Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Processo di migrazione offline: da Apache Cassandra ad Amazon Keyspaces
Le migrazioni offline sono adatte quando ci si può permettere tempi di inattività necessari per eseguire la migrazione. È comune tra le aziende disporre di finestre di manutenzione per l'applicazione di patch, rilasci di grandi dimensioni o tempi di inattività per aggiornamenti hardware o aggiornamenti importanti. La migrazione offline può utilizzare questa finestra per copiare i dati e trasferire il traffico delle applicazioni da Apache Cassandra ad Amazon Keyspaces.
La migrazione offline riduce le modifiche all'applicazione perché non richiede la comunicazione simultanea con Cassandra e Amazon Keyspaces. Inoltre, con il flusso di dati in pausa, è possibile copiare lo stato esatto senza mantenere le mutazioni.
In questo esempio, utilizziamo Amazon Simple Storage Service (Amazon S3) come area di gestione temporanea per i dati durante la migrazione offline per ridurre al minimo i tempi di inattività. Puoi importare automaticamente i dati archiviati in formato Parquet in Amazon S3 in una tabella Amazon Keyspaces utilizzando il connettore Spark Cassandra e. AWS Glue La sezione seguente mostrerà una panoramica di alto livello del processo. Puoi trovare esempi di codice per questo processo su Github
Il processo di migrazione offline da Apache Cassandra ad Amazon Keyspaces utilizza Amazon S3 e richiede i seguenti processi. AWS Glue AWS Glue
Un processo ETL che estrae e trasforma i dati CQL e li archivia in un bucket Amazon S3.
Un secondo processo che importa i dati dal bucket in Amazon Keyspaces.
Un terzo lavoro per importare dati incrementali.
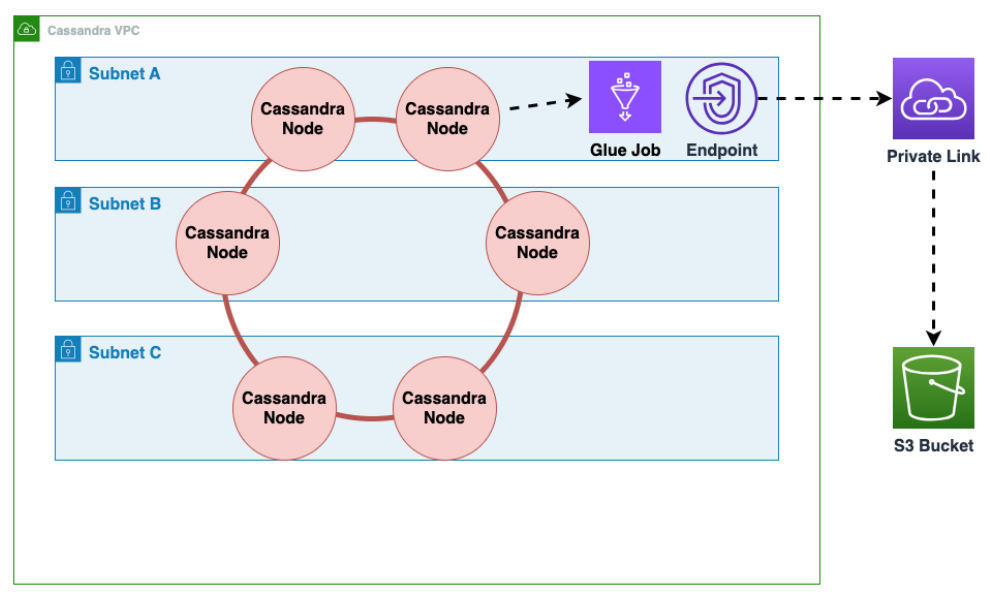
Come eseguire una migrazione offline verso Amazon Keyspaces da Cassandra in esecuzione su Amazon EC2 in un Amazon Virtual Private Cloud
Innanzitutto devi AWS Glue esportare i dati della tabella da Cassandra in formato Parquet e salvarli in un bucket Amazon S3. È necessario eseguire un AWS Glue processo utilizzando un AWS Glue connettore a un VPC in cui risiede l'istanza Amazon EC2 che esegue Cassandra. Quindi, utilizzando l'endpoint privato Amazon S3, puoi salvare i dati nel bucket Amazon S3.
Il diagramma seguente illustra questi passaggi.
Mescola i dati nel bucket Amazon S3 per migliorare la randomizzazione dei dati. I dati importati in modo uniforme consentono una maggiore distribuzione del traffico nella tabella di destinazione.
Questo passaggio è necessario quando si esportano dati da Cassandra con partizioni di grandi dimensioni (partizioni con più di 1000 righe) per evitare schemi di tasti di scelta rapida durante l'inserimento dei dati in Amazon Keyspaces. I problemi relativi ai tasti di scelta rapida si verificano
WriteThrottleEventsin Amazon Keyspaces e comportano un aumento del tempo di caricamento.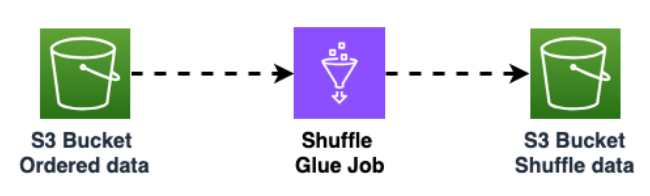
Usa un altro AWS Glue processo per importare dati dal bucket Amazon S3 in Amazon Keyspaces. I dati mischiati nel bucket Amazon S3 vengono archiviati in formato Parquet.
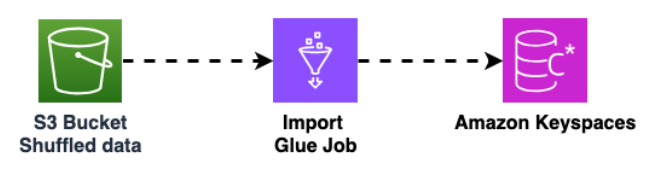
Per ulteriori informazioni sul processo di migrazione offline, consulta il workshop Amazon Keyspaces
