Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Debug di fasi impegnative e attività in ritardo
È possibile utilizzare… AWS Glue profilazione delle mansioni per identificare le fasi impegnative e le attività secondarie nei lavori di estrazione, trasformazione e caricamento (ETL). Un'attività ritardata richiede molto più tempo rispetto alle altre attività in una fase di AWS Glue lavoro. Di conseguenza, il completamento della fase richiede più tempo e aumenta il tempo totale di esecuzione del processo.
Unione di file di input di piccole dimensioni in file di output di dimensioni maggiori
Un'attività in ritardo può verificarsi in caso di distribuzione non uniforme del lavoro tra attività diverse oppure in caso di un'asimmetria dei dati a causa della quale un'attività elabora più dati.
È possibile profilare il codice seguente, che rappresenta un modello comune in Apache Spark, per unire un numero elevato di piccoli file in file di output di dimensioni maggiori. Per questo esempio, il set di dati di input è costituito da 32 GB di file compressi Gzip JSON. Il set di dati di output include circa 190 GB di file JSON non compressi.
Il codice profilato è il seguente:
datasource0 = spark.read.format("json").load("s3://input_path") df = datasource0.coalesce(1) df.write.format("json").save(output_path)
Visualizza le metriche profilate sul AWS Glue console
È possibile profilare il processo per esaminare quattro diversi set di parametri:
-
Spostamento di dati ETL
-
Distribuzione casuale dei dati tra executor
-
Esecuzione del processo
-
Profilo di memoria
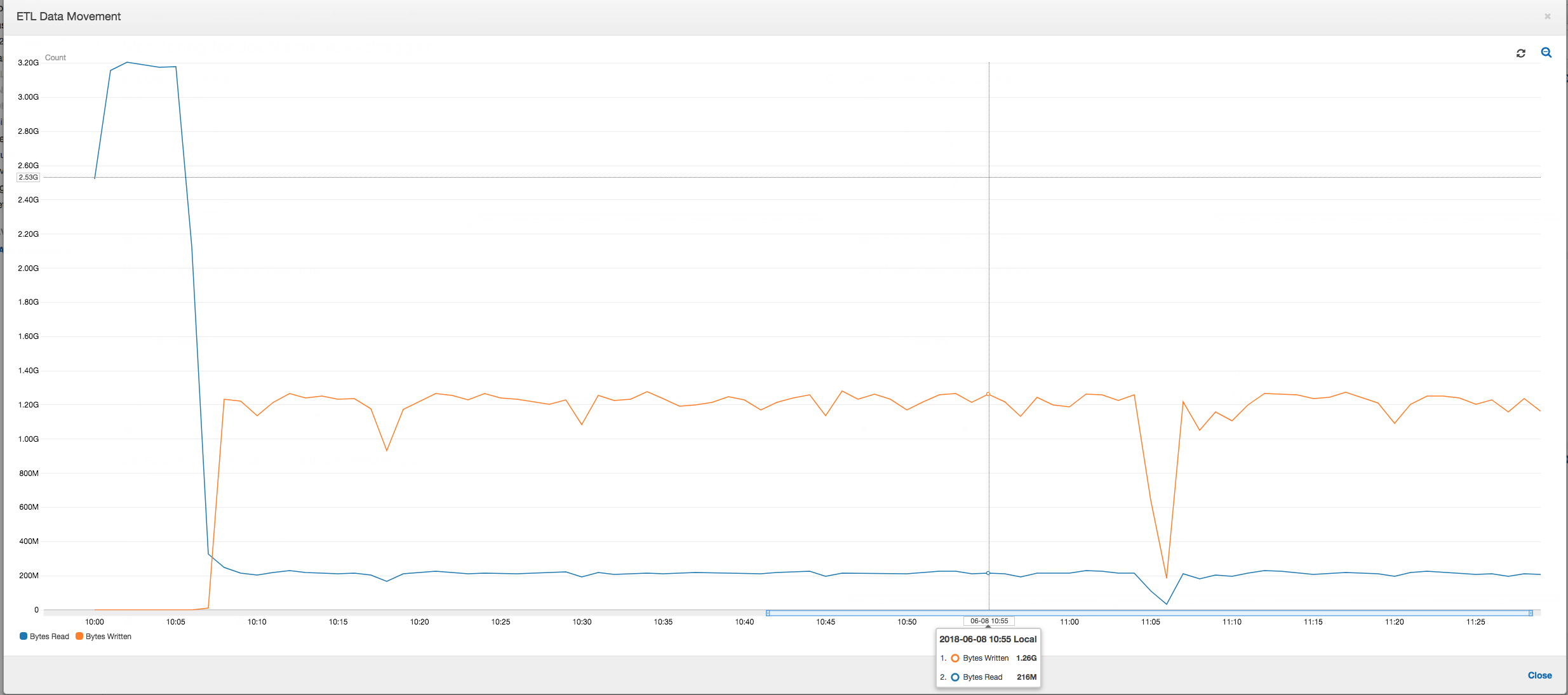
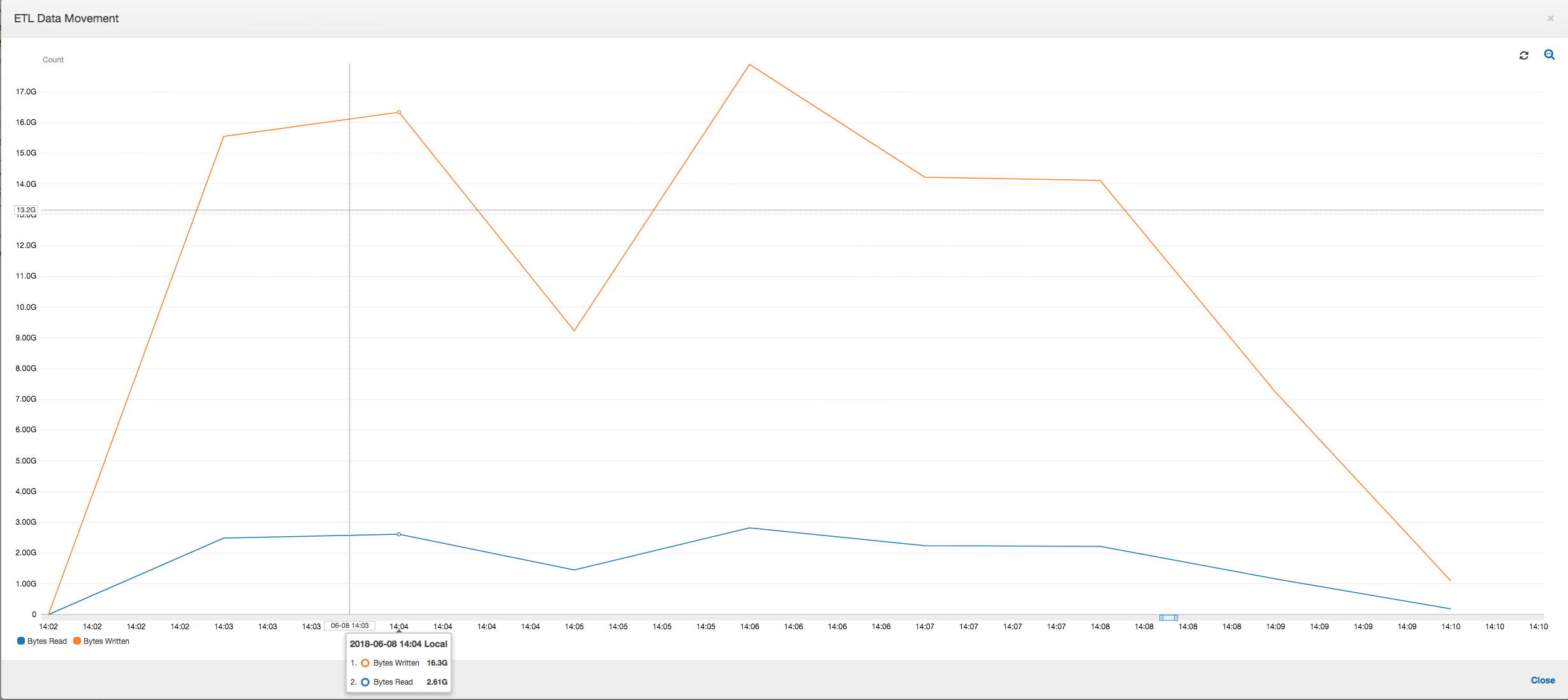
Spostamento di dati ETL: nel profilo ETL Data Movement (Spostamento di dati ETL) i byte vengono letti abbastanza rapidamente da tutti gli executor nella prima fase, che viene completata entro i primi sei minuti. Tuttavia, il tempo di esecuzione totale del processo è di circa un'ora, principalmente a causa delle operazioni di scrittura dei dati.
