Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Tutorial: Visualizzazione delle chiamate all'assistenza clienti con OpenSearch Service e dashboard OpenSearch
Questo capitolo è un'analisi completa della seguente situazione: un'azienda riceve un numero di chiamate al servizio di assistenza clienti e desidera analizzarle. Qual è l'argomento di ogni chiamata? Quante sono state positive? Quante sono state negative? In che modo i responsabili possono cercare o analizzare le trascrizioni di queste chiamate?
Un flusso di lavoro manuale potrebbe coinvolgere dipendenti che ascoltano le registrazioni, annotano l'oggetto di ciascuna chiamata e decidono se l'interazione con il cliente è stata positiva.
Tale processo sarebbe estremamente impegnativo. Considerando un tempo medio di 10 minuti per chiamata, ogni dipendente potrebbe ascoltare solo 48 chiamate al giorno. Ad eccezione di eventuali distorsioni umane, i dati generati sarebbero altamente accurati, ma la quantità di dati sarebbe minima: solo l'oggetto della chiamata e un Boolean se il cliente è soddisfatto oppure no. Qualcosa di più complesso, come una trascrizione completa, potrebbe richiedere una grande quantità di tempo.
Utilizzando Amazon S3
Mentre è possibile usare questa spiegazione passo per passo così com'è, l'intento è dare vita a nuove idee su come arricchire i documenti JSON prima di indicizzarli in Service. OpenSearch
Costi stimati
In generale, l'esecuzione della procedura indicata in questo scenario avrebbe un costo inferiore a $2. La procedura guidata utilizza le risorse seguenti:
-
Bucket S3 con meno di 100 MB trasferiti e memorizzati
Per ulteriori informazioni, consultare Amazon S3 Pricing
. -
OpenSearch Dominio di servizio con un'
t2.mediumistanza e 10 GiB di spazio di archiviazione EBS per diverse orePer ulteriori informazioni, consultare Prezzi OpenSearch di Amazon Service
. -
Chiamate multiple ad Amazon Transcribe
Per ulteriori informazioni, consultare Prezzi di Amazon Transcribe
. -
Diverse chiamate di elaborazione del linguaggio naturale ad Amazon Comprehend
Per ulteriori informazioni, consultare Prezzi di Amazon Comprehend
.
Argomenti
Fase 1: Configurazione dei prerequisiti
Prima di procedere, devi disporre delle risorse indicate di seguito.
| Prerequisito | Descrizione |
|---|---|
| Bucket Amazon S3 | Per ulteriori informazioni, consulta Creazione di un bucket nella Guida per l'utente di Amazon Simple Storage Service. |
| OpenSearch Dominio del servizio | Destinazione per i dati. Per ulteriori informazioni, consulta Creazione di domini OpenSearch di servizio. |
Se non si dispone già di queste risorse, è possibile crearle utilizzando i comandi AWS CLI seguenti:
aws s3 mb s3://my-transcribe-test --region us-west-2
aws opensearch create-domain --domain-name my-transcribe-test --engine-version OpenSearch_1.0 --cluster-config InstanceType=t2.medium.search,InstanceCount=1 --ebs-options EBSEnabled=true,VolumeType=standard,VolumeSize=10 --access-policies '{"Version":"2012-10-17","Statement":[{"Effect":"Allow","Principal":{"AWS":"arn:aws:iam::123456789012:root"},"Action":"es:*","Resource":"arn:aws:es:us-west-2:123456789012:domain/my-transcribe-test/*"}]}' --region us-west-2
Nota
Questi comandi utilizzano la regione us-west-2, ma è possibile usare qualsiasi regione supportata da Amazon Comprehend. Per ulteriori informazioni consulta Riferimenti generali di AWS.
