Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Sviluppo e test di script di processo AWS Glue in locale
Quando sviluppi e testi gli script di processo Spark per AWS Glue, hai a disposizione molteplici opzioni:
Console AWS Glue Studio
Visual editor (Editor visivo)
Editor di script
Notebook AWS Glue Studio
Sessioni interattive
Jupyter Notebook
immagine Docker
Sviluppo locale
Sviluppo remoto
Libreria ETL AWS Glue Studio
Sviluppo locale
Puoi scegliere una delle opzioni sopra elencate in base alle tue esigenze.
Se preferisci un'esperienza priva di codice o con meno codice da gestire, l'editor visivo AWS Glue Studio è un'ottima scelta.
Se preferisci un'esperienza interattiva con notebook, AWS Glue Studio notebook è un'ottima scelta. Per ulteriori informazioni, consulta Utilizzare Notebooks with AWS Glue Studio e AWS Glue Se desideri utilizzare il tuo ambiente locale, le sessioni interattive sono un'ottima scelta. Per ulteriori informazioni, consulta Utilizzare le sessioni interattive con AWS Glue.
Se preferisci un'esperienza di sviluppo locale/remoto, l'immagine Docker è un'ottima scelta. Ciò ti consente di sviluppare e testare gli script di processo Spark per AWS Glue in qualsiasi ambiente, senza dover sostenere i costi di AWS Glue.
Se preferisci uno sviluppo locale senza Docker, l'installazione della directory della libreria ETL AWS Glue in locale è un'ottima scelta.
Sviluppo utilizzando AWS Glue Studio
L'editor visivo AWS Glue Studio è un'interfaccia grafica che consente di creare, eseguire e monitorare in modo semplice processi di estrazione, trasformazione e caricamento (ETL) in AWS Glue. È possibile comporre visivamente flussi di lavoro per la trasformazione dei dati ed eseguirli senza problemi sul motore ETL serverless basato su Apache Spark di AWS Glue. È possibile esaminare lo schema e i risultati dei dati in ogni fase del processo. Per ulteriori informazioni, consulta la Guida per l'utente di AWS Glue Studio.
Sviluppo tramite le sessioni interattive
Le sessioni interattive consentono di creare e testare le applicazioni dall'ambiente che preferisci. Per ulteriori informazioni, consulta Utilizzare le sessioni interattive con AWS Glue.
Sviluppo tramite un'immagine Docker
Nota
Le istruzioni contenute in questa sezione non sono state testate sui sistemi operativi Microsoft Windows.
Per lo sviluppo e i test locali su piattaforme Windows, consulta il blog Come costruire una pipeline ETL AWS Glue localmente senza un account AWS
Per una piattaforma dati pronta per la produzione, il processo di sviluppo e la pipeline CI/CD per i processi AWS Glue sono un argomento chiave. È possibile sviluppare e testare in modo flessibile i processi AWS Glue in un container Docker. AWS Glue ospita immagini Docker su Docker Hub per configurare l'ambiente di sviluppo con utility aggiuntive. È possibile utilizzare il tuo IDE, notebook o REPL preferito utilizzando la libreria ETL AWS Glue. Questo argomento illustra come sviluppare e testare i processi della versione 4.0 di AWS Glue su un container Docker utilizzando l'immagine Docker.
Le seguenti immagini Docker sono disponibili per AWS Glue su Docker Hub.
Per la versione 4.0 di AWS Glue:
amazon/aws-glue-libs:glue_libs_4.0.0_image_01Per AWS Glue versione 3.0:
amazon/aws-glue-libs:glue_libs_3.0.0_image_01Per AWS Glue versione 2.0:
amazon/aws-glue-libs:glue_libs_2.0.0_image_01
Queste immagini sono per x86_64. Si consiglia di eseguire il test su questa architettura. Tuttavia, potrebbe essere possibile rielaborare una soluzione di sviluppo locale su immagini di base non supportate.
In questo esempio viene descritto l'utilizzo di amazon/aws-glue-libs:glue_libs_4.0.0_image_01 e l'esecuzione del container su un computer locale. Questa immagine del container è stata testata per i processi della versione 3.3 di Spark di AWS Glue. Questa immagine contiene quanto segue:
Amazon Linux
Libreria ETL AWS Glue (aws-glue-libs
) Apache Spark 3.3.0
Spark History Server
Jupyter Lab
Livy
Altre dipendenze della libreria (lo stesso set di quelle del sistema di processi AWS Glue)
Completa una delle seguenti sezioni in base alle tue esigenze:
Configurazione del container per l'utilizzo di spark-submit
Configurazione del container per l'utilizzo della shell REPL (PySpark)
Configurazione del container per l'utilizzo di Pytest
Configurazione del container per l'utilizzo di Jupyter Lab
Configurazione del container per l'utilizzo di Visual Studio Code
Prerequisiti
Prima di iniziare, verifica che Docker sia installato e che il daemon Docker sia in esecuzione. Per istruzioni sull'installazione, consulta la documentazione Docker per Mac
Per ulteriori informazioni sulle restrizioni durante lo sviluppo locale del codice AWS Glue, consulta Local Development Restrictions (restrizioni sullo sviluppo locale).
