Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Creazione di processi con connettori personalizzati
È possibile utilizzare connettori e connessioni sia per i nodi di origine dati che per i nodi di destinazione dati in AWS Glue Studio.
Creare processi che utilizzano un connettore per l'origine dati
Quando si crea un nuovo processo, puoi scegliere un connettore per l'origine dati e le destinazioni dati.
Per creare un processo che utilizza connettori per l'origine dati o la destinazione dati
Accedi a AWS Management Console e apri il AWS Glue Studio console all'indirizzo https://console.aws.amazon.com/gluestudio/.
-
Nella pagina Connectors (Connettori), nell'elenco di risorse Your connections (Le tue connessioni), scegli la connessione da utilizzare nel processo, quindi scegli Create job (crea processo).
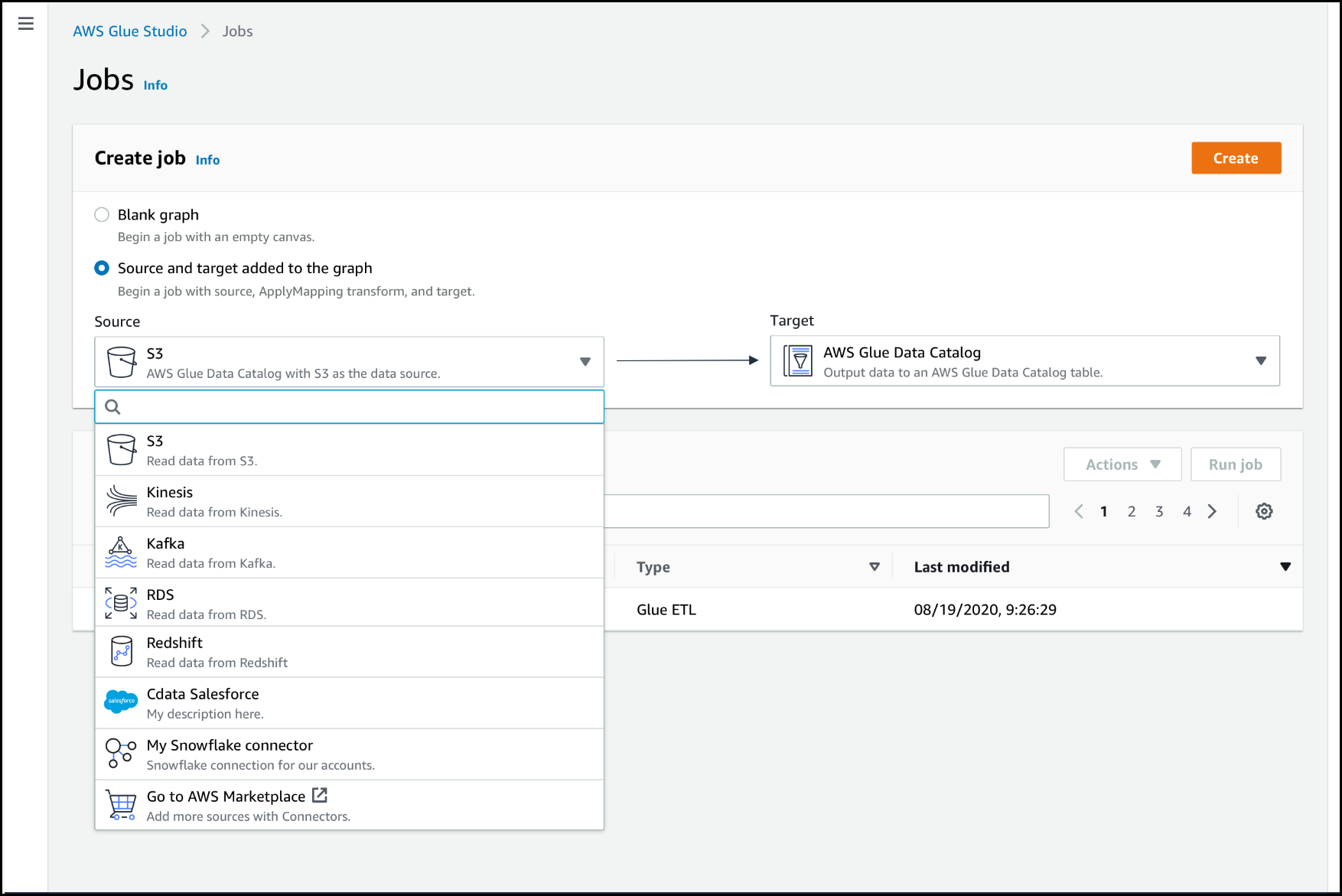
In alternativa, su AWS Glue Studio Nella pagina Lavori, in Crea lavoro, scegli Sorgente e destinazione aggiunti al grafico. Nell'elenco a discesa Source (Origine), scegli il connettore personalizzato che desideri utilizzare nel processo. Puoi anche scegliere un connettore per Target (Destinazione).
