AWS IoT Greengrass Version 1 è entrato nella fase di estensione della vita utile il 30 giugno 2023. Per ulteriori informazioni, consulta la politica AWS IoT Greengrass V1 di manutenzione. Dopo questa data, AWS IoT Greengrass V1 non rilascerà aggiornamenti che forniscano funzionalità, miglioramenti, correzioni di bug o patch di sicurezza. I dispositivi che funzionano AWS IoT Greengrass V1 non subiranno interruzioni e continueranno a funzionare e a connettersi al cloud. Ti consigliamo vivamente di eseguire la migrazione a AWS IoT Greengrass Version 2, che aggiunge nuove importanti funzionalità e supporto per piattaforme aggiuntive.
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Esporta le configurazioni per le destinazioni supportate Cloud AWS
Le funzioni Lambda definite dall'utente vengono StreamManagerClient utilizzate AWS IoT Greengrass nell'SDK Core per interagire con lo stream manager. Quando una funzione Lambda crea uno stream o aggiorna uno stream, passa un MessageStreamDefinition oggetto che rappresenta le proprietà dello stream, inclusa la definizione di esportazione. L'ExportDefinitionoggetto contiene le configurazioni di esportazione definite per lo stream. Stream Manager utilizza queste configurazioni di esportazione per determinare dove e come esportare lo stream.
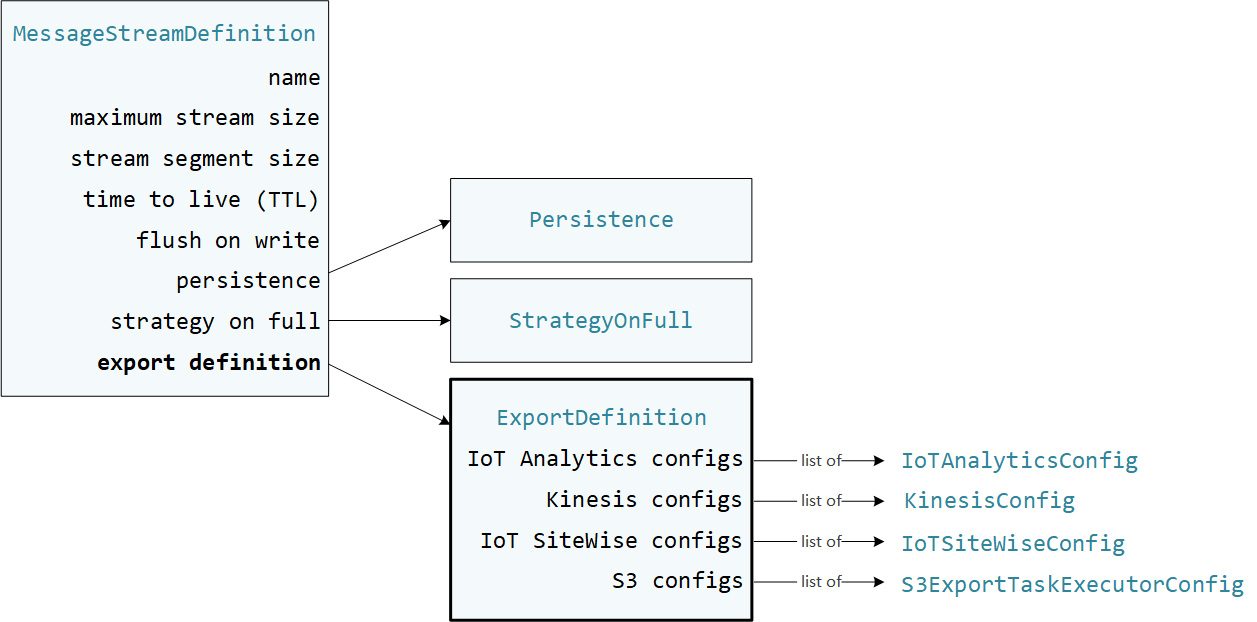
È possibile definire zero o più configurazioni di esportazione su uno stream, incluse più configurazioni di esportazione per un singolo tipo di destinazione. Ad esempio, puoi esportare uno stream su due AWS IoT Analytics canali e un flusso di dati Kinesis.
In caso di tentativi di esportazione falliti, stream manager riprova continuamente a esportare i dati verso il a Cloud AWS intervalli fino a cinque minuti. Il numero di tentativi di nuovo tentativo non ha un limite massimo.