Configurazione di AWS
Per abilitare le chiamate API AWS dal container, configura le credenziali AWS seguendo i passaggi di seguito. Nelle sezioni seguenti, useremo questo profilo denominato AWS.
-
Configura AWS CLI, impostando un profilo denominato. Per ulteriori informazioni sulla configurazione di AWS CLI, consulta Impostazioni del file di configurazione e delle credenziali nella documentazione di AWS CLI.
Esegui il comando seguente in un terminale:
PROFILE_NAME="<your_profile_name>"
Potrebbe anche essere necessario impostare la variabile di ambiente AWS_REGION per specificare la Regione AWS a cui inviare le richieste.
Configurazione ed esecuzione del container
La configurazione del container per eseguire il codice PySpark tramite il comando spark-submit include i seguenti passaggi di alto livello:
Estrarre l'immagine da Docker Hub.
Eseguire il container.
Estrazione dell'immagine da Docker Hub
Esegui il comando seguente per estrarre l'immagine da Docker Hub:
docker pull amazon/aws-glue-libs:glue_libs_4.0.0_image_01
Esecuzione del container
Ora puoi eseguire un container utilizzando questa immagine. Puoi scegliere una delle opzioni seguenti in base alle tue esigenze.
spark-submit
Puoi eseguire uno script di processo di AWS Glue eseguendo il comando spark-submit sul container.
Scrivi lo script e salvalo come
sample1.pynella directory/local_path_to_workspace. Il codice di esempio è incluso come appendice in questo argomento.$ WORKSPACE_LOCATION=/local_path_to_workspace $ SCRIPT_FILE_NAME=sample.py $ mkdir -p ${WORKSPACE_LOCATION}/src $ vim ${WORKSPACE_LOCATION}/src/${SCRIPT_FILE_NAME}Esegui il comando seguente per eseguire il comando
spark-submitsul container per inviare una nuova applicazione Spark:$ docker run -it -v ~/.aws:/home/glue_user/.aws -v $WORKSPACE_LOCATION:/home/glue_user/workspace/ -e AWS_PROFILE=$PROFILE_NAME -e DISABLE_SSL=true --rm -p 4040:4040 -p 18080:18080 --name glue_spark_submit amazon/aws-glue-libs:glue_libs_4.0.0_image_01 spark-submit /home/glue_user/workspace/src/$SCRIPT_FILE_NAME ...22/01/26 09:08:55 INFO DAGScheduler: Job 0 finished: fromRDD at DynamicFrame.scala:305, took 3.639886 s root |-- family_name: string |-- name: string |-- links: array | |-- element: struct | | |-- note: string | | |-- url: string |-- gender: string |-- image: string |-- identifiers: array | |-- element: struct | | |-- scheme: string | | |-- identifier: string |-- other_names: array | |-- element: struct | | |-- lang: string | | |-- note: string | | |-- name: string |-- sort_name: string |-- images: array | |-- element: struct | | |-- url: string |-- given_name: string |-- birth_date: string |-- id: string |-- contact_details: array | |-- element: struct | | |-- type: string | | |-- value: string |-- death_date: string ...-
(Facoltativo) Configura
spark-submitin modo che corrisponda all'ambiente in uso. Ad esempio, puoi trasferire le dipendenze con la configurazione--jars. Per ulteriori informazioni, consulta Avvio delle applicazioni con spark-submitnella documentazione di Spark.
Shell REPL (Pyspark)
Puoi eseguire la shell REPL (read-eval-print loop) per lo sviluppo interattivo.
Esegui il seguente comando per eseguire il comando PySpark sul container per avviare la shell REPL:
$ docker run -it -v ~/.aws:/home/glue_user/.aws -e AWS_PROFILE=$PROFILE_NAME -e DISABLE_SSL=true --rm -p 4040:4040 -p 18080:18080 --name glue_pyspark amazon/aws-glue-libs:glue_libs_4.0.0_image_01 pyspark ... ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 3.1.1-amzn-0 /_/ Using Python version 3.7.10 (default, Jun 3 2021 00:02:01) Spark context Web UI available at http://56e99d000c99:4040 Spark context available as 'sc' (master = local[*], app id = local-1643011860812). SparkSession available as 'spark'. >>>
Pytest
Per l'unit test, puoi utilizzare pytest per gli script di processo Spark di AWS Glue.
Esegui i comandi seguenti per la preparazione.
