Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Rilevamento delle anomalie in Qualità dei dati di AWS Glue
Gli ingegneri gestiscono centinaia di pipeline di dati contemporaneamente. Ogni pipeline può estrarre dati da varie fonti e caricarli nel data lake o in altri archivi di dati. Per garantire che vengano forniti dati di alta qualità ai fini del processo decisionale, stabiliscono regole sulla qualità dei dati. Queste regole valutano i dati sulla base di criteri fissi che riflettono lo stato attuale delle attività. Tuttavia, quando l'ambiente aziendale cambia, le proprietà dei dati cambiano, rendendo questi criteri fissi obsoleti e causando una scarsa qualità dei dati.
Ad esempio, un ingegnere dei dati di un'azienda di vendita al dettaglio ha stabilito una regola che stabilisce che le vendite giornaliere devono superare una one-million-dollar soglia. Dopo alcuni mesi, le vendite giornaliere hanno superato i due milioni di dollari, rendendo la soglia obsoleta. Il data engineer non è riuscito ad aggiornare le regole in modo che rispecchino le soglie più recenti a causa della mancanza di notifica e dello sforzo richiesto per analizzare e aggiornare manualmente la regola. Nel corso del mese, gli utenti aziendali hanno notato un calo delle vendite del 25%. Dopo ore di indagini, i tecnici dei dati hanno scoperto che una pipeline ETL responsabile dell'estrazione dei dati da alcuni archivi aveva fallito senza generare errori. La regola con soglie obsolete ha continuato a funzionare correttamente senza rilevare questo problema.
In alternativa, gli avvisi proattivi in grado di rilevare queste anomalie avrebbero potuto consentire agli utenti di rilevare questo problema. Inoltre, il monitoraggio della stagionalità nelle aziende può evidenziare importanti problemi di qualità dei dati. Ad esempio, le vendite al dettaglio possono essere più elevate nei fine settimana e durante le festività natalizie, mentre relativamente basse nei giorni feriali. La divergenza da questo modello può indicare problemi di qualità dei dati o cambiamenti nelle circostanze aziendali. Le regole sulla qualità dei dati non sono in grado di rilevare i modelli stagionali, poiché ciò richiede algoritmi avanzati in grado di imparare dai modelli passati, che catturano la stagionalità per rilevare le deviazioni.
