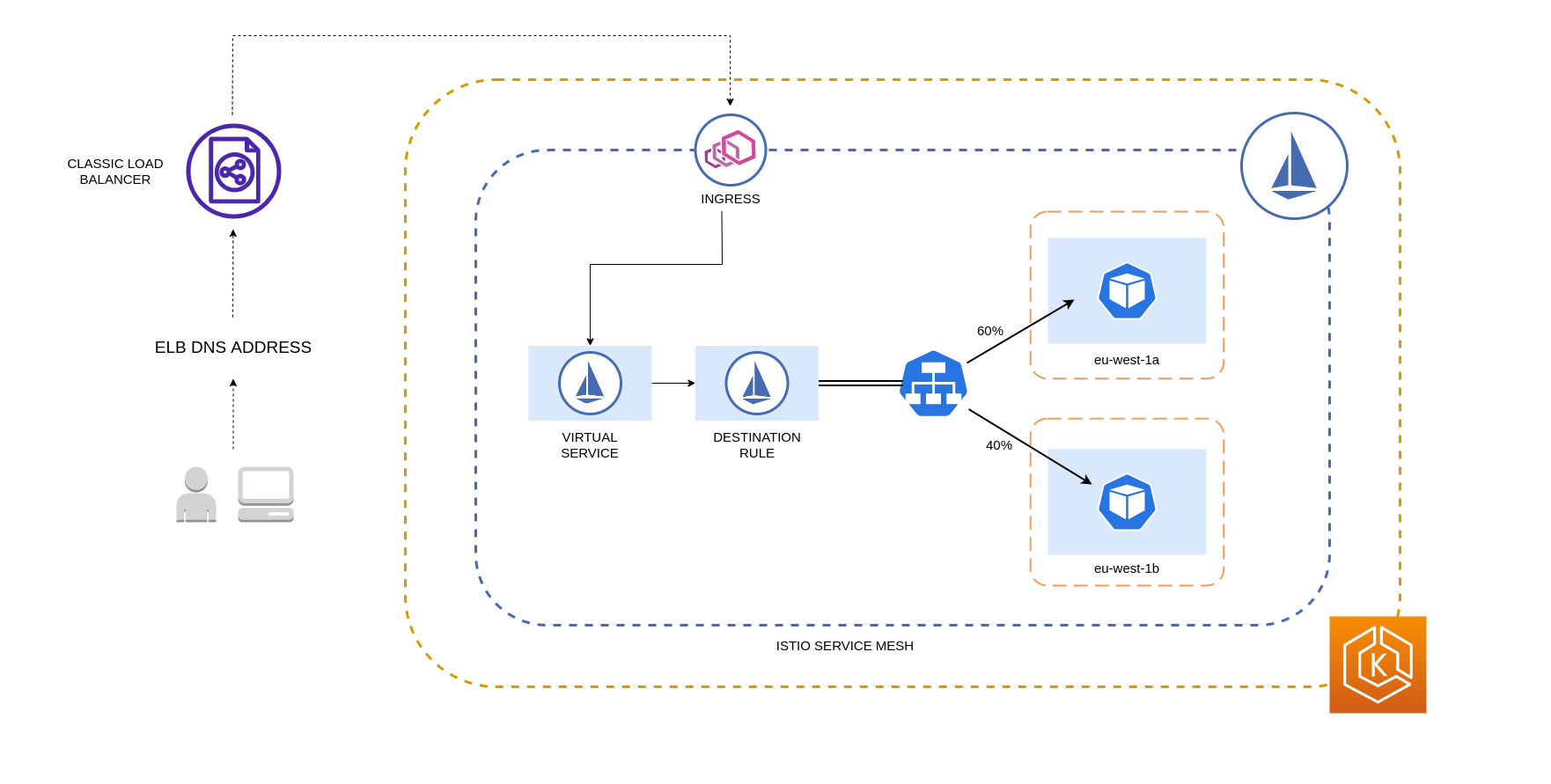
Le regole di destinazione Istio descritte sopra possono essere applicate anche per gestire il traffico da un sistema di bilanciamento del carico ai Pods nel cluster EKS. Le regole di distribuzione ponderate in base alla località possono essere applicate a un servizio che riceve traffico da un sistema di bilanciamento del carico ad alta disponibilità (in particolare Ingress Gateway). Queste regole consentono di controllare la quantità di traffico destinata a destinazione in base alla sua origine zonale, in questo caso il sistema di bilanciamento del carico. Se configurato correttamente, si verificherà una riduzione del traffico in uscita tra le zone rispetto a un sistema di bilanciamento del carico che distribuisce il traffico in modo uniforme o casuale su repliche Pod diverse. AZs
Di seguito è riportato un esempio di blocco di codice di una risorsa Destination Rule in Istio. Come si può vedere di seguito, questa risorsa specifica configurazioni ponderate per il traffico in entrata da 3 diverse località della regione. AZs eu-west-1 Queste configurazioni dichiarano che la maggior parte del traffico in entrata (70% in questo caso) da una determinata AZ deve essere inoltrato tramite proxy a una destinazione nella stessa AZ da cui proviene.