-
Scegli quindi Create (Crea) per aprire l'editor visivo dei processi.
-
Configura il nodo di origine dati, come descritto in Configurare le proprietà di origine per i nodi che utilizzano connettori.
-
Continua a creare il processo ETL aggiungendo trasformazioni, datastore aggiuntivi e destinazioni dati, come descritto in Avvio di lavori ETL visivi in AWS Glue Studio.
-
Personalizza l'ambiente di esecuzione configurando le proprietà del processo, come descritto in Modificare le proprietà del processo.
-
Salva ed esegui il processo.
Configurare le proprietà di origine per i nodi che utilizzano connettori
Dopo aver creato un processo che utilizza un connettore per l'origine dati, l'editor visivo dei processi mostra un grafico del processo con un nodo di origine dati configurato per il connettore. Devi configurare le proprietà dell'origine dati per tale nodo.
Per configurare le proprietà di un nodo di origine dati che utilizza un connettore
-
Scegli il nodo dell'origine dati del connettore nel grafico del processo oppure aggiungi un nuovo nodo e scegli il connettore per Node type (Tipo di nodo). Quindi, sulla destra, nel pannello dei dettagli dei nodi, scegli la scheda Data source properties (Proprietà dell'origine dati) se non è già selezionata.
-
Nella scheda Data source properties (Proprietà dell'origine dati), scegli la connessione da utilizzare per questo processo.
Inserisci le informazioni aggiuntive necessarie per ciascun tipo di connessione:
- JDBC
-
-
Data source input type (Tipo di input dell'origine dati): scegli di specificare un nome di tabella o una query SQL come origine dati. A seconda del tipo, devi fornire le seguenti informazioni aggiuntive:
-
Table name (Nome tabella): il nome della tabella nell'origine dati. Se l'origine dati non utilizza la tabella dei termini, fornite il nome di una struttura dati appropriata, come indicato dalle informazioni sull'utilizzo del connettore personalizzato (disponibili in Marketplace AWS).
-
Filter predicate (Predicato di filtro): una clausola di condizione da utilizzare durante la lettura dell'origine dati, simile a una clausola WHERE, che viene utilizzata per recuperare un sottoinsieme dei dati.
-
Query code (Codice query): inserisci una query SQL da utilizzare per recuperare un set di dati specifico dall'origine dati. Un esempio di query SQL di base è:
SELECT column_list FROM
table_name WHERE where_clause
-
Schema: Perché AWS Glue Studio utilizza le informazioni memorizzate nella connessione per accedere all'origine dati anziché recuperare le informazioni sui metadati da una tabella del Catalogo dati, è necessario fornire i metadati dello schema per l'origine dati. Scegli Add schema (Aggiungi schema) per aprire l'editor dello schema.
Per istruzioni su come utilizzare l'editor dello schema, consulta Modifica dello schema in un nodo di trasformazione personalizzato.
-
Partition column (Colonna di partizione): (facoltativo) puoi scegliere di partizionare le letture dei dati fornendo valori per Partition column (Colonna di partizione), Lower bound (Limite inferiore), Upper bound (Limite superiore) e Number of partitions (Numero di partizioni).
I valori lowerBound e upperBound vengono utilizzati per decidere lo stride della partizione, non per filtrare le righe nella tabella. Tutte le righe della tabella vengono partizionate e restituite.
Il partizionamento delle colonne aggiunge una condizione di partizionamento aggiuntiva alla query utilizzata per leggere i dati. Quando si utilizza una query anziché un nome di tabella, è necessario verificare che la query funzioni con la condizione di partizionamento specificata. Ad esempio:
-
Se il formato della query è "SELECT col1 FROM table1", testa la query aggiungendo una clausola WHERE alla fine della query che utilizza la colonna della partizione.
-
Se il formato della query è "SELECT col1 FROM table1 WHERE
col2=val", testa la query estendendo la clausola WHERE con AND e un'espressione che utilizza la colonna della partizione.
-
Data type casting (Casting del tipo di dati): se l'origine dati utilizza tipi di dati non disponibili in JDBC, utilizza questa sezione per specificare come convertire un tipo di dati dell'origine dati in tipi di dati JDBC. Puoi specificare fino a 50 conversioni di tipi di dati diverse. Tutte le colonne dell'origine dati che utilizzano lo stesso tipo di dati vengono convertite nello stesso modo.