Infine, gli utenti trovano difficile creare e mantenere regole a causa della natura tecnica del processo di creazione delle regole e del tempo necessario per crearle. Di conseguenza, preferiscono esplorare le informazioni approfondite sui dati prima di definire le regole. I clienti devono poter individuare le anomalie con facilità, in modo da rilevare in modo proattivo i problemi di qualità dei dati e prendere decisioni aziendali sicure.
Come funziona
Nota
Il rilevamento delle anomalie è supportato solo in AWS Glue ETL. Questo non è supportato nella qualità dei dati basata su Data Catalog.
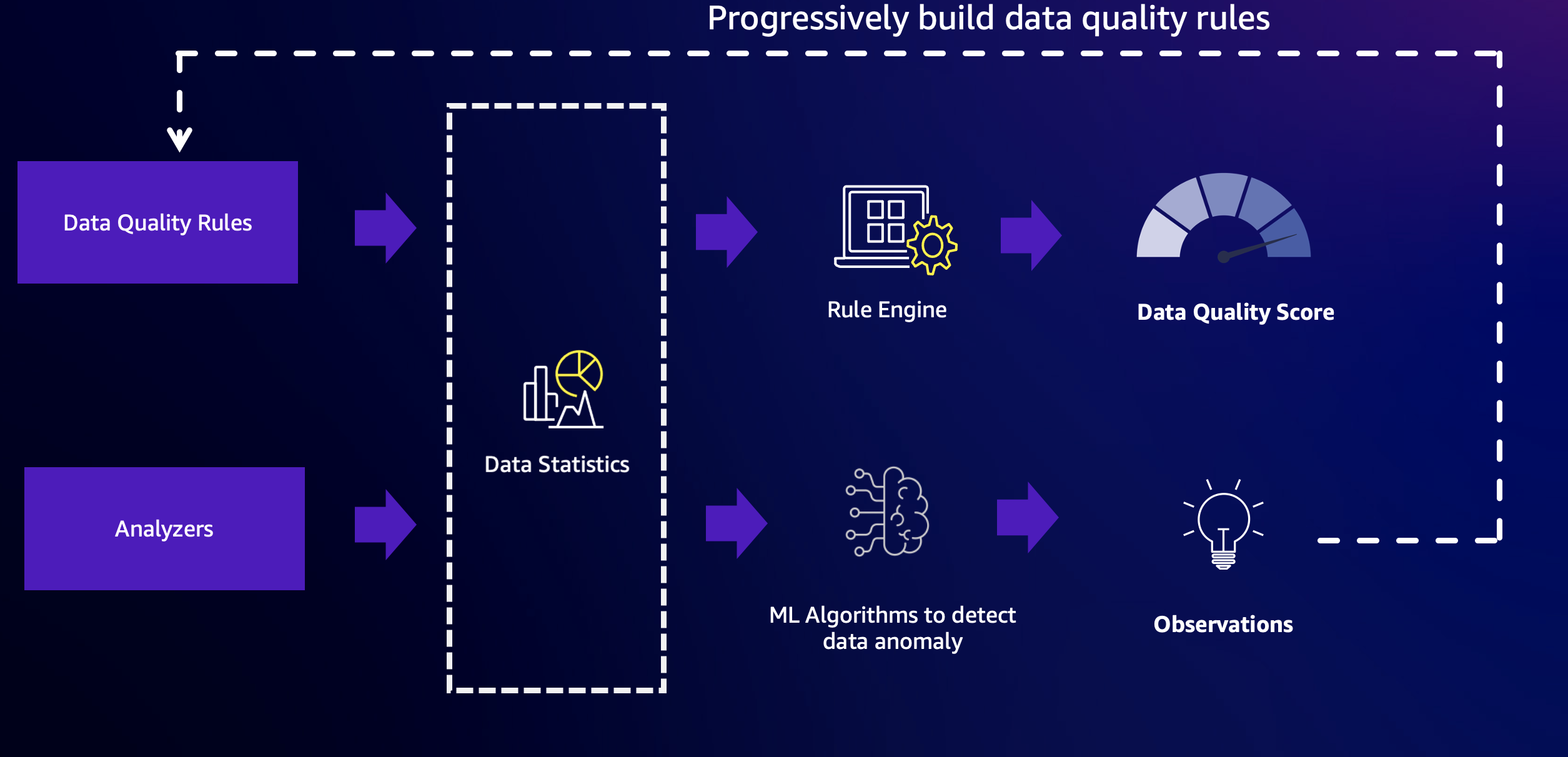
AWS Glue Data Quality combina la potenza della qualità dei dati basata su regole e le funzionalità di rilevamento delle anomalie per fornire dati di alta qualità. Per iniziare, devi prima configurare regole e analizzatori, quindi abilitare il rilevamento delle anomalie.
Regolamento
Regole: le regole esprimono le aspettative per i dati in un linguaggio aperto chiamato Data Quality Definition Language (DQDL). Di seguito è riportato un esempio di regola. Questa regola avrà successo quando non ci sono valori vuoti o NULL nella colonna `passenger count`:
Rules = [ IsComplete "passenger_count" ]
Analizzatori
In situazioni in cui conosci le colonne critiche ma potresti non conoscere abbastanza i dati per scrivere regole specifiche, puoi monitorare tali colonne utilizzando gli analizzatori. Gli analizzatori sono un modo per raccogliere statistiche sui dati senza definire regole esplicite. Di seguito è riportato un esempio di configurazione di Analyzers:
Analyzers = [ AllStatistics "fare_amount", DistinctValuesCount "pulocationid", RowCount ]
In questo esempio, sono configurati tre analizzatori:
-
Il primo analizzatore, `AllStatistics «fare_amount"`, acquisirà tutte le statistiche disponibili per il campo `fare_amount`.
-
Il secondo analizzatore, `«DistinctValuesCount pulocationid"`, acquisirà il conteggio dei valori distinti nella colonna `pulocationid`.
-
Il terzo analizzatore, `RowCount`, acquisirà il numero totale di record nel set di dati.