Nota
StreamManagerClientfornisce anche una destinazione di destinazione che è possibile utilizzare per esportare i flussi su un server HTTP. Questo target è destinato esclusivamente a scopi di test. Non è stabile né è supportato per l'uso in ambienti di produzione.
Cloud AWS Destinazioni supportate
Sei responsabile del mantenimento di queste Cloud AWS risorse.
AWS IoT Analytics canali
Stream manager supporta le esportazioni automatiche verso AWS IoT Analytics. AWS IoT Analytics consente di eseguire analisi avanzate sui dati per aiutare a prendere decisioni aziendali e migliorare i modelli di apprendimento automatico. Per ulteriori informazioni, consulta Cos'è AWS IoT Analytics? nella Guida AWS IoT Analytics per l'utente.
Nel AWS IoT Greengrass Core SDK, le funzioni Lambda utilizzano per definire IoTAnalyticsConfig la configurazione di esportazione per questo tipo di destinazione. Per ulteriori informazioni, consulta il riferimento SDK per la lingua di destinazione:
-
Io TAnalytics Config nell'SDK
Node.js
Requisiti
Questa destinazione di esportazione presenta i seguenti requisiti:
-
I canali di destinazione in ingresso AWS IoT Analytics devono appartenere allo Regione AWS stesso Account AWS gruppo Greengrass.
-
Ruolo del gruppo GreengrassDevono consentire l'
iotanalytics:BatchPutMessageautorizzazione per i canali di destinazione. Per esempio:{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "iotanalytics:BatchPutMessage" ], "Resource": [ "arn:aws:iotanalytics:region:account-id:channel/channel_1_name", "arn:aws:iotanalytics:region:account-id:channel/channel_2_name" ] } ] }È possibile concedere un accesso granulare o condizionale alle risorse, ad esempio utilizzando uno schema di denominazione con caratteri jolly
*. Per ulteriori informazioni, consulta Aggiungere e rimuovere le policy IAM nella IAM User Guide.
Esportazione in AWS IoT Analytics
Per creare un flusso in cui esportare AWS IoT Analytics, le funzioni Lambda creano un flusso con una definizione di esportazione che include uno o più IoTAnalyticsConfig oggetti. Questo oggetto definisce le impostazioni di esportazione, come il canale di destinazione, la dimensione del batch, l'intervallo del batch e la priorità.
Quando le funzioni Lambda ricevono dati dai dispositivi, aggiungono messaggi che contengono un blob di dati al flusso di destinazione.
Quindi, stream manager esporta i dati in base alle impostazioni del batch e alla priorità definite nelle configurazioni di esportazione dello stream.
Flussi di dati Amazon Kinesis
Stream Manager supporta le esportazioni automatiche verso Amazon Kinesis Data Streams. Kinesis Data Streams viene comunemente utilizzato per aggregare dati di grandi volumi e caricarli in un data warehouse o in un cluster di riduzione delle mappe. Per ulteriori informazioni, consulta Cos'è Amazon Kinesis Data Streams? nella Amazon Kinesis Developer Guide.
Nel AWS IoT Greengrass Core SDK, le funzioni Lambda utilizzano per definire KinesisConfig la configurazione di esportazione per questo tipo di destinazione. Per ulteriori informazioni, consulta il riferimento SDK per la lingua di destinazione:
-
KinesisConfig
nell'SDK Python -
KinesisConfig
nell'SDK Java -
KinesisConfig
nell'SDK Node.js
Requisiti
Questa destinazione di esportazione presenta i seguenti requisiti:
-
I flussi di destinazione in Kinesis Data Streams devono appartenere allo Regione AWS stesso gruppo Account AWS Greengrass.
-
Ruolo del gruppo GreengrassDevono consentire l'
kinesis:PutRecordsautorizzazione per indirizzare i flussi di dati. Per esempio:{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "kinesis:PutRecords" ], "Resource": [ "arn:aws:kinesis:region:account-id:stream/stream_1_name", "arn:aws:kinesis:region:account-id:stream/stream_2_name" ] } ] }È possibile concedere un accesso granulare o condizionale alle risorse, ad esempio utilizzando uno schema di denominazione con caratteri jolly
*. Per ulteriori informazioni, consulta Aggiungere e rimuovere le policy IAM nella IAM User Guide.
