Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Tutorial: creazione di una trasformazione basata su machine learning con AWS Glue
Questa esercitazione guida l'utente nelle operazioni necessarie per creare e gestire una trasformazione basata su machine learning (ML) utilizzando AWS Glue. Prima di seguire questa esercitazione, è necessario sapere come utilizzare la console di AWS Glue per aggiungere crawler e processi e modificare script. È inoltre necessario avere familiarità con la ricerca e il download di file tramite la console Amazon Simple Storage Service (Amazon S3).
In questo esempio, viene creata una trasformazione FindMatches per identificare i record corrispondenti, insegnando ad essa come identificare i record con corrispondenze e quelli senza, e la si utilizza in un processo AWS Glue. Il processo AWS Glue genera un nuovo file Amazon S3 con una colonna aggiuntiva denominata match_id.
I dati di origine utilizzati da questa esercitazione cono contenuti in un file denominato dblp_acm_records.csv. Questo file è una versione modificata derivante da pubblicazioni accademiche (DBLP e ACM) disponibili presso la fonte originale set di dati DBLP ACM dblp_acm_records.csv è un file di valori separati da virgole (CSV) in formato UTF-8 senza BOM (Byte Order Mark).
Un secondo file, dblp_acm_labels.csv, è un esempio di file di etichettatura che contiene sia i record con corrispondenze che quelli senza utilizzato per addestrare la trasformazione come parte dell'esercitazione.
Argomenti
Fase 2: aggiunta di una trasformazione basata su machine learning
Fase 3: addestramento della trasformazione basata su machine learning
Fase 4: stima della qualità della trasformazione basata su machine learning
Fase 5: aggiunta ed esecuzione di un processo con la trasformazione basata su machine learning
Fase 1: crawling dei dati di origine
In primo luogo, esegui il crawling del file CSV di origine su Amazon S3 per creare una tabella di metadati corrispondente nel catalogo dati.
Importante
Per ottenere dal crawler la creazione di una tabella per il solo file CSV, archivia il file CSV dei dati di origine in una cartella Amazon S3 diversa da quella degli altri file.
Accedi a AWS Management Console e apri la AWS Glue console all'indirizzo https://console.aws.amazon.com/glue/
. -
Nel riquadro di navigazione, selezionare Crawlers (Crawler), Add crawler (Aggiungi Crawler).
-
Seguire la procedura guidata per creare ed eseguire un crawler denominato
demo-crawl-dblp-acmcon output indirizzato verso il databasedemo-db-dblp-acm. Se questo non esiste già, durante l'esecuzione della procedura guidata è necessario creare il databasedemo-db-dblp-acm. Scegli un percorso di inclusione di Amazon S3 per i dati di esempio nella regione corrente AWS . Ad esempio, perus-east-1, il percorso di inclusione per i dati di origine su Amazon S3 ès3://ml-transforms-public-datasets-us-east-1/dblp-acm/records/dblp_acm_records.csv.Se conclude l'attività con successo, il crawler crea la tabella
dblp_acm_records_csvcon le seguenti colonne: id, title, authors, venue, year e source.
Fase 2: aggiunta di una trasformazione basata su machine learning
A questo punto, aggiungere una trasformazione basata su machine learning basata sullo schema dei dati della tabella di origine creata dal crawler e denominata demo-crawl-dblp-acm.
-
Nella console AWS Glue, nel riquadro di navigazione in Integrazione dati e ETL, scegli Strumenti di classificazione dei dati > Corrispondenza dei record, quindi Aggiungi trasformazione. Quindi segui la procedura guidata per creare una trasformazione
Find matchescon le seguenti proprietà.-
Alla voce Transform name (Nome trasformazione), immettere
demo-xform-dblp-acm. Questo è il nome della trasformazione che viene utilizzato per trovare le corrispondenze nei dati di origine. -
Alla voce IAM role (Ruolo IAM), scegli un ruolo IAM che disponga delle autorizzazioni per accedere ai dati di origine su Amazon S3, ai file di etichettatura e alle operazioni API di AWS Glue. Per ulteriori informazioni, consulta Creazione di un ruolo IAM per AWS Glue nella Guida per sviluppatori di AWS Glue .
-
Per l'origine dei dati, scegli la tabella denominata dblp_acm_records_csv nel database. demo-db-dblp-acm
-
Alla voce Primary key (Chiave primaria), scegliere la colonna chiave primaria della tabella, id.