Fase 2: Copia del codice di esempio
-
Copiare e incollare il seguente codice di esempio Python 3 in un nuovo file denominato
call-center.py:import boto3 import datetime import json import requests from requests_aws4auth import AWS4Auth import time import urllib.request # Variables to update audio_file_name = '' # For example, 000001.mp3 bucket_name = '' # For example, my-transcribe-test domain = '' # For example, https://search-my-transcribe-test-12345.us-west-2.es.amazonaws.com index = 'support-calls' type = '_doc' region = 'us-west-2' # Upload audio file to S3. s3_client = boto3.client('s3') audio_file = open(audio_file_name, 'rb') print('Uploading ' + audio_file_name + '...') response = s3_client.put_object( Body=audio_file, Bucket=bucket_name, Key=audio_file_name ) # # Build the URL to the audio file on S3. # # Only for the us-east-1 region. # mp3_uri = 'https://' + bucket_name + '.s3.amazonaws.com/' + audio_file_name # Get the necessary details and build the URL to the audio file on S3. # For all other regions. response = s3_client.get_bucket_location( Bucket=bucket_name ) bucket_region = response['LocationConstraint'] mp3_uri = 'https://' + bucket_name + '.s3-' + bucket_region + '.amazonaws.com/' + audio_file_name # Start transcription job. transcribe_client = boto3.client('transcribe') print('Starting transcription job...') response = transcribe_client.start_transcription_job( TranscriptionJobName=audio_file_name, LanguageCode='en-US', MediaFormat='mp3', Media={ 'MediaFileUri': mp3_uri }, Settings={ 'ShowSpeakerLabels': True, 'MaxSpeakerLabels': 2 # assumes two people on a phone call } ) # Wait for the transcription job to finish. print('Waiting for job to complete...') while True: response = transcribe_client.get_transcription_job(TranscriptionJobName=audio_file_name) if response['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break else: print('Still waiting...') time.sleep(10) transcript_uri = response['TranscriptionJob']['Transcript']['TranscriptFileUri'] # Open the JSON file, read it, and get the transcript. response = urllib.request.urlopen(transcript_uri) raw_json = response.read() loaded_json = json.loads(raw_json) transcript = loaded_json['results']['transcripts'][0]['transcript'] # Send transcript to Comprehend for key phrases and sentiment. comprehend_client = boto3.client('comprehend') # If necessary, trim the transcript. # If the transcript is more than 5 KB, the Comprehend calls fail. if len(transcript) > 5000: trimmed_transcript = transcript[:5000] else: trimmed_transcript = transcript print('Detecting key phrases...') response = comprehend_client.detect_key_phrases( Text=trimmed_transcript, LanguageCode='en' ) keywords = [] for keyword in response['KeyPhrases']: keywords.append(keyword['Text']) print('Detecting sentiment...') response = comprehend_client.detect_sentiment( Text=trimmed_transcript, LanguageCode='en' ) sentiment = response['Sentiment'] # Build the Amazon OpenSearch Service URL. id = audio_file_name.strip('.mp3') url = domain + '/' + index + '/' + type + '/' + id # Create the JSON document. json_document = {'transcript': transcript, 'keywords': keywords, 'sentiment': sentiment, 'timestamp': datetime.datetime.now().isoformat()} # Provide all details necessary to sign the indexing request. credentials = boto3.Session().get_credentials() awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, 'opensearchservice', session_token=credentials.token) # Index the document. print('Indexing document...') response = requests.put(url, auth=awsauth, json=json_document, headers=headers) print(response) print(response.json()) -
Aggiornare le prime sei variabili.
-
Installare i pacchetti necessari utilizzando i comandi seguenti:
pip install boto3 pip install requests pip install requests_aws4auth -
Inserisci il tuo MP3 nella stessa directory
call-center.pyed esegui lo script. Di seguito è riportato un output di esempio:$ python call-center.py Uploading 000001.mp3... Starting transcription job... Waiting for job to complete... Still waiting... Still waiting... Still waiting... Still waiting... Still waiting... Still waiting... Still waiting... Detecting key phrases... Detecting sentiment... Indexing document... <Response [201]> {u'_type': u'call', u'_seq_no': 0, u'_shards': {u'successful': 1, u'failed': 0, u'total': 2}, u'_index': u'support-calls4', u'_version': 1, u'_primary_term': 1, u'result': u'created', u'_id': u'000001'}
call-center.py esegue una serie di operazioni:
-
Lo script carica un file audio (in questo caso, un MP3, ma Amazon Transcribe supporta diversi formati) nel tuo bucket S3.