apiVersion: networking.istio.io/v1beta1 kind: DestinationRule metadata: name: express-test-dr spec: host: express-test.default.svc.cluster.local trafficPolicy: loadBalancer: + localityLbSetting: distribute: - from: eu-west-1/eu-west-1a/ + to: "eu-west-1/eu-west-1a/_": 70 "eu-west-1/eu-west-1b/_": 20 "eu-west-1/eu-west-1c/_": 10 - from: eu-west-1/eu-west-1b/_ + to: "eu-west-1/eu-west-1a/_": 20 "eu-west-1/eu-west-1b/_": 70 "eu-west-1/eu-west-1c/_": 10 - from: eu-west-1/eu-west-1c/_ + to: "eu-west-1/eu-west-1a/_": 20 "eu-west-1/eu-west-1b/_": 10 "eu-west-1/eu-west-1c/*": 70** connectionPool: http: http2MaxRequests: 10 maxRequestsPerConnection: 10 outlierDetection: consecutiveGatewayErrors: 1 interval: 1m baseEjectionTime: 30s
Nota
Il peso minimo che può essere distribuito alla destinazione è dell'1%. Il motivo è quello di mantenere le regioni e le zone di failover nel caso in cui gli endpoint nella destinazione principale diventino non integri o non disponibili.
Il diagramma seguente illustra uno scenario in cui esiste un sistema di bilanciamento del carico ad alta disponibilità nella regione eu-west-1 e viene applicata la distribuzione ponderata per località. La politica relativa alla regola di destinazione di questo diagramma è configurata in modo da inviare il 60% del traffico proveniente da eu-west-1a ai Pod nella stessa AZ, mentre il 40% del traffico proveniente da eu-west-1a dovrebbe essere indirizzato ai Pod nell'eu-west-1b.
Limitazione del traffico alle zone e ai nodi di disponibilità
Utilizzo della politica sul traffico interno del servizio con Istio