$ WORKSPACE_LOCATION=/local_path_to_workspace $ SCRIPT_FILE_NAME=sample.py $ UNIT_TEST_FILE_NAME=test_sample.py $ mkdir -p ${WORKSPACE_LOCATION}/tests $ vim ${WORKSPACE_LOCATION}/tests/${UNIT_TEST_FILE_NAME}
Esegui il comando seguente per eseguire pytest nella suite di test:
$ docker run -it -v ~/.aws:/home/glue_user/.aws -v $WORKSPACE_LOCATION:/home/glue_user/workspace/ -e AWS_PROFILE=$PROFILE_NAME -e DISABLE_SSL=true --rm -p 4040:4040 -p 18080:18080 --name glue_pytest amazon/aws-glue-libs:glue_libs_4.0.0_image_01 -c "python3 -m pytest" starting org.apache.spark.deploy.history.HistoryServer, logging to /home/glue_user/spark/logs/spark-glue_user-org.apache.spark.deploy.history.HistoryServer-1-5168f209bd78.out *============================================================= test session starts ============================================================= *platform linux -- Python 3.7.10, pytest-6.2.3, py-1.11.0, pluggy-0.13.1 rootdir: /home/glue_user/workspace plugins: anyio-3.4.0 *collected 1 item * tests/test_sample.py . [100%] ============================================================== warnings summary =============================================================== tests/test_sample.py::test_counts /home/glue_user/spark/python/pyspark/sql/context.py:79: DeprecationWarning: Deprecated in 3.0.0. Use SparkSession.builder.getOrCreate() instead. DeprecationWarning) -- Docs: https://docs.pytest.org/en/stable/warnings.html ======================================================== 1 passed, *1 warning* in 21.07s ========================================================