-
Invia l'URL del file audio ad Amazon Transcribe e attende il completamento del processo di trascrizione.
Il tempo necessario per completare il processo di trascrizione dipende dalla durata del file audio. Supponiamo siano minuti, non secondi.
Suggerimento
Per migliorare la qualità della trascrizione, è possibile configurare un vocabolario personalizzato per Amazon Transcribe.
-
Una volta completato il processo di trascrizione, lo script estrae la trascrizione, la riduce a 5.000 caratteri e la invia ad Amazon Comprehend per l'analisi del sentiment e delle parole chiave.
-
Infine, lo script aggiunge la trascrizione completa, le parole chiave, il sentiment e l'attuale timestamp a un documento JSON e lo indicizza in Service. OpenSearch
Suggerimento
LibriVox
(Facoltativo) Fase 3: Indicizzazione dei dati di esempio
Se non si dispone di un gruppo di registrazioni di chiamate (chi le ha, effettivamente?) è possibile indicizzare i documenti campione in sample-calls.zip, con un risultato simile a quello prodotto da call-center.py.
-
Creare un file denominato
bulk-helper.py:import boto3 from opensearchpy import OpenSearch, RequestsHttpConnection import json from requests_aws4auth import AWS4Auth host = '' # For example, my-test-domain.us-west-2.es.amazonaws.com region = '' # For example, us-west-2 service = 'es' bulk_file = open('sample-calls.bulk', 'r').read() credentials = boto3.Session().get_credentials() awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token) search = OpenSearch( hosts = [{'host': host, 'port': 443}], http_auth = awsauth, use_ssl = True, verify_certs = True, connection_class = RequestsHttpConnection ) response = search.bulk(bulk_file) print(json.dumps(response, indent=2, sort_keys=True)) -
Aggiornare le prime due variabili per
hosteregion. -
Installare il pacchetto necessario utilizzando il seguente comando:
pip install opensearch-py -
Scaricare e decomprimere sample-calls.zip.
-
Posizionare
sample-calls.bulknella stessa directory dibulk-helper.pyed eseguire lo script helper. Di seguito è riportato un output di esempio:$ python bulk-helper.py { "errors": false, "items": [ { "index": { "_id": "1", "_index": "support-calls", "_primary_term": 1, "_seq_no": 42, "_shards": { "failed": 0, "successful": 1, "total": 2 }, "_type": "_doc", "_version": 9, "result": "updated", "status": 200 } },...], "took": 27 }
Fase 4: Analisi e visualizzazione dei dati
Ora che si dispone dei dati in OpenSearch Service, è possibile visualizzarli usando OpenSearch Dashboards.
-
Accedi a
https://search-.domain.region.es.amazonaws.com/_dashboards -
Prima di utilizzare OpenSearch Dashboards, è però necessario un modello di indice. Dashboards usa modelli di indice per limitare l'analisi a uno o più indici. Per abbinare l'indice
support-callscreato dacall-center.py, passare a Gestione degli stack, Modelli di indice e definire un modello di indice disupport*, quindi scegliere Approfondimenti. -
In Time Filter field name (Nome campo Filtro tempo), scegliere timestamp.
-
Ora è possibile iniziare a creare le visualizzazioni. Scegliere Visualize (Visualizza), quindi aggiungere una nuova visualizzazione.
-
Scegliere il grafico a torta e il modello dell'indice
support*. -
La visualizzazione predefinita è di base, quindi scegliere Split Slices (Dividi sezioni) per creare una visualizzazione più interessante.
Per Aggregation (Aggregazione) scegliere Terms (Termini). In Field (Campo), scegliere sentiment.keyword. Quindi selezionare Apply changes (Applica modifiche) e poi Save (Salva).