Esportazione in Kinesis Data Streams
Per creare un flusso che esporta in Kinesis Data Streams, le funzioni Lambda creano un flusso con una definizione di esportazione che include uno o più oggetti. KinesisConfig Questo oggetto definisce le impostazioni di esportazione, come il flusso di dati di destinazione, la dimensione del batch, l'intervallo del batch e la priorità.
Quando le funzioni Lambda ricevono dati dai dispositivi, aggiungono messaggi che contengono un blob di dati al flusso di destinazione. Quindi, stream manager esporta i dati in base alle impostazioni del batch e alla priorità definite nelle configurazioni di esportazione dello stream.
Stream Manager genera un UUID univoco e casuale come chiave di partizione per ogni record caricato su Amazon Kinesis.
AWS IoT SiteWise proprietà degli asset
Stream manager supporta le esportazioni automatiche verso AWS IoT SiteWise. AWS IoT SiteWise consente di raccogliere, organizzare e analizzare dati provenienti da apparecchiature industriali su larga scala. Per ulteriori informazioni, consulta Cos'è AWS IoT SiteWise? nella Guida AWS IoT SiteWise per l'utente.
Nel AWS IoT Greengrass Core SDK, le funzioni Lambda utilizzano per definire IoTSiteWiseConfig la configurazione di esportazione per questo tipo di destinazione. Per ulteriori informazioni, consulta il riferimento SDK per la lingua di destinazione:
-
Io TSite WiseConfig
nell'SDK Python -
Io TSite WiseConfig
nell'SDK Java -
Io TSite WiseConfig
nell'SDK Node.js
Nota
AWS fornisce anche la SiteWise Connettore IoT, che è una soluzione preconfigurata che è possibile utilizzare con i sorgenti OPC-UA.
Requisiti
Questa destinazione di esportazione presenta i seguenti requisiti:
-
Le proprietà degli asset di destinazione AWS IoT SiteWise devono appartenere al gruppo Greengrass Account AWS e a Regione AWS quelle del gruppo Greengrass.
Nota
Per l'elenco delle regioni che lo AWS IoT SiteWise supportano, consulta gli AWS IoT SiteWise endpoint e le quote nel AWS Riferimento generale.
-
Ruolo del gruppo GreengrassDevono consentire l'
iotsitewise:BatchPutAssetPropertyValueautorizzazione per indirizzare le proprietà degli asset. La seguente politica di esempio utilizza la chiaveiotsitewise:assetHierarchyPathcondition per concedere l'accesso a una risorsa principale di destinazione e ai suoi figli. Puoi rimuoverlaConditiondalla policy per consentire l'accesso a tutte le tue AWS IoT SiteWise risorse o specificare ARNs singole risorse.{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "iotsitewise:BatchPutAssetPropertyValue", "Resource": "*", "Condition": { "StringLike": { "iotsitewise:assetHierarchyPath": [ "/root node asset ID", "/root node asset ID/*" ] } } } ] }Puoi concedere un accesso granulare o condizionale alle risorse, ad esempio utilizzando uno schema di denominazione con caratteri jolly
*. Per ulteriori informazioni, consulta Aggiungere e rimuovere le policy IAM nella IAM User Guide.Per importanti informazioni sulla sicurezza, consulta BatchPutAssetPropertyValue l'autorizzazione nella Guida AWS IoT SiteWise per l'utente.
Esportazione in AWS IoT SiteWise
Per creare un flusso in cui esportare AWS IoT SiteWise, le funzioni Lambda creano un flusso con una definizione di esportazione che include uno o più IoTSiteWiseConfig oggetti. Questo oggetto definisce le impostazioni di esportazione, come la dimensione del batch, l'intervallo del batch e la priorità.
Quando le funzioni Lambda ricevono dati sulle proprietà degli asset dai dispositivi, aggiungono messaggi che contengono i dati allo stream di destinazione. I messaggi sono PutAssetPropertyValueEntry oggetti serializzati in JSON che contengono valori di proprietà per una o più proprietà delle risorse. Per ulteriori informazioni, consulta Aggiungi messaggio per le destinazioni di esportazione. AWS IoT SiteWise
Nota
Quando invii dati a AWS IoT SiteWise, i tuoi dati devono soddisfare i requisiti dell'BatchPutAssetPropertyValueazione. Per ulteriori informazioni, consulta BatchPutAssetPropertyValue nella documentazione di riferimento dell'API AWS IoT SiteWise .
Quindi, stream manager esporta i dati in base alle impostazioni del batch e alla priorità definite nelle configurazioni di esportazione dello stream.