Gli analizzatori rappresentano un modo semplice per raccogliere statistiche pertinenti sui dati senza specificare regole complesse. Monitorando queste statistiche, è possibile ottenere informazioni sulla qualità dei dati e identificare potenziali problemi o anomalie che potrebbero richiedere ulteriori indagini o la creazione di regole specifiche.
Statistiche sui dati
Sia Analyzer che Rules in AWS Glue Data Quality raccolgono statistiche sui dati, note anche come profili di dati. Queste statistiche forniscono informazioni sulle caratteristiche e sulla qualità dei dati. Le statistiche raccolte vengono archiviate nel tempo all'interno del servizio AWS Glue, che consente di tracciare e analizzare le modifiche nei profili di dati.
Puoi recuperare facilmente queste statistiche e scriverle su Amazon S3 per ulteriori analisi o per lo storage a lungo termine richiamando le informazioni appropriate. APIs Questa funzionalità consente di integrare la profilazione dei dati nei flussi di lavoro di elaborazione dei dati e di sfruttare le statistiche raccolte per vari scopi, come il monitoraggio della qualità dei dati e il rilevamento delle anomalie.
Archiviando i profili di dati in Amazon S3, puoi sfruttare la scalabilità, la durabilità e l'economicità del servizio di storage di oggetti di Amazon. Inoltre, puoi sfruttare altri AWS servizi o strumenti di terze parti per analizzare e visualizzare i profili di dati, consentendoti di ottenere informazioni più approfondite sulla qualità dei dati e prendere decisioni informate sulla gestione e la governance dei dati.
Ecco un esempio di statistiche sui dati archiviate nel tempo.
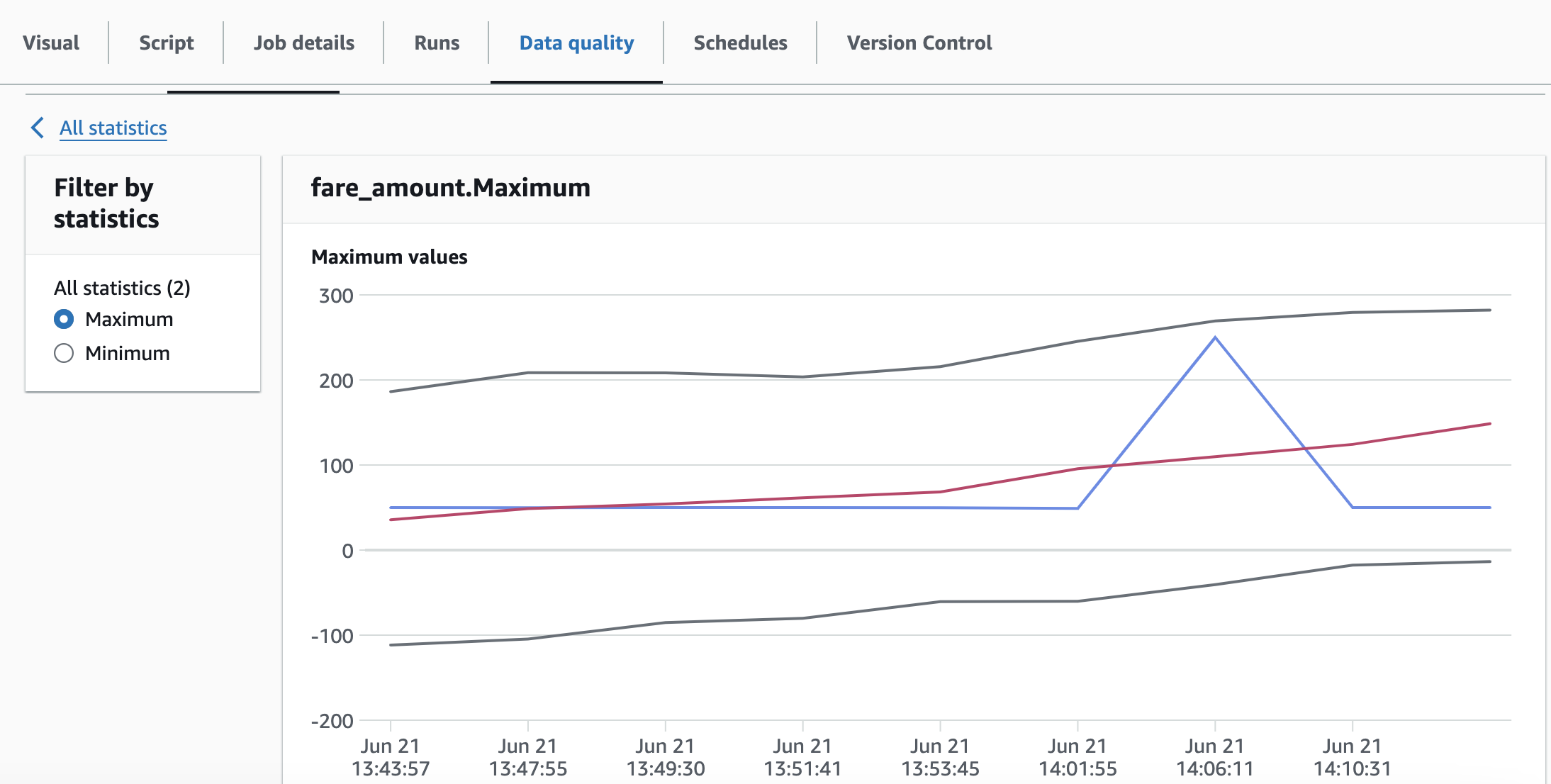
Nota
AWS Glue Data Quality raccoglierà le statistiche una sola volta, anche se hai sia Rule che Analyzer per le stesse colonne, rendendo efficiente il processo di generazione delle statistiche.
Rilevamento di anomalie
AWS Glue Data Quality richiede un minimo di tre punti dati per rilevare le anomalie. Utilizza un algoritmo di apprendimento automatico per imparare dalle tendenze passate e quindi prevedere i valori futuri. Quando il valore effettivo non rientra nell'intervallo previsto, AWS Glue Data Quality crea un'osservazione delle anomalie. Fornisce una rappresentazione visiva del valore effettivo e delle tendenze. Nel grafico seguente vengono visualizzati quattro valori.
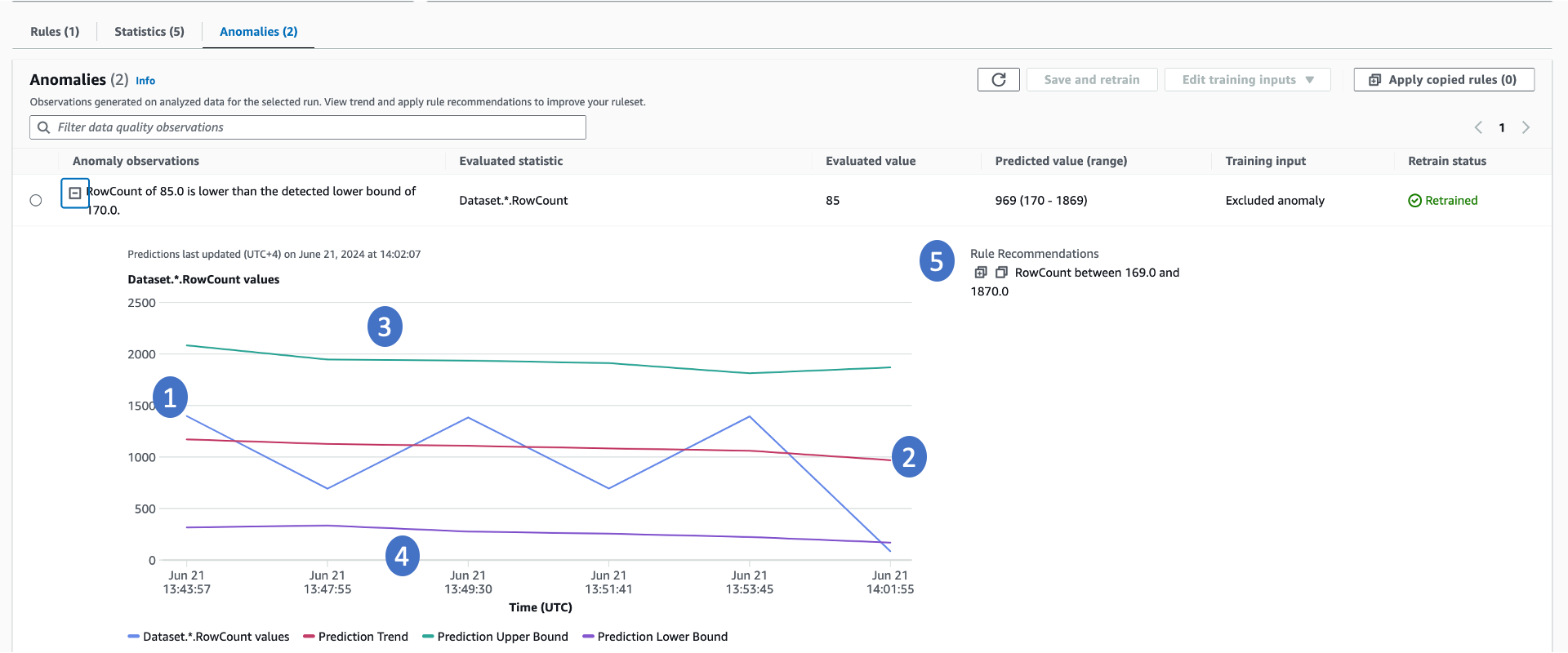
-
La statistica attuale e la sua tendenza nel tempo.