-
Nella procedura guidata, scegliere Finish (Fine) e tornare all'elenco delle ML transforms (Trasformazioni basate su ML).
Fase 3: addestramento della trasformazione basata su machine learning
A questo punto è necessario addestrare la trasformazione basata su machine learning utilizzando il file di etichettatura di esempio del tutorial.
Non è possibile utilizzare una trasformazione basata su machine learning in un processo di estrazione, trasformazione e caricamento (ETL) finché il suo stato non è Ready for use (Pronta per l'uso). Affinché la trasformazione sia pronta, è necessario addestrarla a identificare i record con corrispondenze e quelli senza fornendo esempi di record con corrispondenza e di record senza corrispondenza. Per addestrare la trasformazione, è possibile scegliere Generate a label file (Genera un file di etichettatura), aggiungere le etichette e quindi selezionare Upload label file (Carica un file di etichettatura). In questa esercitazione è possibile utilizzare il file di etichettatura di esempio denominato dblp_acm_labels.csv. Per ulteriori informazioni sul processo di etichettatura, consultare Etichettatura.
-
Nella console AWS Glue, seleziona Corrispondenza dei record nel riquadro di navigazione.
-
Scegliere la trasformazione
demo-xform-dblp-acme quindi scegliere Action (Operazione), Teach (Addestra). Seguire la procedura guidata per addestrare la trasformazioneFind matches. Nella pagina delle proprietà della trasformazione, scegliere I have labels (Dispongo delle etichette). Scegli un percorso Amazon S3 per il file di etichettatura di esempio nella regione corrente. AWS Ad esempio, nel caso di
us-east-1, caricare il file di etichettatura fornito dal percorso su Amazon S3s3://ml-transforms-public-datasets-us-east-1/dblp-acm/labels/dblp_acm_labels.csvcon l'opzione di overwrite (sovrascrivere) le etichette esistenti. Il file di etichettatura deve essere situato su Amazon S3 nella stessa regione in cui si trova la console di AWS Glue.Quando si carica un file di etichettatura, AWS Glue avvia un'attività per aggiungere o sovrascrivere le etichette utilizzate per addestrare la trasformazione sull'elaborazione dell'origine dati.
Nella pagina finale della procedura guidata scegliere Finish (Fine) e tornare all'elenco delle ML transforms (Trasformazioni basate su ML).
Fase 4: stima della qualità della trasformazione basata su machine learning
Successivamente, è possibile stimare la qualità della propria trasformazione basata su machine learning. La qualità varia in base al numero di etichettature eseguite. Per ulteriori informazioni sulla stima della qualità, consultare Stima della qualità.
-
Nella console AWS Glue, nel riquadro di navigazione in Integrazione dati e ETL, scegli Strumenti di classificazione dei dati > Corrispondenza dei record.
-
Scegliere la trasformazione
demo-xform-dblp-acme scegliere la scheda Estimate quality (Stima della qualità). Questa scheda visualizza l'attuale stima di della qualità, se disponibile, per la trasformazione. Scegliere Estimate quality (Stima della qualità) per avviare un'attività di stima della qualità della trasformazione. La precisione della stima della qualità si poggia sull'etichettatura dei dati di origine.
Passare alla scheda History (Cronologia). In questo riquadro sono elencate le esecuzioni di attività per ogni trasformazione, inclusa l'attività di Estimate quality (Stima della qualità). Per ulteriori informazioni sull'esecuzione, scegliere Logs (Log). Verificare che, al termine dell'operazione, lo stato di esecuzione sia Succeeded (Completata correttamente).
Fase 5: aggiunta ed esecuzione di un processo con la trasformazione basata su machine learning
In questo passaggio si utilizza la trasformazione basata su machine learning per aggiungere ed eseguire un processo in AWS Glue. Quando la trasformazione demo-xform-dblp-acm è Ready for use (Pronta per l'uso) è possibile utilizzarla in un processo ETL.
-
Nel riquadro di navigazione della console di AWS Glue, scegliere Jobs (Processi).
-
Scegliere Add job (Aggiungi processo) e seguire la procedura guidata per creare un processo ETL Spark con uno script generato. Per le proprietà della trasformazione scegliere i seguenti valori:
-
Per Nome, scegli il lavoro di esempio in questo tutorial,. demo-etl-dblp-acm
-
Alla voce IAM role (Ruolo IAM), scegli un ruolo IAM che disponga delle autorizzazioni per accedere ai dati di origine su Amazon S3, ai file di etichettatura dei dati e alle operazioni API di AWS Glue. Per ulteriori informazioni, consulta Creazione di un ruolo IAM per AWS Glue nella Guida per sviluppatori di AWS Glue .