Jupyter Lab
Puoi avviare Jupyter per lo sviluppo interattivo e le query ad hoc sui notebook.
Esegui il comando seguente per avviare Jupyter Lab:
$ JUPYTER_WORKSPACE_LOCATION=/local_path_to_workspace/jupyter_workspace/ $ docker run -it -v ~/.aws:/home/glue_user/.aws -v $JUPYTER_WORKSPACE_LOCATION:/home/glue_user/workspace/jupyter_workspace/ -e AWS_PROFILE=$PROFILE_NAME -e DISABLE_SSL=true --rm -p 4040:4040 -p 18080:18080 -p 8998:8998 -p 8888:8888 --name glue_jupyter_lab amazon/aws-glue-libs:glue_libs_4.0.0_image_01 /home/glue_user/jupyter/jupyter_start.sh ... [I 2022-01-24 08:19:21.368 ServerApp] Serving notebooks from local directory: /home/glue_user/workspace/jupyter_workspace [I 2022-01-24 08:19:21.368 ServerApp] Jupyter Server 1.13.1 is running at: [I 2022-01-24 08:19:21.368 ServerApp] http://faa541f8f99f:8888/lab [I 2022-01-24 08:19:21.368 ServerApp] or http://127.0.0.1:8888/lab [I 2022-01-24 08:19:21.368 ServerApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).Apri http://127.0.0.1:8888/lab nel browser web del tuo computer locale, per visualizzare l'interfaccia utente di Jupyter lab.
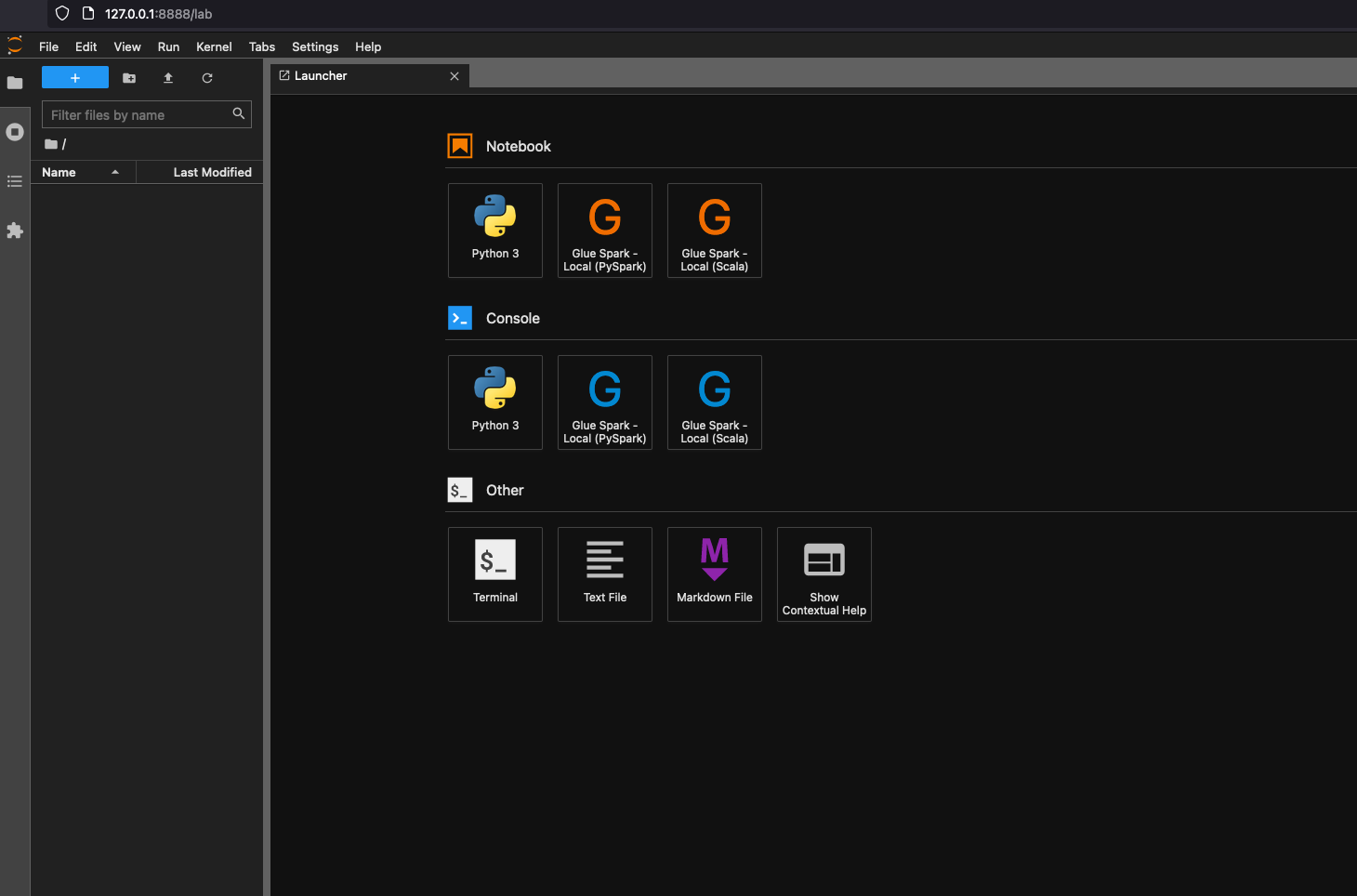
Scegli Glue Spark Local (PySpark) in Notebook. Puoi iniziare a sviluppare codice nell'interfaccia utente interattiva del notebook Jupyter.
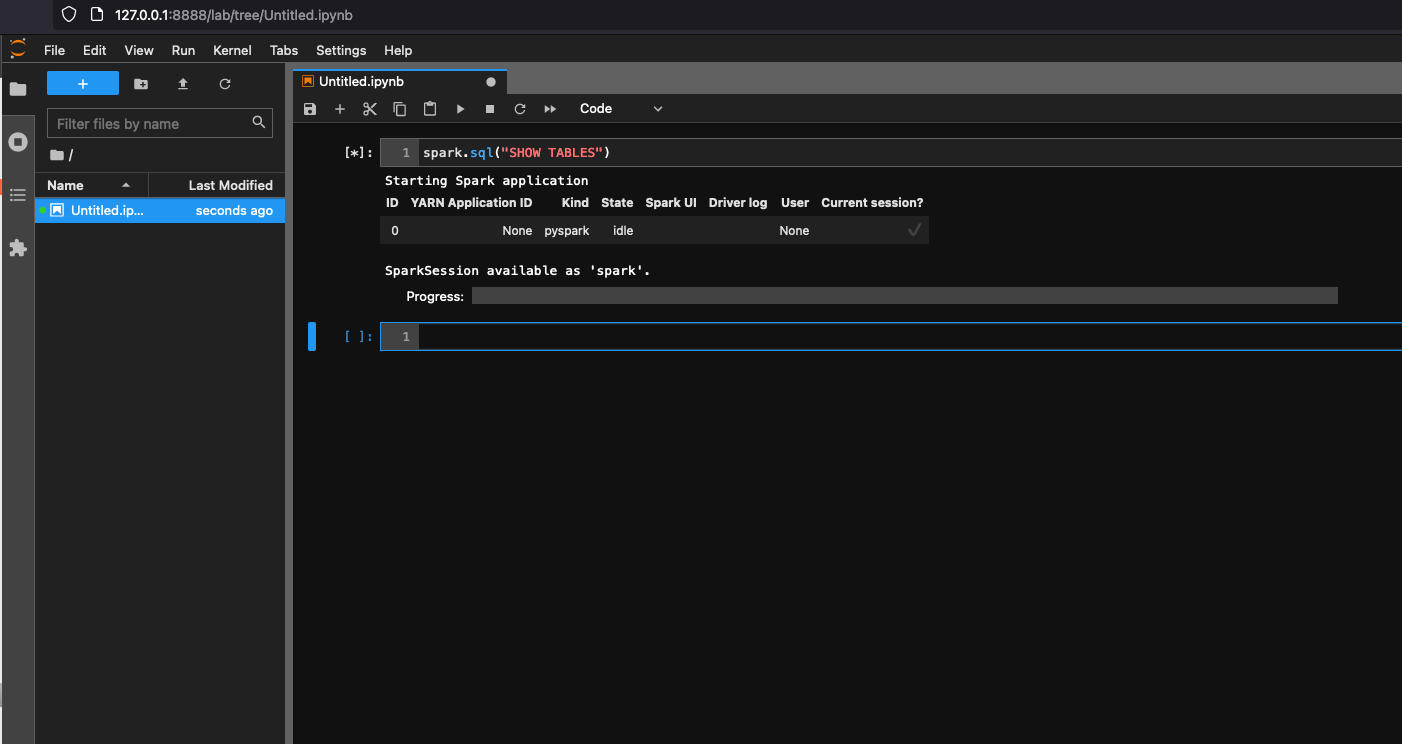
Configurazione del container per l'utilizzo di Visual Studio Code
Prerequisiti:
Installare Visual Studio Code.