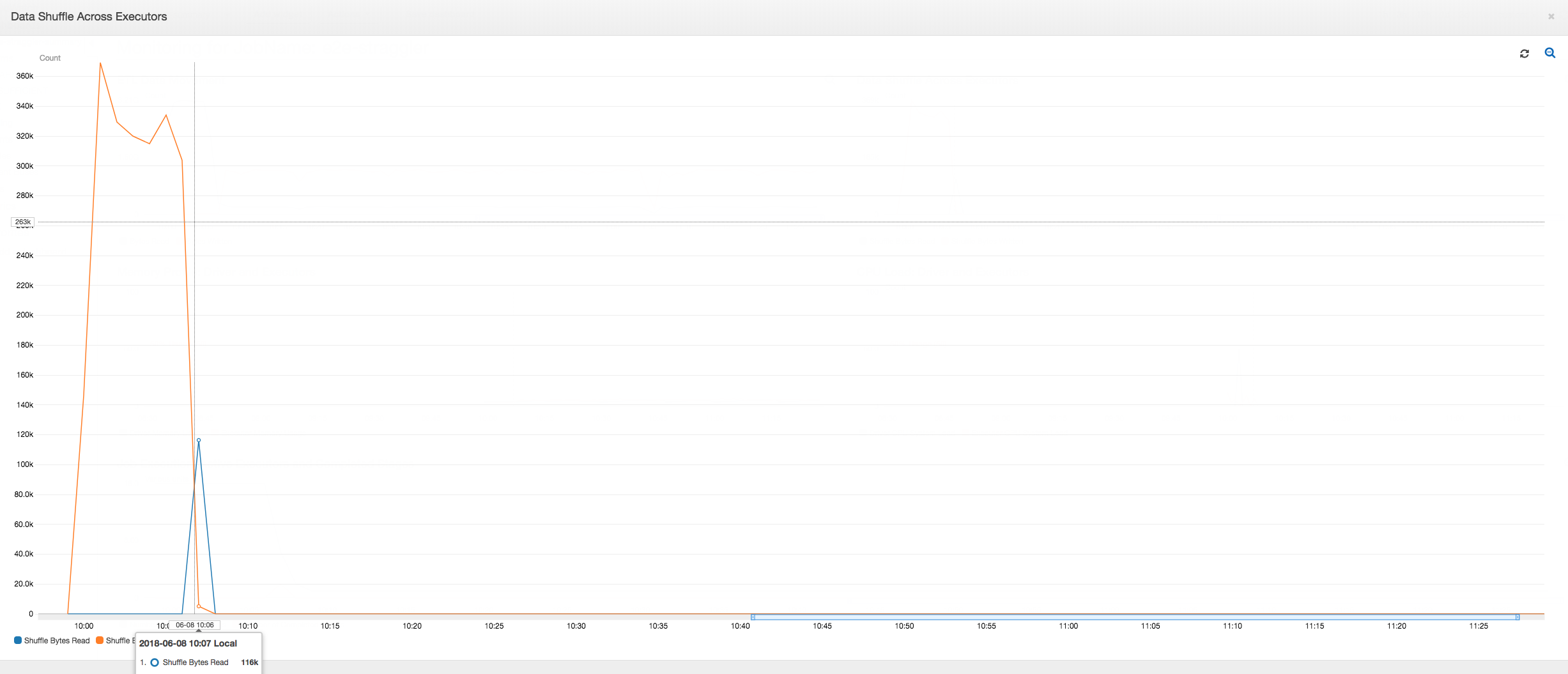
Distribuzione casuale dei dati tra executor: il numero di byte letti e scritti durante la distribuzione casuale mostra un picco prima del completamento della fase 2, come indicato dai parametri Job Execution (Esecuzione processo) e Data Shuffle (Distribuzione casuale dei dati). Dopo che i dati sono stati distribuiti in modo causale da tutti gli executor, le operazioni di lettura e scrittura procedono solo dall'executor numero 3.
Esecuzione del processo: come illustrato nel grafico seguente, tutti gli altri executor sono inattivi e vengono infine rilasciati entro le 10:09. A questo punto, il numero totale di executor scende a uno solo. Ciò mostra chiaramente che l'executor numero 3 è costituito dall'attività in ritardo che sta impiegando il tempo di esecuzione più lungo e che contribuisce in misura maggiore al tempo di esecuzione del processo.