Per mitigare i costi di rete associati al traffico esterno in entrata e al traffico interno tra i pod, puoi combinare le regole di destinazione di Istio e la politica sul traffico interno del servizio Kubernetes. Il modo di combinare le regole di destinazione di Istio con la politica sul traffico interno del servizio dipenderà in gran parte da 3 fattori:
-
Il ruolo dei microservizi
-
Modelli di traffico di rete tra i microservizi
-
Come devono essere distribuiti i microservizi nella topologia del cluster Kubernetes
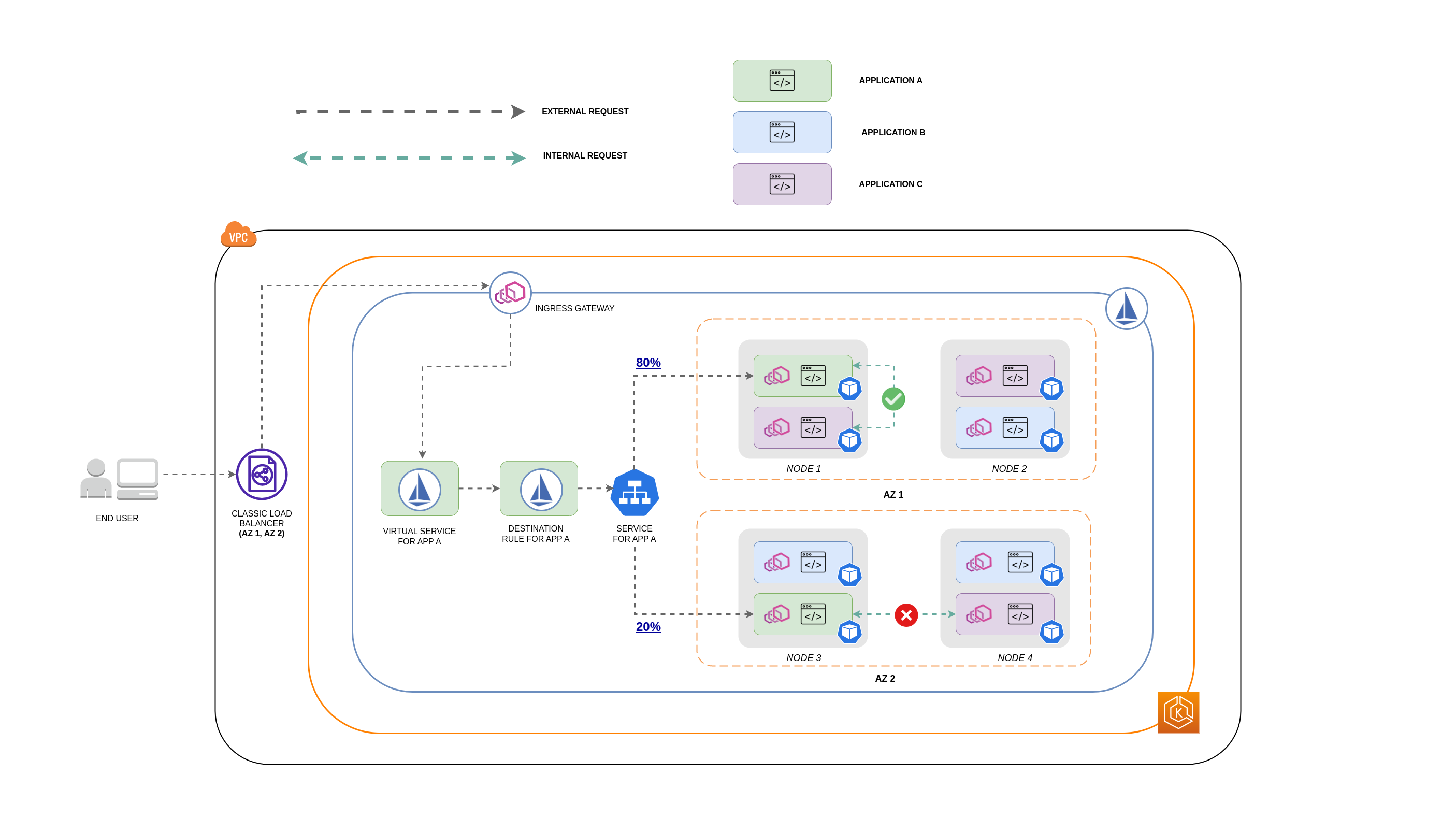
Il diagramma seguente mostra come sarebbe il flusso di rete nel caso di una richiesta annidata e come le politiche sopra menzionate controllerebbero il traffico.
-
L'utente finale invia una richiesta all'APP A, che a sua volta invia una richiesta annidata all'APP C. Questa richiesta viene prima inviata a un sistema di bilanciamento del carico ad alta disponibilità, che dispone di istanze in AZ 1 e AZ 2, come mostra il diagramma precedente.
-
La richiesta esterna in entrata viene quindi indirizzata alla destinazione corretta dal servizio virtuale Istio.
-
Dopo che la richiesta è stata instradata, la regola di destinazione Istio controlla la quantità di traffico destinata alla rispettiva richiesta in AZs base alla sua provenienza (AZ 1 o AZ 2).
-
Il traffico passa quindi al Servizio per l'APP A e viene quindi inoltrato tramite proxy ai rispettivi endpoint Pod. Come mostrato nel diagramma, l'80% del traffico in entrata viene inviato agli endpoint Pod in AZ 1 e il 20% del traffico in entrata viene inviato a AZ 2.
-
L'APP A effettua quindi una richiesta interna all'APP C. Il servizio APP C ha una politica interna sul traffico abilitata (
internalTrafficPolicy`: Local`). -
La richiesta interna dall'APP A (sul NODO 1) all'APP C ha esito positivo grazie all'endpoint locale del nodo disponibile per l'APP C.
