Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Data lake moderni
Casi d'uso avanzati nei data lake moderni
I data lake offrono una delle migliori opzioni per l'archiviazione dei dati in termini di costi, scalabilità e flessibilità. Puoi utilizzare un data lake per conservare grandi volumi di dati strutturati e non strutturati a basso costo e utilizzare questi dati per diversi tipi di carichi di lavoro di analisi, dai report di business intelligence all'elaborazione di big data, all'analisi in tempo reale, all'apprendimento automatico e all'intelligenza artificiale generativa (AI), per guidare decisioni migliori.
Nonostante questi vantaggi, i data lake non sono stati inizialmente progettati con funzionalità simili a quelle dei database. Un data lake non fornisce il supporto per la semantica di elaborazione basata sull'atomicità, la coerenza, l'isolamento e la durabilità (ACID), che potrebbe essere necessaria per ottimizzare e gestire efficacemente i dati su larga scala tra centinaia o migliaia di utenti utilizzando una moltitudine di tecnologie diverse. I data lake non forniscono supporto nativo per le seguenti funzionalità:
-
Esecuzione di aggiornamenti ed eliminazioni efficienti a livello di record man mano che i dati cambiano nell'azienda
-
Gestione delle prestazioni delle query man mano che le tabelle crescono fino a milioni di file e centinaia di migliaia di partizioni
-
Garantire la coerenza dei dati tra più scrittori e lettori simultanei
-
Prevenzione del danneggiamento dei dati quando le operazioni di scrittura falliscono a metà dell'operazione
-
Evoluzione degli schemi di tabelle nel tempo senza riscrivere (parzialmente) i set di dati
Queste sfide sono diventate particolarmente frequenti in casi d'uso come la gestione dell'acquisizione dei dati di modifica (CDC) o in casi d'uso relativi alla privacy, alla cancellazione dei dati e all'inserimento di dati in streaming, che possono portare a tabelle non ottimali.
I data lake che utilizzano le tradizionali tabelle in formato Hive supportano le operazioni di scrittura solo per interi file. Ciò rende gli aggiornamenti e le eliminazioni difficili da implementare, dispendiosi in termini di tempo e costi. Inoltre, i controlli e le garanzie di concorrenza offerti nei sistemi conformi agli ACID sono necessari per garantire l'integrità e la coerenza dei dati.
Introduzione ad Apache Iceberg
Apache Iceberg è un formato di tabella open source che fornisce funzionalità nelle tabelle dei data lake che storicamente erano disponibili solo nei database o nei data warehouse. È progettato per garantire scalabilità e prestazioni ed è ideale per la gestione di tabelle di oltre centinaia di gigabyte. Alcune delle caratteristiche principali dei tavoli Iceberg sono:
-
Eliminare, aggiornare e unire.Iceberg supporta i comandi SQL standard per il data warehousing da utilizzare con le tabelle dei data lake.
-
Pianificazione rapida della scansione e filtraggio avanzato. Iceberg archivia metadati come statistiche a livello di partizioni e colonne che possono essere utilizzati dai motori per velocizzare la pianificazione e l'esecuzione delle query.
-
Evoluzione completa dello schema. Iceberg supporta l'aggiunta, l'eliminazione, l'aggiornamento o la ridenominazione di colonne senza effetti collaterali.
-
Evoluzione delle partizioni. È possibile aggiornare il layout delle partizioni di una tabella man mano che il volume di dati o i modelli di query cambiano. Iceberg supporta la modifica delle colonne su cui è partizionata una tabella, l'aggiunta di colonne o la rimozione di colonne dalle partizioni composite.
-
Partizionamento nascosto.Questa funzione impedisce la lettura automatica delle partizioni non necessarie. Ciò elimina la necessità per gli utenti di comprendere i dettagli di partizionamento della tabella o di aggiungere filtri aggiuntivi alle loro query.