Installare Python
. Installare Visual Studio Code Remote - Containers
(Visual Studio Code Remote - Container) Aprire la cartella del WorkSpace in Visual Studio Code.
Selezionare Settings (Impostazioni).
Scegliere WorkSpace.
Scegliere Open Settings (JSON) (Apri impostazioni [JSON]).
Incollare il seguente codice JSON e salvarlo.
{ "python.defaultInterpreterPath": "/usr/bin/python3", "python.analysis.extraPaths": [ "/home/glue_user/aws-glue-libs/PyGlue.zip:/home/glue_user/spark/python/lib/py4j-0.10.9-src.zip:/home/glue_user/spark/python/", ] }
Fasi:
Eseguire il container Docker.
$ docker run -it -v ~/.aws:/home/glue_user/.aws -v $WORKSPACE_LOCATION:/home/glue_user/workspace/ -e AWS_PROFILE=$PROFILE_NAME -e DISABLE_SSL=true --rm -p 4040:4040 -p 18080:18080 --name glue_pyspark amazon/aws-glue-libs:glue_libs_4.0.0_image_01 pysparkAvviare Visual Studio Code.
Scegliere Remote Explorer nel menu a sinistra, quindi
amazon/aws-glue-libs:glue_libs_4.0.0_image_01.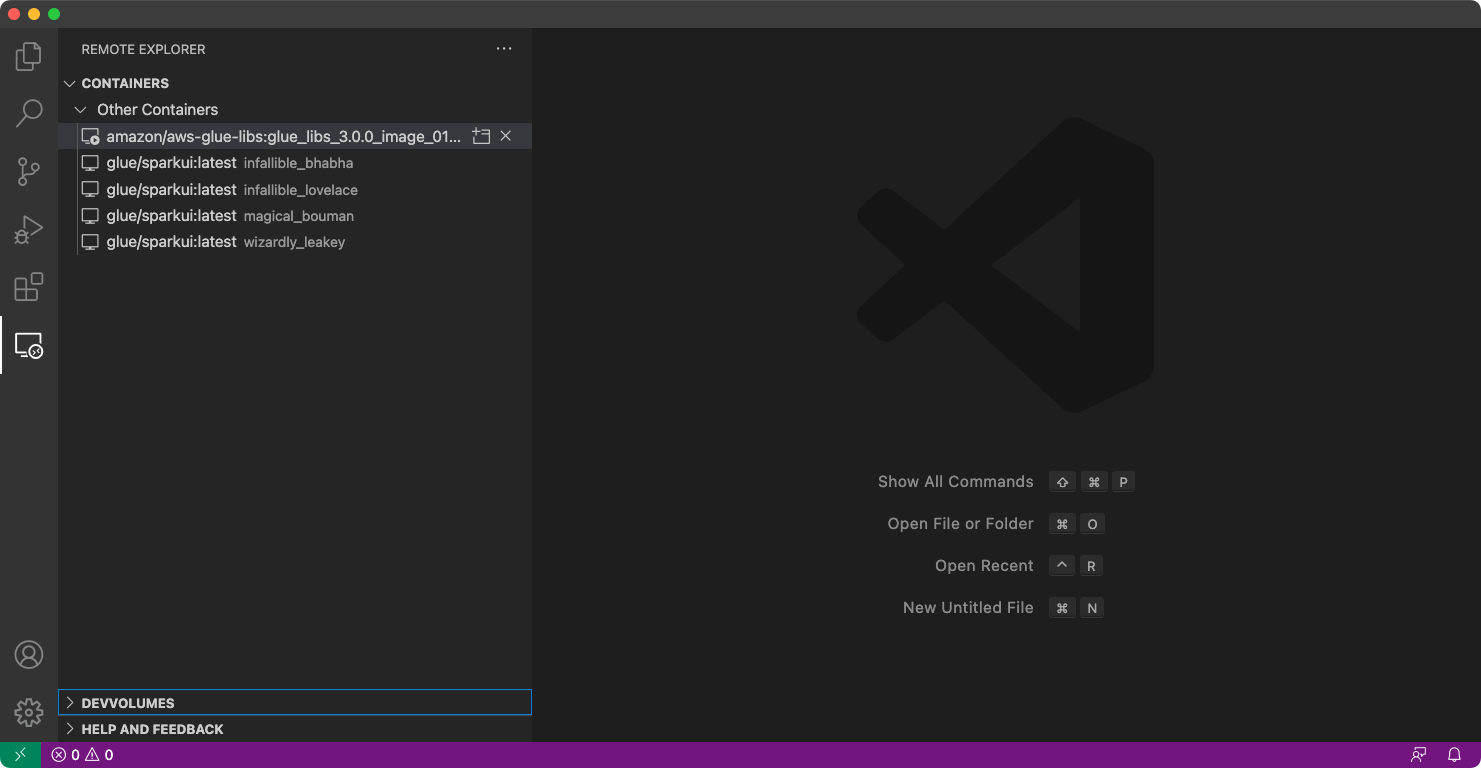
Cliccare con il tasto destro e scegliere Attach to Container (Allega al container). Se viene visualizzata una finestra di dialogo, scegliere Got it (Fatto).