-
Una tendenza derivata imparando dalla tendenza attuale. Ciò è utile per comprendere la direzione del trend.
-
Il possibile limite superiore per la statistica.
-
Il possibile limite inferiore per la statistica.
-
Regole di qualità dei dati consigliate in grado di rilevare questi problemi in futuro.
Ci sono alcune cose importanti da notare per quanto riguarda le anomalie:
-
Quando vengono generate anomalie, i punteggi di qualità dei dati non vengono influenzati.
-
Quando viene rilevata un'anomalia, questa viene considerata normale per le esecuzioni successive. L'algoritmo di machine learning considererà questo valore anomalo come input a meno che non venga esplicitamente escluso.
Riqualificazione
La riqualificazione del modello di rilevamento delle anomalie è fondamentale per rilevare le anomalie corrette. Quando vengono rilevate anomalie, AWS Glue Data Quality include l'anomalia nel modello come valore normale. Per garantire che il rilevamento delle anomalie funzioni correttamente, è importante fornire un feedback riconoscendo o rifiutando l'anomalia. AWS Glue Data Quality fornisce meccanismi sia in AWS Glue Studio che APIs per fornire feedback al modello. Per ulteriori informazioni, consulta la documentazione sulla configurazione del rilevamento delle anomalie nelle pipeline AWS Glue ETL.
Dettagli dell'algoritmo di rilevamento delle anomalie
-
L'algoritmo Anomaly Detection esamina le statistiche dei dati nel tempo. L'algoritmo considera tutti i punti dati disponibili e ignora tutte le statistiche esplicitamente escluse.
-
Queste statistiche sui dati vengono archiviate nel servizio AWS Glue e puoi fornire AWS KMS chiavi per crittografarle. Consulta la Guida alla sicurezza su come fornire AWS KMS le chiavi per crittografare le statistiche sulla qualità dei dati di AWS Glue.
-
La componente temporale è fondamentale per l'algoritmo di rilevamento delle anomalie. Sulla base dei valori passati, AWS Glue Data Quality determina i limiti superiore e inferiore. Durante questa determinazione, considera la componente temporale. I limiti differiranno per gli stessi valori su un intervallo di un minuto, un intervallo orario o un intervallo giornaliero.