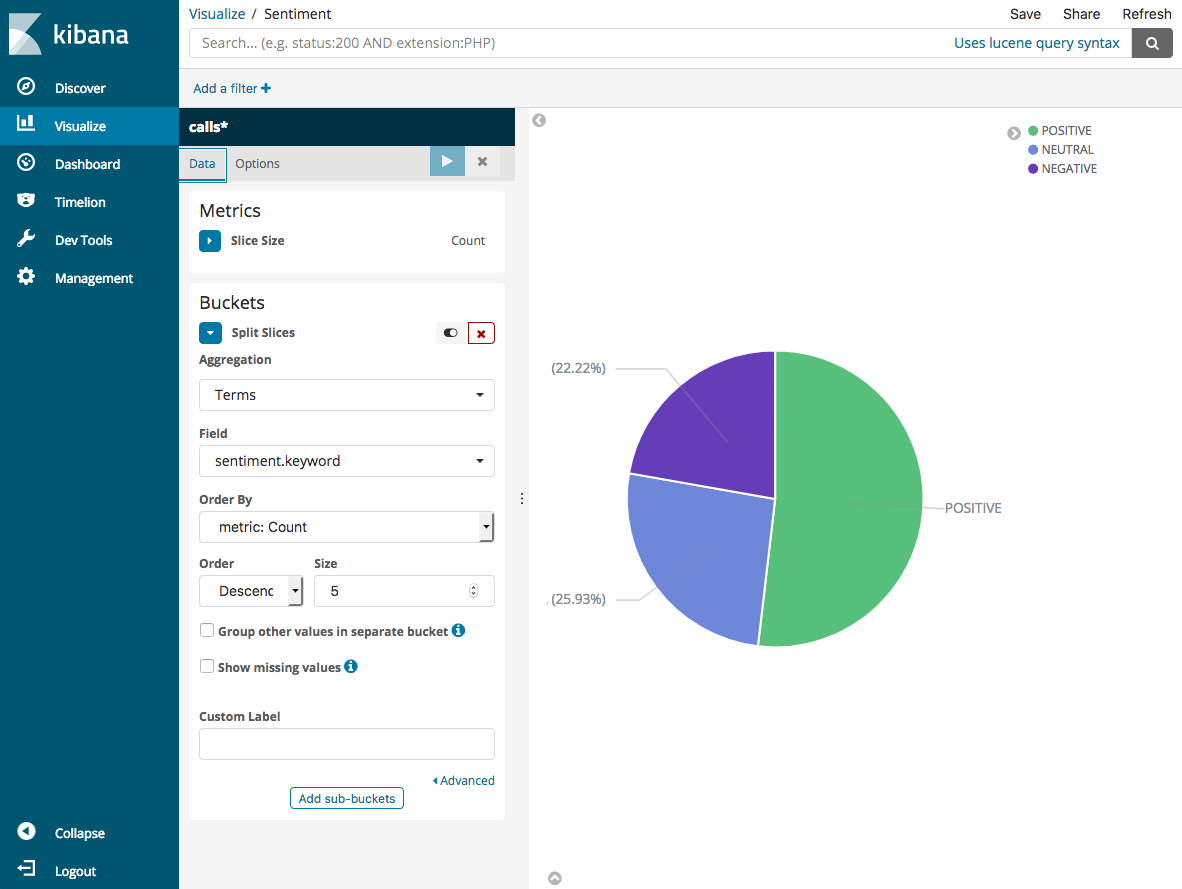
-
Tornare alla pagina Visualize (Visualizza) e aggiungere un'altra visualizzazione. Questa volta, scegliere il grafico a barre orizzontali.
-
Scegliere Split Series (Dividi serie).
Per Aggregation (Aggregazione) scegliere Terms (Termini). In Field (Campo), scegliere keywords.keyword e modificare Size (Dimensioni) in 20. Quindi selezionare Apply Changes (Applica modifiche) e poi Save (Salva).
