Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Comprensione delle metriche di scalabilità gestita in Amazon EMR
Amazon EMR pubblica i parametri di alta risoluzione con dati a una granularità di un minuto quando il dimensionamento gestito è abilitato per un cluster. Puoi visualizzare gli eventi relativi a ogni avvio e completamento del ridimensionamento controllati dalla scalabilità gestita con la console Amazon EMR o la console Amazon. CloudWatch CloudWatch le metriche sono fondamentali per il funzionamento della scalabilità gestita di Amazon EMR. Ti consigliamo di monitorare attentamente i CloudWatch parametri per assicurarti che non manchino dati. Per ulteriori informazioni su come configurare gli CloudWatch allarmi per rilevare le metriche mancanti, consulta Using Amazon CloudWatch alarms. Per ulteriori informazioni sull'utilizzo CloudWatch degli eventi con Amazon EMR, consulta Monitoraggio CloudWatch degli eventi.
i parametri seguenti indicano le capacità correnti o di destinazione di un cluster. Questi parametri sono disponibili solo quando è abilitata il dimensionamento gestito. Per i cluster composti da parchi istanze, i parametri della capacità del cluster vengono misurate in Units. Per i cluster composti da gruppi di istanze, i parametri della capacità del cluster vengono misurate in Nodes o in vCPU in base al tipo di unità utilizzato nella policy di dimensionamento gestito.
| Parametro | Descrizione |
|---|---|
|
Il numero totale previsto di unità units/nodes/vCPUs in un cluster, determinato dalla scalabilità gestita. Unità: numero |
|
Il numero totale corrente di units/nodes/vCPUs disponibilità in un cluster in esecuzione. Quando viene richiesto il ridimensionamento di un cluster, questo parametro verrà aggiornato dopo l'aggiunta o la rimozione delle nuove istanze dal cluster. Unità: numero |
|
Il numero target di CORE units/nodes/vCPUs in un cluster determinato dalla scalabilità gestita. Unità: numero |
|
Il numero attuale di CORE in units/nodes/vCPUs esecuzione in un cluster. Unità: numero |
|
Il numero target di TASK units/nodes/vCPUs in un cluster determinato dalla scalabilità gestita. Unità: numero |
|
Il numero corrente di TASK in units/nodes/vCPUs esecuzione in un cluster. Unità: numero |
I parametri seguenti indicano lo stato di utilizzo del cluster e delle applicazioni. Questi parametri sono disponibili per tutte le caratteristiche Amazon EMR, ma vengono pubblicati a una risoluzione più elevata con dati a una granularità di un minuto quando il dimensionamento gestito è abilitato per un cluster. È possibile correlare i parametri seguenti con i parametri della capacità del cluster nella tabella precedente per comprendere le decisioni relative al dimensionamento gestito.
| Parametro | Descrizione |
|---|---|
|
|
Il numero di applicazioni inviate a YARN che sono state completate. Caso d'uso: monitorare l'avanzamento del cluster Unità: numero |
|
|
Il numero di applicazioni inviate a YARN che sono in attesa. Caso d'uso: monitorare l'avanzamento del cluster Unità: numero |
|
|
Il numero di applicazioni inviate a YARN che sono in esecuzione. Caso d'uso: monitorare l'avanzamento del cluster Unità: numero |
ContainerAllocated |
Il numero di contenitori di risorse allocati da. ResourceManager Caso d'uso: monitorare l'avanzamento del cluster Unità: numero |
|
|
Il numero di container nella coda non ancora allocati. Caso d'uso: monitorare l'avanzamento del cluster Unità: numero |
ContainerPendingRatio |
Il rapporto tra contenitori in sospeso e contenitori allocati (ContainerPendingRatio = ContainerPending /). ContainerAllocated Se ContainerAllocated = 0, allora ContainerPendingRatio =. ContainerPending Il valore di ContainerPendingRatio rappresenta un numero, non una percentuale. Questo valore è utile per il dimensionamento delle risorse del cluster in funzione del comportamento di attribuzione dei container. Unità: numero |
