Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Amazon Keyspaces: come funziona
Amazon Keyspaces rimuove il sovraccarico amministrativo legato alla gestione di Cassandra. Per capire perché, è utile iniziare con l'architettura Cassandra e poi confrontarla con Amazon Keyspaces.
Argomenti
High-level architettura: Apache Cassandra e Amazon Keyspaces
Apache Cassandra tradizionale viene distribuito in un cluster composto da uno o più nodi. Sei responsabile della gestione di ogni nodo e dell'aggiunta e rimozione dei nodi man mano che il cluster cresce.
Un programma client accede a Cassandra connettendosi a uno dei nodi ed emettendo istruzioni Cassandra Query Language (CQL). CQL è simile a SQL, il linguaggio popolare utilizzato nei database relazionali. Anche se Cassandra non è un database relazionale, CQL fornisce un'interfaccia familiare per interrogare e manipolare i dati in Cassandra.
Il diagramma seguente mostra un semplice cluster Apache Cassandra, composto da quattro nodi.
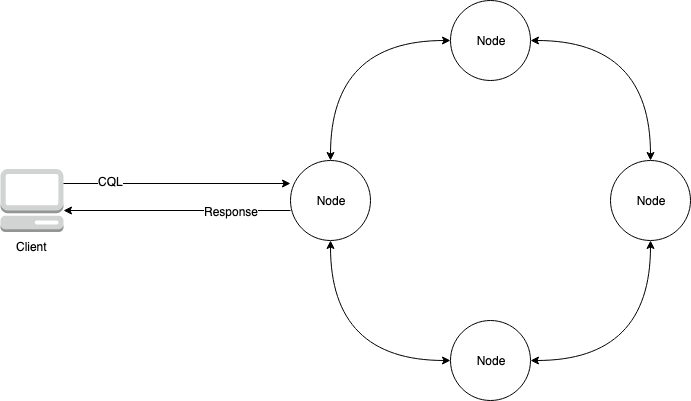
Un'implementazione di Cassandra di produzione potrebbe consistere in centinaia di nodi, in esecuzione su centinaia di computer fisici in uno o più data center fisici. Ciò può comportare un onere operativo per gli sviluppatori di applicazioni che devono fornire, applicare patch e gestire i server oltre all'installazione, alla manutenzione e al funzionamento del software.
Con Amazon Keyspaces (per Apache Cassandra), non è necessario effettuare il provisioning, applicare patch o gestire i server, quindi puoi concentrarti sulla creazione di applicazioni migliori. Amazon Keyspaces offre due modalità di capacità di throughput per le letture e le scritture: on-demand e provisioned. Puoi scegliere la modalità di capacità di throughput della tabella per ottimizzare il prezzo delle letture e delle scritture in base alla prevedibilità e alla variabilità del carico di lavoro.
Con la modalità on-demand, paghi solo per le letture e le scritture effettivamente eseguite dall'applicazione. Non è necessario specificare in anticipo la capacità di throughput della tabella. Amazon Keyspaces gestisce il traffico delle applicazioni quasi istantaneamente man mano che aumenta o diminuisce, rendendolo una buona opzione per le applicazioni con traffico imprevedibile.
La modalità di capacità fornita ti aiuta a ottimizzare il prezzo del throughput se hai un traffico applicativo prevedibile e puoi prevedere in anticipo i requisiti di capacità della tua tabella. Con la modalità di capacità fornita, è possibile specificare il numero di letture e scritture al secondo che si prevede che l'applicazione esegua. È possibile aumentare e diminuire automaticamente la capacità assegnata per la tabella abilitando il ridimensionamento automatico.
Puoi modificare la modalità di capacità della tabella una volta al giorno man mano che acquisisci ulteriori informazioni sui modelli di traffico del tuo carico di lavoro o se prevedi che si verifichi un forte aumento di traffico, ad esempio a causa di un evento importante che prevedi genererà molto traffico sulle tabelle. Per ulteriori informazioni sul provisioning della capacità di lettura e scrittura, consulta. Configura le modalità di read/write capacità in Amazon Keyspaces
Amazon Keyspaces (per Apache Cassandra) archivia tre copie dei dati in più zone di disponibilità per garantire durabilità e disponibilità
Il diagramma seguente mostra l'architettura di Amazon Keyspaces.