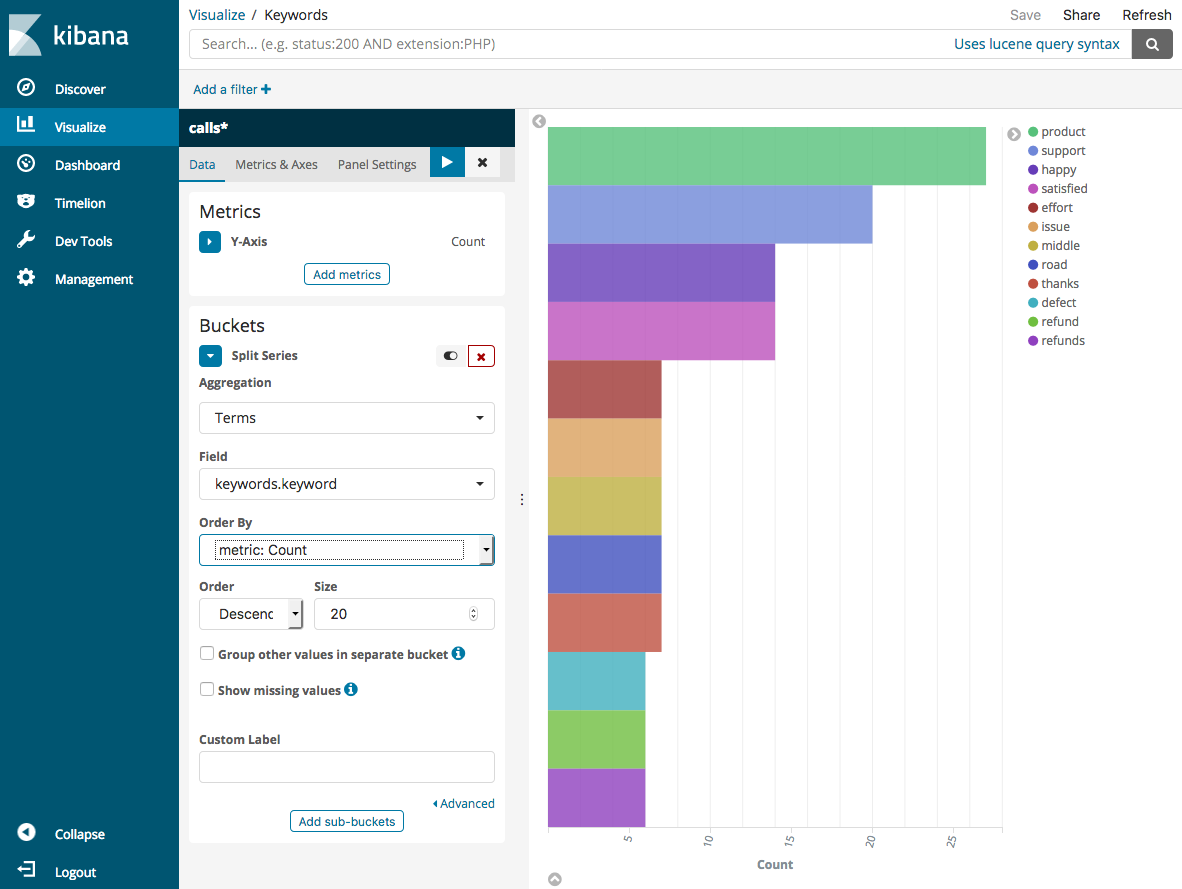
-
Tornare alla pagina Visualize (Visualizza) e aggiungere una visualizzazione finale, un grafico a barre verticali.
-
Scegliere Split Series (Dividi serie). In Aggregation (Aggregazione), scegliere Date Histogram (Istogramma date). In Field (Campo), scegliere timestamp e modificare Interval (Intervallo) in Daily (Giornaliero).
-
Scegliere Metrics & Axes (Parametri e assi) e cambiare Mode (Modalità) in normal (normale).