|
|
La percentuale di storage HDFS attualmente utilizzato. Caso d'uso: analizzare le prestazioni del cluster Unità: percentuale |
|
|
Indica che un cluster non è più in esecuzione ma è ancora attivo e genera spese. È impostato su 1 se non vi sono task e processi in esecuzione, altrimenti è impostato su 0. Questo valore viene verificato a intervalli di cinque minuti e un valore 1 indica unicamente l'inattività del cluster al momento della verifica e non durante i cinque minuti. Per evitare falsi positivi, devi attivare un allarme quando questo valore è 1 durante due o più verifiche consecutive di cinque minuti. Ad esempio, puoi attivare un allarme se questo valore è 1 per trenta minuti o più. Caso d'uso: monitorare le prestazioni del cluster Unità: booleane |
|
|
La quantità di memoria disponibile da allocare. Caso d'uso: monitorare l'avanzamento del cluster Unità: numero |
|
|
Il numero di nodi che attualmente eseguono MapReduce attività o lavori. Equivalente al parametro YARN Caso d'uso: monitorare l'avanzamento del cluster Unità: numero |
|
|
La percentuale di memoria rimanente disponibile per YARN (YARNMemoryAvailablePercentage = MemoryAvailable MB/ MemoryTotal MB). Questo valore è utile per il dimensionamento delle risorse del cluster in funzione dell'utilizzo della memoria di YARN. Unità: percentuale |
Le seguenti metriche forniscono informazioni sulle risorse utilizzate dai contenitori e dai nodi YARN. Queste metriche del gestore delle risorse YARN offrono approfondimenti sulle risorse utilizzate dai contenitori e dai nodi in esecuzione nel cluster. Il confronto di queste metriche con le metriche della capacità del cluster della tabella precedente fornisce un quadro più chiaro dell'impatto della scalabilità gestita:
| Parametro | Versioni associate | Descrizione |
|---|---|---|
|
|
Disponibile con l'etichetta di rilascio 7.3.0 e versioni successive |
Memoria del contenitore consumata* secondi per il periodo di pubblicazione. Unità: GB* secondi |
|
|
Disponibile con l'etichetta di rilascio 7.3.0 e versioni successive |
Il totale del contenitore di filato* secondi per il periodo di pubblicazione. Unità: GB* secondi |
|
|
Disponibile con l'etichetta di rilascio 7.5.0 e versioni successive |
I secondi VCPU del container consumati per il periodo di pubblicazione. Unità: VCPU * secondi |
|
Disponibile con l'etichetta di rilascio 7.5.0 e versioni successive |
Il numero totale di secondi VCPU del container per il periodo di pubblicazione. Unità: VCPU * secondi |
|
|
Disponibile con l'etichetta di rilascio 7.5.0 e versioni successive |
Memoria del nodo consumata* secondi per il periodo di pubblicazione. Unità: GB* secondi |
|
Disponibile con l'etichetta di rilascio 7.5.0 e versioni successive |
Memoria totale del nodo* secondi per il periodo di pubblicazione. Unità: GB* secondi |
|
|
Disponibile con l'etichetta di rilascio 7.3.0 e versioni successive |
I secondi VCPU del nodo utilizzati per il periodo di pubblicazione. Unità: VCPU * secondi |
|
|
Disponibile con l'etichetta di rilascio 7.3.0 e versioni successive |
Il numero totale di secondi VCPU del nodo per il periodo di pubblicazione. Unità: VCPU * secondi |
Grafici dei parametri di dimensionamento gestito
Puoi visualizzare in grafico i parametri per vedere i modelli di carico di lavoro del cluster e le corrispondenti decisioni di dimensionamento adottate dal dimensionamento gestito da Amazon EMR come illustrato nella procedura riportata di seguito.
Per rappresentare graficamente le metriche di scalabilità gestita nella console CloudWatch
-
Apri la CloudWatch console
. -
Nel riquadro di navigazione, seleziona Amazon EMR. È possibile cercare il cluster da monitorare in base al relativo identificatore.
