Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Utilizzo di Aggregate per eseguire calcoli di riepilogo sui campi selezionati
Utilizzo della trasformazione Aggregate
-
Aggiungi il nodo Aggregate al diagramma del processo.
-
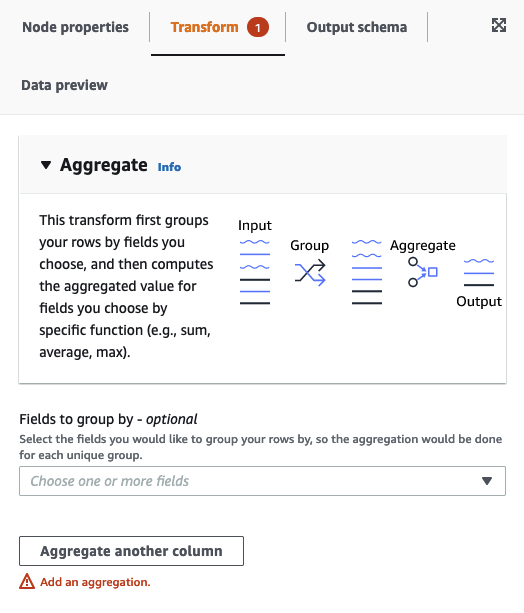
Nella scheda Node properties (Proprietà del nodo), scegli i campi da raggruppare selezionando il campo a discesa (facoltativo). È possibile selezionare più di un campo alla volta o cercare il nome del campo digitando nella barra di ricerca.
Quando i campi sono selezionati, vengono visualizzati il nome e il tipo di dati. Per eliminare un campo, selezionare "X" sul campo.
-
Scegli Aggregate another column (Aggrega un'altra colonna). È necessario selezionare almeno un campo.
-
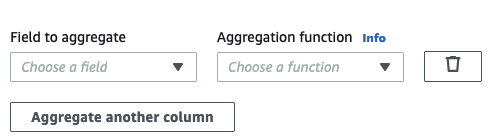
Scegli un campo nel menu a discesa Field to aggregate (Campo da aggregare).
-
Scegli la funzione di aggregazione da applicare al campo scelto:
-
avg. calcola la media
-
countDistinct: calcola il numero di valori univoci non nulli
-
count: calcola il numero di valori non null
-
first: restituisce il primo valore che soddisfa i criteri "raggruppa per"
-
last: restituisce l'ultimo valore che soddisfa i criteri "raggruppa per"
-
kurtosis: calcola la nitidezza del picco di una curva di distribuzione della frequenza
-
max: restituisce il valore più alto che soddisfa i criteri "raggruppa per"
-
min: restituisce il valore più basso che soddisfa i criteri "raggruppa per"
-
skewness: misura l'asimmetria della distribuzione di probabilità di una distribuzione normale
-
stddev_pop: calcola la deviazione standard della popolazione e restituisce la radice quadrata della varianza di popolazione
-
sum: la somma di tutti i valori del gruppo
-
SumDistinct: la somma di valori distinti nel gruppo
-
var_samp: la varianza campione del gruppo (ignora i valori nulli)
-
var_pop: la varianza di popolazione del gruppo (ignora i valori nulli)
-