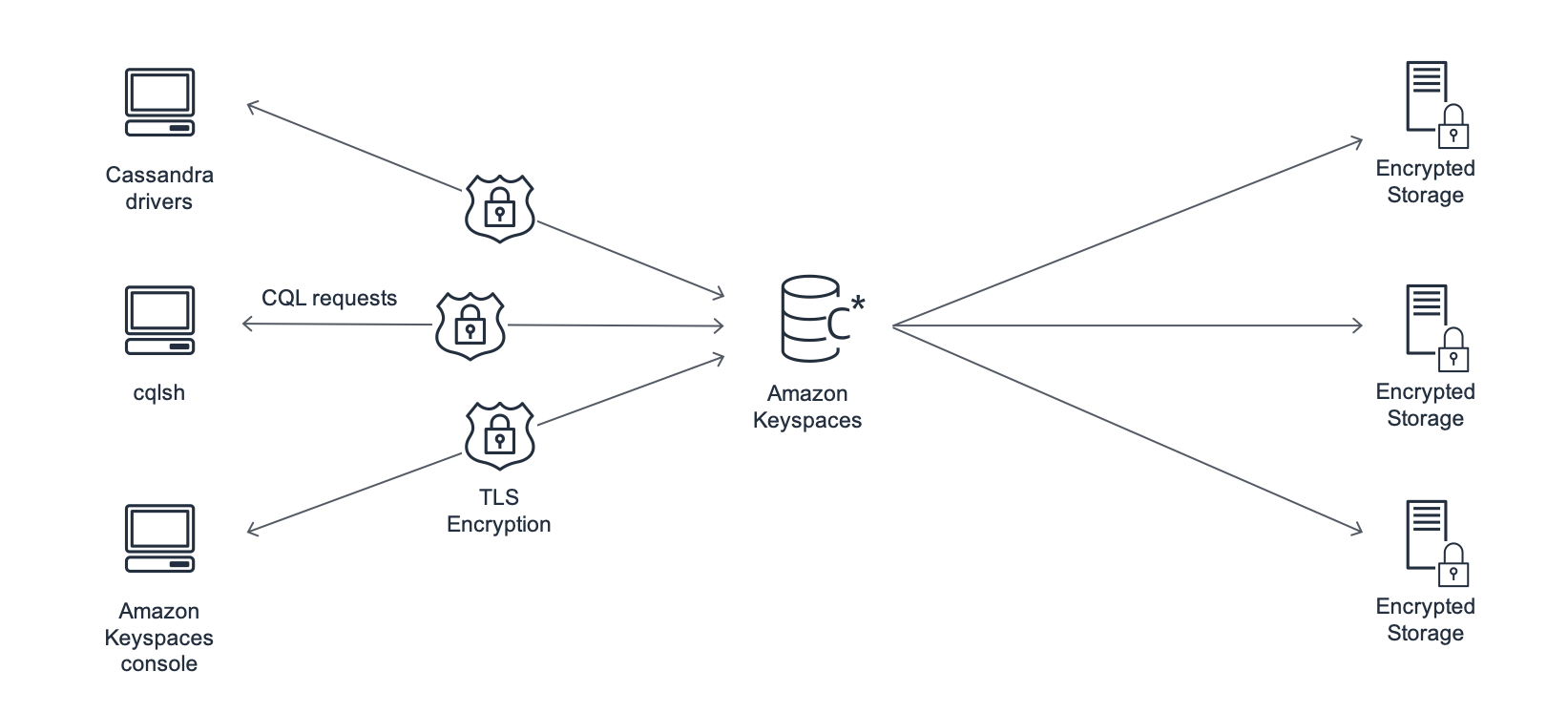
Un programma client accede ad Amazon Keyspaces connettendosi a un endpoint predeterminato (nome host e numero di porta) ed emettendo istruzioni CQL. Per un elenco degli endpoint disponibili, consulta. Endpoint di servizio per Amazon Keyspaces
Modello di dati Cassandra
Il modo in cui modelli i dati per il tuo business case è fondamentale per ottenere prestazioni ottimali da Amazon Keyspaces. Un modello di dati scadente può ridurre in modo significativo le prestazioni.
Anche se CQL è simile a SQL, i backend di Cassandra e i database relazionali sono molto diversi e devono essere affrontati in modo diverso. Di seguito sono riportate alcune delle questioni più importanti da considerare:
- Storage
-
È possibile visualizzare i dati di Cassandra in tabelle, in cui ogni riga rappresenta un record e ogni colonna un campo all'interno di quel record.