Puoi modificare le impostazioni dello stream manager e la logica della funzione Lambda per progettare la tua strategia di esportazione. Per esempio:
-
Per esportazioni quasi in tempo reale, imposta impostazioni di intervallo e dimensioni dei batch ridotte e aggiungi i dati allo stream quando vengono ricevuti.
-
Per ottimizzare il batching, mitigare i vincoli di larghezza di banda o ridurre al minimo i costi, le funzioni Lambda possono raggruppare i punti dati timestamp-quality-value (TQV) ricevuti per una singola proprietà dell'asset prima di aggiungere i dati allo stream. Una strategia consiste nell'inserire in un unico messaggio le voci relative a un massimo di 10 diverse combinazioni proprietà-asset, o alias di proprietà, anziché inviare più di una voce per la stessa proprietà. Questo aiuta lo stream manager a rimanere entro le quote.AWS IoT SiteWise
Oggetti Amazon S3
Stream Manager supporta le esportazioni automatiche verso Amazon S3. Puoi usare Amazon S3 per archiviare e recuperare grandi quantità di dati. Per ulteriori informazioni, consulta Cos'è Amazon S3? nella Guida per sviluppatori di Amazon Simple Storage Service.
Nel AWS IoT Greengrass Core SDK, le funzioni Lambda utilizzano per definire S3ExportTaskExecutorConfig la configurazione di esportazione per questo tipo di destinazione. Per ulteriori informazioni, consulta il riferimento SDK per la lingua di destinazione:
-
S3 ExportTaskExecutorConfig
nell'SDK Python -
S3 ExportTaskExecutorConfig
nell'SDK Node.js
Requisiti
Questa destinazione di esportazione presenta i seguenti requisiti:
-
I bucket Amazon S3 di Target devono appartenere allo stesso gruppo Account AWS Greengrass.
-
Se la containerizzazione predefinita per il gruppo Greengrass è il contenitore Greengrass, è necessario impostare il parametro STREAM_MANAGER_READ_ONLY_DIRS per utilizzare una directory di file di input che si trova o non si trova nel file system root.
/tmp -
Se una funzione Lambda in esecuzione in modalità contenitore Greengrass scrive i file di input nella directory dei file di input, è necessario creare una risorsa di volume locale per la directory e montare la directory nel contenitore con autorizzazioni di scrittura. Ciò garantisce che i file vengano scritti nel file system root e siano visibili all'esterno del contenitore. Per ulteriori informazioni, consulta Accedi alle risorse locali con funzioni e connettori Lambda.
-
Ruolo del gruppo GreengrassDeve consentire le seguenti autorizzazioni per i bucket di destinazione. Per esempio:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:AbortMultipartUpload", "s3:ListMultipartUploadParts" ], "Resource": [ "arn:aws:s3:::bucket-1-name/*", "arn:aws:s3:::bucket-2-name/*" ] } ] }È possibile concedere un accesso granulare o condizionale alle risorse, ad esempio utilizzando uno schema di denominazione con caratteri jolly.