-
Alla voce ETL language (Linguaggio ETL) scegli Scala. Questo è il linguaggio di programmazione dello script ETL.
-
Per il nome del file di script, scegliete demo-etl-dblp-acm. Questo è il nome del file dello script Scala (uguale al nome del processo).
-
Come Data source (Origine dati), scegliere dblp_acm_records_csv. L'origine dati scelta deve corrispondere allo schema dell'origine dati della trasformazione basata su machine learning.
-
Alla voce Transform type (Tipo di trasformazione), scegliere Find matching records (Individuazione record corrispondenti) per creare un processo che utilizza una trasformazione basata su machine learning.
-
Annullare la selezione di Remove duplicate records (Rimuovi record duplicati). Si sceglie di non rimuovere i record duplicati perché i record di output dispongono di un campo aggiuntivo
match_idaccodato. -
Per Transform demo-xform-dblp-acm, scegli la trasformazione di machine learning utilizzata dal job.
-
Alla voce Create tables in your data target (Crea tabelle nella destinazioni dati), scegliere di creare tabelle con le seguenti proprietà:
-
Tipo di memorizzazione dei dati:
Amazon S3 -
Formato:
CSV -
Tipo di compressione:
None -
Percorso di destinazione: il percorso Amazon S3 in cui viene scritto l'output del processo (nell'attuale regione della console AWS )
-
-
-
Scegliere Save job and edit script (Salva processo e modifica script) per visualizzare la pagina dell'editor dello script.
-
Modificare lo script per aggiungere un'istruzione che faccia sì che l'output del processo sia scritto sul Target path (Percorso di destinazione) in un file a singola partizione. Aggiungere questa istruzione immediatamente dopo l'istruzione che esegue la trasformazione
FindMatches. Le istruzioni sono simili alle seguenti.val single_partition = findmatches1.repartition(1)È necessario modificare l'istruzione
.writeDynamicFrame(findmatches1)per scrivere l'output come.writeDynamicFrame(single_partion). -
Dopo aver modificato lo script, scegliere Save (Salva). Lo script modificato è simile al codice riportato qui di seguito, ma personalizzato in base al proprio tuo ambiente.
import com.amazonaws.services.glue.GlueContext import com.amazonaws.services.glue.errors.CallSite import com.amazonaws.services.glue.ml.FindMatches import com.amazonaws.services.glue.util.GlueArgParser import com.amazonaws.services.glue.util.Job import com.amazonaws.services.glue.util.JsonOptions import org.apache.spark.SparkContext import scala.collection.JavaConverters._ object GlueApp { def main(sysArgs: Array[String]) { val spark: SparkContext = new SparkContext() val glueContext: GlueContext = new GlueContext(spark) // @params: [JOB_NAME] val args = GlueArgParser.getResolvedOptions(sysArgs, Seq("JOB_NAME").toArray) Job.init(args("JOB_NAME"), glueContext, args.asJava) // @type: DataSource // @args: [database = "demo-db-dblp-acm", table_name = "dblp_acm_records_csv", transformation_ctx = "datasource0"] // @return: datasource0 // @inputs: [] val datasource0 = glueContext.getCatalogSource(database = "demo-db-dblp-acm", tableName = "dblp_acm_records_csv", redshiftTmpDir = "", transformationContext = "datasource0").getDynamicFrame() // @type: FindMatches // @args: [transformId = "tfm-123456789012", emitFusion = false, survivorComparisonField = "<primary_id>", transformation_ctx = "findmatches1"] // @return: findmatches1 // @inputs: [frame = datasource0] val findmatches1 = FindMatches.apply(frame = datasource0, transformId = "tfm-123456789012", transformationContext = "findmatches1", computeMatchConfidenceScores = true)// Repartition the previous DynamicFrame into a single partition. val single_partition = findmatches1.repartition(1)// @type: DataSink // @args: [connection_type = "s3", connection_options = {"path": "s3://aws-glue-ml-transforms-data/sal"}, format = "csv", transformation_ctx = "datasink2"] // @return: datasink2 // @inputs: [frame = findmatches1] val datasink2 = glueContext.getSinkWithFormat(connectionType = "s3", options = JsonOptions("""{"path": "s3://aws-glue-ml-transforms-data/sal"}"""), transformationContext = "datasink2", format = "csv").writeDynamicFrame(single_partition) Job.commit() } } Scegliere Run job (Esegui processo) per avviare l'esecuzione del processo. Controllare lo stato del processo nell'elenco dei processi. Al termine del processo, nella finestra ML transform (Trasformazione ML), History (Cronologia), è disponibile una nuova riga Run ID (ID esecuzione) aggiunta di tipo ETL job (Processo ETL).