Ad esempio, se nell'origine dati sono presenti tre colonne che utilizzano il tipo di dati Float e si indica che il tipo di dati Float deve essere convertito nel tipo di dati String JDBC, tutte e tre le colonne che utilizzano il tipo di dati Float vengono convertite in String.
-
Chiavi Job bookmark: Job bookmark aiuta AWS Glue mantiene le informazioni sullo stato e impedisce la rielaborazione di vecchi dati. Specificate un'altra o più colonne come chiavi dei segnalibri. AWS Glue Studio utilizza le chiavi dei segnalibri per tenere traccia dei dati che sono già stati elaborati durante un'esecuzione precedente del processo ETL. Tutte le colonne utilizzate per le chiavi di segnalibro personalizzati devono aumentare o diminuire in modo rigorosamente monotonico, ma sono ammessi spazi.
Se inserisci più chiavi di segnalibro, queste vengono combinate per formare una singola chiave composta. Una chiave di segnalibro di processo composta non deve contenere colonne duplicate. Se non specifichi le chiavi dei segnalibri, AWS Glue Studio per impostazione predefinita utilizza la chiave primaria come chiave del segnalibro, a condizione che la chiave primaria sia crescente o decrescente in sequenza (senza spazi vuoti). Se la tabella non dispone di una chiave primaria, ma la proprietà segnalibro di processo è abilitata, devi fornire chiavi personalizzate di segnalibro di processo. In caso contrario, la ricerca delle chiavi primarie da utilizzare come impostazione predefinita avrà esito negativo e l'esecuzione del processo avrà non riuscirà.
Job bookmark keys sorting order (Ordinamento delle chiavi di segnalibro di processo): scegli se i valori chiave vengono aumentati o diminuiti in sequenza.
- Spark
-
-
Schema: Perché AWS Glue Studio utilizza le informazioni memorizzate nella connessione per accedere all'origine dati anziché recuperare le informazioni sui metadati da una tabella del Catalogo dati, è necessario fornire i metadati dello schema per l'origine dati. Scegli Add schema (Aggiungi schema) per aprire l'editor dello schema.
Per istruzioni su come utilizzare l'editor dello schema, consulta Modifica dello schema in un nodo di trasformazione personalizzato.
-
Connection options (Opzioni di connessione): inserisci ulteriori coppie chiave-valore in base alle esigenze per fornire ulteriori informazioni o opzioni di connessione. Ad esempio, puoi inserire un nome di database, un nome di tabella, un nome utente e una password.
Ad esempio, per OpenSearch, si inseriscono le seguenti coppie chiave-valore, come descritto in: Tutorial: utilizzo del AWS Glue connettore per Elasticsearch
-
es.net.http.auth.user :
username
-
es.net.http.auth.pass :
password
-
es.nodes : https://<Elasticsearch
endpoint>
-
es.port : 443
-
path: <Elasticsearch
resource>
-
es.nodes.wan.only : true
Per un esempio delle opzioni di connessione minime da usare, vedete lo script di test di esempio MinimalSparkConnectorTest.scala on GitHub, che mostra le opzioni di connessione che normalmente fornireste in una connessione.
- Athena
-
-
Table name (Nome tabella): il nome della tabella nell'origine dati. Se utilizzi un connettore per leggere i log di CloudWatch Athena-log, devi inserire il nome della tabella. all_log_streams
-
Athena schema name (Nome schema Athena): scegli lo schema nell'origine dati Athena corrispondente al database che contiene la tabella. Se si utilizza un connettore per la lettura da CloudWatch Athena-logs, è necessario immettere un nome di schema simile a. /aws/glue/name
-
Schema: Perché AWS Glue Studio utilizza le informazioni memorizzate nella connessione per accedere all'origine dati anziché recuperare le informazioni sui metadati da una tabella del Catalogo dati, è necessario fornire i metadati dello schema per l'origine dati. Scegli Add schema (Aggiungi schema) per aprire l'editor dello schema.
Per istruzioni su come utilizzare l'editor dello schema, consulta Modifica dello schema in un nodo di trasformazione personalizzato.
-
Additional connection options (Opzioni di connessione aggiuntive): inserisci ulteriori coppie chiave-valore in base alle esigenze per fornire ulteriori informazioni o opzioni di connessione.