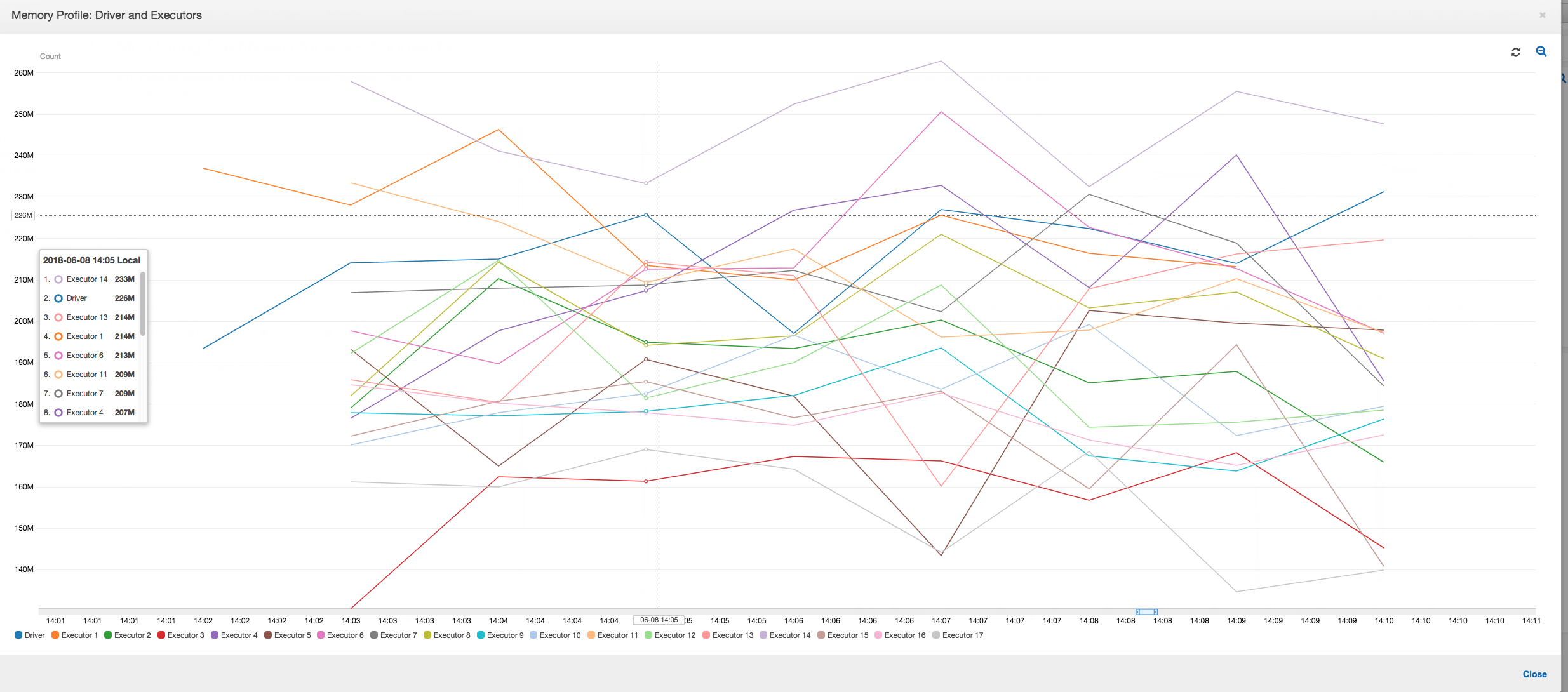
Profilo di memoria: dopo le prime due fasi, solo l'executor numero 3 consuma attivamente memoria per elaborare i dati. Gli altri executor sono semplicemente inattivi o sono stati rilasciati poco dopo il completamento delle prime due fasi.

Correzione del calo degli executor tramite il raggruppamento
È possibile evitare di separare gli esecutori utilizzando la funzionalità di raggruppamento in AWS Glue. Utilizza il raggruppamento per distribuire i dati in modo uniforme tra tutti gli executor e unire i file in file più grandi utilizzando tutti gli executor disponibili nel cluster. Per ulteriori informazioni, consulta Lettura di file di input in gruppi di grandi dimensioni.
Per controllare i movimenti dei dati ETL nel AWS Glue job, profila il seguente codice con il raggruppamento abilitato:
df = glueContext.create_dynamic_frame_from_options("s3", {'paths': ["s3://input_path"], "recurse":True, 'groupFiles': 'inPartition'}, format="json") datasink = glueContext.write_dynamic_frame.from_options(frame = df, connection_type = "s3", connection_options = {"path": output_path}, format = "json", transformation_ctx = "datasink4")
Spostamento di dati ETL: le operazioni di scrittura dei dati vengono ora trasmesse in parallelo alle operazioni di lettura dei dati per tutto il tempo di esecuzione del processo. Di conseguenza, il processo viene completato entro otto minuti, molto più rapidamente che in precedenza.
