Non aggiorniamo più il servizio Amazon Machine Learning né accettiamo nuovi utenti. Questa documentazione è disponibile per gli utenti esistenti, ma non la aggiorniamo più. Per ulteriori informazioni, consulta Cos'è Amazon Machine Learning.
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Fase 1. Preparare i dati
Nel machine learning, in genere è possibile ottenere i dati e assicurarsi che siano correttamente formattati prima di avviare il processo di addestramento. Ai fini di questo tutorial, abbiamo ottenuto un set di dati di esempio dall'UCI Machine Learning Repository
Per i requisiti di formattazione di Amazon ML, consultaComprendere il formato dei dati per Amazon ML.
Per scaricare i set di dati
-
Scaricare il file che contiene i dati cronologici dei clienti che hanno acquistato prodotti simili al deposito bancario a termine facendo clic su banking.zip. Decomprimere la cartella e salvare il file banking.csv sul computer.
-
Scarica il file che userai per prevedere se i potenziali clienti risponderanno alla tua offerta facendo clic su banking-batch.zip. Decomprimere la cartella e salvare il file banking-batch.csv sul computer.
-
Aprire
banking.csv. Verranno visualizzate righe e colonne di dati. La riga di intestazione contiene i nomi degli attributi di ogni colonna. Un attributo è una proprietà denominata in modo univoco che descrive una determinata caratteristica di ciascun cliente; ad esempio, nr_employed indica lo stato lavorativo del cliente. Ogni riga rappresenta la raccolta delle osservazioni relative a un singolo cliente.
Si vuole che il modello ML risponda alla domanda "Il cliente effettuerà la sottoscrizione al mio nuovo prodotto?". Nel set di dati
banking.csv, la risposta a questa domanda è l'attributo y, che contiene i valori 1 (per sì) o 0 (per no). L'attributo che vuoi che Amazon ML impari a prevedere è noto come attributo target.Nota
L'attributo y è un attributo binario. Può contenere solo uno di due valori, in questo caso 0 o 1. Nel set di dati UCI originale, l'attributo y è Sì o No. Abbiamo modificato il set di dati originale per l'utente. Tutti i valori dell'attributo y che significano sì sono ora 1 e tutti i valori che significano no sono ora 0. Se si utilizzano propri dati, è possibile impiegare altri valori per un attributo binario. Per ulteriori informazioni sui valori validi, consultare Utilizzo del campo AttributeType .
I seguenti esempi mostrano i dati prima e dopo la modifica dei valori dell'attributo y in attributi binari 0 e 1.

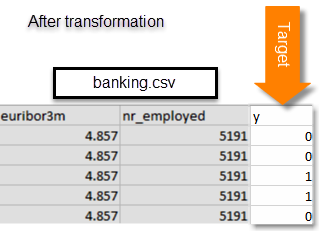
Il file banking-batch.csv non contiene l'attributo y. Dopo aver creato un modello ML, si utilizzerà il modello per prevedere y per ciascun record di quel file.
Quindi, carica i banking-batch.csv file banking.csv and su Amazon S3.
Per caricare i file su una posizione Amazon S3
Accedi a AWS Management Console e apri la console Amazon S3 all'indirizzo. https://console.aws.amazon.com/s3/
-
Nell'elenco All Buckets (Tutti i bucket), creare un bucket o scegliere il percorso in cui si vogliono caricare i file.
-
Nella barra di navigazione, scegliere Upload (Carica).
-
Seleziona Aggiungi file.
-
Nella finestra di dialogo, passare al desktop, scegliere
banking.csvebanking-batch.csv, quindi Open (Apri).
Ora è possibile creare la propria origine dati di addestramento.