Per un esempio, consulta il file in/. README.md https://github.com/aws-samples/ aws-glue-samples tree/master/GlueCustomConnectors/development/Athena Nei passaggi di questo documento, il codice di esempio mostra le opzioni di connessione minime richieste, che sono tableName, schemaName e className. L'esempio di codice specifica queste opzioni come parte della variabile optionsMap, ma puoi specificarle per la connessione e quindi utilizzarla.
-
(Facoltativo) Dopo aver configurato le proprietà del nodo e dell'origine dati, puoi visualizzare lo schema dei dati risultante per l'origine dati scegliendo la scheda Output schema (Schema di output) nel pannello dei dettagli del nodo. Lo schema visualizzato in questa scheda viene utilizzato da tutti i nodi figlio aggiunti al grafico del processo.
-
(Facoltativo) Dopo aver configurato le proprietà del nodo e dell'origine dati, puoi visualizzare il set di dati dall'origine dati scegliendo la scheda Data preview (Anteprima dei dati) nel pannello dei dettagli del nodo. La prima volta che si sceglie questa scheda per qualsiasi nodo del processo, viene richiesto di fornire un ruolo IAM per accedere ai dati. Esiste un costo per l'utilizzo di questa caratteristica e la fatturazione inizia non appena si fornisce un ruolo IAM.
Configurare le proprietà di destinazione per i nodi che utilizzano connettori
Se usi un connettore per il tipo di destinazione dati, devi configurare le proprietà del nodo di destinazione dati.
Per configurare le proprietà di un nodo di destinazione dati che utilizza un connettore
-
Scegli il nodo di destinazione dati del connettore nel grafico del processo. Quindi, sulla destra, nel pannello dei dettagli dei nodi, scegli la scheda Data target properties (Proprietà della destinazione dati) se non è già selezionata.
-
Nella scheda Data target properties (Proprietà della destinazione dati), scegli la connessione da utilizzare per la scrittura nella destinazione.
Inserisci le informazioni aggiuntive necessarie per ciascun tipo di connessione:
- JDBC
-
-
Connection (Connessione): scegli la connessione da utilizzare con il connettore. Per informazioni su come creare una connessione, vedi Creazione di connessioni per i connettori.
-
Table name (Nome tabella): il nome della tabella nella destinazione dati. Se la destinazione dei dati non utilizza la tabella dei termini, fornite il nome di una struttura dati appropriata, come indicato dalle informazioni sull'utilizzo del connettore personalizzato (disponibili in Marketplace AWS).
-
Batch size (Dimensione batch): (facoltativo): immetti il numero di righe o record da inserire nella tabella di destinazione in un'unica operazione. Il valore predefinito è 1000 righe.
- Spark
-
-
Connection (Connessione): scegli la connessione da utilizzare con il connettore. Se non hai creato una connessione in precedenza, scegli Create connection (Crea connessione) per crearne una. Per informazioni su come creare una connessione, vedi Creazione di connessioni per i connettori.
-
Connection options (Opzioni di connessione): inserisci ulteriori coppie chiave-valore in base alle esigenze per fornire ulteriori informazioni o opzioni di connessione. Puoi inserire un nome di database, un nome di tabella, un nome utente e una password.
Ad esempio, per OpenSearch, si inseriscono le seguenti coppie chiave-valore, come descritto in: Tutorial: utilizzo del AWS Glue connettore per Elasticsearch
-
es.net.http.auth.user :
username
-
es.net.http.auth.pass :
password
-
es.nodes : https://<Elasticsearch
endpoint>
-
es.port : 443
-
path: <Elasticsearch
resource>
-
es.nodes.wan.only : true
Per un esempio delle opzioni di connessione minime da usare, vedete lo script di test di esempio MinimalSparkConnectorTest.scala on GitHub, che mostra le opzioni di connessione che normalmente fornireste in una connessione.
-
Dopo aver configurato le proprietà del nodo e dell'origine dati, puoi visualizzare lo schema dei dati risultante per l'origine dati scegliendo la scheda Output schema (Schema di output) nel pannello dei dettagli del nodo.
![L'immagine è uno screenshot del AWS Glue Studio pagina di visual job editor, con un nodo di origine dati selezionato nel grafico. La scheda Data source properties (Proprietà dell'origine dati) a destra è selezionata. I campi visualizzati per le proprietà dell'origine dati sono Connection (Connessione) (un elenco a discesa delle connessioni disponibili, seguito da un pulsante Refresh [Aggiorna]) e un pulsante Add schema (Aggiungi schema). Una sezione Connection options (Opzioni di connessione) aggiuntiva è mostrata in stato compresso.](images/data-source-properties-connector-screenshot2.png)