-
Ripristino della versione. Gli utenti possono correggere rapidamente i problemi ripristinando lo stato precedente alla transazione.
-
Viaggio nel tempo. Gli utenti possono interrogare una versione precedente specifica di una tabella.
-
Isolamento serializzabile. Le modifiche alle tabelle sono atomiche, quindi i lettori non vedono mai modifiche parziali o non eseguite.
-
Scrittori concorrenti. Iceberg utilizza la concorrenza ottimistica per consentire il successo di più transazioni. In caso di conflitto, uno degli autori deve ritentare la transazione.
-
Formati di file aperti. Iceberg supporta diversi formati di file open source, tra cui Apache Parquet, Apache
Avro e Apache ORC.
In sintesi, i data lake che utilizzano il formato Iceberg traggono vantaggio dalla coerenza transazionale, dalla velocità, dalla scalabilità e dall'evoluzione dello schema. Per ulteriori informazioni su queste e altre funzionalità di Iceberg, consulta la documentazione di Apache Iceberg.
AWS supporto per Apache Iceberg
Apache Iceberg è supportato dai più diffusi framework di elaborazione dati open source e da Amazon EMR, Servizi AWS Amazon Athena,
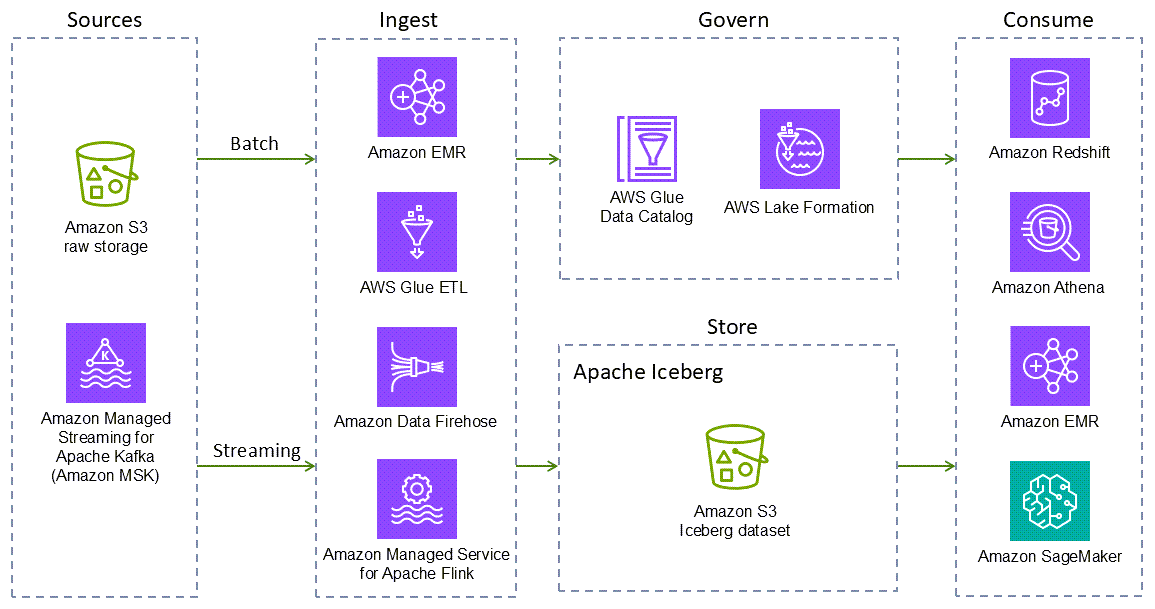
Di seguito vengono Servizi AWS fornite integrazioni native di Iceberg. Ce ne sono altre Servizi AWS che possono interagire con Iceberg, indirettamente o impacchettando le librerie Iceberg.
-
Amazon S3 è il posto migliore per creare data lake grazie alle sue capacità di durabilità, disponibilità, scalabilità, sicurezza, conformità e audit. Iceberg è stato progettato e realizzato per interagire con Amazon S3 senza problemi e fornisce supporto per molte funzionalità di Amazon S3 elencate nella documentazione di Iceberg.