-
La richiesta interna dall'APP A (su NODE 3) all'APP C ha esito negativo perché non ci sono endpoint locali del nodo disponibili per l'APP C. Come mostra il diagramma, l'APP C non ha repliche su NODE 3. * *
Le schermate seguenti sono tratte da un esempio dal vivo di questo approccio. La prima serie di schermate mostra una richiesta esterna riuscita a un graphql e una richiesta annidata riuscita da una orders replica co-localizzata sul graphql nodo. ip-10-0-0-151.af-south-1.compute.internal
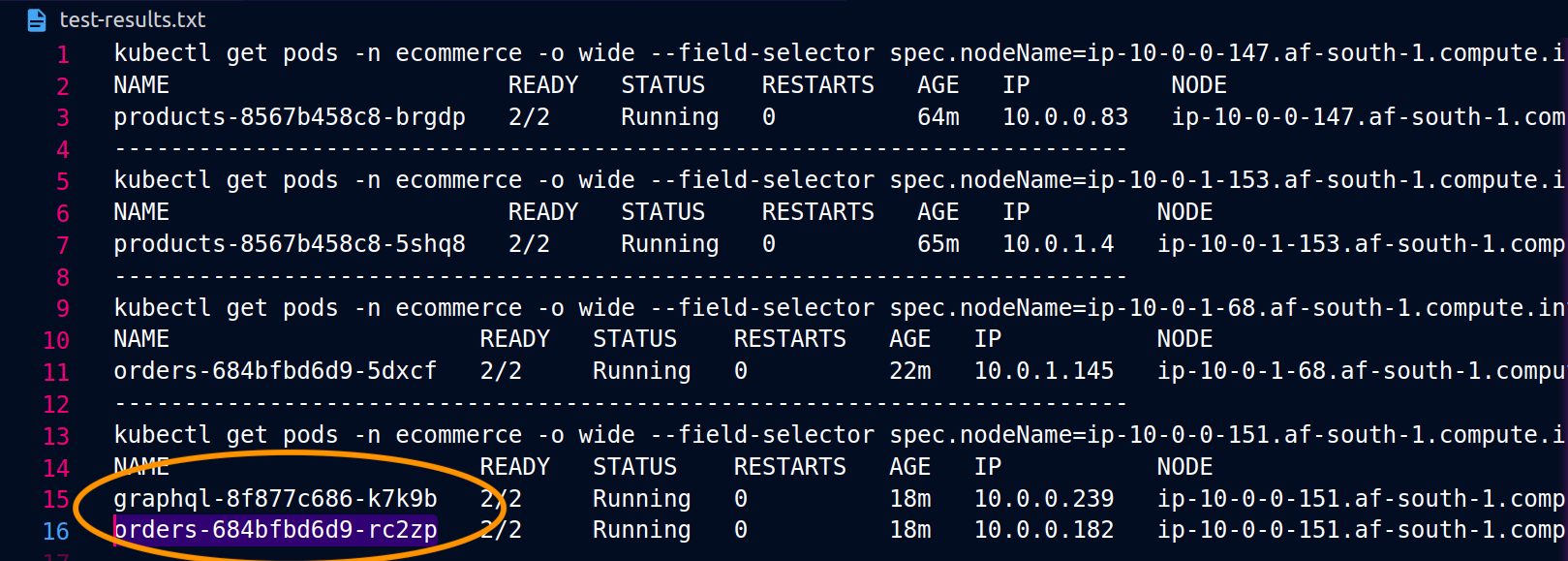
Con Istio, puoi verificare ed esportare le statistiche di qualsiasi [cluster upstream] (https://www.envoyproxy. io/docs/envoy/latest/intro/arch_overview/intro/terminologyorders endpoint di cui è a conoscenza il graphql proxy possono essere ottenuti utilizzando il seguente comando:
kubectl exec -it deploy/graphql -n ecommerce -c istio-proxy -- curl localhost:15000/clusters | grep orders
... orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**rq_error::0** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**rq_success::119** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**rq_timeout::0** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**rq_total::119** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**health_flags::healthy** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**region::af-south-1** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**zone::af-south-1b** ...
In questo caso, il graphql proxy conosce solo l'ordersendpoint della replica con cui condivide un nodo. Se rimuovi l'internalTrafficPolicy: Localimpostazione dal servizio ordini ed esegui nuovamente un comando come quello precedente, i risultati restituiranno tutti gli endpoint delle repliche distribuiti sui diversi nodi. Inoltre, esaminando rq_total i rispettivi endpoint, noterai una condivisione relativamente uniforme nella distribuzione della rete. Di conseguenza, se gli endpoint sono associati a servizi upstream che funzionano in modo diverso AZs, questa distribuzione di rete tra le zone comporterà costi più elevati.
Come indicato nella sezione precedente, è possibile collocare insieme i Pod che comunicano frequentemente utilizzando l'affinità tra i pod.
... spec: ... template: metadata: labels: app: graphql role: api workload: ecommerce spec: affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - orders topologyKey: "kubernetes.io/hostname" nodeSelector: managedBy: karpenter billing-team: ecommerce ...