Aprire
/home/glue_user/workspace/.Creare uno script Glue PySpark e scegliere Run (Esegui).
Visualizzerai l'esecuzione corretta dello script.

Appendice: codice di esempio di processo di AWS Glue per i test
Questa appendice fornisce script come codice di esempio di processo di AWS Glue per motivi di test.
sample.py: codice di esempio per utilizzare la libreria ETL AWS Glue con una chiamata API di Amazon S3
import sys from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job from awsglue.utils import getResolvedOptions class GluePythonSampleTest: def __init__(self): params = [] if '--JOB_NAME' in sys.argv: params.append('JOB_NAME') args = getResolvedOptions(sys.argv, params) self.context = GlueContext(SparkContext.getOrCreate()) self.job = Job(self.context) if 'JOB_NAME' in args: jobname = args['JOB_NAME'] else: jobname = "test" self.job.init(jobname, args) def run(self): dyf = read_json(self.context, "s3://awsglue-datasets/examples/us-legislators/all/persons.json") dyf.printSchema() self.job.commit() def read_json(glue_context, path): dynamicframe = glue_context.create_dynamic_frame.from_options( connection_type='s3', connection_options={ 'paths': [path], 'recurse': True }, format='json' ) return dynamicframe if __name__ == '__main__': GluePythonSampleTest().run()
Il codice di cui sopra richiede le autorizzazioni Amazon S3 in AWS IAM. È necessario concedere la policy gestita da IAM arn:aws:iam::aws:policy/AmazonS3ReadOnlyAccess o una policy personalizzata IAM che consente di chiamare ListBucket e GetObject per il percorso Amazon S3.
test_sample.py: codice di esempio per l'unit test di sample.py.
import pytest from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job from awsglue.utils import getResolvedOptions import sys from src import sample @pytest.fixture(scope="module", autouse=True) def glue_context(): sys.argv.append('--JOB_NAME') sys.argv.append('test_count') args = getResolvedOptions(sys.argv, ['JOB_NAME']) context = GlueContext(SparkContext.getOrCreate()) job = Job(context) job.init(args['JOB_NAME'], args) yield(context) job.commit() def test_counts(glue_context): dyf = sample.read_json(glue_context, "s3://awsglue-datasets/examples/us-legislators/all/persons.json") assert dyf.toDF().count() == 1961
Sviluppo tramite la libreria ETL AWS Glue
La libreria ETL AWS Glue è disponibile in un bucket Amazon S3 pubblico e può essere utilizzata dal sistema di compilazione Apache Maven. Questo consente di sviluppare e testare gli script di estrazione, trasformazione e caricamento (ETL) Python e Scala in locale, senza la necessità di una connessione di rete. Consigliamo lo sviluppo locale con l'immagine Docker, in quanto fornisce un ambiente correttamente configurato per l'uso di questa libreria.
Lo sviluppo locale è disponibile per tutte le versioni di AWS Glue, tra cui le versioni di AWS Glue 0.9, 1.0, 2.0 e successive. Per informazioni sulle versioni di Python e Apache Spark disponibili con AWS Glue, consulta Glue version job property.
La libreria viene rilasciata con la licenza software Amazon (https://aws.amazon.com/asl
Limitazioni di sviluppo locali
Tieni presente le seguenti limitazioni quando utilizzi la libreria Scala di AWS Glue per sviluppare localmente.
-
Evita di creare un jar di assembly ("fat jar" o "uber jar") con la libreria AWS Glue, in quanto causa la disabilitazione delle seguenti caratteristiche:
-
Writer AWS Glue Parquet (Utilizzo del formato Parquet in AWS Glue)
Queste caratteristiche sono disponibili solo all'interno del sistema di processi AWS Glue.
-
La trasformazione FindMatches non è supportata con lo sviluppo locale.
-
Il lettore CSV SIMD vettorializzato non è supportato nello sviluppo locale.
-
La proprietà customJdbcDriverS3Path per il caricamento del driver JDBC dal percorso S3 non è supportata nello sviluppo locale. In alternativa, puoi scaricare il driver JDBC in locale e caricarlo da lì.
-
Qualità dei dati di Glue non è supportato nello sviluppo locale.
Sviluppo in locale con Python
Completa alcune fasi preliminari, quindi utilizza le utilità AWS Glue per testare e inviare lo script ETL Python.