Passare alla scheda Jobs (Processi), History (Cronologia). In questo riquadro vengono elencate le esecuzioni dei processi. Per ulteriori informazioni sull'esecuzione, scegliere Logs (Log). Verificare che, al termine dell'operazione, lo stato di esecuzione sia Succeeded (Completata correttamente).
Fase 6: verifica dei dati di output da Amazon S3
In questa fase si verifica l'output dell'esecuzione del processo nel bucket Amazon S3 scelto al momento dell'aggiunta del processo. È possibile scaricare il file di output sulla propria macchina locale e verificare che i record corrispondenti siano stati identificati.
Apri la console Amazon S3 all'indirizzo. https://console.aws.amazon.com/s3/
Scaricare il file di output di destinazione del processo
demo-etl-dblp-acm. Aprire il file in un foglio di calcolo (per aprire il file correttamente, potrebbe essere necessario aggiungere al file l'estensione.csv).L'immagine seguente mostra un estratto dell'output in Microsoft Excel.
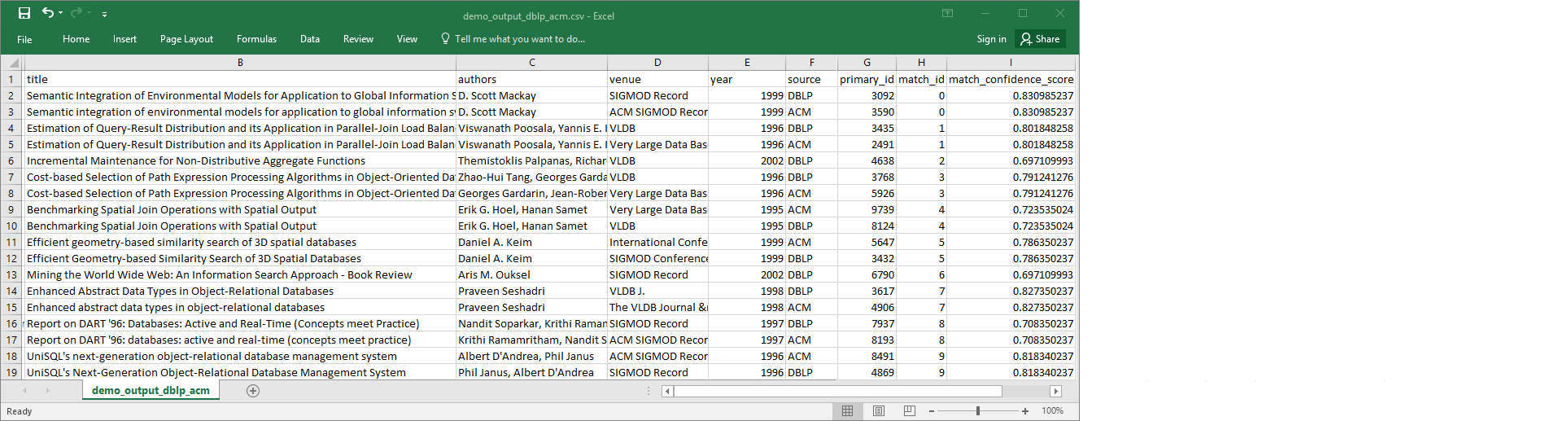
L'origine e la destinazione dei dati contano entrambe 4.911 record. Tuttavia, la trasformazione
Find matchesaggiunge un'altra colonna denominatamatch_idper identificare i record corrispondenti nell'output. Le righe con gli stessimatch_idsono considerate record corrispondenti. Lamatch_confidence_scoreè un numero compreso tra 0 e 1 che fornisce una stima della qualità delle corrispondenze trovate daFind matches.-
Ordinare il file di output per
match_idal fine di visualizzare facilmente i record corrispondenti. Confrontare i valori nelle altre colonne per confermare i risultati della trasformazioneFind matches. Se i risultati non sono soddisfacenti, è possibile continuare ad addestrare la trasformazione aggiungendo ulteriori etichette.È anche possibile ordinare i file per un altro campo, ad esempio
title, per vedere se record con titoli simili presentano lo stessomatch_id.