*Per ulteriori informazioni, consulta Aggiungere e rimuovere le policy IAM nella IAM User Guide.
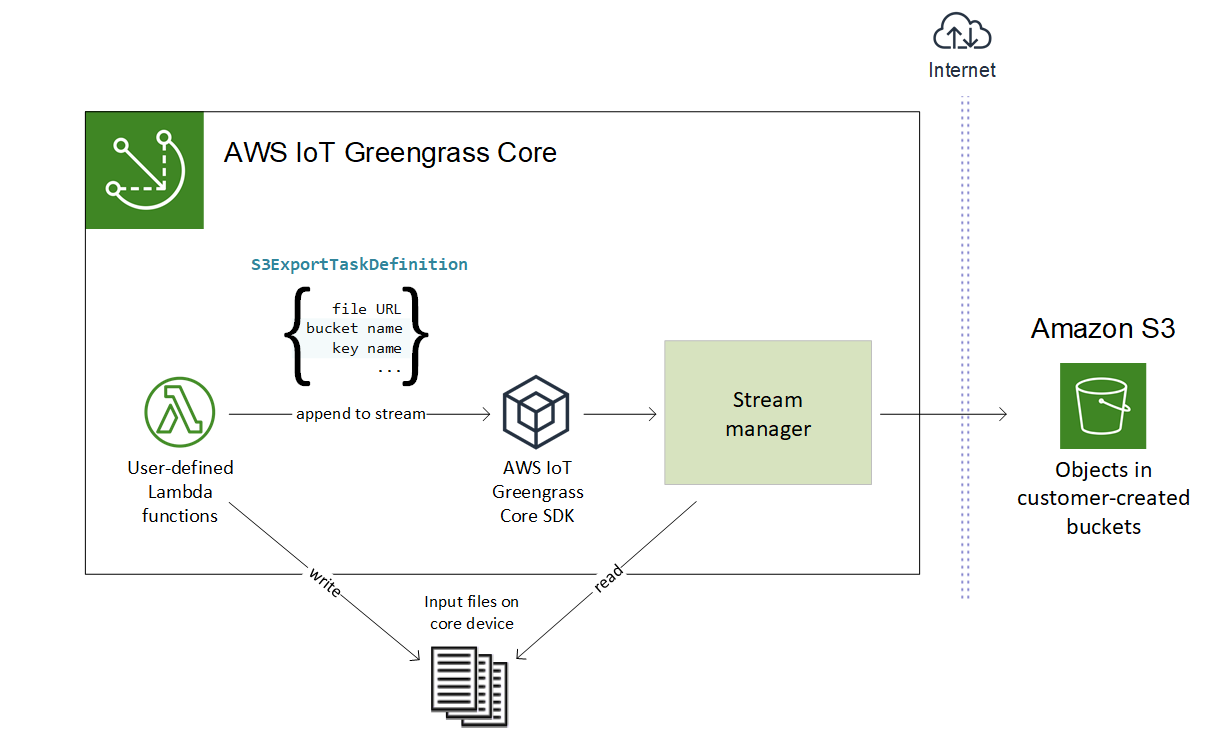
Esportazione su Amazon S3
Per creare uno stream che esporta in Amazon S3, le funzioni Lambda utilizzano l'S3ExportTaskExecutorConfigoggetto per configurare la politica di esportazione. La policy definisce le impostazioni di esportazione, come la soglia e la priorità di caricamento multiparte. Per le esportazioni di Amazon S3, stream manager carica i dati che legge dai file locali sul dispositivo principale. Per avviare un caricamento, le funzioni Lambda aggiungono un'attività di esportazione allo stream di destinazione. L'attività di esportazione contiene informazioni sul file di input e sull'oggetto Amazon S3 di destinazione. Stream manager esegue le attività nella sequenza in cui vengono aggiunte allo stream.
Nota
Il bucket di destinazione deve già esistere nel tuo. Account AWS Se non esiste un oggetto per la chiave specificata, lo stream manager crea l'oggetto per te.
Questo flusso di lavoro di alto livello è illustrato nel diagramma seguente.
Stream Manager utilizza la proprietà della soglia di caricamento multiparte, l'impostazione della dimensione minima della parte e la dimensione del file di input per determinare come caricare i dati. La soglia di caricamento in più parti deve essere maggiore o uguale alla dimensione minima della parte. Se desideri caricare dati in parallelo, puoi creare più stream.
Le chiavi che specificano gli oggetti Amazon S3 di destinazione possono includere DateTimeFormatter stringhe Java!{timestamp: Puoi utilizzare questi segnaposto con timestamp per partizionare i dati in Amazon S3 in base all'ora in cui i dati del file di input sono stati caricati. Ad esempio, il seguente nome di chiave si risolve in un valore come. value}my-key/2020/12/31/data.txt
my-key/!{timestamp:YYYY}/!{timestamp:MM}/!{timestamp:dd}/data.txt
Nota
Se desideri monitorare lo stato dell'esportazione di uno stream, crea prima uno stream di stato e poi configura il flusso di esportazione per utilizzarlo. Per ulteriori informazioni, consulta Monitora le attività di esportazione.
Gestisci i dati di input
Puoi creare codice utilizzato dalle applicazioni IoT per gestire il ciclo di vita dei dati di input. Il seguente flusso di lavoro di esempio mostra come utilizzare le funzioni Lambda per gestire questi dati.
-
Un processo locale riceve dati da dispositivi o periferiche e quindi li scrive su file in una directory sul dispositivo principale. Questi sono i file di input per lo stream manager.
Nota
Per determinare se è necessario configurare l'accesso alla directory dei file di input, vedete il parametro STREAM_MANAGER_READ_ONLY_DIRS.