Prerequisiti per lo sviluppo in locale con Python
Completa queste fasi per preparare allo sviluppo di Python locale:
-
Clona il repository Python AWS Glue da GitHub (https://github.com/awslabs/aws-glue-libs
). -
Completa una delle seguenti operazioni:
Per AWS Glue versione 0.9, controlla il ramo
glue-0.9.Per AWS Glue versione 1.0, controlla il ramo
glue-1.0. Tutte le versioni successive a AWS Glue 0.9 supportano Python 3.Per AWS Glue versione 2.0, controlla il ramo
glue-2.0.Per AWS Glue versione 3.0, controlla il ramo
glue-3.0.Per AWS Glue versione 4.0, controlla il ramo
master.
-
Installa Apache Maven dal seguente percorso: https://aws-glue-etl-artifacts.s3.amazonaws.com/glue-common/apache-maven-3.6.0-bin.tar.gz
. -
Installa la distribuzione Apache Spark da uno dei seguenti percorsi:
Per AWS Glue versione 0.9: https://aws-glue-etl-artifacts.s3.amazonaws.com/glue-0.9/spark-2.2.1-bin-hadoop2.7.tgz
Per AWS Glue versione 1.0: https://aws-glue-etl-artifacts.s3.amazonaws.com/glue-1.0/spark-2.4.3-bin-hadoop2.8.tgz
Per AWS Glue versione 2.0: https://aws-glue-etl-artifacts.s3.amazonaws.com/glue-2.0/spark-2.4.3-bin-hadoop2.8.tgz
Per AWS Glue versione 3.0: https://aws-glue-etl-artifacts.s3.amazonaws.com/glue-3.0/spark-3.1.1-amzn-0-bin-3.2.1-amzn-3.tgz
Per la versione 4.0 di AWS Glue: https://aws-glue-etl-artifacts.s3.amazonaws.com/glue-4.0/spark-3.3.0-amzn-1-bin-3.3.3-amzn-0.tgz
-
Esporta la variabile di ambiente
SPARK_HOMEimpostandola sulla posizione della radice estratta dall'archivio Spark. Ad esempio:Per AWS Glue versione 0.9:
export SPARK_HOME=/home/$USER/spark-2.2.1-bin-hadoop2.7Per AWS Glue versione 1.0 e 2.0:
export SPARK_HOME=/home/$USER/spark-2.4.3-bin-spark-2.4.3-bin-hadoop2.8Per AWS Glue versione 3.0:
export SPARK_HOME=/home/$USER/spark-3.1.1-amzn-0-bin-3.2.1-amzn-3Per la versione 4.0 di AWS Glue:
export SPARK_HOME=/home/$USER/spark-3.3.0-amzn-1-bin-3.3.3-amzn-0
Esecuzione dello script ETL Python
Con i file jar AWS Glue disponibili per lo sviluppo locale, puoi eseguire il pacchetto AWS Glue Python in locale.
Utilizza le seguenti utilità e framework per testare ed eseguire lo script Python. I comandi elencati nella tabella seguente vengono eseguiti dalla directory root del pacchetto AWS Glue Python
| Utility | Comando | Descrizione |
|---|---|---|
| AWS Glue Shell | ./bin/gluepyspark |
Inserisci ed esegui script Python in una shell che si integra con le librerie ETL AWS Glue. |
| Invio AWS Glue | ./bin/gluesparksubmit |
Invia uno script Python completo per l'esecuzione. |
| Pytest | ./bin/gluepytest |
Scrivi ed esegui unit test del codice Python. Il modulo pytest deve essere installato e disponibile in PATH. Per ulteriori informazioni, consulta la documentazione del pytest |
Sviluppo in locale con Scala
Completa alcune fasi preliminari, quindi emetti un comando Maven per eseguire lo script ETL Scala in locale.
Prerequisiti per lo sviluppo in locale con Scala
Completa queste fasi per la preparazione allo sviluppo Scala locale.
Fase 1: installare il software
In questa fase devi installare il software e impostare la variabile di ambiente richiesta.