-
Selezionare Apply Changes (Applica modifiche) e poi Save (Salva).
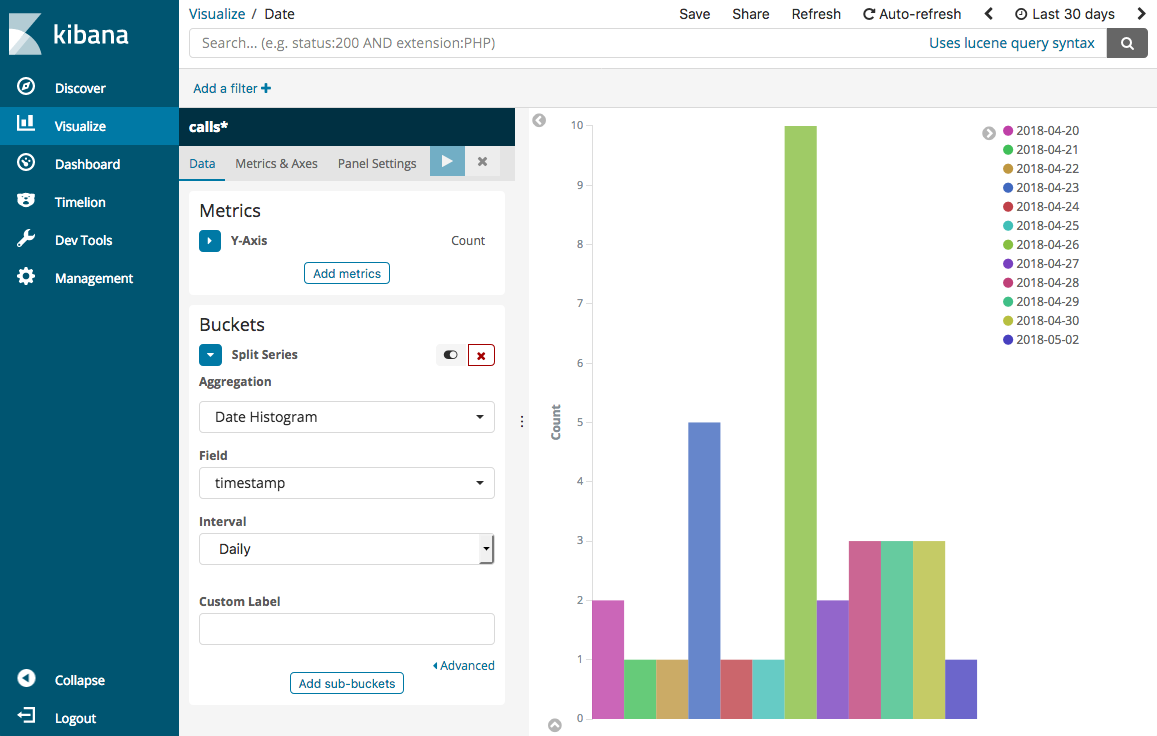
-
Ora che si dispone di tre visualizzazioni, è possibile aggiungerle a una visualizzazione di Dashboards. Scegliere Dashboard (Pannello di controllo), creare un pannello di controllo e aggiungere le visualizzazioni.