Catturare la stagionalità
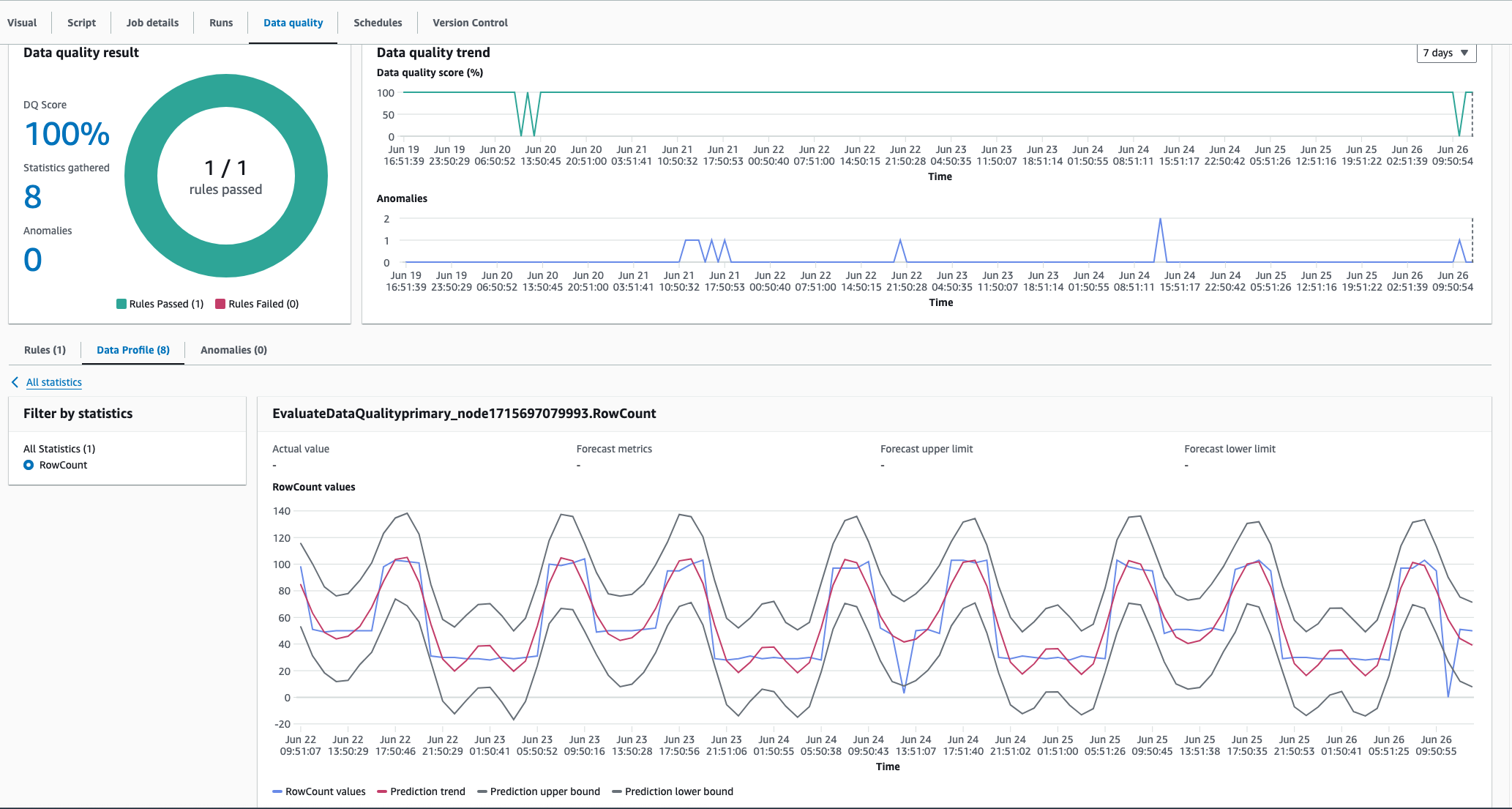
AWS L'algoritmo di rilevamento delle anomalie di Glue Data Quality può catturare modelli stagionali. Ad esempio, è in grado di comprendere che gli schemi dei giorni feriali differiscono da quelli dei fine settimana. Questo può essere visto nell'esempio seguente, in cui AWS Glue Data Quality rileva una tendenza stagionale nei valori dei dati. Non è necessario fare nulla di specifico per abilitare questa funzionalità. Nel tempo, AWS Glue Data Quality apprende le tendenze stagionali e rileva le anomalie quando questi schemi si interrompono.
Costo
L'addebito verrà calcolato in base al tempo necessario per rilevare le anomalie. A ogni statistica viene addebitata 1 DPU per il tempo necessario a rilevare le anomalie. Consulta AWS Glue Pricing
Considerazioni chiave
L'archiviazione delle statistiche è gratuita. Tuttavia, esiste un limite di 100.000 statistiche per account. Queste statistiche verranno archiviate per un massimo di due anni.