-
Amazon EMR è una soluzione di big data per l'elaborazione di dati su scala petabyte, l'analisi interattiva e l'apprendimento automatico che utilizza framework open source come Apache Spark, Flink, Trino e Hive. Amazon EMR può essere eseguito su cluster Amazon Elastic Compute Cloud (Amazon EC2) personalizzati, Amazon Elastic Kubernetes Service (Amazon EKS) o Amazon EMR Serverless. AWS Outposts
-
Amazon Athena è un servizio di analisi interattivo senza server basato su framework open source. Supporta formati di file e tabelle aperte e offre un modo semplificato e flessibile per analizzare petabyte di dati nel luogo in cui risiedono. Athena fornisce supporto nativo per lettura, viaggio nel tempo, scrittura e query DDL per Iceberg e utilizza il metastore for the AWS Glue Data Catalog Iceberg.
-
Amazon Redshift è un data warehouse cloud su scala petabyte che supporta opzioni di distribuzione basate su cluster e serverless. Amazon Redshift Spectrum può eseguire query su tabelle esterne registrate e archiviate su Amazon S3. AWS Glue Data Catalog Redshift Spectrum supporta anche il formato di storage Iceberg.
-
AWS Glueè un servizio di integrazione dei dati senza server che semplifica l'individuazione, la preparazione, lo spostamento e l'integrazione di dati provenienti da più fonti per l'analisi, l'apprendimento automatico (ML) e lo sviluppo di applicazioni. AWS Glue 3.0 e versioni successive supportano il framework Iceberg per i data lake. Puoi utilizzarlo AWS Glue per eseguire operazioni di lettura e scrittura sulle tabelle Iceberg in Amazon S3 o lavorare con le tabelle Iceberg utilizzando. AWS Glue Data Catalog Sono supportate anche operazioni aggiuntive come inserimento, aggiornamento, query Spark e scritture Spark.
-
AWS Glue Data Catalogfornisce un servizio di catalogo dati compatibile con Hive metastore che supporta le tabelle Iceberg.
-
Crawler di AWS Gluefornisce automazioni per registrare le tabelle Iceberg in. AWS Glue Data Catalog
-
Amazon Data Firehose è un servizio completamente gestito per la distribuzione di dati di streaming in tempo reale a destinazioni come Amazon S3, Amazon Redshift, Amazon OpenSearch Service, OpenSearch Amazon Serverless, Splunk, tabelle Apache Iceberg e qualsiasi endpoint HTTP o HTTP personalizzato di proprietà di provider di servizi terzi supportati, tra cui Datadog, Dynatrace, MongoDB, New Relic, Coralogix e Elastico LogicMonitor Con Firehose, non è necessario scrivere applicazioni o gestire risorse. È sufficiente configurare i produttori dati perché inviino i dati a Firehose, che li distribuirà automaticamente alla destinazione specificata. È anche possibile configurare Firehose per trasformare i dati prima di distribuirli.
-
Amazon SageMaker AI supporta l'archiviazione di set di funzionalità in Amazon SageMaker AI Feature Store utilizzando il formato Iceberg.
-
AWS Lake Formationfornisce autorizzazioni di controllo degli accessi grossolane e dettagliate per accedere ai dati, incluse le tabelle Iceberg utilizzate da Athena o Amazon Redshift. Per saperne di più sul supporto delle autorizzazioni per le tabelle Iceberg, consulta la documentazione di Lake Formation.
AWS offre un'ampia gamma di servizi che supportano Iceberg, ma coprire tutti questi servizi non rientra nello scopo di questa guida. Le seguenti sezioni trattano Spark (streaming in batch e strutturato) su Amazon EMR AWS Glue e Amazon Athena SQL. La sezione seguente fornisce una rapida panoramica del supporto Iceberg in Athena SQL.