-
Scorrere fino al parametro da rappresentare graficamente. Aprire un parametro per visualizzare il grafico.
-
Per rappresentare graficamente uno o più parametri, seleziona la casella di controllo accanto a ciascun parametro.
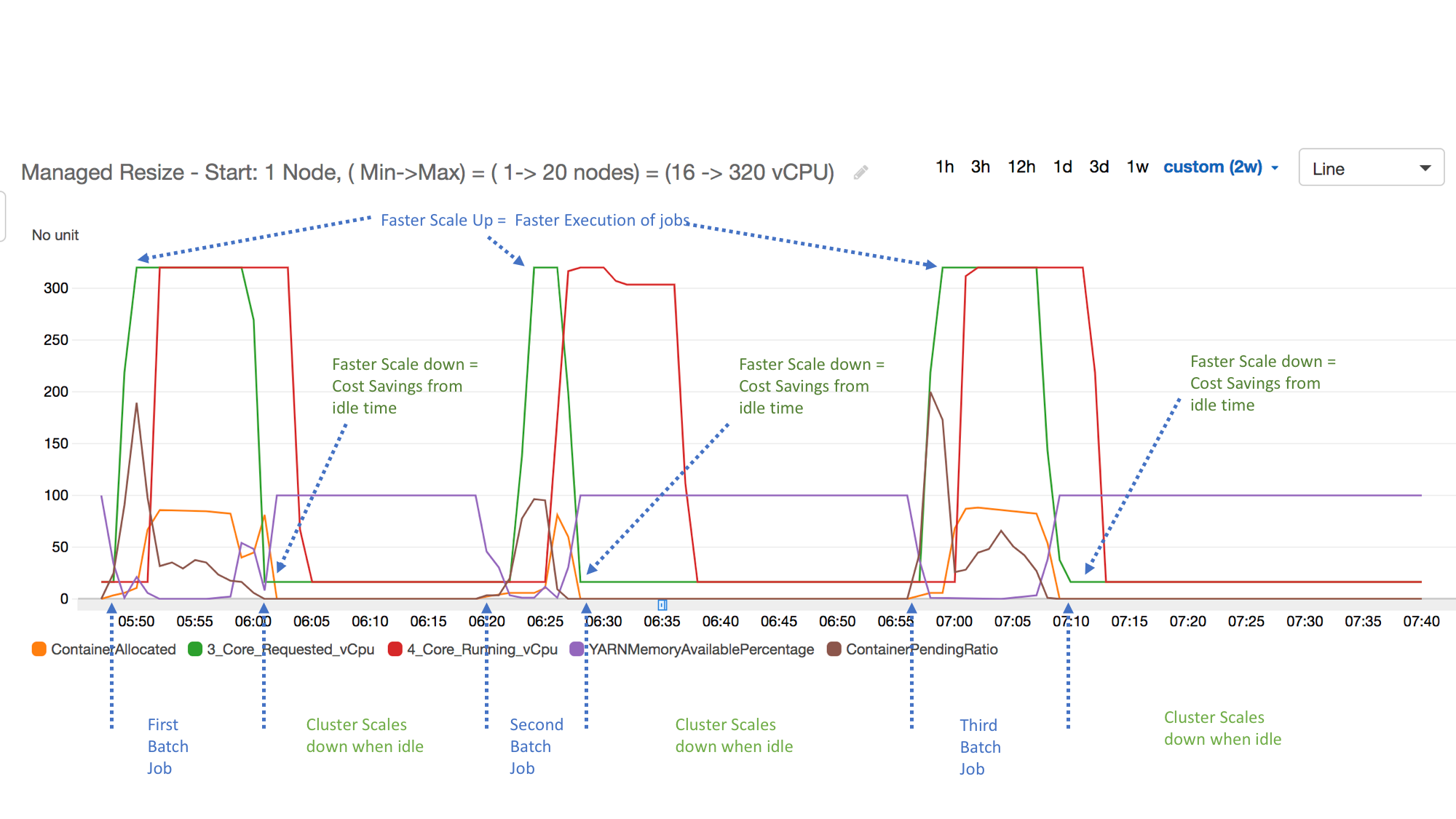
Nell'esempio seguente viene illustrata l'attività di dimensionamento gestito da Amazon EMR di un cluster. Il grafico mostra tre periodi di dimensionamento automatico, che consentono di risparmiare sui costi quando è presente un carico di lavoro meno attivo.