-
Installa Apache Maven dal seguente percorso: https://aws-glue-etl-artifacts.s3.amazonaws.com/glue-common/apache-maven-3.6.0-bin.tar.gz
. -
Installa la distribuzione Apache Spark da uno dei seguenti percorsi:
Per AWS Glue versione 0.9: https://aws-glue-etl-artifacts.s3.amazonaws.com/glue-0.9/spark-2.2.1-bin-hadoop2.7.tgz
Per AWS Glue versione 1.0: https://aws-glue-etl-artifacts.s3.amazonaws.com/glue-1.0/spark-2.4.3-bin-hadoop2.8.tgz
Per AWS Glue versione 2.0: https://aws-glue-etl-artifacts.s3.amazonaws.com/glue-2.0/spark-2.4.3-bin-hadoop2.8.tgz
Per AWS Glue versione 3.0: https://aws-glue-etl-artifacts.s3.amazonaws.com/glue-3.0/spark-3.1.1-amzn-0-bin-3.2.1-amzn-3.tgz
Per la versione 4.0 di AWS Glue: https://aws-glue-etl-artifacts.s3.amazonaws.com/glue-4.0/spark-3.3.0-amzn-1-bin-3.3.3-amzn-0.tgz
-
Esporta la variabile di ambiente
SPARK_HOMEimpostandola sulla posizione della radice estratta dall'archivio Spark. Ad esempio:Per AWS Glue versione 0.9:
export SPARK_HOME=/home/$USER/spark-2.2.1-bin-hadoop2.7Per AWS Glue versione 1.0 e 2.0:
export SPARK_HOME=/home/$USER/spark-2.4.3-bin-spark-2.4.3-bin-hadoop2.8Per AWS Glue versione 3.0:
export SPARK_HOME=/home/$USER/spark-3.1.1-amzn-0-bin-3.2.1-amzn-3Per la versione 4.0 di AWS Glue:
export SPARK_HOME=/home/$USER/spark-3.3.0-amzn-1-bin-3.3.3-amzn-0
Fase 2: configurare il progetto Maven
Utilizza il file pom.xml seguente come un modello per le applicazioni Scala AWS Glue. Contiene gli elementi obbligatori plugins, dependencies e repositories. Sostituisci la stringa Glue version con uno dei seguenti:
-
4.0.0per AWS Glue versione 4.0 -
3.0.0per AWS Glue versione 3.0 -
1.0.0per AWS Glue versione 1.0 o 2.0 -
0.9.0per AWS Glue versione 0.9
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.amazonaws</groupId> <artifactId>AWSGlueApp</artifactId> <version>1.0-SNAPSHOT</version> <name>${project.artifactId}</name> <description>AWS ETL application</description> <properties> <scala.version>2.11.1 for AWS Glue 2.0 or below, 2.12.7 for AWS Glue 3.0 and 4.0</scala.version> <glue.version>Glue version with three numbers (as mentioned earlier)</glue.version> </properties> <dependencies> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>${scala.version}</version> <!-- A "provided" dependency, this will be ignored when you package your application --> <scope>provided</scope> </dependency> <dependency> <groupId>com.amazonaws</groupId> <artifactId>AWSGlueETL</artifactId> <version>${glue.version}</version> <!-- A "provided" dependency, this will be ignored when you package your application --> <scope>provided</scope> </dependency> </dependencies> <repositories> <repository> <id>aws-glue-etl-artifacts</id> <url>https://aws-glue-etl-artifacts.s3.amazonaws.com/release/</url> </repository> </repositories> <build> <sourceDirectory>src/main/scala</sourceDirectory> <plugins> <plugin> <!-- see http://davidb.github.com/scala-maven-plugin --> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.4.0</version> <executions> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> </execution> </executions> </plugin> <plugin> <groupId>org.codehaus.mojo</groupId> <artifactId>exec-maven-plugin</artifactId> <version>1.6.0</version> <executions> <execution> <goals> <goal>java</goal> </goals> </execution> </executions> <configuration> <systemProperties> <systemProperty> <key>spark.master</key> <value>local[*]</value> </systemProperty> <systemProperty> <key>spark.app.name</key> <value>localrun</value> </systemProperty> <systemProperty> <key>org.xerial.snappy.lib.name</key> <value>libsnappyjava.jnilib</value> </systemProperty> </systemProperties> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-enforcer-plugin</artifactId> <version>3.0.0-M2</version> <executions> <execution> <id>enforce-maven</id> <goals> <goal>enforce</goal> </goals> <configuration> <rules> <requireMavenVersion> <version>3.5.3</version> </requireMavenVersion> </rules> </configuration> </execution> </executions> </plugin> <!-- The shade plugin will be helpful in building a uberjar or fatjar. You can use this jar in the AWS Glue runtime environment. For more information, see https://maven.apache.org/plugins/maven-shade-plugin/ --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>3.2.4</version> <configuration> <!-- any other shade configurations --> </configuration> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> </execution> </executions> </plugin> </plugins> </build> </project>
Esecuzione dello script ETL Scala
Esegui il comando seguente dalla directory root del progetto Maven per eseguire lo script ETL Scala.
mvn exec:java -Dexec.mainClass="mainClass" -Dexec.args="--JOB-NAMEjobName"
Sostituisci mainClass con il nome della classe completo della classe principale dello script. Sostituisci jobName con il nome del processo desiderato.
Configurazione di un ambiente di test
Per esempi di configurazione di un ambiente di test locale, consulta i seguenti articoli del blog:
Per utilizzare endpoint di sviluppo o notebook per testare gli script ETL, consulta Utilizzo di endpoint per lo sviluppo di script.
Nota
Gli endpoint di sviluppo non sono supportati per l'utilizzo con i processi AWS Glue versione 2.0. Per ulteriori informazioni, consulta Esecuzione di processi ETL Spark con tempi di avvio ridotti.