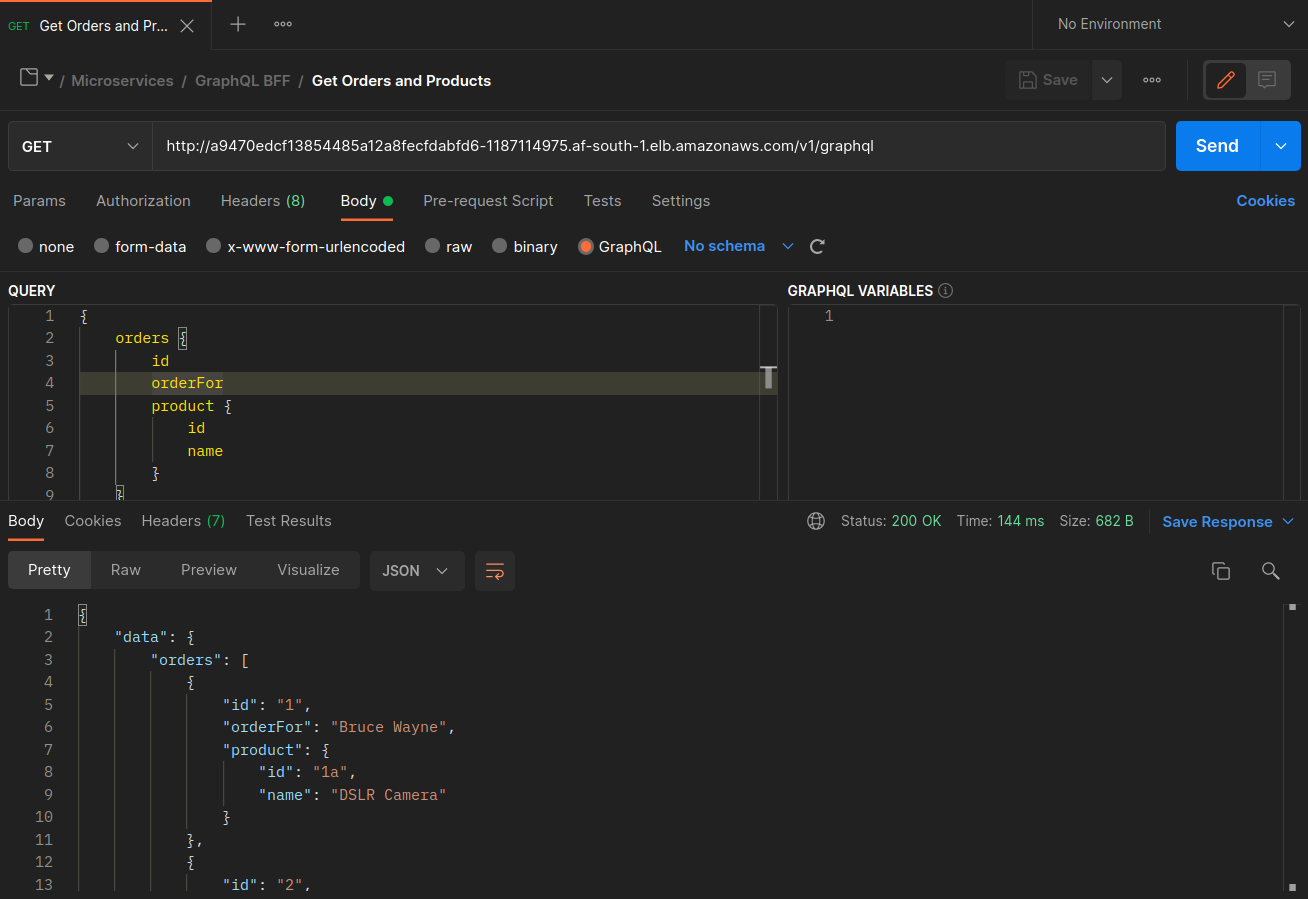
Quando le orders repliche graphql and non coesistono sullo stesso nodo (ip-10-0-0-151.af-south-1.compute.internal), la prima richiesta a graphql ha esito positivo, come indicato nella schermata di Postman riportata di seguito, mentre la 200 response code seconda richiesta annidata da a ha esito negativo con a. graphql orders 503 response code


Risorse aggiuntive
-
Gestione della latenza e dei costi di trasferimento dei dati su EKS utilizzando Istio
-
Ottieni visibilità sui byte di rete da pod a pod di Amazon EKS Cross-AZ
-
Ottimizza i costi e le prestazioni di Kubernetes con Service Internal Traffic Policy
-
Ottimizza i costi e le prestazioni di Kubernetes con Istio e Service Internal Traffic Policy
-
Comprensione dei costi di trasferimento dei dati per i servizi container AWS