Distribuzione casuale dei dati tra executor: poiché i file di input vengono uniti durante le operazioni di lettura usando la caratteristica di raggruppamento, non vengono eseguite costose attività di distribuzione casuale dei dati dopo le operazioni di lettura dei dati.
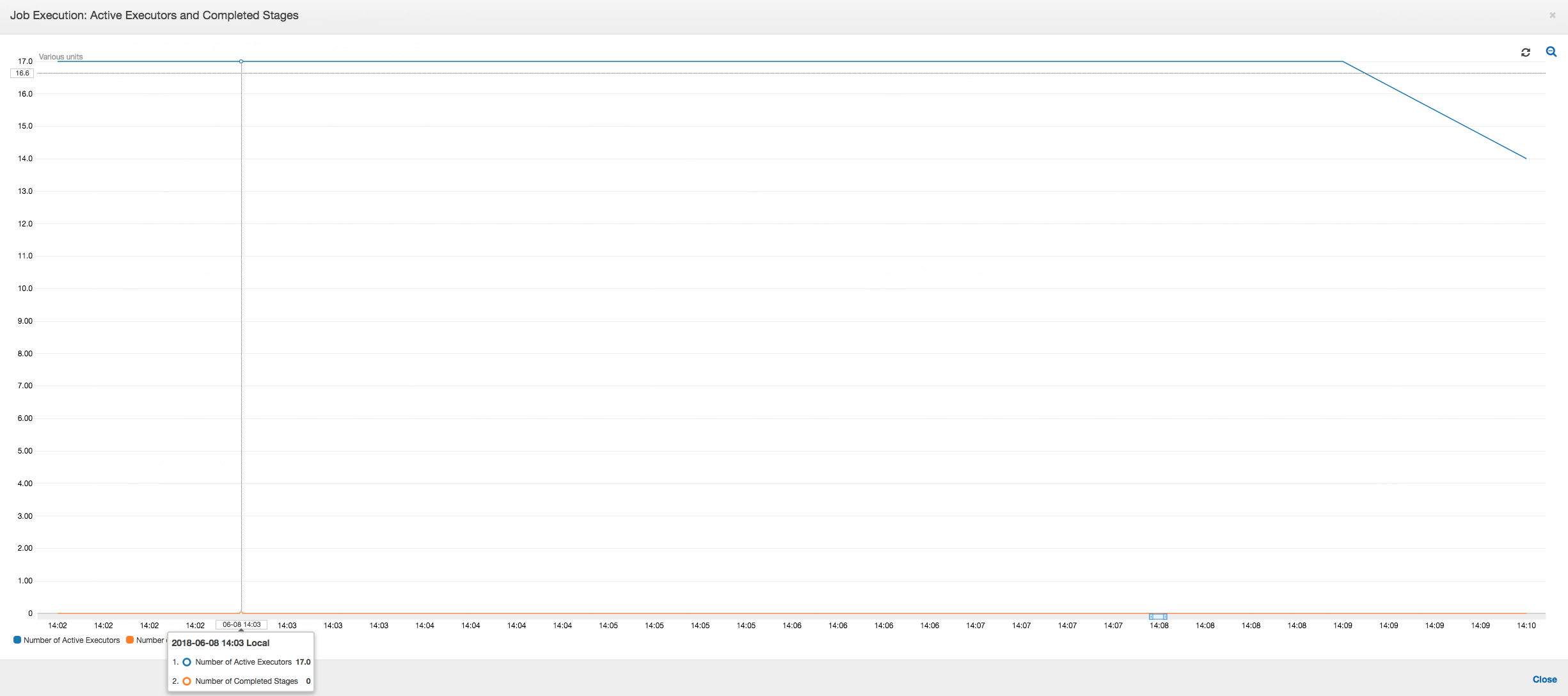
Esecuzione del processo: i parametri relativi all'esecuzione del processo mostrano che il numero totale di executor attivi in esecuzione e che elaborano i dati rimane relativamente costante. Non vi sono singole attività in ritardo nel processo. Tutti gli executor sono attivi e non vengono rilasciati fino al completamento del processo. Poiché non vi è alcuna operazione intermedia di distribuzione casuale dei dati tra gli executor, il processo è costituito da un'unica fase.
Profilo di memoria: i parametri mostrano il consumo di memoria attivo tra tutti gli executor, riconfermando la presenza di attività in tutti gli executor. Poiché i dati vengono trasmessi e scritti in parallelo, l'utilizzo totale di memoria di tutti gli executor è piuttosto uniforme e ben al di sotto della soglia di sicurezza per tutti gli executor.