Il processo in cui viene eseguito lo stream manager eredita tutte le autorizzazioni del file system dell'identità di accesso predefinita per il gruppo. Lo stream manager deve disporre dell'autorizzazione per accedere ai file di input. È possibile utilizzare il
chmod(1)comando per modificare l'autorizzazione dei file, se necessario. -
Una funzione Lambda analizza la directory e aggiunge un'attività di esportazione al flusso di destinazione quando viene creato un nuovo file. L'attività è un
S3ExportTaskDefinitionoggetto serializzato in JSON che specifica l'URL del file di input, il bucket e la chiave Amazon S3 di destinazione e i metadati utente opzionali. -
Stream Manager legge il file di input ed esporta i dati in Amazon S3 nell'ordine delle attività aggiunte. Il bucket di destinazione deve già esistere nel tuo. Account AWS Se non esiste un oggetto per la chiave specificata, lo stream manager crea l'oggetto per te.
-
La funzione Lambda legge i messaggi da un flusso di stato per monitorare lo stato dell'esportazione. Una volta completate le attività di esportazione, la funzione Lambda può eliminare i file di input corrispondenti. Per ulteriori informazioni, consulta Monitora le attività di esportazione.
Monitora le attività di esportazione
Puoi creare codice utilizzato dalle applicazioni IoT per monitorare lo stato delle esportazioni Amazon S3. Le funzioni Lambda devono creare un flusso di stato e quindi configurare il flusso di esportazione per scrivere aggiornamenti di stato nel flusso di stato. Un singolo flusso di stato può ricevere aggiornamenti di stato da più flussi esportati in Amazon S3.
Innanzitutto, crea uno stream da utilizzare come flusso di stato. Puoi configurare le dimensioni e le politiche di conservazione dello stream per controllare la durata dei messaggi di stato. Per esempio:
-
PersistenceImposta suMemoryse non desideri archiviare i messaggi di stato. -
Impostato
StrategyOnFullinOverwriteOldestDatamodo che i nuovi messaggi di stato non vadano persi.
Quindi, crea o aggiorna il flusso di esportazione per utilizzare il flusso di stato. In particolare, imposta la proprietà di configurazione dello stato della configurazione di S3ExportTaskExecutorConfig esportazione dello stream. Questo dice al gestore dello stream di scrivere messaggi di stato sulle attività di esportazione nello stream di stato. Nell'StatusConfigoggetto, specifica il nome del flusso di stato e il livello di verbosità. I seguenti valori supportati vanno da least verbose (ERROR) a most verbose (). TRACE Il valore predefinito è INFO.
-
ERROR -
WARN -
INFO -
DEBUG -
TRACE
Il seguente flusso di lavoro di esempio mostra come le funzioni Lambda potrebbero utilizzare un flusso di stato per monitorare lo stato delle esportazioni.
-
Come descritto nel flusso di lavoro precedente, una funzione Lambda aggiunge un'attività di esportazione a uno stream configurato per scrivere messaggi di stato sulle attività di esportazione in un flusso di stato. L'operazione di aggiunta restituisce un numero di sequenza che rappresenta l'ID dell'attività.
-
Una funzione Lambda legge i messaggi in sequenza dallo stream di stato, quindi filtra i messaggi in base al nome del flusso e all'ID dell'attività o in base a una proprietà dell'attività di esportazione dal contesto del messaggio. Ad esempio, la funzione Lambda può filtrare in base all'URL del file di input dell'attività di esportazione, che è rappresentato dall'
S3ExportTaskDefinitionoggetto nel contesto del messaggio.I seguenti codici di stato indicano che un'attività di esportazione ha raggiunto lo stato di completamento:
-
Success. Il caricamento è stato completato con successo. -
Failure. Lo stream manager ha riscontrato un errore, ad esempio, il bucket specificato non esiste. Dopo aver risolto il problema, puoi aggiungere nuovamente l'attività di esportazione allo stream. -
Canceled. L'attività è stata interrotta perché la definizione dello stream o dell'esportazione è stata eliminata o il periodo time-to-live (TTL) dell'attività è scaduto.
Nota
L'attività potrebbe anche avere lo stato o.
InProgressWarningStream manager emette avvisi quando un evento restituisce un errore che non influisce sull'esecuzione dell'attività. Ad esempio, la mancata pulizia di un caricamento parziale interrotto restituisce un avviso. -
-
Una volta completate le attività di esportazione, la funzione Lambda può eliminare i file di input corrispondenti.
L'esempio seguente mostra come una funzione Lambda potrebbe leggere ed elaborare i messaggi di stato.