- Progettazione della tabella: interroga prima
-
Non ci sono messaggi in
JOINCQL. Pertanto, è necessario progettare le tabelle in base alla forma dei dati e al modo in cui è necessario accedervi per i casi d'uso aziendali. Ciò potrebbe comportare una denormalizzazione con dati duplicati. È necessario progettare ciascuna tabella in modo specifico per un particolare modello di accesso. - Partizioni
-
I dati vengono archiviati in partizioni su disco. Il numero di partizioni in cui sono archiviati i dati e il modo in cui vengono distribuiti tra le partizioni sono determinati dalla chiave di partizione. Il modo in cui si definisce la chiave di partizione può avere un impatto significativo sulle prestazioni delle query. Per le best practice, consulta Come utilizzare le chiavi di partizione in modo efficace in Amazon Keyspaces.
- Chiave primaria
-
In Cassandra, i dati vengono archiviati come coppia chiave-valore. Ogni tabella Cassandra deve avere una chiave primaria, che è la chiave univoca per ogni riga della tabella. La chiave primaria è composta da una chiave di partizione richiesta e da colonne di clustering opzionali. I dati che compongono la chiave primaria devono essere univoci in tutti i record di una tabella.
-
Chiave di partizione: la parte relativa alla chiave di partizione della chiave primaria è obbligatoria e determina in quale partizione del cluster sono archiviati i dati. La chiave di partizione può essere una singola colonna o un valore composto da due o più colonne. È consigliabile utilizzare una chiave di partizione composta se una chiave di partizione a colonna singola comporta che una singola partizione o pochissime partizioni contengano la maggior parte dei dati e quindi supportino la maggior parte delle operazioni su disco. I/O
-
Colonna di clustering: la parte opzionale della colonna di clustering della chiave primaria determina il modo in cui i dati vengono raggruppati e ordinati all'interno di ciascuna partizione. Se includi una colonna di clustering nella chiave primaria, la colonna di clustering può avere una o più colonne. Se nella colonna di raggruppamento sono presenti più colonne, l'ordinamento è determinato dall'ordine in cui le colonne sono elencate nella colonna di raggruppamento, da sinistra a destra.
-
Per ulteriori informazioni sulla progettazione NoSQL e Amazon Keyspaces, consulta. Principali differenze e principi di progettazione della progettazione NoSQL Per ulteriori informazioni su Amazon Keyspaces e sulla modellazione dei dati, consulta. Migliori pratiche di modellazione dei dati: consigli per la progettazione di modelli di dati
Accesso ad Amazon Keyspaces da un'applicazione
Amazon Keyspaces (per Apache Cassandra) implementa l'API Apache Cassandra Query Language (CQL), in modo da poter utilizzare i driver CQL e Cassandra che già utilizzi. Aggiornare l'applicazione è semplice: basta aggiornare il driver o la cqlsh configurazione Cassandra in modo che punti all'endpoint del servizio Amazon Keyspaces. Per maggiori informazioni sulle credenziali richieste, consulta Crea e configura AWS credenziali per Amazon Keyspaces.
Nota
Per aiutarti a iniziare, puoi trovare esempi di codice end-to-end per la connessione ad Amazon Keyspaces utilizzando vari driver client Cassandra nell'archivio di esempi di codice Amazon Keyspaces su. GitHub
Considerate il seguente programma Python, che si connette a un cluster Cassandra e interroga una tabella.
from cassandra.cluster import Cluster #TLS/SSL configuration goes here ksp = 'MyKeyspace' tbl = 'WeatherData' cluster = Cluster(['NNN.NNN.NNN.NNN'], port=NNNN) session = cluster.connect(ksp) session.execute('USE ' + ksp) rows = session.execute('SELECT * FROM ' + tbl) for row in rows: print(row)
Per eseguire lo stesso programma su Amazon Keyspaces, devi:
-
Aggiungere l'endpoint e la porta del cluster: ad esempio, l'host può essere sostituito con un endpoint di servizio, ad esempio
cassandra.us-east-1.amazonaws.come il numero di porta con:.9142 -
Aggiungere la TLS/SSL configurazione: per ulteriori informazioni sull'aggiunta della TLS/SSL configurazione per la connessione ad Amazon Keyspaces utilizzando un driver Python del client Cassandra, consulta. Utilizzo di un driver client Cassandra Python per accedere ad Amazon Keyspaces a livello di codice