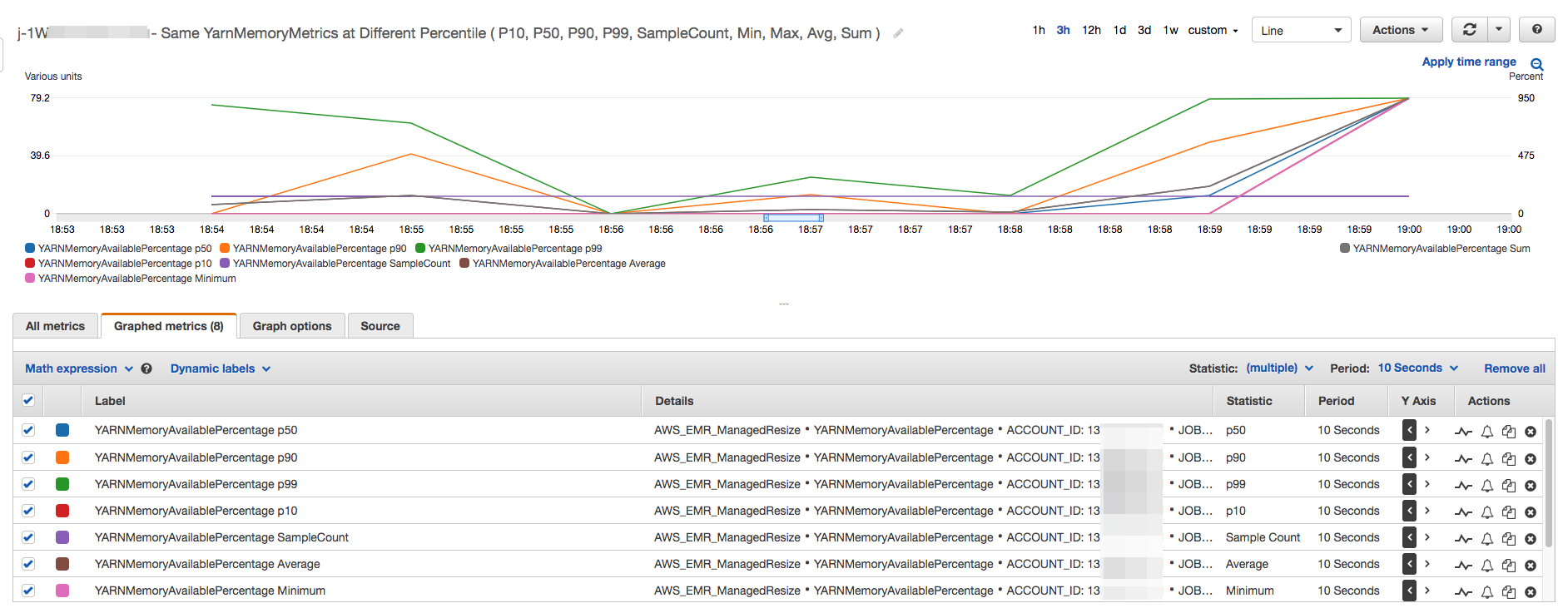
Tutti i parametri relativi alla capacità e all'utilizzo del cluster vengono pubblicati a intervalli di un minuto. Anche altre informazioni statistiche sono associate a ogni dato di un minuto, permettendo il monitoraggio di varie funzioni come Percentiles, Min, Max, Sum, Average, SampleCount.
Ad esempio, il grafico seguente traccia lo stesso parametro YARNMemoryAvailablePercentage in percentili diversi, P10, P50, P90, P99, insieme a Sum, Average, Min, SampleCount.