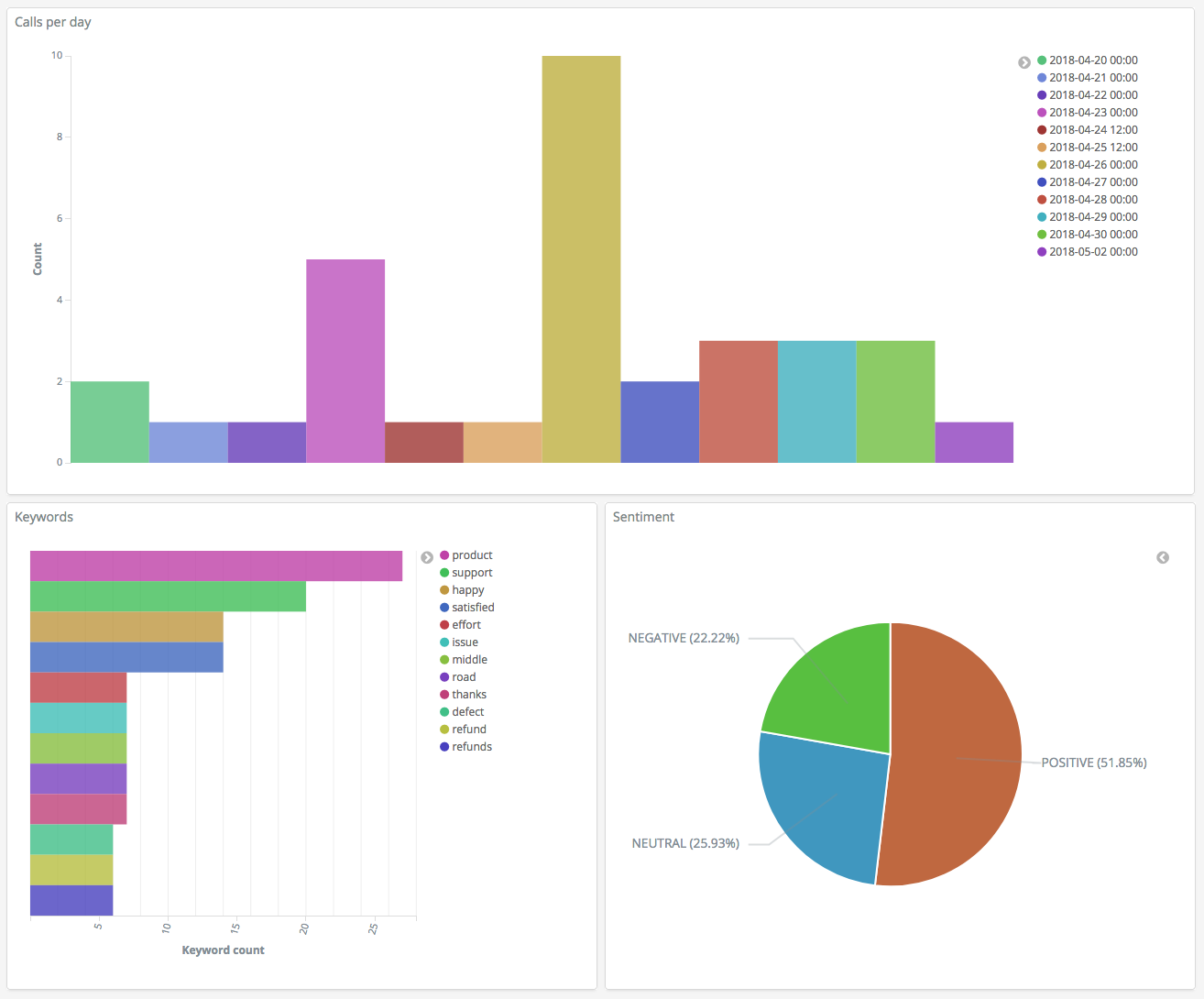
Fase 5: Pulizia delle risorse e fasi successive
Per evitare addebiti non necessari, eliminare il bucket S3 e il dominio OpenSearch Service. Per ulteriori informazioni, consulta Delete a Bucket nella Amazon Simple Storage Service User Guide e Delete an OpenSearch Service domain in questa guida.
Le trascrizioni richiedono molto meno spazio su disco rispetto ai file. MP3 È possibile ridurre il MP3 periodo di conservazione ad esempio, da tre mesi di registrazioni di chiamate a un mese, conservare anni di trascrizioni e comunque risparmiare sui costi di archiviazione.
È inoltre possibile automatizzare il processo di trascrizione utilizzando e AWS Step Functions Lambda, aggiungere altri metadati prima dell'indicizzazione o progettare visualizzazioni più complesse per casi d'uso specifici.
